基于FIOS类型的Montgomery双域模乘器设计*
2011-06-03杨晓辉王雪瑞张永福
杨晓辉 ,王雪瑞 ,秦 帆 ,张永福
(1.信息工程大学 电子技术学院,河南 郑州450004;2.河南工程学院,河南 郑州 451191)
随着计算机网络的发展和普及,信息安全问题越来越多地被人们所关注。公钥密码体制有效地解决了在公共信道上保护信息的抗抵赖性、身份认证、密钥分发等问题。椭圆曲线密码 ECC(Elliptic Curve Cryptography)是一种基于椭圆曲线离散对数问题的公钥密码,1985年分别由Miller[1]和Koblitz[2]独立提出。相对于其他公钥密码系统,椭圆曲线密码系统具有计算速度快、存储空间小、带宽要求低等优点,特别适用于各种无线设备和智能卡等计算资源受限的设备,因而受到了人们的广泛关注,成为新一代公钥密码标准。而模乘运算是椭圆曲线加密算法中的核心运算,如何高效地实现模乘运算是当前的一个研究热点。
Montgomery模乘算法[3]是目前应用最为广泛、同时也是最为高效的模乘算法。但Montgomery模乘算法存在的主要问题是模乘运算数据长度固定,不具备可配置性。另一个缺陷就是模乘运算的数据路径延迟达到2级n位全加器的延迟,极大地限制了电路的时钟频率。Bajard将Montgomery模乘算法扩展到剩余数系统RNS(Residue Number System),并进一步提高了模乘的性能,但数系转换硬件实现复杂,并且不支持双域运算[4]。在对算法进行硬件实现时,一般是将运算数据分成若干个字,对运算数据按字进行处理,以提高算法并行度和电路时钟频率,参考文献[5]提出了基于高基阵列的Montgomery模乘算法。
目前Montgomery模乘运算的扩展和优化实现算法主要可以分为以下四种类型:比特级-完全长度BLFP(Bit-Level Full-Precision)算法;比特级-字级 BLWL(Bit-Level Word-Level)算法;字级-完全长度WLFP(Word-Level Full-Precision)算法,对另一个运算数据按完全长度进行处理;字级-字级WLWL(Word-Level Word-Level)算法。因为BLFP和WLFP类型的算法与原始Montgomery模乘算法存在相同的缺陷,所以考虑到设计高效的模乘运算单元,本文基于BLWL和WLWL这两种类型的算法,结合FIOS(Finely Integrated Operand Scanning)Montgomery模乘扩展算法,提出了一种Montgomery双域模乘器实现方案。结果表明,相比较于传统的Montgomery模乘器,本文的设计减少了近一半的时钟周期数,不仅大大提高了模乘运算速度,而且支持运算长度可配置的两个有限域GF(p)和GF(2n)的模乘运算,提高了模乘处理的灵活性。
1 FIOS类型的Montgomery模乘算法
Montgomery模乘算法按求乘法部分积与约简运算结合方式的不同,参考文献[6]提出了SOS(Separated Operand Scanning)、CIOS (Coarsely Integrated Operand Scanning)、FIOS(Finely Integrated Operand Scanning)、FIPS(Finely Integrated Product Scanning)、CIHS(Coarsely Integrated Hybrid Scanning)这五种不同类型的Montgomery扩展算法,算法详细内容可参阅文献。
五种算法中,在不考虑并行实现算法的前提下,FIOS算法的运算量最少。
1.1 BLWL类型的FIOS算法
为缩短电路数据路径中的延迟,首先将BLWL类型的FIOS算法中的中间变量全部采用TS-TC这样的冗余数表示,以进位保留加法运算完成算法中的加法运算。在算法中以这样的形式表示进位保留加法 (TC,TS)=X+Y+Z。算法中Ai表示A的第i位,B(i)表示B的第i个字,运算数据字长为wbit,字数为s=「n/w,该算法描述如下:
GF(p)上BLWL类型FIOS模乘算法[7]
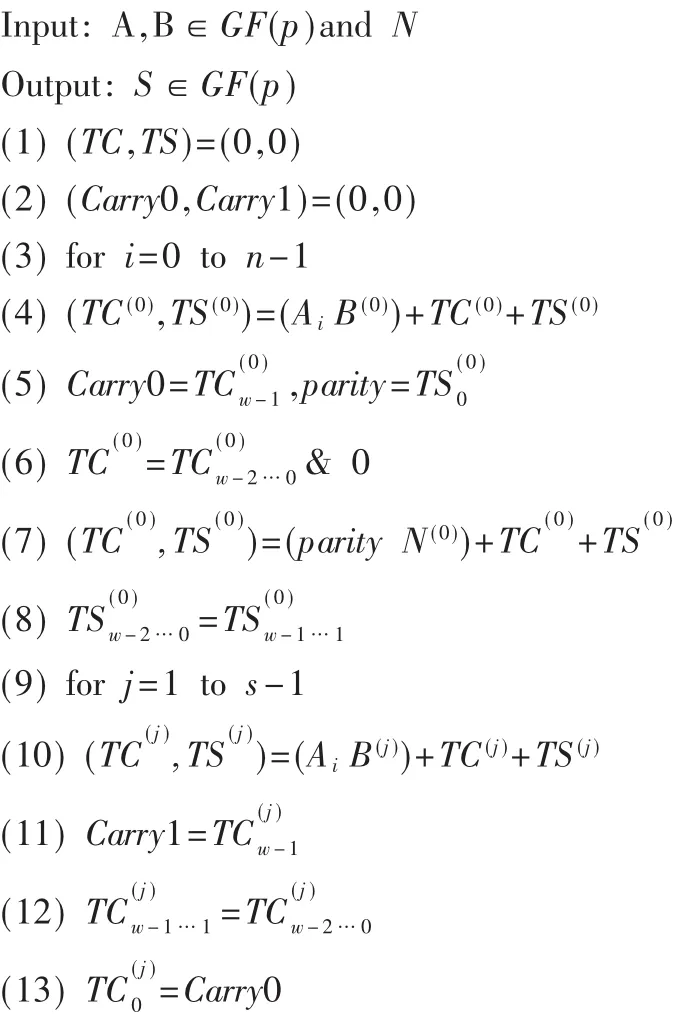

GF(p)的Montgomery模乘算法可以扩展到GF(2n)上来,算法中的加法运算为简单的“异或”操作,没有进位产生。
1.2 WLWL类型的FIOS算法
为进一步缩短运算周期,提高速度,可以将BLWL类型的FIOS模乘算法扩展为WLWL类型的算法。WLWL类型算法每次对两个运算数据和模数的一个字进行扫描,所以相比较于BLWL类型算法,可以进一步缩短运算所需周期。该算法在缩短运算周期的同时,由于采用字乘字的乘法器增加了电路的面积和复杂度。算法中Ai表示A的第i个字,运算数据字长为wbit,字数为s=「n/w,W=2w,modW,该算法同样可以扩展到GF(2n)上来,其中加法运算为简单的“异或”操作。
算法描述如下:GF(p)上WLWL类型FIOS模乘算法[8]
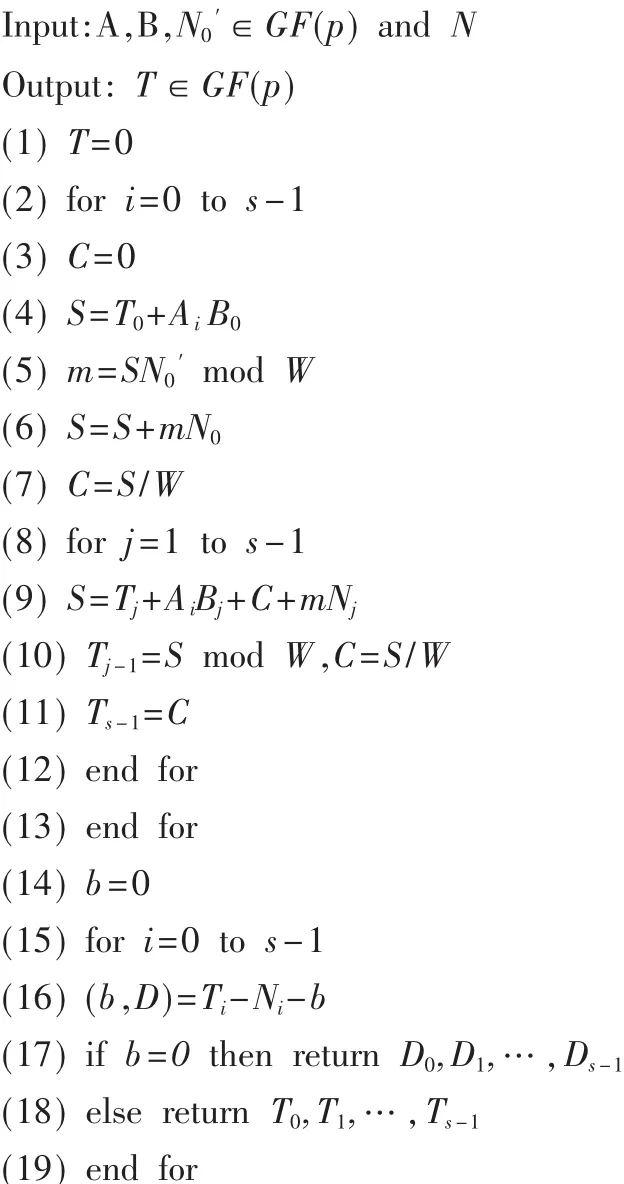
2 两种算法的流水线组织结构分析
2.1 BLWL类型算法的流水线组织结构
通过对算法1的分析研究,可以采用多处理单元的流水线结构来实现算法。流水线运算流程如图1所示,每一竖列表示一级流水线,每一横行表示一个运算周期,其中X和Y为运算处理单元。从图1可以看出,在外部循环i=0和内部j=1这两个过程经两个时钟周期完成后,才能够得到下一级流水线处理单元PU所需的(C(0),S(0)),即此时才开始对A的第 2个 bit进行扫描。也就是说在第i个外部循环的第1个内部循环经两个时钟周期完成后才可以开始第i+1个外部循环的运算,所以采用这种流水线组织形式,每级流水线之间的延迟为两个时钟周期。因为流水线每级间存在两个时钟周期的延迟,所以需要两级寄存器用来存储中间结果,而且这种流水线组织形式会增加时钟周期数,降低运算速度。
采用以上的流水线组织结构,每级流水线之间存在两个时钟的周期延迟,这是因为必须在上一级流水线的第2个运算单元计算出S(1)之后,才能得到下一级流水线的第1个运算单元要进行计算所需要的S(0),此时下一级的流水线才能够开始。实际上在上一级流水线的第1个运算单元计算完成后,已经产生新的S(0)的低w-1 bit,第2个运算单元运算完成后才产生S(0)的最高一个bit。所以每一级流水线的第一个运算单元可以采用由上级流水线运算单元产生的S(0),即采用(0,)和(1,)分别进行计算,得到两个结果,由上级流水线的第2个运算单元产生的这一bit数对这两个数据计算得到的结果进行选择。经过改进的流水线组织如图2所示。

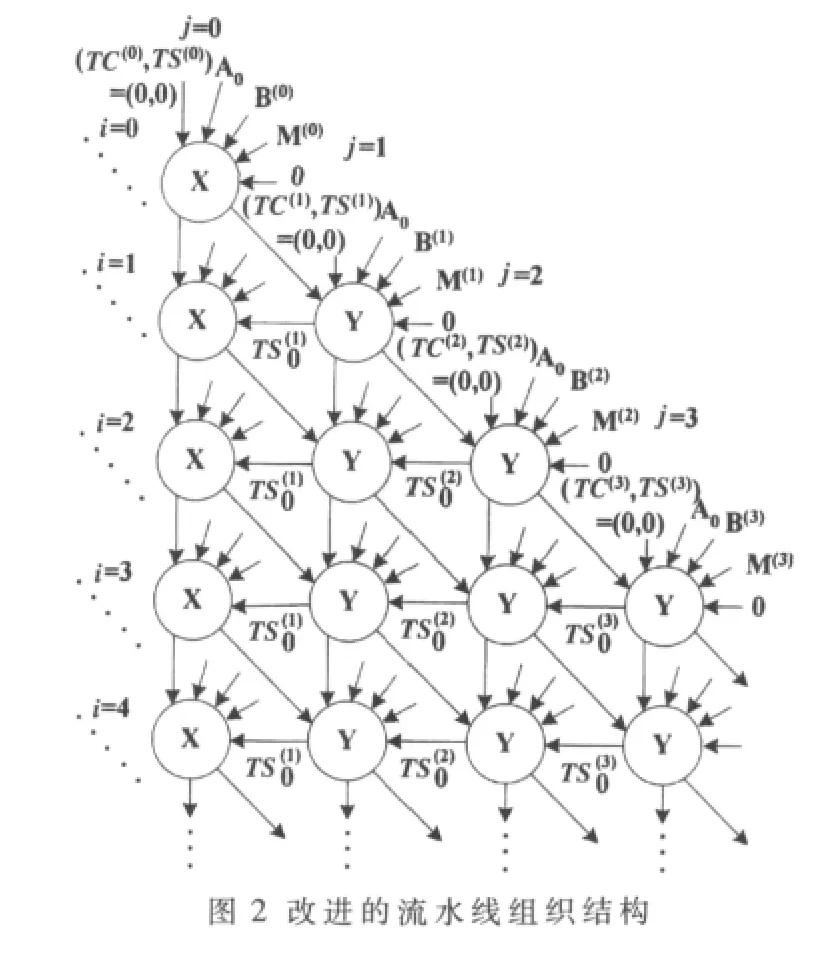
可以看出,采用这样的流水线组织结构,两级流水线之间的时钟延迟已经由2个时钟缩短为1个时钟。所以在存在足够的运算单元的条件下,完成两个位数据的模乘运算需要n+e-1个时钟周期,而采用改进前的流水线组织结构则时需要2n+e-1个时钟周期[4]。
2.2 WLWL类型算法的流水线组织结构
通过对算法2的分析研究,模乘运算的多处理单元流水线运算流程中,在i=0及j=1这两步运算完成后,得到下一级流水线处理单元X进行运算所需的T0,这时开始进行由A的第2个字对B的逐字扫描。也就是说在第i个外部循环的第1个内部循环完成后可以开始进行第i+1个外部循环。所以说对于WLWL类型算法,在不同的i循环之间存在并行性,采用多处理单元流水线的设计方式可以提高运算效率,相邻两级流水线之间的延迟为两个处理单元的运算时间。
若流水线中有不少于k=「s/2个处理单元,流水线运算将连续地进行下去,不会因为没有空闲的处理单元而停顿部分时钟周期,所以完成两个n位数据的模乘运算需要3s-1个时钟周期。当电路中的处理单元少于k=「s/2个,流水线运算将会因为没有空闲的处理单元而停顿部分时钟周期,此时完成模乘运算需要(「n/2k-1)(「s/2+1-k)+3s-1 个时钟周期。
3 算法的硬件实现
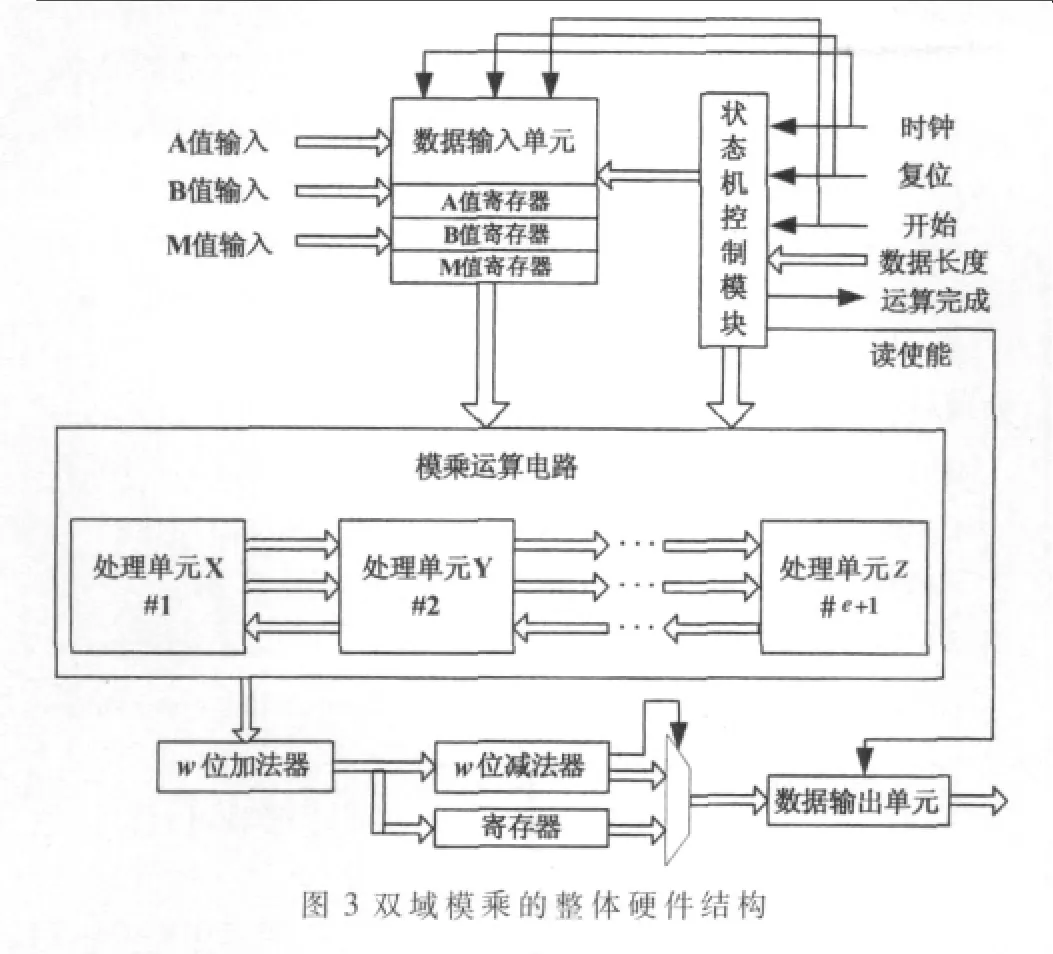
根据算法1和算法2以及前面对于BLWL算法和WLWL算法流水线结构的分析,基于FIOS类型Montgomery双域模乘器的整体硬件实现结构如图3所示。
图中,双域模乘器整体结构主要由数据输入和输出、状态机控制、模乘运算等单元构成。数据的输入和输出单元与外部的数据接口宽度可以根据具体的应用环境进行灵活设计,外部数据的写操作和输出结果数据的读操作均在状态机控制模块的控制下完成,数据输入单元中各个操作数寄存器的数据输出同样也在状态机控制模块的控制下完成,所有控制信号由输入的数据长度值产生。
模乘运算电路的主要功能单元有流水线处理单元X和Y,对于BLWL算法的模乘器需要每级流水线最后一步移位运算的移位单元Z;而对于WLWL算法的模乘器则不需要。对于BLWL算法的模乘器,模乘运算电路每个时钟输出w bit的TS和TC值,若进行的是二进制域上的运算,那么TS直接就是最终运算结果,进行素数域上运算时,需要将TS和TC值相加得到最终运算结果。模乘单元每个时钟周期输出w bit的TS和TC,所以只需要一个w bit的加法器与模乘单元按流水线方式进行计算。对于WLWL算法的模乘器,模乘运算单元的整体电路中不需要位加法器对冗余表示数进行数据转换。
4 性能分析和比较
在设计可配置模乘电路时,考虑到NIST推荐的有限域长度,并根据以上对模乘运算流水线组织结构的分析,本文在BLWL类型模乘运算单元电路中设计1个处理单元X和17个处理单元Y,在WLWL类型运算单元电路中设计1个处理单元X和8个处理单元Y。这样两种模乘运算单元均支持长度在163~571 bit之间任意数据的运算,并保证流水线运算连续进行。基于运算部件的关键路径延迟与运算速度折衷的考虑,选择32作为运算数据字长和电路接口宽度。将以上设计的模乘器用VerilogHDL硬件语言进行代码描述,并使用ModelSim SE 6.0c进行功能仿真。在功能仿真正确后,使用Synopsys公司的 Design Complier在 SIMC 0.18 μm工艺库下进行综合。
对于BLWL算法,采用改进的流水线组织结构模乘单元实现结果如表1所示。表格中的周期数为模乘运算和最终进行字加法运算以及减法运算共需的周期数。
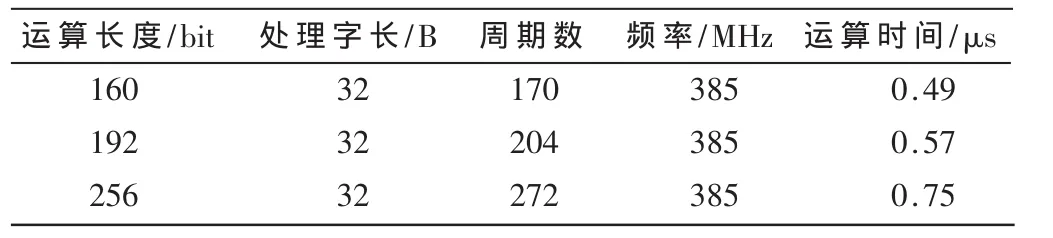
表1 BLWL算法改进流水线组织结构实现结果
由表1得出,采用改进的流水线组织结构设计模乘单元,能够达到与改进前流水线组织结构相近的时钟频率,并且由于减少了近一半的时钟周期数,其模乘运算时间也大为缩短。
对于WLWL算法,由于字与字的乘法运算和加法运算的延迟较大,并且不能将这几级的乘法和加法运算做并行化处理,所以为提高模乘电路的时钟频率和匹配流水线运算时序,本文对处理单元X和Y均采用五时钟设计,即处理单元完成一次运算需要5个时钟周期。实现结果如表2所示。
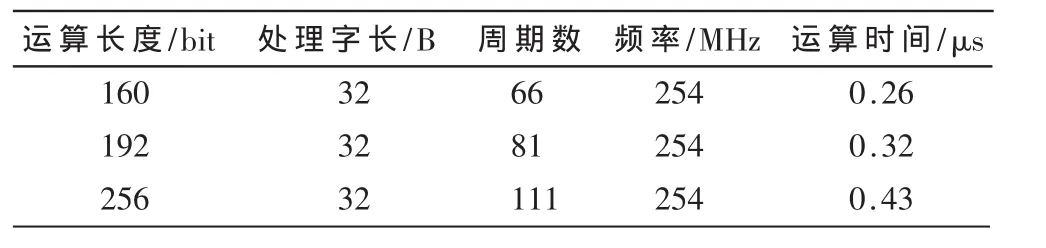
表2 WLWL算法流水线组织结构实现结果
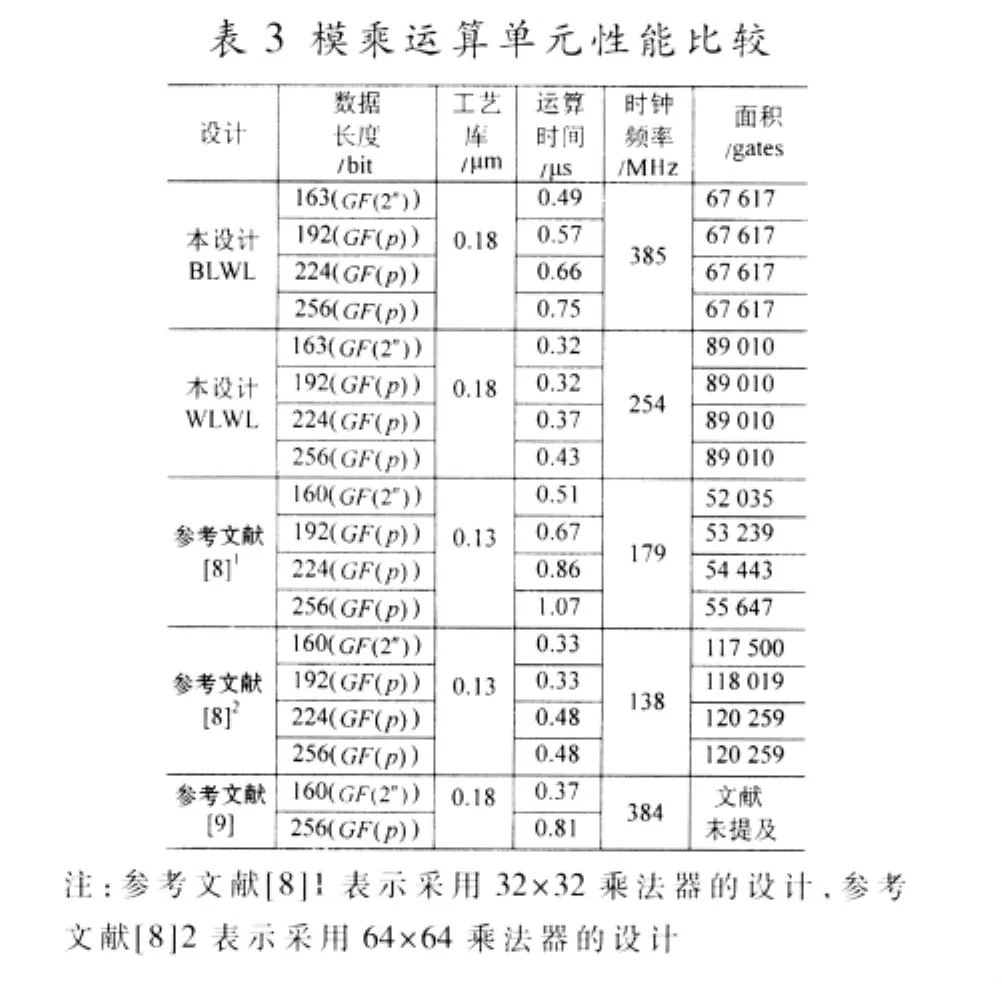
由于电路的综合环境和仿真平台不同,只能将本文设计与其他一些国内外先进设计作大致的比较。表3列出了本文设计的模乘器与其他文献中的模乘运算单元的性能比较。因为这些参考文献中的模乘运算单元最高支持256 bit数据的运算,为进行比较,对本文设计同样考虑可以最高支持256 bit数据运算时的情况。如表3所示,与参考文献[8]中采用乘法器的设计相比,WLWL类型模乘运算单元在运算速度方面略有劣势,但在电路面积方面具有优势,若采用相同的工艺,WLWL类型模乘运算单元电路时钟频率会更高,因而运算速度会更优。与参考文献[8]中采用乘法器的设计相比,BLWL类型模乘运算单元虽然电路面积较大,但在运算速度方面具有优势。
本文基于FIOS的Montgomery模乘算法,设计了BLWL和WLWL类型的双域模乘运算单元。根据以上的分析和比较,本文设计的两种模乘运算单元在电路面积和运算速度方面各有优势,而且具有运算长度可配置功能,支持目前椭圆曲线密码576 bit长度以内的有限域模乘运算具备了很大的灵活性,满足现代通信网络对公钥密码处理高速性和灵活性的要求。
[1]MILLER V S.Use of elliptic curves in cryptography[C].Proc.of CRYPTO’85.Berlin:Springer-Verlag,1986:417-426.
[2]KOBLITZ N,Elleptic curve cryptosystems[J].Mathematics of computation,1987,48(4):203-209.
[3]MONTGOMERY P L.Modular multiplication without trial division[J].Mathematics of Computation,1985,44:519-521.
[4]BAJARD J C,KAIHARA M,PLANTARD T.Selected RNS bases for modular multiplication[J].IEEE computer society,2009,20:25-32.
[5]胡进,何德彪,陈建华.基于高基阵列乘法器的高速模乘单元设计与实现[J].计算机工程与设计,2010,31(6):1202-1204.
[6]KOC C K,ACAR T.Analyzing and comparing montgomery multiplication algorithms[J].IEEE.Micro,1996,16(3):26-33.
[7]SAVAS E,TENCA A F,KOC C K.A scalable and unified multiplier architecture for fields GF(p)and GF(2m)[C].Cryptographic Hardware and Embedded Systems(CHES 2000).New York:Springer-Verlag,2000:1-20.
[8]SATOH A,TAKANO K.A scalable dual-field elliptic curve cryptographic processor[J].IEEE.Transactions on Computers,2003,52(4):449-460.
[9]史焱,吴行军.高速双有限域加密协处理器设计[J].微电子学与计算机,2005,22(5):8-12.
