自然语言信息隐藏通用算法
2011-06-01吴建涛房鼎益靳艳萍
吴建涛,房鼎益,靳艳萍,何 路
(1.西北大学信息科学与技术学院,陕西西安 710127;2.陕西华县经贸局,陕西渭南 714100)
随着数字产品的广泛应用,信息隐藏技术逐渐成为数字安全领域的重要研究方向。所谓信息隐藏是将秘密信息隐藏在非机密的载体内容中,载体形式可以是视频、音频、图像或文本文档等。主要研究如何对秘密信息增加一层伪装,使得秘密信息的传输不引人注意,从而实现隐蔽通信[1]。
自然语言信息隐藏技术利用自然语言处理技术对文本内容进行分析,得到文章中可以替换的文字片段,如单词、句子等,通过改写或替换文字片段进行信息隐藏。根据操纵的语言单位不同,可以分为基于词汇的信息隐藏、基于句法的信息隐藏和基于语义的信息隐藏。
以自然语言为内容的信息交换是人们交流信息的主要方式,文本文档根据其应用需求不同,对信息隐藏方案的性能要求也不尽相同。如军事部门、政府机关、国家安全部门以及一些商业机构对文本的安全性要求较高。通过在文本中嵌入数字指纹,可以在机密泄漏后追踪泄密者。而在电子书籍、通讯稿、新闻稿等文本载体中嵌入数字水印可以提供版权保护。在电子商务,数字图书馆等领域,文档在拷贝分发过程中需要确定其内容是否被篡改或伪造,这时可以通过嵌入脆性水印来进行数据完整性认证和版权验证。
1 现有文本信息隐藏算法分析
通过对现有自然语言信息隐藏算法的分析,其存在如下问题:
(1)隐藏容量。
在进行秘密信息嵌入时,根据载体文本的篇幅长短以及行文风格不同,文本能够为信息隐藏技术提供的隐藏空间也不一样。如在版权保护领域,通讯稿、新闻稿等篇幅较短的文本,一般能够提供的隐藏空间非常有限,而且容易被攻击者找到从而破坏水印信息。而且篇幅较长的小说中,为防止局部内容的抄袭,需要在文章中多个地方重复嵌入水印信息,来提供版权保护。但现有的文本信息隐藏算法还无法提供足够的隐藏容量来满足不同的应用需求。
如现有的基于同义词替换的文本信息隐藏算法,需要用到同义词词库。而目前还没有完全适合信息隐藏算法的大型同义词库。同义词库中同义词集太少,导致同义词替换算法的隐藏容量无法满足嵌入要求。因此,迫切需要建立全面、权威的同义词库来提高隐藏容量。
而现有的句法变换信息隐藏算法,在文本中嵌入一个字符,按照ASCII编码方式,一个字符占8个二进制bit位。以文献[18]中的句法变换方法为例,将可变换句子分为“标识句”和“水印句”。如果一个“水印句”只承载一个比特的信息,嵌入一个字符至少需要16个句子。若将该技术应用于版权保护,需要在文本中嵌入作者信息,以30个字符为例,文本中至少需要480个可变换的句子。于是,在新闻稿件,短篇小说等篇幅较小的文本中嵌入作者信息就变得不现实。
(2)隐藏算法的通用性。
如使用同义词替换算法在文学著作中嵌入秘密信息,由于词语的使用存在少许差异,所以对原文的表达力会造成影响,容易被察觉,从而使秘密信息的隐蔽性得不到保证。再如,对于网络小说在网络中传播等攻击普遍存在的应用场景,文本在传递过程中会被大量且多次修改,如果采用简单的从左向右向文本中嵌入秘密信息,对于文本的简单修改,就有可能打乱秘密信息的同步信息,比如将原先的秘密信息由“01000100”,改变为“1000100”,从而导致提取出的秘密信息完全失去意义。
2 自然语言信息隐藏抽象算法
2.1 载体单元的概念
目前的自然语言信息隐藏算法只是使用文本中某一种文字片段进行信息隐藏,而其它文字片段并没有得到有效利用。如基于同义词替换的信息隐藏算法只使用文本中可以替换的同义词。基于句法变换的信息隐藏算法只使用文本中可以变换的句子。从根本上讲,无论单词还是句子都是文本的一个语义单元,只是大小不同而已。对于隐藏编码而言,这些文字片段都是承载秘密信息比特位的语义单位。如果将多种变换方法应用到同一个信息隐藏算法中,则可以极大地提高隐藏容量。而且多种文字片段混合使用,也提高了隐藏算法的鲁棒性,使得攻击者针对某一类变换方法的攻击成功率大大降低。
为抹去不同自然语言处理技术的不同,实现多种自然语言处理技术的协同工作,提出载体单元的概念。载体单元的定义如下:
对于特定自然语言处理技术,将可以做语义不变替换的文字片段称为载体单元。
载体单元作为一个抽象概念,对不同的自然语言处理技术具有不同的意义。例如对于同义词替换技术,载体单元即具有同义词的词语;对于句式变换技术,载体单元即可以进行句式变换的句子。这样无论在信息隐藏中使用何种自然语言处理技术,均可以将其可处理的文本统一作为载体单元。
由于载体单元是一个抽象概念,所以在程序中以接口的形式定义它。其属性列表如表1所示。
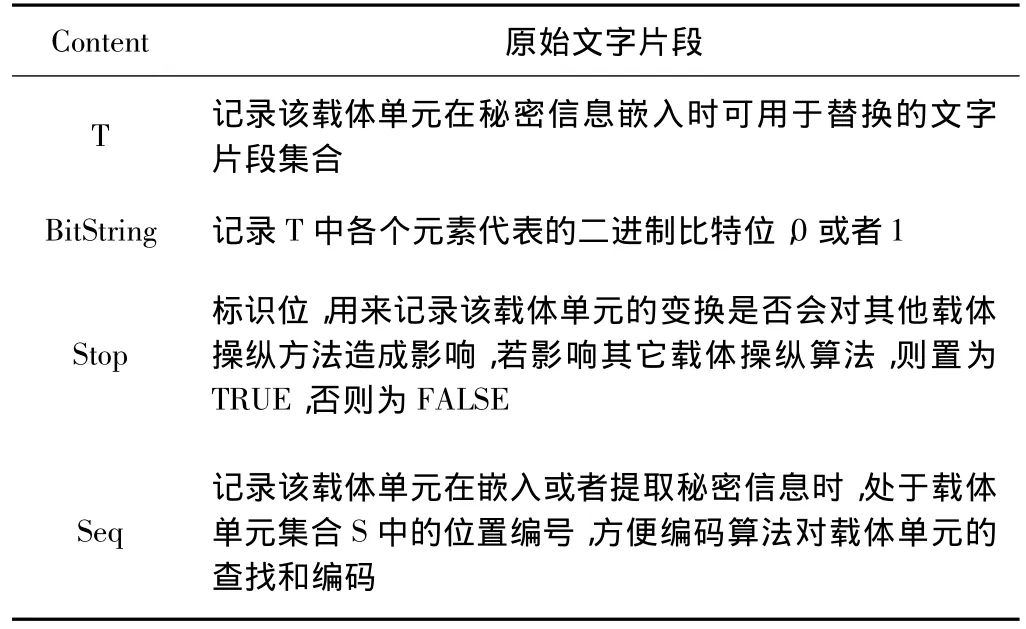
表1 抽象载体单元属性列表
2.2 算法的分离
以载体单元的概念为纽带,可以进一步将自然语言信息隐藏算法分离为载体操纵算法和隐藏编码算法。现有的自然语言处理技术,主要关注与对于文本进行变换,没有关注隐藏编码,将隐藏编码算法单独分离出来,有利于实现鲁棒性和隐蔽性更好的隐藏方案,有利于提高系统的扩展性,同时也有利于代码的复用。
2.2.1 载体操纵算法的定义
对于载体操纵算法,需要完成以下功能:
(1)分析文本功能。对于给定文本片段c┃┃┃C,扫描得到c中的对应类型的载体单元,同时对载体单元进行可行变换,将变换结果存储在载体单元Ti的中,将找到的载体单元加入载体单元集合S。并标识在该片段中嵌入信息是否可能会和其他载体操纵算法冲突。即S=Traverse(C)过程的和Transform过程,不同的是,对于特定载体操纵算法未必可以得到S集合的全部,通常只能得到S的一个子集,并且具体实现中,如果两个载体操纵算法在同一个片段中嵌入信息,则可能存在冲突。
(2)嵌入功能。对于给定载体单元和需要嵌入的具体bit,如果是该载体操纵算法对应的载体单元,使用载体单元中定义的可用于替换的文本片段替换文本片段中的相应内容,使之表示给定bit。即Embed ding(Si,Ti,Mg,Pi,ComputeBit,K)。
(3)提取功能。对于给定的载体单元,如果是该载体操纵算法对应的载体单元,分析该载体单元目前表示的bit;并确定在嵌入过程中是否由于当前载体操纵对文本的修改,导致该文本片段中已经不存在其他类型的载体单元。即M1=Extracting(S″,ComputeBit,K)的一个子过程,该过程只处理一个载体单元,并得到对应比特。
2.2.2 隐藏编码算法的定义
对于隐藏编码算法,需要完成以下功能:
(1)确定Ti中每个文本表示的bit。对于已有的载体单元集合S,确定集合中每个元素对应的集合T中的每个元素的bit,将得到的bit串,由对应载体单元记录,即ComputeBit过程。
(2)分组载体单元。确定S中每个元素对应嵌入Mg的哪个分组,即Blocking过程,由对应载体单元记录结果,即pi。
(3)重排序Mg。按照S中每个元素的pi值,将秘密信息进行重新排序,并对空白的位置补充无效字符,使得载体单元集合中第i个元素和秘密信息中第i个分组对应。该过程是为嵌入过程的算法复杂度考虑,即在嵌入过程中,只需顺序地嵌入重新排列后的bit串,不需要再在原有bit串中查找。
(4)恢复M1顺序。与c过程相反,本过程将M1,按照已有载体单元集合中每个载体单元pi的值,恢复其原始顺序,即Recover过程。
(5)编码过程。即对给定秘密信息进行编码和分组,具体过程视不同的编码算法而定。该过程即Encode过程。
(6)解码过程,对于已经提取得到的bit串,按照解码算法将之复原为原始秘密信息的二进制序列,具体过程视不同编码算法而定。即Decode过程。
2.3 抽象算法的设计
2.3.1 嵌入算法
在载体单元、载体操纵和隐藏编码3个接口之下。提出的通用信息隐藏算法可以描述如下:
嵌入信息时,先利用载体操纵算法对文本进行分析,得到文本中所有载体单元,然后对载体单元进行预变换,得到每个载体单元对应的同义集合。然后利用隐藏编码算法对载体单元集合中所有元素进行编码,通过密钥选择对应编码的同义单元来嵌入秘密信息。
提取信息是嵌入的逆过程。提取时,也需要先利用载体操纵算法对含密文本进行分析,得到文本中所有载体单元,然后进行预变换,获得载体单元对应的同义集合。然后利用隐藏编码算法对载体单元进行编码,通过密钥选择载体单元,并获取载体单元对应的比特来还原秘密信息。
对于嵌入过程描述中需要使用到的符号定义如下:
C为原始文本;K为密钥;S为原始文本中提取出来的载体单元集合,类似的S中第i个元素表示为Si;Ti为可以替换第i个载体单元的文本的集合;M为需要嵌入的秘密信息;Mg为分组并编码后的M,由若干个分组组成;Pi为第i个载体单元需要对应嵌入Mg的第几个分组。
抽象嵌入过程描述如下:
(1)分析文本。S=Traverse(C),S={S0,S1,…,Sn}。即使用某种或者某几种自然语言处理技术分析文本,得到C中所有的载体单元。S中各元素可能是不同类型的载体单元,例如S0对应文本中一个可以替换为其同义词的词语,而Si对应的却是文本中的一个可变换句式的句子。

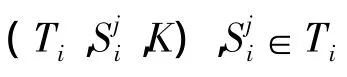
(4)分组载体单元。考虑到分组编码的需求,需要对载体单元进行分组。Pi=Blocking(Si,K),Pi∈N*。该函数返回值为载体单元Si需要对应嵌入Mg的第几个分组。具体应用中,对于不需要分组的算法,则将每组包含的载体单元数量设置为1。基于鲁棒性考虑,分组与载体单元在原文中顺序无关。分组的目的是把秘密信息的比特顺序和实际嵌入的顺序打乱。如果将M顺序的嵌入到S中,秘密信息集中在文本的首部,攻击者可能通过篡改或统计分析等手段破坏或破解秘密信息,所以鲁棒性较差。
(5)分组并编码秘密信息。Mg=Encoding(M,K)。对于秘密信息M进行编码和分组。
(6)嵌入。Embed ding(Si,Ti,Mg,Pi,ComputeBit,K),作为最终嵌入过程就是将Mg的第Pi个分组嵌入到Si中,也就是使用Ti中 Compute(Ti,,K)的值恰好等于Mg的第Pi个分组的元素改写C中的到Si。
(7)生成含密载体。即将嵌入秘密信息后的文本输出。
2.3.2 提取算法
对于该过程描述中需要用到的符号定义如下:
C'为嵌入了秘密信息的文件,即含密文本;K为密钥;S'为含密文本中提取出来的载体单元集合,类似的S'中第i个元素表示为;为可以替换第i个载体单元的文本的集合;M为秘密信息,类似的M1,M2等为对于M的变换形式为第i个载体单元需要对应嵌入的秘密信息的第几位。
则秘密信息的提取过程可以描述如下:
(1)分析文本。S'=Traverse(C'),S'={,,…,}。即使用嵌入秘密信息时使用的自然语言处理技术分析文本,得到C'中所有的载体单元。
(3)提取。M1=Extracting(S',ComputeBit,K)。这一步从C'中初步提取,得到 bit串M1。此处的ComputeBit与嵌入时使用的ComputeBit函数相同。
(5)恢复秘密信息顺序。M2=Recover(M1,Blocking)即将提取出来的M1恢复到原始的顺序。
(6)解码。M3=Decoding(M2,K)。该过程是对M2解码,得到的M3即提取得到的秘密信息。
3 自然语言信息隐藏平台实现
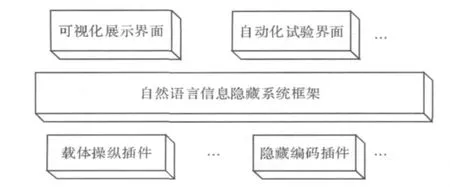
图1 信息隐藏平台框架
在提出的自然语言信息隐藏抽象算法框架下,设计并实现了一个信息隐藏通用平台。该平台的结构如图1所示,最上层是展示层,负责嵌入秘密信息后载体文本的可视化展示,编码方案展示以及提取后的秘密信息解码结果展示。
核心模块是中间层的“自然语言信息隐藏系统框架”,它只是一个通用的信息嵌入和提取的系统框架。框架向下定义了载体操纵算法接口和隐藏编码算法接口。通过框架设计将载体操纵部分和隐藏编码部分进行了分工。展示层定义了两部分内容:一个是内部算法的API接口,由展示层控制系统框架进行运转,并了解其工作过程;另一个是数据可视化接口,在界面上直观地显示嵌入、提取效果。下层的“载体操纵插件”和“隐藏编码插件”都以插件方式设计。并生成动态链接库到指定目录,框架运行时即可自动识别所有插件。
目前本原型系统实现的载体操纵插件包括:英文绝对同义词替换插件、英文相对同义词替换插件、英文句法变换插件、中文绝对同义词插件、中文句式变换插件。隐藏编码插件包括随机编码插件、扩频编码插件和F5编码插件。
4 实验
为验证文中提出的信息隐藏抽象算法,从网络上收集了1 000篇英文语料,构建了测试语料库。这1 000篇英文语料涵盖了人文社会、自然科学、新闻、综合4大类。使用的自然语言处理工具包括:Lingpipe,Stanford Lexicalized Parser。其中Lingpipe使用其单词歧义消解(Word Sense Disambiguation)功能,Stanford Lexicalized Parser使用其语法解析功能。
4.1 隐藏容量
图2是对一个20 kB的英文文本,分别使用英文绝对同义词替换隐藏方法、英文相对同义词替换隐藏方法、英文句式变换隐藏方法和文中的信息隐藏抽象算法对其进行载体分析,所获得的载体单元数量。由图2可以看出,在使用载体单元的概念后,可以将所有可变换的语言单元结合到一个编码算法中。极大地提高了信息隐藏算法的隐藏容量。

图2 隐藏容量比较
4.2 通用性
由于不同算法在隐蔽性、鲁棒性和隐藏容量上的不同性能,对于特定的应用,就可以灵活选择不同插件,构建隐藏方案。

表2 隐藏方案示例
5 结束语
通过对现有自然语言信息隐藏算法进行分析,发现现有隐藏算法的隐藏容量不足,算法的通用性较差。无法满足实际应用的多样性需求。为获得容量足够大且载体单元覆盖面足够广的隐藏算法,提出了一种自然语言信息隐藏抽象算法。通过定义载体单元、载体操纵和隐藏编码三个抽象接口。对现有自然语言信息隐藏算法进行了抽象化处理。通过对这三个抽象接口的实例化,设计并实现了一个自然语言信息隐藏平台。最后通过实验证明,文中提出的信息隐藏抽象算法的隐藏容量有了极大提高,而且也极高了隐藏编码算法的通用性。
[1]PETITCOLAS F A,ANDERSON R J,KUHN M G.Information hiding - a survey[C].Proc.of IEEE,1999,87(7):1062-1078.
[2]ZUNERA J Z.,ANWAR M M.A review of digital watermarking techniques for text documents [C].ICIMT,2009:230-234.
[3]BRASSIL J,LOW S,MAXEMCHUK N,et al.Hiding information in document images[C].Proceedings of the 29th Annual Conference on Information Sciences and Systems,1995:482-489.
[4]BRASSIL J T,LOW S,MAXEMCHUK N F,et al.Electronic marking and identification techniques to discourage document copying[J].IEEE Journal on Selected Areas in Communications,1995,13(8):1495 -1504.
[5]LOW S H,MAXEMCHUK N F,BRASSIL J,et al.Document marking and identification using both line and word shifting[C].Proc.IEEE INFOCOM,1995:853 -860.
[6]钟尚平,陈铁睿.提高 wbStego4性能的方法及其实现[J].计算机工程与应用,2005(22):117 -120.
[7]BOHMAN P R,ANDERSON S.An accessible method of hiding HTML content[C].W4A'04,2004.
[8]NG W,LAU H L.Effective approaches for watermarking XML data[M].Database Systems for Advanced Applications,2005:68-80.
[9]ZHOU X,PANG H H,TAN K L.WmXML:A system for watermarking XML data[C].Proceedings of the 31st International Conference on Very Large Data Bases,2005.
[10]CHIANG Y L,CHANG L P,HSIEH W T.Natural language watermarking using semantic substitution for chinese text[C].Proc.of IWDW,2004,2939:129 -140
[11]BOLSHAKOV I A.A method of linguistic steganography based on collocationlly verified synonymy[C].Proc.of the 6th InternationalInformation Hiding Workshop,2004:180-191.
[12]TOPKARA U,TOPKARA M,ATALLAH M J.The hiding virtues of ambiguity:quantifiably resilient watermarking of naturallanguage textthrough synonym substitution [C].MM&Sec,2006:164 -174.
[13]WINSTEIN K.Tyrannosaurus Lex[EB/OL].(2007 - 11 -01)[2011 - 08 - 01].http://alumni.imsa.edu/~ keithw/tlex.
[14]Mikhail,Atallah J,et al.Natural Language Watermarking:Design,Analysis,and a Proof- of- Concept Implementation[C].Information Hiding,2001:185 -199.
[15]TOPKARA M,RICCARDI G,MIKHAIL J,et al.Natural language watermarking:challenges in building a practical system[M].Proc.SPIE,2006.
[16]ATALLAH M J,RASKIN V,HEMPELMANN C F,et al.Natural language watermarking and tamperproofing[C].The 5th International Information Hiding Workshop,2002:196 -212.
[17]NAKAGAWA H,MATSUMOTO T,MURASE I.Information hiding for text by paraphrasing[EB/OL].(2007 -4 -11)[2011 -07 -11]http://www.r.dl.itc.u - tokyo.ac.jp
[18]MIKHAIL J ATALLAH,VICTOR RASKIN,MICHAEL CROGAN,et al.Natural language watermarking:design,analysis,and a Proof-of-Concept implementation[C].Information Hiding,2001,2137:185-199.
