多带激励MBE谱幅度估计与参数编解码方案研究
2011-03-28李建锋唐斌
李建锋,唐斌
(1.北京工商大学北京102488;2.总装备部通信研究所北京101416)
随着多带激励MBE模型的成功运用,MBE语音编解码算法也日新月易。在提高话音质量的同时,编码速率也在不断地降低,从最初的8 kb/s,已经能降到1.2 kb/s,甚至会更低[1-4]。目前比较实用的MBE算法是IMBE(Improved MBE)算法[5-6]和AMBE(Advanced MBE)算法。1997年美国DVSI公司开发了3.6 kb/s AMBE编码算法,在此基础上生产了语音编码芯片AMBE-1000TM[7],并取得了广泛应用;IMBE算法也是由DVSI公司开发,码速率为4.15 kb/s,其优良的特性在商业化过程中取得了巨大成功,成为几个全球卫星通信服务的标准。
本方案计算MBE谱幅度参数及清浊音判决参数。在参数量化编码时,则采用了IMBE编解码方案,对谱幅度量化时,先进行了离散余弦变换(DCT),然后进行了矢量量化(VQ)。最终实验测定本文算法码速率为4.4 kb/s。
1 MBE算法中的参数估计
设语音信号s(n)的采样频率为8 kHz,每帧取160个样点,窗函数w(n)即为基音细搜索窗(宽度取为221个样点的哈明窗)。设加窗语音信号为sw(n),则sw(n)=w(n)×s(n)。用Sw(w)表示sw(n)的傅立叶变换,可以看成是系统函数Hw(w)同激励信号谱Ew(w)的乘积,即:

而重建语音信号可以写成:
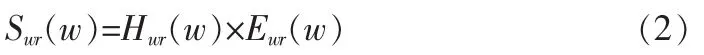
1.1 谱幅度估计
多带激励编码过程都涉及3种参数的提取,它们是基音频率,按基音频率各次谐波分成频带后每个频带的谱包络参数以及每个频带的V/U判决信息。统一提取这3个参数所涉及的计算量相当大,目前在实际应用中难以实时实现[2,6]。一种次优的算法是分两步来完成参数提取计算。第一步是确定基音频率和每个分带的谱幅度参数,第二步再对每个分带进行V/U判决。计算的过程是要使得原始语音谱模值|Sw(w)|合成语音谱模值|Swr(w)|之差的下列加权积分达到最小:
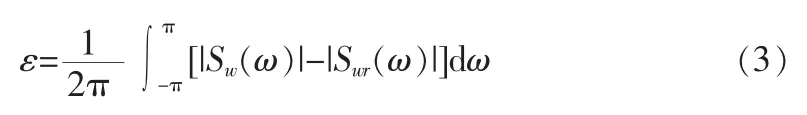
已经获得了每帧语音的基音周期P,则基音频率ω0=2π/P。对于每一个基音频率值,将ω=-π~π分成2M个频带,每个频带的频率下限和上限依次为am=(m-1/2)ω0以及bm=(m+1/2)ω0,m=±1,±2,…,±M。并且在每个分带[am,bm]中保持不变[2],其值为谱幅度则第m个子带所产生的拟合误差为εm:
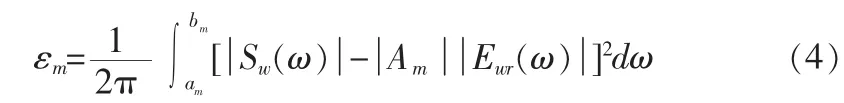
总的拟合误差为:

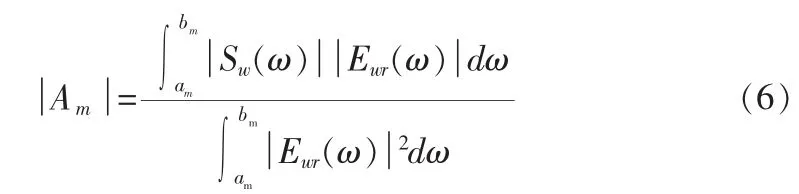
式(6)表明,第m带的谱值与该带的激励信号谱有关,若该带为浊音带,则可选用周期谱Pw(ω)来表示激励信号Ewr(ω),若该带为清音带,激励信号应采用理想白噪声谱,因此最终的谱值估计还应在清浊判决后才能确定,当第m带为浊音带时:
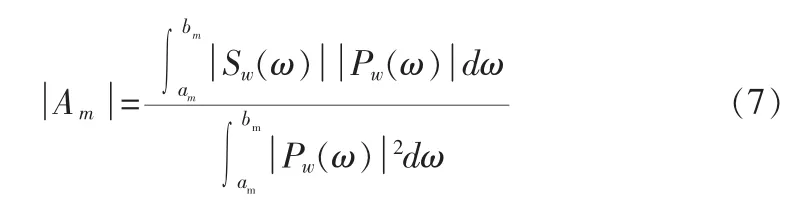
当第m带为清音带时,由于白噪声谱在所在频率上保持为常数,则谱幅度为:
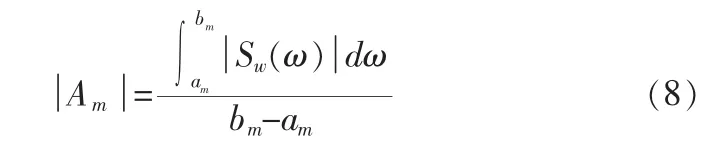
该式实际上表示的是加窗原始语音谱幅度在该带内的平均值。
以上是在频域内推导,下面用时域采样点进行计算。对加窗语音信号采用256点DFT
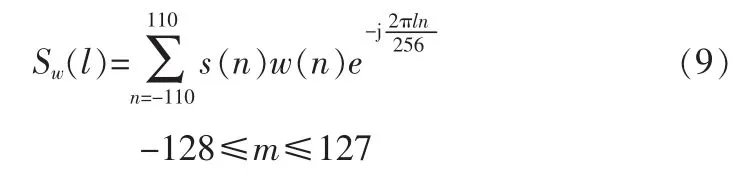
对窗函数采用16 384点DFT,以保证窗函数频谱在频域中移动时能有足够的精度。
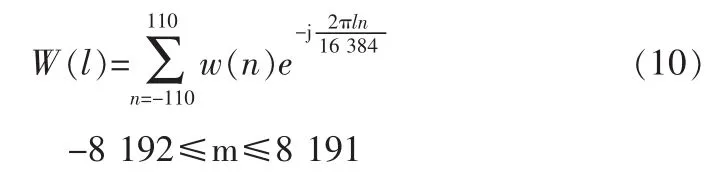
当基音频率为ω0时,在-π~π之间有2π/ω0个谐波分量,两个相邻谐波之间含有256/2π个语音信号的DFT点,因此第l次谐波带的上限和下限的计算公式:
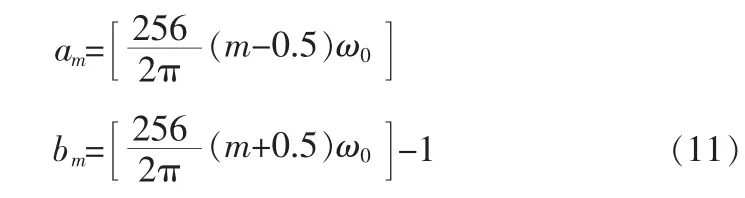
其中[x]表示大于或等于x的最小整数。
根据式(7),可求出加窗语音激励Pw(ω)在频带内与窗主瓣包络形状相同,窗内16 384点,而加窗语音256点,意味着语音改变一个样点,窗就要改变64个样点。可以求出最佳谱幅度
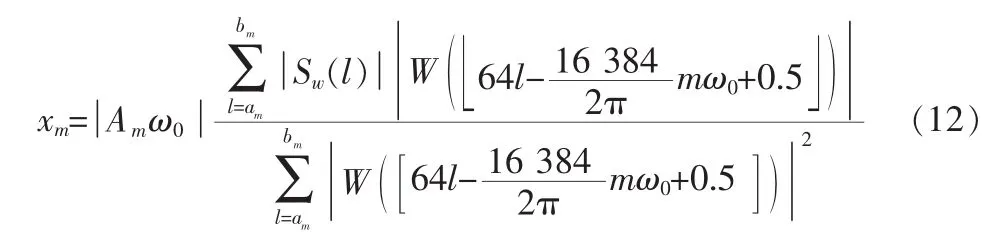
当第m带为清音带时,由式(9,10,11),则谱幅度为:
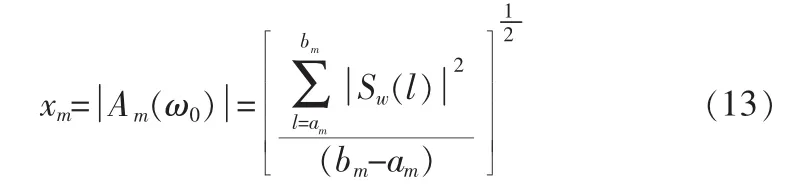
1.2 V/U判决
确定了基音频率ω0和xm谱幅度后,可以利用归一化误差能量进行V/U判决。归一化误差能量定义为[2]:
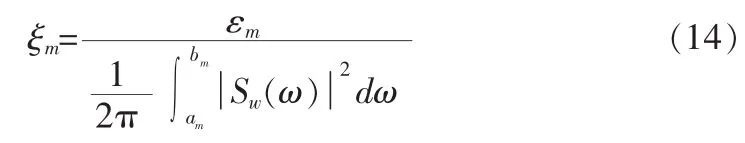
若ξm小于一定的阈值,则可以判该谐波频带为浊音区,反之为清音区。采用DFT时,式(14)表示的归—化误差应改成:
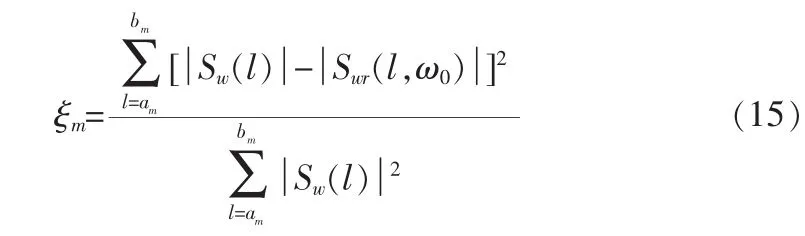
上式中的合成信号谱定义为[1,8]:
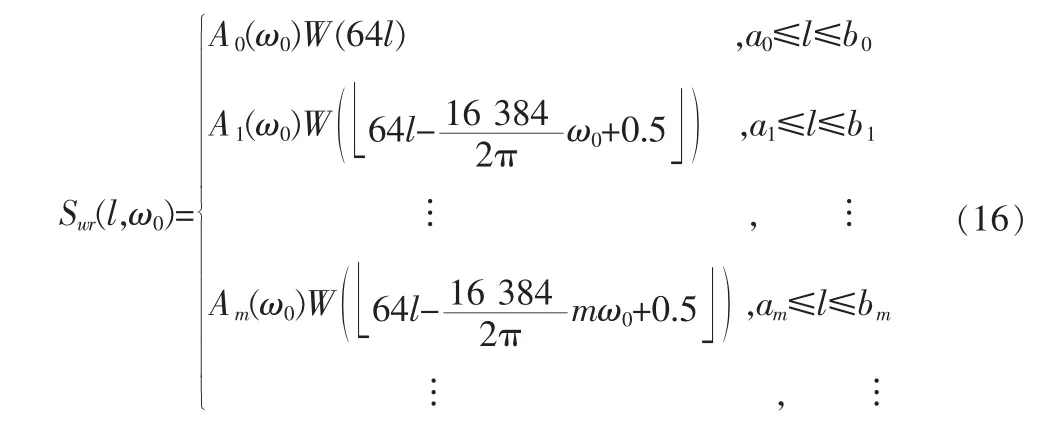
如果编码速率比较低,没有足够的比特来表示每一个谐波频带的V/Uv信息,可以将几个相邻的谐波频带合并成一个带,根据该带的总的拟合误差作出该带的V/U判决。这儿采用将每帧语音信号的频谱最多分成12个频带的方法,首先确定谐波个数M[1,8]:
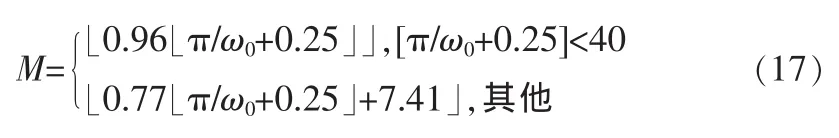
每个频带通常包含3个谐波分量,则每帧所含的频带数K:
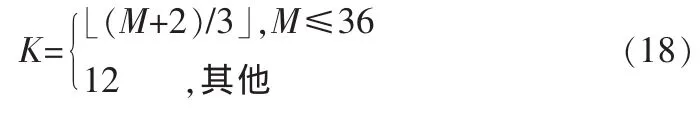
2 MBE中的参数编、解码算法
经过上述语音分析,对每帧语音信号都可得到一套语音参数:基音频率ω0,V/Uv判决信息Vk,1≤k≤K,和谱幅度xm,1≤m≤M,对于ω0和Vk,采用一般的标量量化即可,分别分配8 bit和K bit。下面主要阐述谱幅度参数编解码方法。
2.1 幅度谱的编码
幅度谱的编码主要利用帧间的相关性,首先计算预测残差Tm,1≤m≤M,然后再对Tm进行编码,编码框图如图1所示。谱幅度编码算法的一个重要特征是传递差信息,这种预测残差反映了当前帧与过去帧在幅度谱上的差异,为了保证这种方案工作正常,编码端要模拟解码端的操作,用重建的过去帧的幅度谱来预测当前帧的谱幅度,图1中的反馈路径就给出了解码端的部分操作。
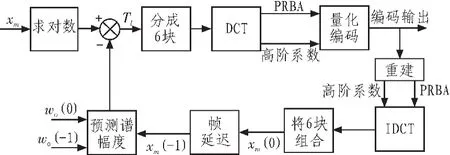
图1 谱幅度编码框图Fig.1 Block diagram of spectral amplitude coding
图中,xm(0)是当前帧未量化的谱幅度,xm(-1)指过去的第一帧量化的谱幅度,ω0(0)和ω0(-1)指当前帧的基音频率和过去第一帧的基音频率。在初始化时,ω0(-1)全部置为1.0,ω0(-1)置为0.02π。Tm为[2,6,9]:
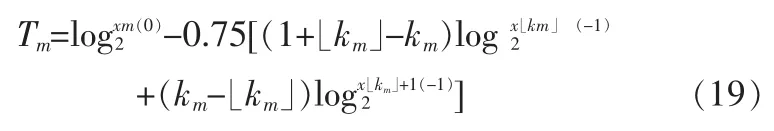

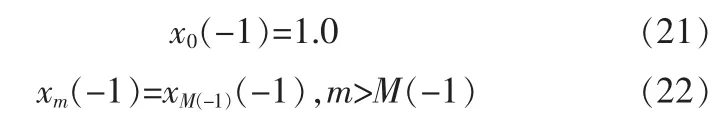
这M个预测残差被分成6块,每块的长度记为Ji,1≤i≤6,分块原则[7]如下:
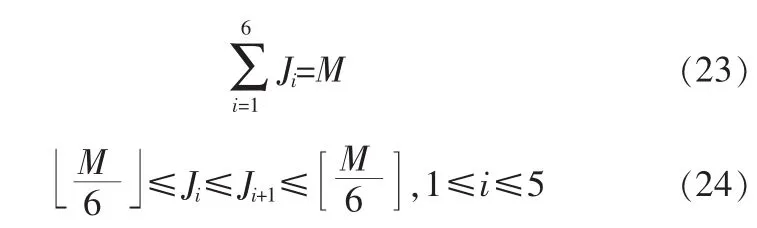
第i块的一个元素记为ci,j,1≤j≤Ji。每一块再进行离散余弦变换,第i块的变换长度为Ji,DCT系数记为Ci,k
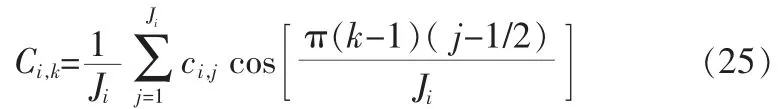
现在将得到的DCT系数再分成两组。第一组由每块的第一个DCT系数组成,构成了一个六维的矢量,称之为PRBA(Prediction Residual Block Average)矢量;第二组由剩余的DCT系数组成。
PRBA矢量的编码分为3步,第1步就是计算矢量元素的平均值mR:
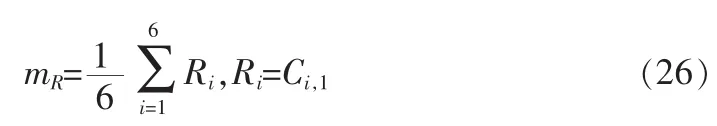
对mR使用6比特的非均匀的标量量化器,得量化值第二步是将PRBA矢量的每一个元素分别减去,得到零均值的PRBA矢量,然后用10比特的矢量码本对其进行矢量量化,得量化值码本的产生利用LBG算法[4]。第三步是计算PRBA矢量的每个元素的量化误差Qi:


其中Δ为量化阶距,如果b落在0≤b≤2B-1范围之外,则b取与此范围内的数据距离最近的值。
M-6个高阶■C1,2,C1,3,…,C1,J1,…,C6,2,C6,3,…,C6,J6」DCT系数的编码仍然采用均匀量化,每个系数分配的比特数B通过查相关比特分配表确定[2,6],DCT系数及Qi的比特分配表是根据M及它们的长时统计特征确定的。最后编码值b为

如b在0≤b≤2B-1之外,则b取与此范围内距离最近值。
2.2 幅度谱的解码
谱幅度的解码过程是编码过程的逆过程,如图1所示。基音频率ω0解码后,根据式(17)可得M,进而根据式(23)和(24)确定块长Ji,然后解码PRBA矢量,则
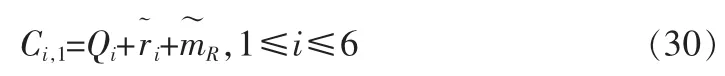
再解码得到高阶的DCT系数,就可得到6块DCT系数Ci,k,对每块DCT系数进行DCT反变换,可得到ci,j
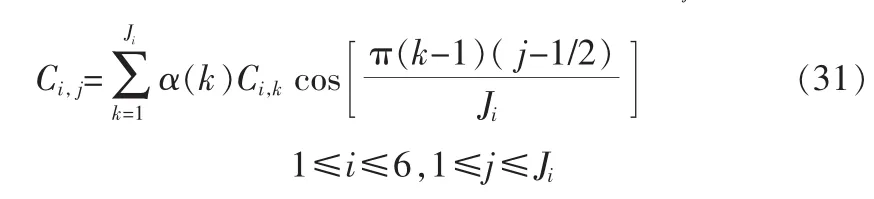

将这6块Ci,j合并成一个长度为M的矢量,记为Tm,1≤m≤M,即重建的幅度谱预测残差。再根据式(20)确定,最后计算当前帧的幅度谱[2,6,9]:
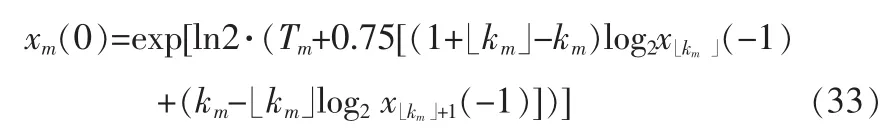
3 语音合成
合成语音信号sr(n)由清音部分su(n)和浊音部分sv(n)组成,合成时,这两部分被分别合成,合成后再将其相加即可。
3.1 清音语音合成
首先要产生一个白噪声激励,对它加窗后进行256点DFT,得到白噪声谱Uw(m):
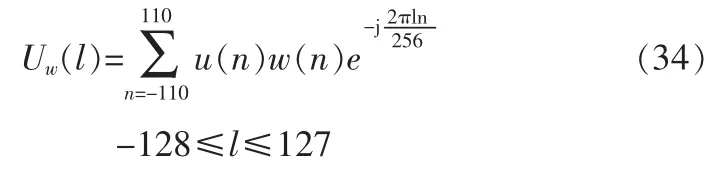
根据当前帧的V/Uv信息,对Uw(l)进行修正得(l)。若m频带为浊音段,则
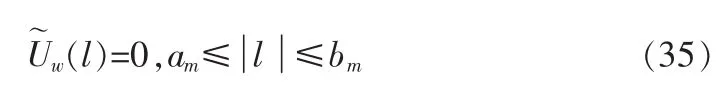
若m频带为清音段,则[1]
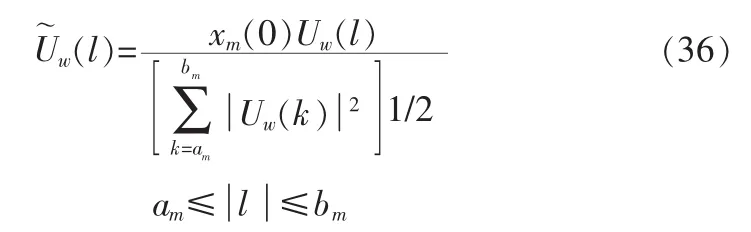
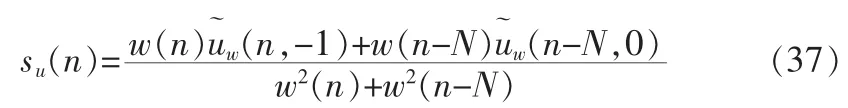
其中N表示帧长。
3.2 浊音语音合成
合成语音浊音部分可用一组余弦波在时域中直接合成,[1]:
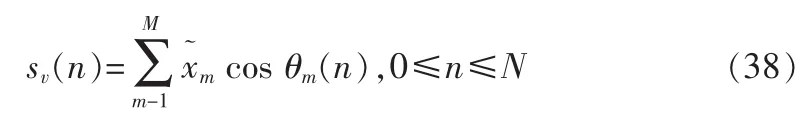
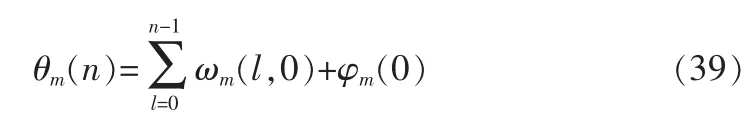
插值角频率ωm(l,0)由本帧与上一帧第m次谐波频率插值:
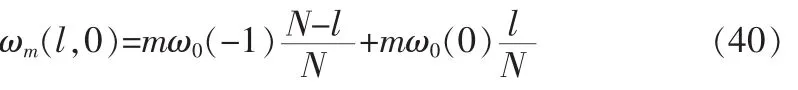
初始相位可用下式得到:
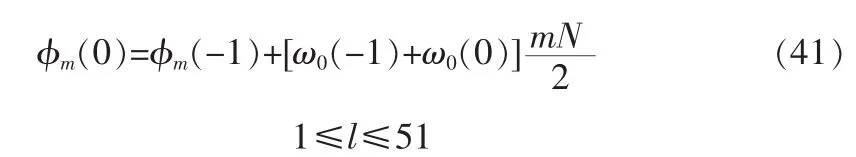
最后当前帧的合成语音sr(n)为:
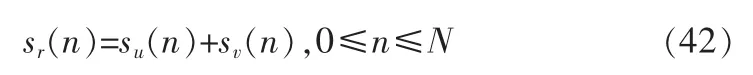
4 语音合成实验结果
取一帧实际语音,帧长20 ms,采样率8 kHz,实际语音波形如图2所示,仅进行语音分析合成实验,结果如图3所示。
对比图2、3,原始波形与合成波形除在相位上有偏差外,频率、幅度几乎一致。相位偏差因采用算法没有对语音信号相位信息进行传递,没进行编参数量化、编码,所以得到的合成语音原始语音在频率和幅度上几乎一致,得到的合成语音质量当是最佳效果。
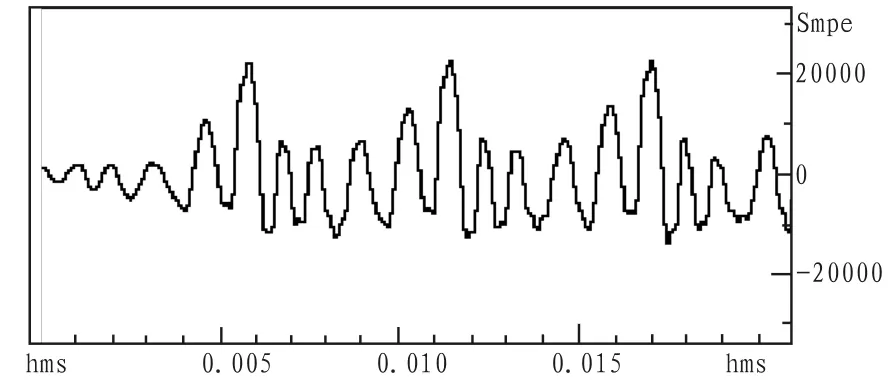
图3 一帧合成语音波形Fig.3 A synthesized speech waveform
5 结论
实验表明:有噪声环境下,该方法有良好的适应性,恢复语音保留了较好的讲话人特征,具有较高的自然度和可信度。
[1] PAN Sheng-xi,LIU Jia,WANGZuoying,et al.A new multimodel coding algorithm based on MBE and spectral amplitude correlation between successive frames[J].Chinese Journal of Acoustics,1998,17(3):266-270.
[2] HARDWICK C J,J.A 4.8 kbps multi-band excitation speech coder[C]//Acoustics,Speech,and Signal Processing,1988.Icassp-88.,1988 International Conference on,1988:374-377.
[3] JAMROZIK M,J.Modified multiband excitation model at 2400 bps[C]//Acoustics,Speech,and Signal Processing,1997.Icassp-97.,1997 IEEE International Conference on,2.Munich,Germany,1997:1603-1606.
[4] ROWE D,SECKER P.A robust 2400bit/s MBE-LPC speech coder incorporating joint source and channel cod-ing[C]//Acoustics,Speech,and Signal Processing,1992.Icassp-92.,1992 IEEE International Conference on,2,1992:141-144.
[5] 戴怀宇,曹志刚.语音增强IMBE声码器研究[J].通信学报,1998,19(4):43-49.DAI Huai-yu,CAO Zhi-gang.Study of IMBE vocoder with speech enhancement[J].Journal on Communications,1998,19(4):43-49.
[6] Inmasat,Digital Voice System Inmarsat-MVoice Codec[S].Version 2.London,1991.
[7] 张连海.多带激励语音编码算法研究与IMBE算法实现[D].郑州:解放军信息工程大学,2000.
[8] 袁春华.改进型多带激励声码器的研究与实现[D].北京:北京邮电大学,1995.
