点击流分析在教务管理系统中的应用
2011-06-07邹丽新
邹丽新
(福建江夏学院 电子信息科学系,福建 福州 350108)
用户点击网站每天都会产生大量的数据,这些数据被称作点击流数据.点击流,顾名思义,就是访问者在网上的持续的访问轨迹.它从各方面详尽地反映出用户访问Web的细节,其中包含很多潜在的非常有用的信息,例如,客户的行为和客户的兴趣等.通过对其深入分析,能更深刻地理解用户行为,也有利于明确数据挖掘的任务,改善网页设计和提供决策支持等.
1 点击流数据源
本文所研究的点击流数据为学校Web服务器上的日志文件.现在有3种公开的标准日志文件格式用来记录日志文件.这3种开放格式是:NCSA的普通日志格式CLF(common log format);NCSA的扩展日志格式ECLF(extendedcommon log format)和W3C的扩展日志文件ExLF(extended logfile format).其中,ExLF是唯一一种能够定制那些特殊的域并写入日志的标准化日志格式.而且它还提供更详细的可选域的集合.所以这种格式也比较适合于研究点击流数据.本文采用对ExLF格式进行域扩展来获得学生点击行为的数据.ExLF的域很多,表1仅列出与本文的分析主题相关而所需的日志格式的域:
下文对教务网站服务器上的一条日志进行直观的分析:
#Software:Microsoft Internet Information Services 6.0
#Version:1.0
#Date:2008-05-16 16:00:01
#Fields:date time cs-method cs-uri-stem cs-uri-query cs-username c-ip cs(User-Agent)cs(Referer)sc-statustime-taken
2008-05-16 16:00:05 GET /WebCourse/courseelective/schoolelectivepublic.aspx--
192.168.6.43
Mozilla/4.0+(compatible;+MSIE+7.0;+Windows+NT+6.0;+SLCC1;+.NET+CLR+2.0.50727;+.NET+CLR+3.0.04506;+InfoPath.1;+.NET+CLR+1.1.4322)
http://10.4.12.13/webcourse/login.aspx 200 330

表1 W3C扩展日志格式的部分域描述[1]
该例子中有四条指令,前三条说明该网站的Web服务器采用微软IIS6.0;日志版本使用1.0的ExLF格式;日志文件产生的时间是2008年5月16日16点00分01秒.第四条指令说明日志文件包含的域有date、time、cs-method、cs-uri-stem、cs-uri-query、cs-username、c-ip、cs(User-Agent)、cs(Referer)、sc-status、time-taken,其中域前缀c-表示客户端,cs-表示客户端到服务器端,sc-表示服务器端到客户端.
日志文件的数据记录的第一行说明,用户访问时间是2008年5月16日,16点00分01秒,客户请求命令的方式为GET,客户请求的资源是/WebCourse/courseelective/schoolelectivepublic.aspx,查询为空,访客用户名为空(由于通常用户没有进行注册,故用‘-’符号表示日志中为空的域),客户IP地址是192.168.6.43,访客所用的操作系统为Windows NT 6.0,浏览器类型为微软IE7.0,浏览本网页前访客访问的是http://10.4.12.13/webcourse/login.aspx,HTTP状态码为200,请求完成的时间为330秒.
2 数据预处理模块
点击流数据的预处理技术关系着数据挖掘的质量,是Web数据挖掘中的一个重要的研究方向.其预处理过程一般包括:数据清洗、数据转换、用户识别、用户会话识别、补全路径和事务识别等.
实验数据集:在现实的应用中所涉及的数据应该是几个月、季度甚至几年的庞大数据,本文仅选用某高校教务管理系统服务器上一天的日志文件,记录了从2008-01-02:16:00至2008-01-03:16:00,即24个小时的点击信息,用来直观说明如何从这些点击流数据中挖掘出学生的访问模式和网站的统计分析.
2.1数据清洗
Web日志的清洗工作在很多文献都有讨论[2-3].数据清洗就是要滤掉多余的记录,合并相关数据并从数据集中清除不恰当的或冗余的数据项.本文采用的方法是除去URL中包含后缀为gif,GIF,jpeg,JPEG,jpg,JPG,map,swf,css等与我们分析主题无关的图形、图像、声音文件的日志记录以及删除请求被重定向和标识存在错误的记录,本文中只取状态码以2开头的成功访问的记录.
所选用的日志数据集原始数据共有132497条,根据url字段后缀以及status字段值进行数据清洗后剩余58673条记录,约为原始记录总数的44.28%,所得到的表记为tempclickfact.
2.2数据转换
为便于数据的进一步处理,需确定适当的数据表示形式,为此本文对日志记录中的访问页url进行编号.采用的方法是利用SQL语句:select distict cs-uri-stem from WebLog,从已经数据清洗过的日志表WebLog中选出用户访问过的不同的URL,然后根据网站数据库中的页面维表分别给出页面编号urlid.
通过数据转换,统计出数据集中共有121个不同的页面即url,在处理过程中也统计出各个页面对应的访问次数num.从结果可以看出,urlid为58的页面在该时间段内的点击量为9876次,为访问次数最多的页面.
2.3用户识别
由于本地缓存、代理服务器和防火墙的存在,导致Web日志无法精确记录用户的浏览行为,也是用户识别的困难所在.为了更准确地确定用户,利用结合IP地址和日志中的启发式信息对用户及用户访问事务进行识别.例如,对于IP地址相同的日志记录,可以观察日志记录中主机代理cs(user-agent)这个字段,这个字段记录了访问者使用的浏览器或操作系统的版本.如果该字段所记录的浏览器或操作系统不一样,那么就可以假设是不同的用户使用了同样的IP地址.
用户识别后得到1464用户,根据所得到的users表以及url表,进一步对表tempclickfact进行处理,得到表clickfact,即点击事实表,部分数据如图1所示,其中字段clickid为点击编号.
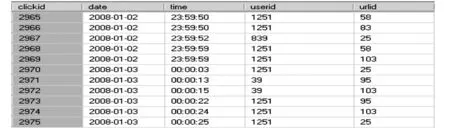
图1 clickfact表
2.4用户会话识别
本文采用基于时间的启发式方法进行会话识别,即同一用户依次发出相邻的页面请求之间的时间间隔如不超过时间阈值,那么这两个页面请求属于同一个会话.如果一个用户的日志记录跨度超过时间阀值,那么可以猜测,该用户多次访问了该网站.本文将时间阀值设定为20分钟,时限的选择可以通过日志的统计分析来确定.当判断不属于同一个会话时,在数据库表中添加一个域会话编号sessionid,用于存储进行识别后的会话标识.通过用户会话识别,得到2062个会话,在图2 sessionfact中,其中字段surlid表示会话入口页面编号,字段furlid表示会话结束页面编号,字段lasttime为会话的持续时间,sessionid为会话编号.
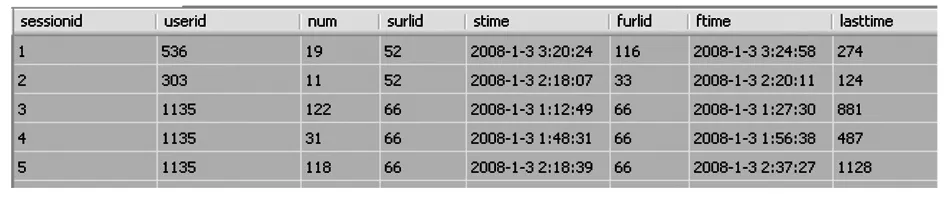
图2 sessionfact表
经过上述四个步骤的数据预处理后,按照Raphl Kimball在《数据仓库工具箱》中提出的维度建模方法指导设计数据仓库,分三个步骤逐步建立点击流数据仓库.
3 基于分析主题的挖掘与结果展示
在点击流数据仓库建成后,希望通过OLAP分析和数据挖掘了解网站的运行情况和对用户的行为进行深入分析.因此建立的点击流数据仓库应支持网站流量统计,实现用户行为分析这两个目标(分析主题).本文通过在所建立的数据立方体结构中,利用多维扩展语言(MDX)分析数据和借助OLAP对数据立方体进行切片、切块、下钻、上卷及旋转等操作.
为了给网站管理员、网站运营商提供更全面的统计信息及用户行为模式,本实验中通过图表、透视图等直观的方式展示分析结果.
3.1统计分析
(1)某时段网站的总点击量.该网站在2008-01-02:16:00至2008-01-03:16:00时段的总点击量为58673次.
图3显示各个页面每天的点击次数,图中以urlid为x轴,date为y轴,clickid的计数为z轴,urlid表示页面编号,date表示日期,clickid表示点击编号.从图中可以很明显看出各个页面的访问情况,比如在2008-01-02,urlid为46的页面被访问971次,为访问最频繁的页面.在实际应用中,可以以年、月等为y轴,反映出较长一段时间内的访问情况.
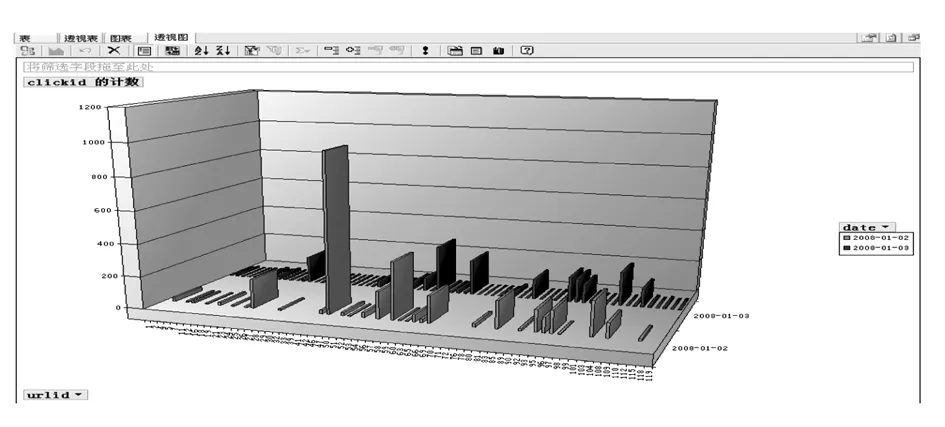
图3 各网页访问频率透视图
(2)某时段网站的总访问人次.该网站在2008-01-02:16:00至2008-01-03:16:00时段内的总访问人次为2062人次.图4显示按时段会话次数,即访问人次进行统计.从中可以看出8时到11时以及13时到14时为访问人次比较多的时段.
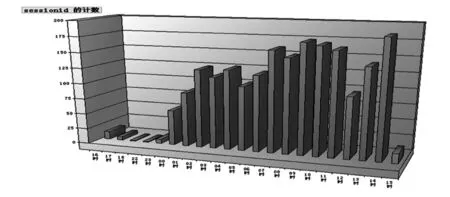
图4 各时段访问人次透视图
(3)访问最频繁与访问量最少的页面.在数据转换中我们得到的表中,可得出urlid为58的页面总共有9876次,为访问最频繁的页面.
通过Analysis Servcies MDX查询统计出总访问量为前三名的页面:
Select
Topcount([url].[All].children,3,[measures].[urlid])on columns,
[measures].[urlid] on rows
From click_cube
与上同理,统计出urlid为120的页面在实验时段内总访问次数为2次,为访问量最少的页面.
(4)某时段访问网站的总时间.通过SQL语句对表sessionfact进行简单运算,可以得到在实验数据集的时段内,总访问时间为592757秒,约164.64小时,平均访问持续时间为287秒.
3.2用户行为分析
(1)用户喜欢从哪个页面开始访问网站.通过MDX查询可以得到1595次的会话在surlid为60的页面开始会话.
通过OLAP分析,得到从urlid为60~70的页面开始的会话有1668次,约占总会话次数(2062次)的81%.由此,可以给我们发布一些重要通知时选择哪个网页提供决策支持.
(2)用户一般在哪个页面结束了访问.同上,通过MDX查询可以得到541次的会话在furlid为93的页面结束会话,480次的会话在furlid为66的页面结束会话.其中在furlid为57~67的页面结束的会话有748次,在furlid为90~100的页面结束的会话有637次,总计约占总会话次数的67.2%.由此,可以考虑是这些网页设计存在缺陷还是是学生已经达到访问的目的离开了本网站.
(3)平均访问时间.图5展示了会话持续时间分布图,从图中可以很直观发现有1003次的会话,其会话持续时间在0~119S;285次的会话,其会话持续时间落在120~239S.对于网站来说,通过会话长度可以判断出用户对该网站的兴趣程度,帮助网站的进一步改善.

图5 会话持续时间分布图
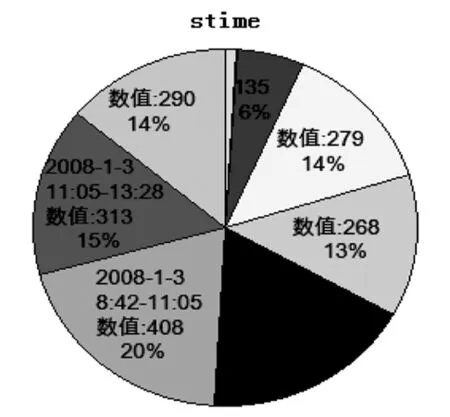
图6 会话开始时间分布图
(4)用户一般喜欢在哪个时间段访问该网站.通过图6可以很直观看出在各时间段的访问人次比例,其中在2008-1-3的08:42~11:05开始的会话所占比例为20%,相对而言为访问人次最多的时间段.图中,stime表示会话开始的时间,数值为相应的时间段内的会话总数(访问人次数),百分比为对应时间段内的访问人次数占总时间内的访问人次的百分比.
4 小结
本文引入了数据仓库技术和数据挖掘技术对教务管理网站的web日志进行挖掘,实现了网站的统计分析和用户行为分析,获取了潜在的有用信息.高校可以通过对这些信息数据进行深层次分析,了解网站的经营状况、了解用户行为,让学校网站更好地为全校师生服务.
参考文献:
[1]Mark Sweiger Jimmy Langston.点击流数据仓库[M].陆昌辉,译.北京:电子工业出版社,2004.
[2]李双双,陈毅文.点击流:一种研究网上消费者的新范式[J].心理科学进展,2007,15(4):715-720.
[3]张波,巫莉莉,周敏.基于Web使用挖掘的用户行为分析[J].计算机科学,2006,33(8).
