基于Hadoop的Web日志预处理的设计与实现*
2011-06-09宋莹沈奇威王晶
宋莹,沈奇威,王晶
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876;2 东信北邮信息技术有限公司,北京 100191)
1 引言
随着Internet的迅猛发展,Web上的信息急剧膨胀,而其中蕴含的信息未能得到充分的挖掘和利用。因此,Web数据挖掘成为数据挖掘技术研究的热点。Web数据挖掘主要分为3类:Web内容挖掘(Web Content Mining),Web结构挖掘(Web Structure Mining)和Web日志挖掘(Web Usage Mining)[1]。
Web日志挖掘就是对用户访问Web时的访问记录进行数据挖掘。通过分析和研究日志的规律, 实现聚类、分类、关联规则、序列分析等Web日志挖掘算法[2]。
Web日志挖掘过程一般分为3个阶段[3]:预处理阶段、挖掘算法实施阶段、分析阶段。数据预处理的目的就是将原始日志经过处理形成用户的会话文件,为挖掘算法实施阶段作好数据准备。作为整个挖掘过程的基础和实施有效挖掘算法的前提,数据预处理环节非常关键。
Web日志包含了丰富和动态Web页面的访问和使用信息,这为Web日志挖掘提供了丰富的资源。但是如何对Web日志进行高效可靠的数据预处理具有极大的挑战性[4]。
Hadoop是Apache下的一个开源分布式计算平台,它提供简单的编程模型,对大量数据进行分布式处理。Hadoop一般运行在由大量普通计算机组成的集群上。Hadoop框架的核心是分布式文件系统HDFS和Map/Reduce。HDFS创建数据块的多个副本,并将其分布存储在集群的数据节点(Data Node)上,实现可靠而快速的计算。Map/Reduce是一个用于大数据量并行计算的编程模型,同时也是一种高效的任务调度模型,它将一个计算任务分成很多细粒度的子任务,并在空闲的处理节点(Task Tracker)之间进行调度,使处理速度快的节点处理更多的任务[5]。同时Map/Reduce也会针对失败的任务重新分布处理,提供其高可用性。
本文采用高可拓展性的Hadoop分布式计算平台,通过对某典型书籍阅读网站的日志进行研究和分析,设计与实现了一个基于Hadoop的Web日志预处理方法,方便行之有效的进行后续Web日志挖掘工作,进而指导页面的布局改造,优化网站的总体架构,提升网站的流量,增加网站的收益。
2 设计思想
Web日志挖掘首先要对日志中的原始数据进行采集和预处理,其任务是将原始日志数据转换成适合数据挖掘和模式发现所需的会话文件。传统的Web日志预处理主要包括数据清洗、用户识别、会话识别和路径补充。我们的日志中含有用户ID字段,每个用户ID标识一个用户,故而省去用户识别步骤。并结合路径补充进行适当的会话拆分。
2.1 Web日志采集
在进行Web日志预处理和挖掘之前,首先要进行数据采集,确定合适的数据源。Web用户访问数据可以服务器端、客户端或代理服务器端进行收集。本文的数据源为来自服务器端的Apache日志文件,它详细记录了该书籍阅读网站用户的访问行为,日志格式如表1所示(省略部分空字段)。
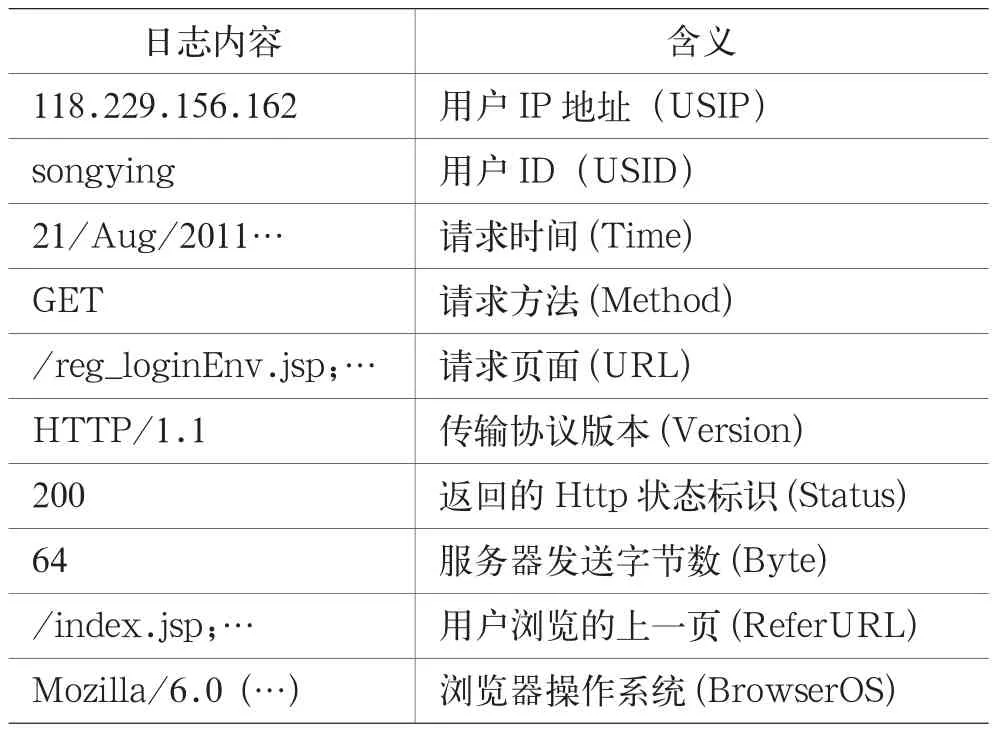
表1 Web 日志格式
2.2 Web日志预处理
Web日志记录了用户对网站的每一次点击访问,但由于种种原因,Web日志中有很多记录是多余的、不完整或错误的,这对数据挖掘不但无用,还会增加处理的复杂性,甚至产生错误结果。因此在进行数据挖掘之前必须对数据进行预处理,以消除数据的不完整性、噪声和不一致性。
2.2.1 数据清洗
数据清洗是指根据需求,对日志文件进行处理,删除与挖掘任务不相关的数据并合并某些记录,对用户请求页面时发生错误的记录进行适当的处理等等。
当用户请求一个网页时,与这个网页有关的图片、音频等信息会自动下载,并记录在日志文件中,由于图片、音频等不是用户显式请求的,因此可以把日志中文件的后缀为gif、jpg、jpeg、wav等的记录删除。后缀名为cgi、js等的脚本文件对后面的分析处理没有任何影响,也应该删除。
常见的页面请求方法包括GET、POST和 HEAD。由于只有GET方法反映了用户的访问行为, 因此本文只保留 GET 方式的记录。
2.2.2 会话识别
会话就是指一个用户从进入网站到离开网站所访问的一系列页面。会话识别的任务就是将每一个用户的每一个会话识别出来。本文结合使用基于引用和基于页面访问时间间隔的方法完成会话识别,识别过程可描述如下:
(1)对同一用户,按照页面访问时间排序,依次处理访问页面。
(2)如果用户访问的页面为网站主页,则认为这是一个新的会话。
(3)检查访问页面的ReferURL,如果ReferURL为网站主页,且用户访问的上一页不是网站主页,也认为这是一个新的会话;如果ReferURL为空,且该记录与上一条记录的访问时间间隔大于10s[6],也认为该记录为一个新的用户会话。
(4)设定相邻页面的访问时间阈值δ。对于一个用户访问序列中的两条相邻访问记录,只有当ti+1-ti<δi的时候,才认为两次访问属于同一个会话。现有的会话识别方法一般将δ设为10min。由于本文的实验数据来自一个书籍阅读网站,导航页与书籍阅读页的信息含量差别很大,鉴于正常人的阅读速度平均为每分钟200~240字[7],而该书籍阅读网站书籍阅读页页面字数为1000~6000不等,故而提出一种基于页面包含字数的时间阈值设定方法,假设页面i包含字数为Ci,其阈值设定为δi=Ci/200。
2.2.3 路径补充与会话拆分
Taucher和Greenberg证明超过50%的页面访问是通过Backward按钮进行的[8]。由于代理服务器和浏览器缓存的存在,在Backward时,不会访问Web服务器,服务器上没有任何该页面的日志文件,路径补充重点是把用户通过Backward按钮访问的路径记录补全。
本文采用基于引用和网络拓扑结构的方法进行路径补充,并据此进行会话拆分。如果一条记录的referURL不是上一条记录的 URL, 则假定用户使用回退按钮访问了缓存中的页面,需要进行路径补充。根据referURL和网络拓扑结构的路径补充遵循以下规则:如果某条用户会话的访问路径为a-b-c-d-e,而页面d的ReferURL不等于c的URL,则依次查找d与页面c、b、a之间的超链接关系,直到发现存在超链接关系的最近页面,假设d与c、b之间均不存在超链接关系,而和a之间存在超链接关系,那么认为这个用户是通过Backward按妞,从本地Cache中调出页面a,从而访问页面d,将该会话拆分为a-b-c和a-d-e;否则若页面d和a、b、c均无超链接关系,则认为用户是从绝对地址到达页面d,将该会话拆分为a-b-c和d-e。
3 分布式预处理模型的实现
3.1 网站拓扑结构的爬取和存储
Web日志预处理中的路径补充和会话拆分需要根据网站的拓扑结构,确定那些由于被代理服务器和浏览器缓存,而在服务器日志中没有记录且被用户重复访问的网页;会话识别需要根据具体网页包含字数确定时间阈值δ,故而我们采用网络爬虫爬取网络拓扑结构。
网络爬虫的爬取策略一般分为深度优先、广度优先和最佳优先3种。广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索,算法的设计和实现相对简单。本文使用广度优先搜索方法,多线程爬取网络拓扑结构,直到所有线程全部超时。
将网站的拓扑结构采用有向图表示。有向图是一个二元组,记为D。即D=
经过爬取、清洗、去重,得到该网站的149265个顶点、4825319条有向边,平均页面出度为32.33。
在爬取网络拓扑结构的同时,计算所有页面的字数。字的定义为:页面HTML标签页,即“<”及“>”之间的字符不计算在内;每个中文字、每个标点符号、每个英文单词、每个数字均记为一个字。
根据2.2.2节提出的方法,得出页面访问时间阈值δ,对应的页面数统计如表2所示。

表2 页面访问时间阈值δ对应的页面数统计(min)
从表2可以看出,页面的时间阈值虽然经过调整。但在一些字数较少的导航页可能过小,当δ<1min时将δ设置为1min。
使用目前常用的评价标准[9]:会话被算法完整重建的程度。使用精确度和查全度这2个指标来衡量重建程度。设Rh为算法h生成的会话集合,R是真正的会话集合,则精确度p(h)=|Rh∩R|/|Rh|,查全度r(h)=|Rh∩R|/|R|。在对各种算法进行比较时,以基于引用的方法得到的会话集合作为基准R,实验数据如表3所示。

表3 会话识别方法的比较结果
可以看到,相对于传统的固定阈值10min,基于页面字数确定页面时间阈值的会话识别算法精确度与查全度都有提高。改进的值更能反映用户的浏览习惯,使得划分的会话更为准确。
3.2 Map/Reduce程序的设计与实现
Map/Reduce提供了一个在大数据集上的并行计算框架。Mapper将输入记录打散,按照用户要求形成
(1)随着Web日志的大规模增长,每天的日增量上亿,单一节点的计算能力已经不能满足要求,而MapReduce支持大规模集群操作,在集群上可以方便地增加多至上千个节点并行计算,其计算速度会随集群数量相应增加。
(2)Web日志的预处理,需要针对每个用户处理其全部访问,非常适合MapReduce的
3.2.1 Mapper操作
Mapper操作的输入为Web日志记录,对于每条记录,进行数据清洗工作,并选择key为USID,value为
功能:清洗每条输入日志记录,形成 1. input[] ← 以" "分隔的输入记录 2. if input[5] = "GET" and input[6] 不以{gif、jpg、jpeg、wav、rm、css、cgi、js}结尾 and 200 <=input[8] <= 299 3. mapKey ← input[0] 4. mapValue ← input[5]|input[6]| input[8] 5. collect {mapKey,mapValue} 6. end if 3.2.2 Combiner操作 为了优化MapReduce操作,我们增加一个可选的Combiner操作。Combiner在Mapper之后、Reducer之前运行,它会在每一个运行map任务的节点上运行;接收节点上的Mapper的输出作为输入,对Mapper的输出进行聚合,同时聚合的结果也会作为Combiner的输入进一步进行数据聚合,直到在该节点上的每个key聚合为一条记录。Combiner的输出会被发送到Reducer。 本文的Combiner操作将Mapper操作的输出键值对聚合为 3.2.3 Reducer操作 将USID定义为Combiner的输出key,将URLIt定义为包含Combiner输出value的迭代器,将US定义为格式为 Reducer接收一系列 2. urlArray[] ← 以";”分隔的urls 4. USIt ← USIt + {url} 5. end for each 6. end for each 7. 将USIt按照Time字段升序排列 8. us1 ← USIt.next() 9. USL ← {us1} 10. reduceValue ← null 11. while USIt.hasnext() do 12. us2 ← USIt.next() 13. if (us2 = "index.jsp") or (us2.referURL =“index.jsp” and us1.URL ≠“index.jsp”) or(us2.referURL = null and us2.Time us1.Time <10s) or (us2.Time us1.Time > δus1.URL) then 14. reduceKey ← USL中全部记录中的URL字段依序以"|"连接 15. collect {reduceKey,reduceValue} 16. us1 ← us2 17. USL ← {us1} 18. else if us2.referURL = us1.URL then 19. USL ← USL + {us2} 20. us1 ← us2 21. else if us2.referURL ≠ us1.URL then 22. reduceKey ← USL中全部记录中的URL字段依序以"|"连接 23. collect {reduceKey,reduceValue} 24. us1 ← us2 25. 倒序扫描USL直到列表头,until find usk,其中usk.URL = us2.referURL 26. USL ← USL – {us1…usk} + {us1} 27. if none usk.URL = us2.referURL 28. USL ← {us1} 29. end if 30. end if 31. end while 实验运行在一个Hadoop集群上,这个集群由10台服务器组成。其中的一台服务器作为分布式文件系统HDFS的NameNode及MapReduce运行过程中的JobTracker,这台机器称为主节点。另外9台机器作为HDFS的DataNode和MapReduce运行过程中的TaskTracker,这些节点称为从节点。9台从节点的配置如表4所示。 为验证Hadoop对Web日志预处理的有效性及高效性,我们在单机和Hadoop集群上分别用Java语言实现了前面相同的Web日志预处理方法(单机的配置为双核3.2GHz处理器,4GB内存),并在两个平台上分别对文件大小不同的Web日志文件分别进行处理,计算执行时间,其结果如图1所示。 表4 集群DataNode配置表 图1 单机系统与Hadoop集群执行时间的对比 同时在Hadoop集群上针对更大量数据进行测试,其结果如图2所示。 图2 大量数据在Hadoop集群执行时间 由以上测试过程可以看出,采用Hadoop平台处理Web日志是一个行之有效的方法。当处理数据量较小时,由于Hadoop平台的启动耗时和中间文件的传输耗时,并行运算的总时间反而大于单机执行的时间。但随着数据量的增大,Hadoop平台将数据分割后分派给多个计算节点并行处理,使并行运算速度增长缓慢,而单机处理时间基本呈现线性增长的趋势。随着输入数据的增加,两者执行效率的差距也越来越大。另外,Web日志条数在104的数量级上由于集群的计算节点一直未满,故而时间增长非常缓慢;在106的数量级上,集群的计算节点基本已满,此时Hadoop的处理时间呈现略小于线性的增长,而在这样的数据集上,由于内存、处理器能力等诸多条件的限制,单机运算还可能出现内存溢出等现象,需要进行数据拆分。 Web日志挖掘中的一个重要的前提和基础就是数据准确性。高质量的Web日志挖掘必须依赖高质量的数据[10]。本文针对海量的Web日志,基于现有的Web日志预处理方法,提出一种改进的会话识别、路径补充和会话拆分方法,并基于Hadoop平台实现。同时针对Hadoop与单机的处理效率进行了对比,证实了Hadoop平台对于Web日志预处理的有效及高效性。 [1] 杨清莲,周庆敏,常志玲. Web挖掘技术及其在网络教学评价中的应用[J]. 南京工业大学学报, 2005(05):100. [2] Ni P,Liao J X,Wang C,Ren K Y. Web information recommendation based on user behaviors[A]. 2009 WRI World Congress on Computer Science and Information Engineering[C]. March 31, 2009-April 2, 2009:426. [3] 杨怡玲,管旭东,陆丽娜. 一个简单的日志挖掘系统[J]. 上海交通大学学报, 2000(7):35- 37. [4] 朱鹤祥. Web日志挖掘中数据预处理算法的研究[D]. 大连:大连交通大学, 2010:11. [5] 程苗,陈华平. 基于Hadoop的Web日志挖掘[J]. 计算机工程.2011,06(11):37. [6] Rosenbium M, Garfinkel T. Virtual machine monitors: current technology and future trends[J]. IEEE Computer Magazine, 2005, 38(5): 39-47. [7] 东尼•博赞(Tony Buzan). 博赞学习技巧[M]. 北京:中信出版社, 2009.41-42. [8] Taucher L,Greenberg S.Revisitation patterns in world wide web navigation[A].Proc of Int Conf CHI’97[C]. 1997 Atlanta. [9] Cooley R,Mobasher B,Srivastava J. Data preparation for mining world wide web browsing patterns[J]. Knowledge and Information System.1999,1(1):32-40. [10] 赵莹莹,韩元杰. Web日志数据挖掘中数据预处理模型的研究与建立[J]. 现代电子技术, 2007(4):103-105.4 结果分析



5 结论
