基于编辑距离的X M L查询方法★
2011-03-16宗传霞
宗传霞
(兰州交通大学电子与信息工程学院 甘肃 兰州 730070)
0 引言
由于XML的特殊性,其信息数据急剧增长。现有的查询算法通常都是先结构查询,在结构匹配成功的基础上再进行内容查询。采用这些算法,不仅要遍历很多结构相关但内容无关的XML文档,而且也要对这些文档结构与查询结构做匹配,浪费了查询时间。目前已有的近似查询算法主要是静态有序选择算法[1]和动态加权减枝算法[3]等。但面对大规模的查询时,这些算法的效率就会明显降低。鉴于这种情况,改进XML信息查询技术具有必要性和紧迫性,这是XML查询研究的主要动力。本文以提高并改进XML查询中匹配的关键技术为主要内容,同时以如何提高其数据信息的查询效率为主要目的,描述了一种既能够在保证查全率的同时又对其查准率有所提高的方法。
1 新方案的实现
XML文档采用一种有序的树型结构来描述数据,树的节点对应文档中的元素、属性或者文本数据,而边则表示元素与元素之间的关系。对XML文档的查询有两种,以值为基础的选择查询(内容查询)和以结构为基础的选择查询(结构查询)。
1.1 内容查询
在文献[1]中提出了给查询条件定义权重的概念,利用权重来体现查询过程中的强弱,并且把这种强弱程度量化成[0,1]之间的数值,权重为0,表示在查询过程中不起作用;权重小于1,例如权重为0.8,那么就表示查询过程中该关键词在本文档中的重要程度为80%;权重为1,表示在查询中起全部作用。一般来讲,权重一般会取0与1之间(不包括0,1)的数值。下面主要从查询词的分类因子,语义因子,层次因子,容量因子等4点考虑对于词项权重的影响。
1)分类因子
设C是分类因子,它反映的是用户搜索内容所属类别的概率。
2)语义因子
在文档中,越能表现文档主题的词项,其语义因子[2]越高。它的范围在[0,1]之间。
3)层次因子
由于XML文档存在嵌套的情况,因此同一个词项出现在不同的层次中所反映的重要程度是不同的。在这里要指出的是根节点的层次就是树的层次。层次因子[2]一般取整数。
4)容量因子

5)查询关键词的加权公式
综上所述,本文新提出的查询关键词加权公式(1)为:

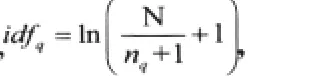
1.2 结构查询
在结构查询中主要涉及到了3种操作,删除操作、插入操作和替换操作。
1)删除操作:把相关文档中与用户查询不相匹配的节点q删除,其中α为删除平衡因子( 实验验证一般取值0.5为最佳)[3],用来调整具体环境所决定的权重与删除代价间变换的差异,见式(2)所示:

2)插入操作:该操作与删除操作是相反操作,其中β为插入平衡因子(实验验证一般取值0.5为最佳)[3],用来调整具体环境所决定的权重与插入代价变换的相似度。计算公式为(3)所示:

3)替换操作:替换主要分为两类:全局替换和局部替换。也就是改变一个节点的标签,把相关文档中的某个关键词节点的标签 q i 更新为用户查询中的某个查询关键词节点的标签 q i ′ ,根据公式(1)得到替换操作的公式见(4)所示:
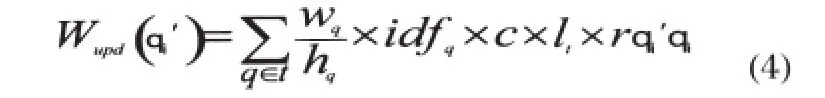
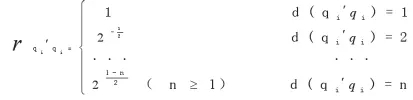
所以,在实际查询中, W d o c文档的权重值为 (非负), W q 为文档中和用户关键词相匹配的词项权重值之和,词项权重的值是利用公式(1)求得。W o p e为各个编辑操作所耗费的权重值之和,根据具体情况,利用公式(2)~(4)分别把删除操作、插入操作、替换操作的权重计算出来,并且相加得到权值之和。注意在很多情况下可能不会把删除,插入,替换一起应用,另外,又可能应用插入,删除或者替换多次。最后,用 W q 减去 W o p e 就是 W d o c 。具体定义公式(5)如下所示:
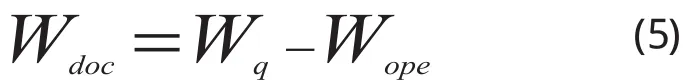
1.3 算法步骤及其流程图
1)首先,输入所查询的XML信息,根据本文提出的公式(1)计算出关键词权重,选择大于阈值L(实验验证0.5为最佳)[4]的权重,并且按照由大到小的顺序进行排列。如果此时权重为1,则说明内容完全匹配,返回结果,退出查询即可;
2)其次,如果权重不为1,这时就要进行结构查询,即利用删除、插入、替换的操作使得文档中的关键词能够和用户查询的信息进行完全匹配,然后计算出各个操作所花费的权重代价之和;
3)最后,用关键词权重减去各个编辑操作所花费的代价之和就是最终的权重值,然后,去掉阈值小于Q的权重,选择大于阈值Q(实验验证0.5为最佳)[5]的权重并且按照从高到低进行排序,返回最符合用户查询要求的文档。
以下是根据算法步骤设计的详细流程如图1所示。
2 实验
为了验证该XML查询方法改进的效果,本文对改进前的XML文档查询方法和基于编辑距离的XML查询方法进行了实验,并且对实验结果进行了分析与对比。
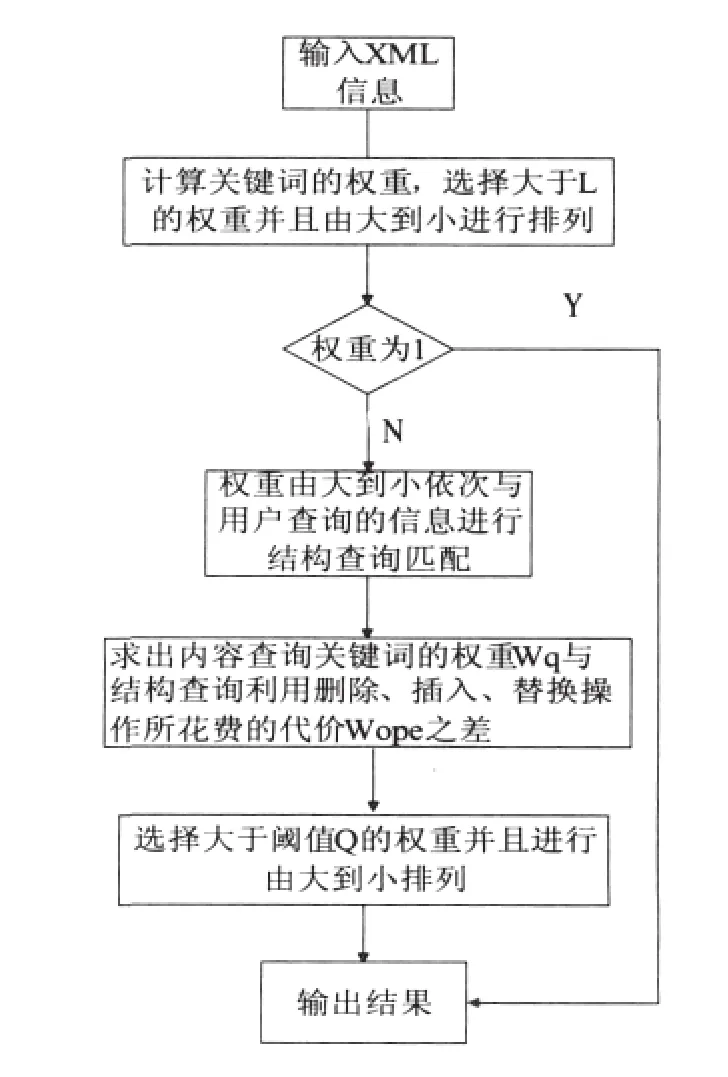
图1 XML查询流程图
2.1 实验环境
实验的平台是Windows XP专业版,P4 2.8GHz CPU, 768M内存,80GB硬盘。开发工具是在Microsoft Visual Studio.NET 2003(实 现 语 言 为vb.net)、Microsoft SQL Server 2000环境下设计并实现的。
INEX[6](Initiative for the Evaluation of XML Retrieval的缩写)是XML信息检索中具有代表性的文档集,其资源的核心内容是从1995年到2000年出版的1.2万篇期刊文章.本文选取了INEX 2006上的Wikipedia XML文集进行实验的测试,该实验数据集共包含659388篇文章,约4600MB大小,文档的平均大小约为7.1M,平均深度为6层,每篇文档所包含的平均结点数为161.26个。
TopX2.0[7]是一个针对半结构化的XML文档的检索排序引擎,它以扩展了的经典概率论理论为基础,能够对模糊内容和结构的XML文档进行查询和排序显示。
2.2 实验结果
TopX2.0的查询结果以文档为单位显示,其中关键词的权重是检索记分标准,最后按照文档中的关键词的最大分值进行排序输出,它可以实现CO(content-only即查询表达式中只有查询词)和CAS(content and structure即查询表达式中包含查询词和路径信息)两种查询方式.因为所测试的数据集过于庞大,PC上将难以胜任所有文档的解析操作,在所有完整文档集上进行检索的效率非常缓慢,所以要先在TopX2.0上发出查询请求并进行检索,然后再在检索结果中的前100篇文档上进行测试。
在测试的实验中,尽可能地模拟用户的查询行为,根据调查统计:一般用户在查询时的查询关键词不大于5个的平均概率为80%;考虑到用户在查看结果时,也不会将所用的相关文档都打开浏览,而往往希望在第一个页面(通常为10个结果)就能找到自己所需的信息.实验主要评测指标为P@10[8](P@10 常常能比较有效地反映系统在真实应用环境下所表现的性能),它是对于该主题返回的前10个结果的准确率.实验任意的选择了10组查询关键词。下面以一组简单的例子进行说明,当用户输入查询Q1://[about(.,Chinese new year in the culture)],根据本文前面所定义的公式,可以计算出文档的权重值并排序输出,查询具体对比结果值如表1所示。
在打开输出的结果文档中进行查阅,可以看到在文档“Chinese new year”中所包含的内容最符合用户的查询要求,而且文档中有和用户查询完全匹配的关键词,但是在初始查询中它却排到第四.同时,也可以看到在初始查询中排第一的文档实际是和查询条件很不匹配的。
3 结束语
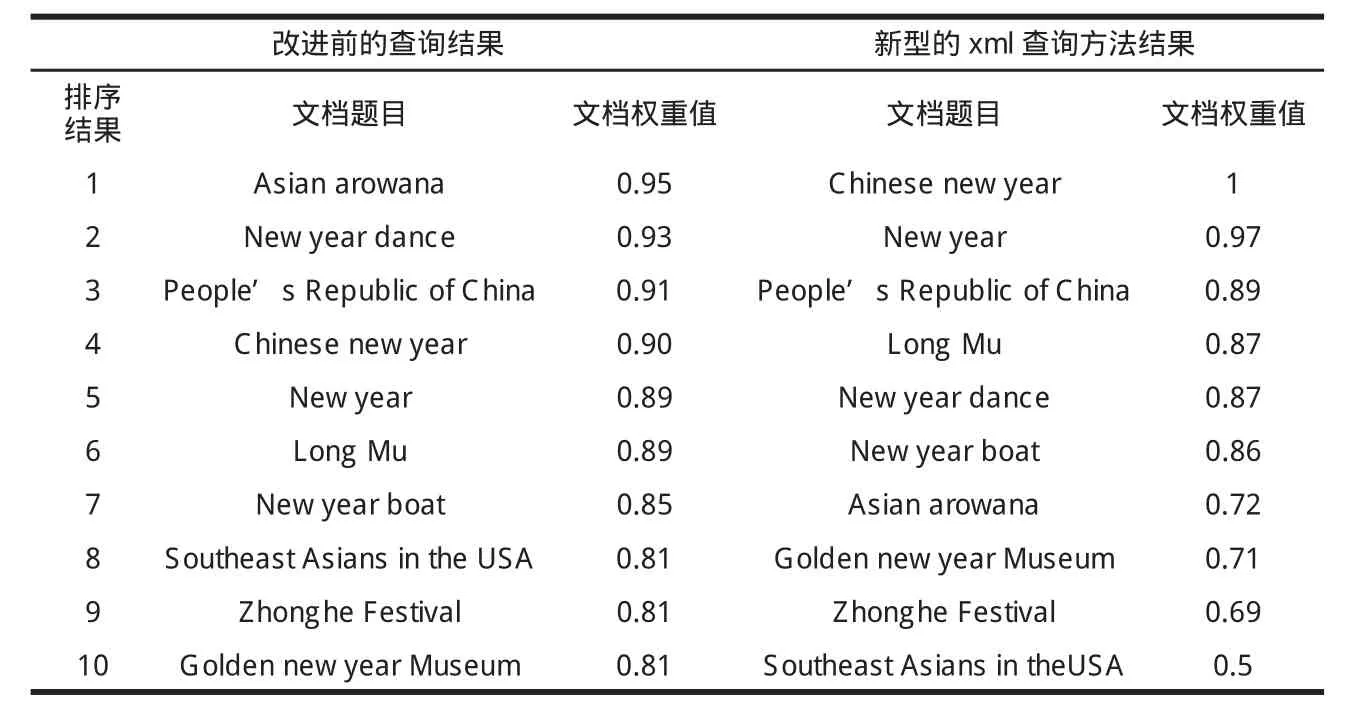
表1 实验的对比结果
本文针对XML信息查询中查询效率不高的情况提出了基于编辑距离的XML查询方法,它主要分为内容查询,结构查询两步。并且对结果进行了排序,以便查询出用户最需要的文档。通过实验验证,该方法在保证查全率的同时对查准率有一定程度的提高。
[1] J.P.TimBray,C.M.Sperberg-McQueen,F.Yergeau. ExtensibleMarkup Language(XML)1.0(third Edition). W3C Recommendation 04 February 2004.http://www. w3.org/TR/REC-XML/,2004.
[2] 万常选,鲁远.基于权重查询词的XML结构查询扩展[J].软件学报,2008,10(19):7-13.
[3] ClarkJ,DeRose S.XML path language(XPath) version1.0 w3c recommendation.World Wide Web Consortium,1999.
[4] 陈恩红,许斗,钱海.基于XML的图形结构数据表示的解决方案及其比较[J].计算机工程,2002, 28(5):6-19.
[5] 王宏志.XML数据查询处理技术的研究[D]:哈尔滨:哈尔滨工业大学,2008.
[6] TORSHEN S,NAUMANN F.Approximate tree embedding for querying XML data[C]//Proc of ACM SIGIR Workshop on XML and Information Retrieval A thens:[sn],2000.
[7] 沈剑沧,鲍培明.XML查询a方法的设计与研究[J].计算机工程,2007,21(33):63-65.
[8] 郭俊文,衡星辰,邵利平,等.一种基于XML文档聚类的XML近似查询算法[J].计算机工程,2006,32(15):52-54.
