SQL Server 2008 R2贝叶斯算法研究
2011-06-06汪明,张征
汪 明,张 征
(1.中国矿业大学 管理学院,江苏 徐州 221116;2.保定市国土资源局新市区分局,河北 保定 071000)
0 引言
随着信息技术和数据库管理系统的快速发展,政府和企业现已拥有海量的数据。事实表明,在海量的数据中往往隐藏着非常有价值的信息,这些信息在政府和企业的各项决策中具有重要的参考价值。因此,探讨如何从海量的数据中发现有价值的信息,对于政府和企业来说具有非常重大的现实意义。
数据挖掘[1]是数据库技术、人工智能、机器学习和统计学等学科相结合的产物。所谓数据挖掘,就是从数据库海量数据中提取出隐含的、事先未知的、具有潜在应用价值的信息。贝叶斯分类算法在众多数据挖掘方法中占有重要的地位,在金融、营销、客户关系管理、医疗、生物、电信等领域中都有广泛的应用。
国内外很多专家学者都对贝叶斯分类算法进行了大量的研究,但绝大部分是对贝叶斯分类算法的原理进行研究。国内目前对于在SQL Server 2008 R2平台下的贝叶斯分类算法研究还比较少。随着数据挖掘在商业环境中的应用越来越多,为企业提供一个有效、实用且易于使用的数据挖掘工具就显得非常重要。而微软最近推出的SQL Server 2008 R2就是一个很好的数据挖掘工具。
1 贝叶斯分类基本原理
微软的贝叶斯算法是朴素贝叶斯分类算法。数据分类的目的是预测样本数据的分类标签。贝叶斯分类是基于贝叶斯定理的统计学分类方法,同时也是一种分类监督学习方法。理论上朴素贝叶斯分类的应用前提为样本的属性是相互独立的,而在实际应用中满足这种条件的情况并不多见,但朴素贝叶斯分类算法仍然能取得非常好的效果。
假设数据库中有一数据集需要用贝叶斯分类方法分类,设数据集中共有m个类别标签:C={C1,C2,C3,…,Cm}。现有一个未分类的对象具有属性{A1,A2,A3,…,An},当条件概率 P{Ck|A1,A2,A3,…,An}=max{P{Ci|A1,A2,A3,…,An}},其中 Ci∈C,Ck∈C,就可以判定该待分类对象属于Ck类别。首先利用贝叶斯公式:

计算所有类别的后验概率,然后从中选取最大的后验概率,即可判定对象的类别。由前所述,朴素贝叶斯算法假设各属性是独立的,所以有:
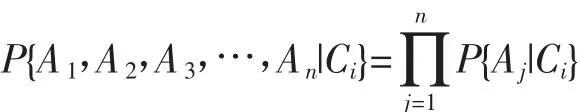

其中ucj表示数据集中属于类别Cj且属性Ac所在属性的数值均值,σcj表示数据集中属于类别cj且属性Ac所在属性的数值标准差。为了便于理解,下面以一个实例来说明如何根据已有的数据(训练集)来判别新对象的类别。假设有一个顾客购物情况表(如表1所示),现要根据贝叶斯分类算法判断顾客{收入=120 000,婚姻状况=“已婚”,是否有车=“是”}是否会在超市买商品。
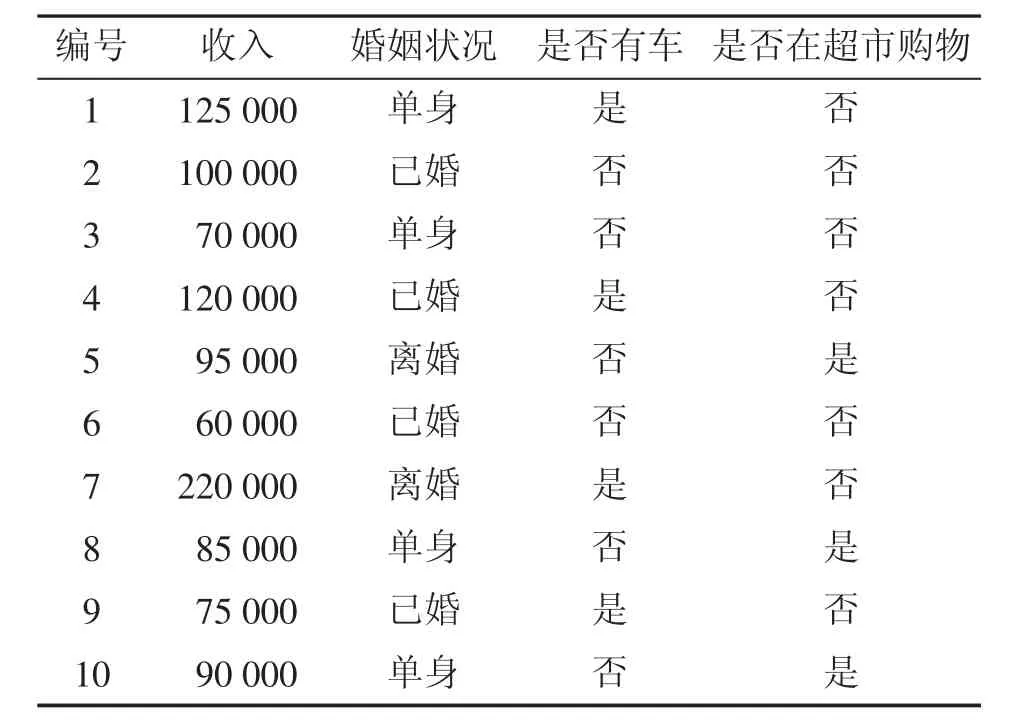
表1 顾客购物情况表
将表1的数据作为贝叶斯分类算法的训练集,可以得知:数据集中“是否在超市购物”字段的类别有2种,即{是,否}。待判顾客具有属性{收入=120 000,婚姻状况=“已婚”,是否有车=“是”}。由表 1可知(为了解决零频率问题,在计算概率时为每个计数加 1):


2 贝叶斯分类实例研究
为了验证微软SQL Server 2008 R2贝叶斯分类算法的有效性,将上面表1的数据保存在SQL Server 2008 R2数据库服务器上。用SQL Server Business Intelligence Development Studio工具新建一个名为“Bayes分类数据挖掘”的Analysis Services项目。在解决方案资源管理器中通过向导为项目定义“数据源”和“数据源视图”。然后,选择“Microsoft Naïve Bayes”数据挖掘技术创建数据挖掘结构和模型。
Microsoft Naive Bayes算法是一种可以快速生成并且适合预测性建模的分类算法,该算法仅支持离散属性或离散化属性(前面提到连续型属性一般按正态分布来计算,但是微软的贝叶斯算法采取将连续属性离散化的方式来处理),而且在给定可预测属性的情况下,它将所有输入属性都按独立属性处理。
在创建测试集时,由于本实例数据量很少,将测试数据百分比设置为0%。创建的挖掘模型如图1所示。
贝叶斯算法参数“MINIMUM_DEPENDENCY_PROBABILITY”用于指定输入属性和输出属性之间的最小依赖关系概率。此值用于限制算法生成的内容的大小。该属性可设置为介于0和1之间的值,该值越大,模型中的属性数就越少。由于本实例数据量很少,需要调整参数值到0.01,否则在依赖关系图中将不会显示除预测属性外的其他属性。在部署和处理完数据挖掘模型后,在挖掘模型预测界面中将查询切换到文本查询视图,然后通过编写以下脚本来预测顾客{收入=120 000,婚姻状况=“已婚”,是否有车=“是”}是否在超市买商品。

图1 顾客购物表挖掘结构图


该脚本返回的预测结果如图2所示。可见其预测结果与理论计算结果相同。

图2 贝叶斯算法预测结果
若在创建测试集时,将测试数据百分比设置为30%。贝叶斯算法挖掘模型取名为“顾客购物表3-7”,在挖掘模型预测界面中将查询切换到文本查询视图,然后通过编写以下脚本来预测数据源的全部记录。


该脚本返回的预测结果如图3所示。可见其预测结果与实际结果相同。从上面两个例子可以看出,SQL Server 2008 R2平台下的贝叶斯算法是有效的,且具有相当高的准确性。
其实,预测模型的准确性可由数据挖掘提升图来判断,图4是将测试数据百分比设置为30%的贝叶斯挖掘模型的提升图。
从图中可以看出,理想模型和贝叶斯数据挖掘模型预测的结果几乎是重合的,说明预测的准确率很高。通过观察不同算法参数和测试数据百分比配置下挖掘模型的准确率,可以逐步获得令人满意的挖掘模型。

图3 30%测试数据下的贝叶斯算法预测结果

图4 30%测试数据下的贝叶斯挖掘模型提升图
3 结束语
在理论上,朴素贝叶斯分类与其他分类算法相比,具有最小的错误概率。实践表明,朴素贝叶斯分类算法可以与复杂的神经网络等分类算法相媲美,甚至在各属性独立性假设不满足的情形下,朴素贝叶斯分类效果依然良好。SQL Server 2008 R2为企业提供了一个高性能的数据库平台,它提供的数据挖掘功能易于使用,且能承载企业级海量数据的挖掘任务。通过实例研究表明,微软贝叶斯分类挖掘算法是有效的,且具有很高的正确率。
[1]刘进峰.动态关联规则的理论与应用研究[D].浙江:浙江大学,2006.
[2]谢斌.朴素贝叶斯分类在数据挖掘中的应用[J].甘肃联合大学学报(自然科学版),2007,28(4):79-91.
[3]张亚萍,张震.基于贝叶斯分类算法的参赛情况预测系统[J].淮北煤炭师范学院学报(自然科学版),2007,28(1):58-60.
[4]董立岩,李真,阎鹏飞.基于贝叶斯分类器的重大危险源辨识[J].吉林大学学报(理学版),2009,47(4):801-804.
[5]赵静,刘培玉,陈孝礼.结合特征和非特征信息改进Naive Bayes及其应用[J].计算机应用研究,2011,28(2):514-516.
[6]廖开际,刘其辉,易聪,等.基于贝叶斯网的知识集群研究[J].计算机应用研究,2011,28(3):828-830.
[7]张雯,张化祥.属性加权的朴素贝叶斯集成分类器[J].计算机工程与应用,2010,46(29):144-146.
[8]Gou K X,Jun G X,Zhao Z.Learning Bayesian network structure from distributed homogenous data[C]//SPND.Chicago:IEEE Computer Society,2007:250-254.
