论数据分区对海量数据处理的必要性
2011-06-13赵浩然
赵浩然
(中国铁通长春分公司,吉林 长春 130061)
1 引言
随着计算机技术、网络技术、通讯技术和Internet技术的发展,随着信息化社会的演进,以及计算机存储设备的高速发展,在人们的生产生活中充斥着大量的数据,这些数据记录着各种各样的信息,如何从丰富的客户数据中挖掘有价值的信息,为企业管理者提供有效的辅助决策,是企业真正关心的问题,以笔者所在的电信公司为例,如何从各种用户消费详单、用户信息中有效迅速的提出企业所需信息,是我们研究的重点。
如何从成千上万甚至百万千万上亿的数据中找出对于我们有价值的信息,因为处理几十万的数据即使再复杂对于目前的软件和硬件发展水平来讲都是可以迎刃而解的,但是数据达到千万级或亿级就是一项耗时持久的事情,往往我们需求的数据又是要反复筛选的,这样就需要做很多的提前准备以及应用一些技巧。
2 数据处理工具选择
在实际工作中遇到的或即将遇到的问题:①日数据处理量几百万条,每日每月周期处理;②数据来源于多个异构系统;③需保证数据完整性,对异常数据进行纠错;④无法对硬件资源升级。
通常情况下海量的数据处理无法通过人工处理,只能借助于工具,在比较成熟的产品和应用中主要用到了数据库产品、数据仓库产品和商业智能产品等以及其组合应用,另外,长期数据处理工作中的一些经验和总结也是解决这些问题的利器。
2.1 工具的选择
数据库产品中用来处理海量数据比较成熟的目前主要有甲骨文公司的 ORACLE、IBM 的 DB2以及微软的 SQL SERVER,并且这三家公司都有较完善的数据库相关产品,如数据仓库、ETL工具、数据挖掘和分析工具,还可以提供全面的数据解决方案,其中ORACLE和DB2在大的行业中应用较多,如银行、电信、大型制造业企业以及政府部门等,SQL SERVER的市场份额还较小,但友好的界面、操作系统的庞大用户资源以及中小应用的普及和SQL SERVER 2008产品对商业智能的全面支持,使得SQL SERVE成为亿级数据往下的一个不错的选择。我们这里就选择了微软的SQL SERVER作为整个数据处理的工具。
2.2 硬件的选择
对于海量数据处理是硬件配置越高对于数据处理越有利,但硬件已经不是数据处理成败的决定性因素,如何在有限的硬件条件下物尽其用,充分发挥硬件的性能、合理的分配资源,与软件相辅相成是我们所看重的。我们选用了一台戴尔T410的塔式服务器,双至强2.13GHz CPU、8G内存和两块500 G硬盘。
2.3 软件的使用
海量数据处理目前主流做法是对数据存储进行分区操作,并辅以索引。还有通过建立数据仓库、多维数据库等商业智能的方法,优化结构来实现海量数据的处理和查询。另外,近期悄然兴起的基于开源的 HADOOP软件的分布式查询也提供一个较强大的海量数据处理方案。经验应用上主要还是因地制宜的根据不同数据源和数据形式进行的一些优化,如分视图、增量抽取、虚拟内存、缓存机制、分批处理、临时表、中间表和数据采样等。
3 数据处理方法具体应用
3.1 数据分区结合索引的应用
我们采用的是数据分区结合索引的方式。
数据分区分为水平分区和垂直分区。水平分区将表分为多个表。每个表包含的列数相同,但是行少。例如,可以将一个包含亿行的表水平分区成几个表,每个表存储一年数据,或者把一年的数据水平分成12个表,每个表存储一个月的数据。任何需要特定月份数据的查询只需引用相应月份的表。而垂直分区则是将原始表分成多个只包含较少列的表。水平分区是最常用的分区方式,我们也采用水平分区的方法。
建立分区表先要创建文件组,而创建多个文件组主要是为了获得好的I/O平衡。一般情况下,文件组数最好与分区数相同,并且这些文件组通常位于不同的磁盘上。每个文件组可以由一个或多个文件构成,而每个分区必须映射到一个文件组。一个文件组可以由多个分区使用。为了更好地管理数据(例如,为了获得更精确的备份控制),对分区表应进行设计,以便只有相关数据或逻辑分组的数据位于同一个文件组中。使用ALTER DATABASE,添加逻辑文件组名。创建文件组后,再使用ALTER DATABASE将文件添加到该文件组中,类似的建立三个文件和文件组对最近三年的数据进行分别存储,并把每一个存储数据的文件放在不同的磁盘驱动器里。
创建分区表必须先确定分区的功能机制,表进行分区的标准是通过分区函数来决定的。创建数据分区函数有 RANGE、“LEFT | / RIGHT”两种选择。代表每个边界值在局部的哪一边。例如存在三个分区,则定义两个边界点值,并指定每个值是第一个分区的上边界(LEFT)还是第二个分区的下边界(RIGHT)。
创建分区函数后,必须将其与分区方案相关联,以便将分区指向特定的文件组。就是定义实际存放数据的媒体与各数据块的对应关系。多个数据表可以共用相同的数据分区函数,一般不共用相同的数据分区方案。可以通过不同的分区方案,使用相同的分区函数,使不同的数据表有相同的分区条件,但存放在不同的媒介上。
建立好分区函数和分区方案后,就可以创建分区表了。分区表是通过定义分区键值和分区方案相联系的。插入记录时,SQL SERVER会根据分区键值的不同,通过分区函数的定义将数据放到相应的分区。从而把分区函数、分区方案和分区表三者有机的结合起来。
分区建好后,还要对分区进行维护。分区的维护主要涉及分区的添加、减少、合并和在分区间转换。可以通过 ALTER PARTITION FUNCTION的选项 SPLIT,MERGE和 ALTER TABLE的选项SWITCH来实现。SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SW ITCH则是逻辑地在组间转换分区。
现在我们对分区前后的效果进行比较,对一张存储4 000万条的记录进行分区,服务器为戴尔T410,CPU至强2.13 G*2、内存8 G、硬盘500 G*2,系统平台为Windows 2008+SQL Server 2008。
从以下四个方面进行比较:①根据时间检索某一天记录所耗时间;②单条记录插入所耗时间;③根据时间删除某一天记录所耗时间;④统计每月的记录数所需时间。
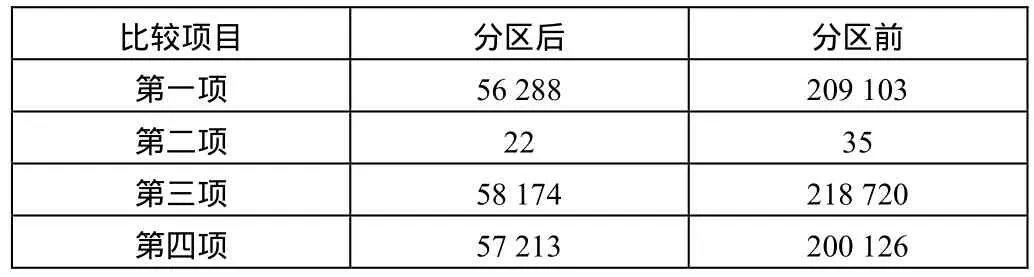
表1 比较结果 / m s
从比较结果可以看出,对分区表进行操作比未分区的表要快,这是因为对分区表的操作采用了CPU和I/O的并行操作,检索数据的数据量也变小了,定位数据所耗时间变短。
除了数据分区外,建立索引是一个非常必要的补充。但建立索引要考虑到具体情况,例如针对大表的分组、排序等字段,都要建立相应索引,一般还可以建立复合索引,对经常插入的表则建立索引时要小心,建有索引的表在进行数据插入时会变的非常慢。所以当插入表时,首先删除索引,然后插入完毕,建立索引,并实施聚合操作,聚合完成后,再次插入前还是删除索引。索引的填充因子和聚集、非聚集索引也都要考虑。
3.2 数据处理其他技巧的应用
3.2.1 加大虚拟内存
如果系统资源有限,内存提示不足,则可以靠增加虚拟内存来解决。一般虚拟内存应设置为物理内存的3倍为最好,并且虚拟内存应分别设置在不同的磁盘上,这样可以得到高于物理内存数倍的容量,解决资源不足的问题。
3.2.2 分批处理
顾名思义,就是把数据化整为零,对海量数据分批处理,然后处理后的数据再进行合并操作,这样逐个击破,有利于小数据量的处理,不至于面对大数据量带来的问题,不过这种方法也要因时因势进行,如果不允许拆分数据,还需要另想办法。不过一般的数据是按天、按月、按年等存储的,都可以采用先分后合的方法,对数据进行分开处理。
3.2.3 优化查询SQL语句
在对海量数据进行查询处理过程中,查询的SQL语句的性能对查询效率的影响非常大,编写高效优良的SQL脚本和存储过程是数据库工作人员的职责,也是检验数据库工作人员水平的一个标准,在对SQL语句的编写过程中,例如减少关联、少用或不用游标、设计好高效的数据库表结构等十分必要。
4 结束语
海量数据处理是一件既简单又繁复的事情,并且对数据分析和挖掘也越来越重要,从海量数据中提取有用信息重要而紧迫,这便要求处理要准确,精度要高,而且处理时间要短,得到有价值信息要快,这也使得近几年海量数据处理的方式方法得到进一步的拓展,也随着硬件设备的更新换代处理性能突飞猛进,海量数据处理将在一定时间内得到很好的解决。
