基于噪声环境下的说话人识别系统的研究
2011-06-13范茂志
林 秀,范茂志
同济大学软件学院,上海 201804
基于噪声环境下的说话人识别系统的研究
林 秀,范茂志
同济大学软件学院,上海 201804
对带噪声的语音信号采用消噪算法处理,并提取特征参数Mel倒谱系数来建立说话人的特征参数的混合高斯模型,构建了一个基于噪声环境的文本无关的说话人识别系统。本文详细阐述了梅尔倒谱系数这一主流语音特征及高斯混合通用背景模型来建立说话人识别系统。实验表明,增加混合高斯模型的维数可以增加系统的识别率。
说话人识别;梅尔倒谱系数;高斯混合-通用背景模型
0 引言
说话人识别指在提取代表个人身份的特征信息,最终识别出说话人。作为身份鉴定的一种方法,说话人识别具有使用简单、获取方便、使用者的接受程度高等优点,但也存在许多值得研究的问题,如训练条件与测试条件不匹配。
说话人识别系统在训练条件与测试条件匹配的情况下,识别系统具有很好的性能。由于人体声道特征,语音信道及通话环境等因素的干扰,使得说话人识别系统的准确性显著降低。在说话人识别系统中,有两方面重要的影响因素:一方面,所选取的语音特征参数应尽量突出说话人的个性特征,使得不同说话人可以在特征空间上尽量分离。另一方面,降低环境噪声对说话人识别系统的干扰,是使训练条件与测试条件匹配的最好办法。通常提高系统抗噪性能的方法有3种:1)前端处理,如自适应噪声抵消技术等[1];2)提取具有鲁棒性的特征参数[2];3)后端处理,如归一化补偿变换[3]。
本系统的基本思路如下:首先,采用消噪算法对带噪声的语音信号进行消噪。其次,提取说话人特征信息。提取梅尔倒谱系数作为说话人的特征信息,由这些特征信息来刻画说话人特征矢量的超空间。最后,建立高斯混合-通用背景模型。通用背景模型的训练,自适应算法生成说话人模型,计算似然度进行得分测试及得分规整,完成辨认说话人。
1 说话人识别算法框架
说话人识别系统以待测说话人的语音波形作为输入,通过对波形的频谱及特征参数的计算和提取,可以得到说话人区别于其他说话人人的生理和行为特征的声学特征参数,来识别待测说话人身份。图1为说话人识别系统的整体框架。
根据系统的整体框架,可以把系统分成由两个主要组成模块:基于Mel倒谱系数[5](Mel-Frequency Cepstrum Coefficients, MFCC)说话人特征参数的提取模块和基于背景模型[6](Gaussian Mixture Model-Universal Background Model,GMM-UBM)的目标说话人的判决模块。
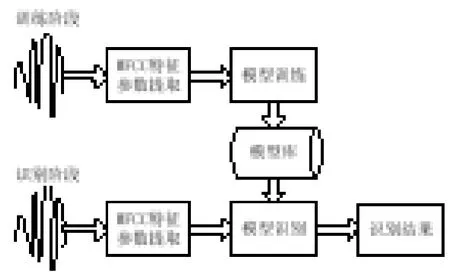
图1 说话人识别系统
1.1 基于MFCC说话人特征的提取
本模块的基本思路:首先,采用消噪算法对带噪声的语音信号进行处理,得到较为纯净的语音。采用消噪算法的目的在于提高语音质量,在消除背景噪音的同时使得语音信号更清晰准确,提高语音信号的可懂度。其次,对消除噪声之后的语音进行特征提取,得到可以代表说话人特征信息的梅尔到普系数,即说话人的特征参数。
1.1.1 消噪算法
采用谱相减法对语音信号消除噪声影响,图2为谱相减法的结构图。

图2 谱相减法
谱相减法的具体步骤如下所示:
1)确定语音信号的每帧的帧长,将语音信号进行分帧;
2)计算各帧的能量值,确定噪音能量阈值。在能量小于阈值且能量等于阈值的时刻之前的时间段内的能量认为是该能量为噪音能量,该时间段的信号为噪音信号。从能量大于阈值的时刻起后面所有时间的信号认为是带噪声语音信号;
3)对各帧语音信号进行傅立叶变换,得到语音信号的频谱信息;
4)根据所确定的噪声信号信息,对带噪声语音信号进行相位和频谱能量的变换,得到增强后的语音频谱图;
5)根据傅立叶逆变换,得到增强后到语音信号。
1.1.2 MFCC特征参数提取
MFCC在人耳听觉结构和人类发声和接受声音等机理特性方面具有很好的鲁棒性,并且在频率域上可以较好的表达说话人的个性特征,具有较好的识别性能和抗噪声能力。因为标准的MFCC仅仅表现了语音算数的静态特征,而语音的动态特性更能满足人耳对声音敏感的特性,故本文采用的特征提取算法是在MFCC的基础上再作一阶差分(MFCC),二阶差分(MFCC)这三部分构成了特征矢量。它对消除语音信号的帧之间的相关性具有很好的效果,并且可以很好的逼近语音的动态特性,对提高系统的识别率有很大的作用。MFCC特征参数的提取过程如图3所示:

图3 特征提取
特征提取具体步骤如下:
1)预加重,减少尖锐噪声的影响,提升高频信号,x(n)为原信号,y(n)为预加重后信号;

2)加汉明窗,减少吉伯斯效应。W(n)是窗函数,Sw(n)是加窗后信号:

3)对信号Sw(n)进行DFT
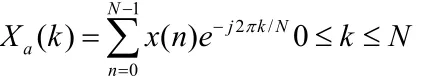
4)把频谱系数用三角滤波器进行滤波处理,得到一组系数m1, m2,...,mM,M 为滤波器组个数。滤波器组中每一个三角滤波器的跨度在Mel标度上是相等的。
5)计算每个滤波器组输出的对数能量:
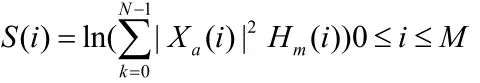
6)经离散余弦变换(DCT)得到MFCC:
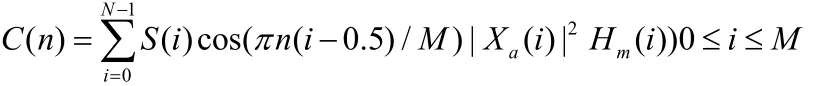
7)对MFCC再作一阶差分、二阶差分作为最终的特征矢量。
1.2 基于GMM-UBM模型目标说话人的判决
1)注册说话人阶段:注册语音在UBM模型上计算高斯状态占有率,得到统计量,在UBM的均值和方差中做一个类似插值的操作得到说话人模型参数。
具体步骤如下:
(1)语音特征矢量X = { x t,t = 1, 2, …,T },设置最大迭代次数L以及每次迭代的改进阈值作为迭代过程的终止条件;

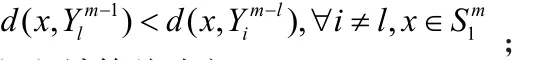
(4)计算总畸变Dm:
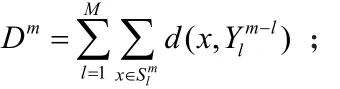
(5)计算畸变的相对改变值:
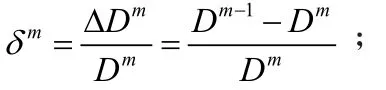
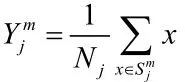
(7)如果当前误差值小于门限值则跳转到第(9)步,否则,跳到第(8)步;
(8)若m > L,跳到第(9)步,否则,m = m +1,跳转到第(3)步;
(9)迭代终止并计算:

其中,Nj是属于第的点的个数;
2)测试阶段:测试语音在UBM模型上计算高斯的似然度,并计算在待测说话人模型上对应的高斯似然度,将两个似然度相减则为最后的得分。具体步骤如下:
(1)首先对通用背景模型(UBM)中每个高斯计算似然度得分,并对每一帧选出得分最高的C个高斯模型。
(2)计算说话人模型得分,每一帧只需要计算对应于UBM的C个高斯模型的得分即可。
(3)计算最终的测试得分为说话人模型和通用背景模型两者之差。
3)得分规整[7]阶段:由于同一说话人在不同的说话状态、语义信息、环境噪音等因素的影响,说话人在不同状态下的语音信息和特征信息会有所不同,导致同一说话人在两次说话中出现差异,在系统上表现为得分不同。不同说话人在某些相同的环境下会有一定的相似性。
通过得分规整技术对说话人识别的高斯似然度进行归一化运算,使在不同说话人模型下的输出得分规整到同一分布范围。得分规则可以有效地减小同一说话人的不一致性,扩大不同说话人的不一致性。本文主要讨论对最后得分ZNORM[7-8]、TNORM[9]及ZTNORM这三种方式规整技术。ZNORM(Zero Normalization)的原理是利用大量冒认者语句对目标说话人模型进行测试,再利用输出得分统计出目标说话人模型的辅助参数。TNORM(Test Normalization)的原理是计算大量冒认者模型对待测语句的得分,从而得到待测语句在冒认者模型上的相关参数,TNORM是一种在线处理的规则方法。其缺点是当冒认者模型较多时,计算量较大,比较耗费时间。
2 实验分析及结果
本实验采用的语音数据的格式是16kHz,8位精度,wav 文件格式,语音时长为5min。设置12个实验,对不同的高斯维数(256、512、1024、2048)及得分规则(ZNORM、TNORM、TZNORM),得到不同的等错误率。

表 1
由表1中的12个实验数据可以看出,2048个高斯模型,TNORM和ZNORM的混合得分规整这个实验参数是等错误率(EER)最小,在12个实验中识别效果最好。对不同的高斯维数及得分规则,说话人识别系统的等错误率(EER)有不同,整体趋势是高斯维数越大,等错误率EER越小,识别效果越好。混合得分规整具有较好的效果,EER较低。
3 结论
增高通用背景高斯混合模型的维数可以较为准确地对说话人的特征信息即MFCC进行建模,很好的描述说话人的特征信息,并使得系统获得较好的系统识别率。
[1]TADJ C, GABREA M, GARGOUR C, et al.Towards robustness speaker verification: enhancement and adaptation[C]//Proceeding of the 45th Midwest Symposium on Circuit and System.New York: IEEE, 2002:320-323.
[2]ZHEN Y X, ZHENG T F, WU W H.Weighting observation[C]//Proceedings of International Conference on Spoken Language Processing.Jeju Island, Korean: ISCA,2004: 819-822.
[3]包永强,赵力,邹采荣.采用归一化补偿变换的与文本无关的说话人识别[J].声学学报,2006,31(1):55-60.
[4]D.A.Reynolds and R.C.Rose.”Robust textindependent speaker identification using Gaussian mixture speaker models”IEEE Trans.on Speech and Audio Processing,1995,3.
[5]Steve Young,The HTK Book.Ver 3.0, July 2000.http://svr-www.eng.cam.ac.uk.
[6]D.A.Reynolds.”Speaker identification and verification using Gaussian mixture speaker models”Speech Communication, 1995,17:91-108.
[7]Frederic Bimbot, Jean-Francois Bonastre, A Tutorial on Text-Independent Speaker Verification[J].EURASIP Journal on Applied Signal Processing,2004,4:430-451.
A Study on the Textindependent Speaker Recognition System under Noisy Condition
LIN Xiu,FAN Mao-zhi
School of Software Engineering, Tongji University,Shanghai 201804
TP391.42
A
1674-6708(2011)53-0182-03
林秀,硕士研究生,研究方向:说话人识别
范茂志,硕士,研究方向:人工智能、人脸识别、嵌入式Linux
