适用于实时查询的电信行业海量数据仓库构建方法
2011-06-11王锐,陈丽
王 锐,陈 丽
(1.中国移动通信集团公司广东分公司 广州510623;2.广东交通职业技术学院计算机工程学院 广州510650)
1 引言
随着互联网、移动互联网和物联网的发展,各种终端、信息收集器产生的数据和种类不断增加。对于海量数据,只有合理存储下来,经过清理、过滤和挖掘,将分析结果以各种直观方式呈现,或者实时地提供服务,提升用户体验,才能体现价值,创造实际效益。
数据仓库是目前企业比较通用的存储数据、获取信息的一种技术和手段,其存储了海量的企业数据,汇总了大量有价值的信息,但数据仓库的应用呈现方式,如KPI报表、OLAP、数据挖掘等,主要是通过对海量数据进行各种维度的不断聚合和汇总分析,处理过程需要数小时或数天,信息获取的实时性非常差,无法提供实时的数据查询服务。
以通信行业为例,由于用户数非常巨大,产生的通话记录、上网记录、短消息记录数据量非常庞大,如广东每天的数据量超过60亿。一般需要经过数据采集、数据装载、数据汇总、报表展示等多个过程,用户才能看到数据的分析结果。但对于实时用户行为分析、实时监控、投诉处理等应用,由于传统数据仓库在实时性上存在弊端,无法有效支撑。
如某用户投诉其手机GPRS套餐流量使用完,但这个月到现在并没有怎么上网,这时就需要查询该用户从月初到现在的所有上网及流量记录。对于这种需求,传统数据仓库技术无法实现,或只能通过一些特殊方式(如采用尽可能小的时间粒度的分区方法、以牺牲装载性能的在线索引方法)实现。这些方法要么只能实现准实时查询,要么需要牺牲装载性能,而装载变慢会直接影响数据查询的实时性。因此该用户的投诉处理无法实时完成,需要等待非常长的时间。因此,对于用户行为的第一手信息(如通话、上网、短信等)无法及时发挥其商业价值,无法及时处理用户对网络质量或消费的投诉。这个时间差值,现有的技术一般在数小时甚至更长时间。
为了更有效地利用数据,发掘商业价值,提高网络质量,快速有效地处理用户投诉,一种适用于实时查询及分析的数据仓库构建方法势在必行,其核心是要解决好快速装载和实时查询问题。
2 现有技术方案
现有技术方案都在努力提高查询的实效性和速度,但目前大多数数据仓库的构建过程一般采用ODS(operational data store,操作数据存储)-DW(data warehouse)架构,其中ODS是一个面向主题的、可变的、当前的细节数据集合;DW是基于ODS构建的汇总数据层,一般采用星型、雪花型模型,实现钻取、旋转等多维分析。ODS是细节数据满足实时查询的关键,目前的构建方案主要有以下两种。
方案1(数据串行装载,索引实时维护)如图1所示。
方案2(数据并行装载,索引后维护)如图2所示。
以上2种方案都具有如下缺点。
(1)实时性差
因为在海量数据仓库中,装载的数据量非常巨大,如果需要进行快速查询,需要在表上建立相关索引,否则查询根本无法快速完成。如果采用方案1,装载效率将非常低,同时也影响查询效率;方案2主要是将表按时间尽可能小粒度地分区,通过设置最后一个分区的索引失效保证装载的效率,但无法对最后一个分区的数据进行高效查询。这些技术针对最近的数据都无法提供查询或需要处理后才可查询,存在较大的时间差,往往在小时级甚至更长时间,数据查询的实效性差。
(2)管理复杂
为了尽可能提升查询的实时性,现有技术需要维护有“海量”分区的分区表,过多的分区将影响数据表维护以及数据装载的性能。每装载完一个分区,需要重建该分区表上的索引,海量数据表的维护管理将十分复杂。
(3)装载过程变得复杂
因为需要将数据装载进最近的一个分区,确保数据采集的实效性,如果采集的数据出现延时,装载的数据将有可能进入索引已重建的分区,装载效率将变得极为低下,装载的调度算法将十分复杂。

图1 现有技术方案1
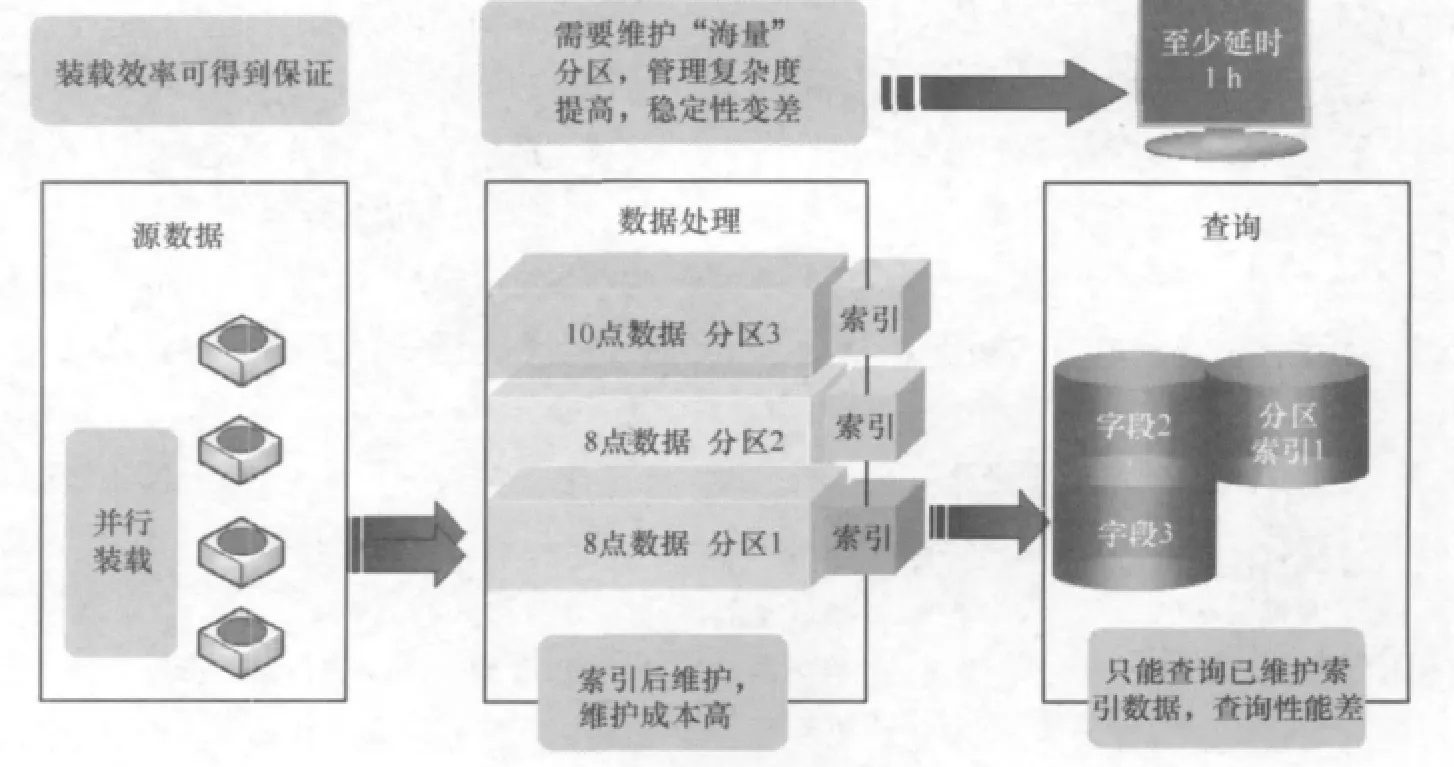
图2 现有技术方案2
(4)存在冲突的可能
方案2中,如果已装载完成的分区在建立索引的同时,有延时数据需要装载,因为数据库的锁机制,两者将发生冲突,其中一个操作将失败,导致应用程序的稳定性变差。
3 支持实时查询的解决方案
海量数据实时查询的需求就是快速从数以亿计的数据中,查询出一定时间范围内符合特定条件的数据。目前由于信息化的不断膨胀,数据规模越来越庞大,数据仓库往往是以TB、PB级的数据量计算。由于企业发展需求,对海量数据的实时查询要求也越来越高。海量数据仓库相对于传统数据库具有如下特点。
·数据一般有时间刻度,随着时间增加,数据量也在不断增加。
·数据一般具有一个关键的维度,如通话话单、WAP日志的手机号码、电子交易账单的用户ID等,一般查询条件都涉及关键的维度。
·数据查询一般有一定的时间范围,如一个月或一个星期等。
·数据在各自维度上的重复率较高,如一个月内某个用户的手机号码会有非常多的记录。
·数据入库后不需要进行更新操作,数据相对静态。
本文通过对海量数据仓库数据特点的研究,使用索引实时有效性及数据物理聚合等多个技术,缩短从源数据加载到查询的处理时间,压缩相关步骤处理时间至接近0,从而实现数据入库后的实时查询。该方案解决了现有方案的不足,其主要特点如下。
(1)实现海量数据的实时查询
采用外部表(平面文件映射表)装载技术以及索引实时有效技术,避免对新入库的数据进行处理后才提供查询,在保证高效装载的同时,能实现ODS层数据的实时高效查询,使数据的查询时间差接近0,满足实时性要求。
(2)实现海量数据的高效装载和查询处理
采用文件合并装载、多文件多并行装载、日志最小化、数据物理聚合以及索引自动聚合等技术,不仅实现海量数据的高效装载,最大限度地压缩入库时间,还能提高查询效率。如根据海量数据仓库实时查询的特点,在数据装载时将数据按时间进行分区存放,同时对同一时间范围内的数据按类型进行聚类存放,将同一时间范围内的同类数据尽可能存放在邻近的物理空间,可以减少磁盘I/O量及磁盘寻道时间,大大减少数据装载和访问带来的物理I/O,提高查询效率。最终可实现查询响应速度在秒级以内,且不受数据量及硬件资源限制。
(3)无其他关联影响
本方案在实现海量数据高效、实时查询的基础上,采用以上技术,无其他关联影响,基本实现自动化处理,无需花费大量的维护成本。
综合以上的技术实现特点,该海量数据仓库平台的整体架构如图3所示。
源数据层主要对原始文件进行采集,为后续操作做好准备。数据处理层是海量数据仓库的关键,采用多种优化装载技术,如文件合并、外部表装载、多文件并行装载等,不仅实现了传统ETL(数据抽取、清洗转换和装载)的过程,还完成了索引建立、数据分区和入库,同时保障索引有效,为上层支撑海量数据实时查询打下基础。查询处理层主要是针对不同查询条件,实现相关索引的自动聚合,满足了高效查询需求。最上层为查询响应层,接收查询请求,返回相应查询结果。
4 技术实现
根据图3的解决方案,在完成ETL的过程中,重点介绍关键的技术实现,如图4所示。
4.1 对数据进行分区存放
根据海量数据仓库的特点,数据都具有时间性,每条数据一般都有一个时间戳,如电信通话清单,每条记录都有一个时间字段(通话发生时间);电子交易账单,每条记录都有一个交易时间的字段。对于这些数据的查询都有时间范围的限制,如查询最近一个月内某个用户的通话记录。因此可以对这些数据进行分区处理,按照查询习惯,将数据按照一定时间粒度进行分区。以通话清单为例,可以按通话时间(即数据的时间性质)对数据进行分区,如图5所示。
数据进行分区后,每个分区的数据量缩小很多,如一个10亿条记录的表,按保留一个月时间计,分成30个分区,每个分区的数据量只在3 000万条左右。每个分区可以近似看成一个单独的表,可以直接在数据所在分区进行查询,从而大大减少查询时需要的物理I/O资源,提高查询速度。该步骤的具体方式如下。

图3 支持实时查询的系统架构
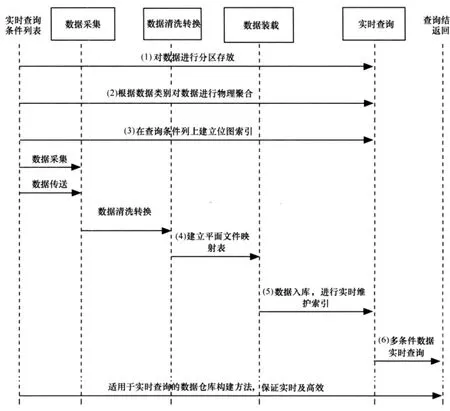
图4 技术实现原理

图5 数据按时间分区
·找出数据中的有效时间维度,一般是查询中涉及的时间范围,如通话清单中的通话时间。
·根据查询需求,定义查询的时间范围,如在通话清单中大部分查询都以一个月为范围。
·按时间范围对数据表进行范围分区,在数据入库时根据分区定义情况,自动将不同时间范围的数据存储到不同的分区中。
4.2 数据物理聚合
对于每个分区中的数据,根据数据的另一个性质——手机号码,对数据进行物理聚合。
本步骤实现了对数据的分区,一般可将数据量从数十亿下降到数千万,但在海量数据仓库中,每个分区也就是每个时间段内的数据量仍可达到数十亿甚至几十亿的规模。因此,对于海量数据的实时查询,每次查询的数据可能将上百GB数据散落在一个分区的任何物理块中,即使采用索引,查询效率也非常低。
分析查询条件进一步对数据进行物理聚合。因为一般存在必备的查询条件,即关键维度,如通话清单中的手机号码,可以将手机号码聚合在一起,通过少量物理I/O就可读取全部查询数据,提高查询速度。
数据按时间范围分区后,再进一步对表中数据按关键维度进行Hash分区,在进行Hash分区的同时,数据会自动进行聚合处理,访问的数据量也大大下降。如一个10亿条记录的表,按保留一个月时间计,分成30个分区,每个分区再分成16个Hash子分区,每个子分区的数据量只有200万左右。分区的个数可根据数据量确定,因此,可以对海量数据按一定需求进行分隔存放,只需保证每一块子分区的合理大小,就可以做到海量数据的无关性,不管多大的数据量,经过分区处理,都可以实现性能最优化。
因为数据装载使用多文件并行装载的方式,二级分区也可以用于提升装载效率,如采用每个CPU、文件、并行进程对应一个分区,可以大大提升装载效率。二级分区的数量计算方式为:二级分区数量=max(逻辑CPU个数×2,单次装载的文件数量),同时二级分区的个数建议设置为2n。其技术原理如图6所示。
该步骤的具体方式如下。
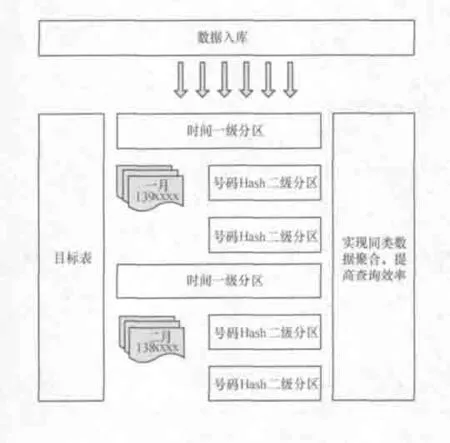
图6 数据聚合技术原理
·找出数据中的关键维度,一般用于特定数据的查询过滤条件,可根据查询需求而定,如通话清单中的手机号码。
·根据上面的计算公式,计算关键维度Hash分区数。
·在时间范围分区的基础上,按关键维度进行二级Hash分区,在数据入库时根据分区定义情况,自动将同类数据自动聚合到相同或相近的物理位置上。
4.3 关键维度字段建立位图索引
通过§4.1、§4.2,实现数据的分区及相同数据的自动聚合,大大降低查询时的I/O量,提高了查询性能。但索引仍然是实现海量数据实时查询最基本的要素。
由于海量数据查询条件一般存在关键维度,关键维度上的数据重复性非常高,如通话清单中的手机号码、电子交易账单中的用户ID。相对于海量的通话记录或交易信息,手机号码或用户ID的数量就较为有限。
根据这个特点,相对于传统的BTree索引技术,可以对该字段建立位图索引,即使用位图的方式,无需对索引的每个键值数据进行维护,只需对单一的键值数据进行维护,索引维护的成本极低。
使用位图索引方式,在进行大数据量装载的时候,索引进行维护的开销可以忽略不计。位图索引不适合需要频繁更新的数据,但对于静态性的数据仓库数据,非常适合。
位图索引要求根据主表分区情况进行相应分区,索引类型为本地分区索引,可以确保在海量入库的同时,在关键维度字段建立索引的有效性,同时无需花费巨大索引维护代价。
在海量数据装载过程中,采用位图索引进行索引实时维护,比采用BTree进行索引实时维护的装载性能高出10倍以上。
4.4 外部表装载
以上步骤为实现数量数据的实时查询打下了坚实的基础,但对于实现实时查询的目标还有一定距离。对于一般数据量的处理,通过以上步骤可以实现要求,但对于海量数据,由于其数据量巨大,无法只使用单进程的方式进行数据装载,否则装载效率无法满足要求。目前对于海量数据的装载,都是通过并行装载的方式实现,对于传统的并行装载方式,都需要将索引置为无效,即跳过索引的实时维护。现有技术方案在满足装载效率的情况下,无法保证索引的实时有效。
本文采用外部表的方式实现数据入库,在入库的同时完成相关实现。平面文件映射可以将多个平面文件映射成一张数据库中的虚拟表,对虚拟表的访问与访问实际物理表一样,如可以通过insert*select*的SQL方式实现数据的并行入库,对于select集及insert集都可以使用并行的方式,该并行方式属于数据库内语句处理级的并行,不会造成索引的无效,可以保证索引的实时维护。
文件映射表需要在每次装载时进行更新,使用更新文件映射表属性的方式对装载的文件源进行更新。
该步骤的具体实现方法如下。
(1)文件映射表建立语法

(2)确定每次装载的平面文件大小
装载的源数据是采集的许多小文件,存在文件数量众多、数据量大的特点。这种特点将导致装载过程缓慢,因此需要对文件进行合并处理,合并文件大小需要根据主机性能及存储性能综合测定,过大及过小都将影响装载速度。文件大小可以通过计算式测算:单个文件大小=存储每秒I/O吞吐量/CPU个数。
(3)确定每次装载的文件个数
目前的主机资源一般都是多CPU,数据仓库的特点就是最大化吞吐量,因此先考虑表的子分区个数,合并文件时,需要考虑CPU数量的影响。为了提高装载速度,必须充分发挥多CPU的特点,每个CPU都分配尽量均等的任务。并行装载文件的个数与CPU数量有关,经实验测算,并行装载文件的个数计算式为:并行装载文件的个数=逻辑CPU个数×2。
(4)修改文件映射表对应文件属性
修改文件映射表装载文件属性,确保每次装载的都是正确的目标文件,且每次装载的文件个数符合要求。
4.5 数据入库及实时索引维护
完成前面步骤后,只需利用平面文件映射表作为数据源表,进行数据并行入库即可。在并行入库的同时,实现数据的分区存储、同类聚合及索引实时维护。
考虑到充分利用主机资源,提高入库效率,一般为装载的语句设置并行度,并行度分为并行读取与并行写入,并行度的大小与CPU数量和并行装载的文件数有关,计算式为:读取并行度=max(逻辑CPU个数×2,并行装载文件个数);写入并行度=max(逻辑CPU个数×2,并行装载文件个数)
相关SQL语法示例如下:insert/*+并行提示 */into目标表select*from平面文件映射表。
4.6 实现海量数据的多条件实时查询
采用位图索引自动聚合技术,解决了多条件实时查询需求。通过在几个查询条件的字段上建立对应的位图索引,在进行各种不同组合的查询时,优化器能根据查询条件自动聚合相关字段上的位图索引,提供与组合索引一样的查询效率。使用该技术可以实现多条件的快速查询,同时避免建立过多组合索引带来的装载速度降低问题。
通过以上步骤,海量数据无需经过缓冲处理,数据入库后即具备高效查询条件,用户可随时进行数据查询,无需等待数据进行额外处理,查询后瞬间返回数据结果,实现真正的海量数据实时查询。
5 结束语
实时查询在通信、金融、电子商务等行业需求广泛,可以应用于用户行为实时分析、网络故障快速定位、用户交易信息的实时查询等,最大程度体现数据的价值。
本文提出的技术解决方案实现了海量数据的近零时差、秒级响应,具备实时查询能力。目前该技术方案已经在中国移动通信集团公司广东分公司实施应用,在每天入库近60亿条数据,单表容量达27 TB的情况下,使用本方法构建的数据仓库,在实时查询方面达到快速返回数据的效果,不仅支撑了数据仓库的多维分析,还提供了海量基础网络数据的实时查询能力,查询效率高效而稳定,支撑了网络监控、投诉处理等众多应用场景,丰富了海量数据的利用价值。
1 王彦龙.企业级数据仓库(EDW)原理、设计与实践.北京:电子工业出版社,2006
2 李颖,郝克刚,葛玮.基于电信数据仓库系统的ETL研究与设计.计算机应用与软件,2009,26(1)
3 朱鹏翔,刘文煌.基于DB-ODS-DW的CRM动态数据仓库.计算机工程与应用,2002,38(20):190~193
4 张俊,张忠能.实时数据仓库体系架构的研究.计算机工程,2004,30(Z1):180~182
