非线性相关的失效数据联合聚类分析与预测
2011-03-12王慧强冯光升林俊宇
卢 旭,王慧强,吕 晓,冯光升,林俊宇
(1.哈尔滨工程大学计算机科学与技术学院,150001哈尔滨,luxu-hrbeu@yahoo.cn; 2.海军工程大学电子工程学院,430033武汉)
随着高性能计算机系统应用的日益普及和对其高可用性的严格约束,如何预测并避免系统可能的失效成为当前一个研究热点[1-2].实现失效预测首先需要对系统所生成的大规模失效数据进行分析,其研究关键就是将具有相似失效模式的失效样本聚集在一起,为后续失效预测与快速恢复提供决策依据.失效数据对象间的一个重要关系就是非线性相关性[3],可用以反映特征向量之间的依赖性或者关联关系,随着近年高性能计算系统失效数据的对外开放[4-5],此类失效数据分析和预测问题的研究逐渐引起了广泛关注.
目前对系统失效数据的分析主要有:1)分析系统运行历史记录,计算失效平均间隔时间; 2)提取失效事件时序特征,通过辨别系统失效模式预测失效.这2类方法尽管在各自的系统上表现优异,但没有有机融合失效特征进行综合评判,或者对于冗余、重复数据需要人为进行筛选,难以得到推广[6-7].在分布式、高性能计算机系统中,失效数据往往具有稀疏、髙维等特征,且有价值的非线性相关性主要存在于维度子空间内,而此类单向聚类方法难以发现这些维度子空间内的局部相关性,增加了失效预测的不确定性.本文分析失效特征的非线性相关性,引入联合聚类思想(Coclustering)[8],以互信息熵损失差作为联合聚类度量标准,提出非线性相关失效数据联合聚类算法,实现非线性相关失效数据自动分析与预测.
1 失效预测基本模型
1.1 失效预测框架
尽管目前已经研究出多种容错机制,致力于避免故障发生后导致系统服务中断,但在实际应用中失效的发生总是不可避免,因此要保证系统的高可用性就必须为系统提供失效预测的能力.根据预测时间的长短,失效预测可分为长期预测和短期预测,其中:长期预测大多通过分析系统可靠性模型来获得失效事件的季节性分布;短期失效则通过失效事件的关联性来预见可能发生的失效,失效预测框架如图1所示.在t时刻预测在t+Δt时间段内是否发生失效,其中:Δt为预先时间;Δtw为Δt的下限表示的失效预恢复所需时间;Δtp为预测期,描述了整个预测时间窗口的长度.显然,预测时间窗口越长,则时间窗口内发生失效的可能性越大.

图1 失效预测基本框架
1.2 失效特征相关性分析
对大规模失效数据集的分析首先需要从运行系统中提取出能够反映与失效事件关联的系统状态特征.这些特征应当能够表示出系统在正常执行时与失效事件发生时的差异,同时还需要捕捉到不同失效事件中间的时空关联性.失效特征应该能够反映系统失效与正常运行下的本质区别,同时还需要能够反映失效事件的时空关联性.一般而言,特征空间可分为强相关特征、弱相关特征和无关特征[9].设F是特征集合,fi是一个特征,Si=F-{fi},特征相关性的形式化定义为:
定义1 特征fi是强相关的当且仅当P(C|fi,Si)≠P(C|Si).
定义2 特征fi是弱相关的当且仅当P(C|fi,Si)=P(C|Si),且存在S'i⊂Si,使得P(C|fi,S'i)≠P(C|S'i)强相关特征是对类的分布构成影响的特征,弱相关特征则只在一定条件下影响不同类之间的分布,以此为基础可给出失效特征非线性相关性定义.
定义3 特征fi是非线性相关的当且仅当特征是强相关或弱相关,且ρ=0为
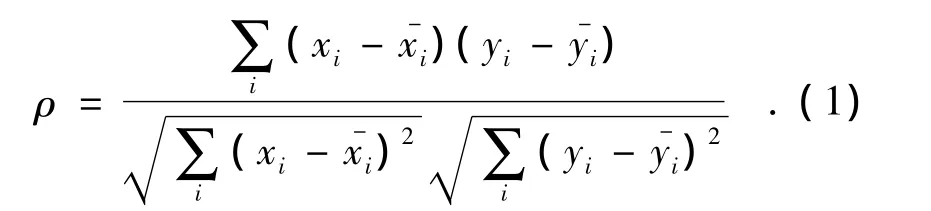
式中ρ被称为线性相关系数且x,y∈F.
通过比对系统各部分失效发生的关联性,给出用于失效预测特征提取的性能指标.这些指标可从系统事件日志中提取,例如处理器与存储空间利用率,通讯与输入输出操作的容量等.而固定时间窗口内的失效事件数、失效类型与平均失效间隔时间等则用来构建系统失效的统计模型.
定义4 失效特征标签由七元组给出定义: tuple(fID,time,fLoct,fType,usrUtil,pktCount,io-Count).其中:fID,time,fLoct,fType分别为失效事件编号、时间戳、失效定位和失效类型;usrUtil为系统失效时资源利用率;pktCount,ioCount分别为衡量特征提取阶段的数据包与通信请求数.
2 失效数据聚类方法
基于信息论的联合聚类算方法从数据矩阵行维与列维2个方向上聚类,在数据分析、协同过滤等研究领域有着广泛应用[10].假设m个待聚类失效样本,记作{x1,x2,…,xm};若每个失效事件特征标签用n维特征向量Y描述,记作{y1,y2,…,yn}. p(X,Y)为随机变量X和Y的联合概率分布,由于X和Y都是离散型随机变量,p(X,Y)可以用一个m×n矩阵表示,矩阵中每个元素p(x,y)表示失效事件x和失效特征标签y联合发生的概率.
定义5 联合聚类映射定义为

式中:随机变量^X,^Y分别为联合聚类后失效事件与特征标签集合;k,l分别为联合聚类后失效事件簇和失效特征簇的数量.
联合聚类映射可简写为^X=CX(X)和^Y= CY(Y).文献[8]引入了互信息熵(mutual information)的概念对联合聚类问题进行量化分析,并给出了联合聚类映射函数的最优解形式.
定义6 最优联合聚类应满足聚类前后的互信息熵差最小化计算为

其中:互信息熵计算为


式中:D(·‖·)为KL散度,或称为相关熵;q(x,y)=.在求解联合聚类算法的映射函数时,KL散度度量被进一步表述为2种对称形式,用于实现行聚类和列聚类,计算公式分别为

在上述分析基础上,提出非线性相关的失效数据联合聚类分析算法.算法分3个部分:1)根据已知的失效事件与特征标签联合分布进行初始化,并给出初始化映射函数;2)按照互信息熵差计算方法分别进行行聚类和列聚类,最终获得新的联合聚类子集;3)判断联合聚类后的数据矩阵是否满足终止条件,如果不满足则继续进行聚类迭代直至满足收敛条件为止.算法详细步骤如图2所示.

图2 非线性相关失效数据联合聚类算法
由于非线性相关的失效数据联合聚类分析很难在可接受的时间内获得最优的聚类结果,因此当互信息熵差小于某一给定任意小整数时,可近似认为联合聚类达到局部最优.为确保算法能在有限事件内获得联合聚类结果,还需要保证失效数据联合聚类算法能够在有限迭代次数后收敛.
引理1 非线性相关失效数据联合聚类算法总能在有限次迭代后收敛并达到局部最优.
证明 KL散度可通过下式进行分解,即


而由于
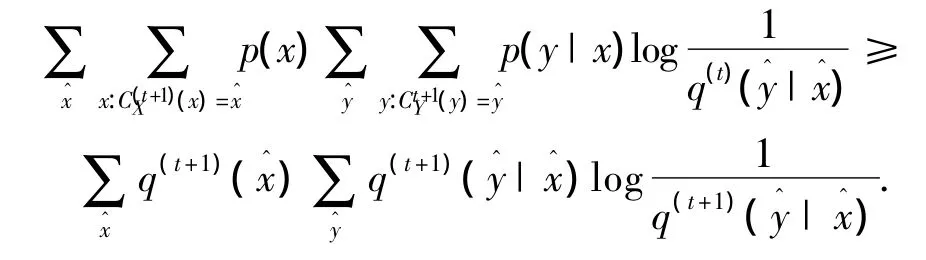
因此有

由于每次迭代后行簇与列簇的数目是有限的,且任意小整数ε确定,所以非线性相关的失效数据联合聚类算法总能在有限次迭代后收敛且达到局部最优,证明完毕.
3 实验结果与分析
3.1 失效特征提取
实验采用了美国洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory,LANL)22台高性能计算系统从1996~2005年的运行记录作为失效数据来源[5].LANL高性能计算系统采用独立内存接口以及多级处理器结构,共包含4 750个节点以及24 101个处理器,LANL高性能计算机系统在规模、体系结构等方面均呈现出多样性,大部分工作负载为3D仿真和可视化计算.图3分别显示了 LANL高性能计算机系统从2003年9月1日~2005年8月31日CPU失效、内存失效、应用程序失效和文件系统失效4种类型的时间分布.由图3可知,不同的失效类型具有不同的时间分布特征,在联合聚类分析时必须根据不同类型失效的特征分布进行区分.
3.2 联合聚类性能测试
实验给出了失效数据联合聚类算法在LANL失效数据集上运行的收敛速度和聚类效果,同时引入迭代双聚类算法(Iterative Double Clustering,IDC)[11]以及失效数据聚类的temporal和spatial算法进行比较.算法在Window XP平台上实现,硬件环境为Intel Celeron CPU 2.4 GHz,主存1 G.实验采用LANL实验室高性能计算机2004年6月~2005年9月之间的失效数据作为聚类算法性能测试的数据来源.

图3 4种失效类型时间分布
实验首先考察4类算法在不同数据规模下的运行时间.图4为失效数据矩阵的列数固定时算法运行时间和数据行数的关系曲线,分别测试矩阵行数m分别从1 000~3 000之间变化的运行时间.图5为失效数据矩阵的行数固定时算法运行时间与矩阵维数的关系曲线,分别测试维数从5~25的运行时间.聚类分析时间随着失效样本数的增加而递增,其中temporal和spatial算法耗时最短,而迭代双聚类以及本文所提算法耗时较长,这是因为前者属于单维聚类方法,在聚类相似度计算时仅考虑行聚类问题,而后者则从行聚类以及列聚类2方面进行聚类计算,因此算法运行时间不可避免地延长.

图4 列数固定时算法运行时间与行数关系曲线
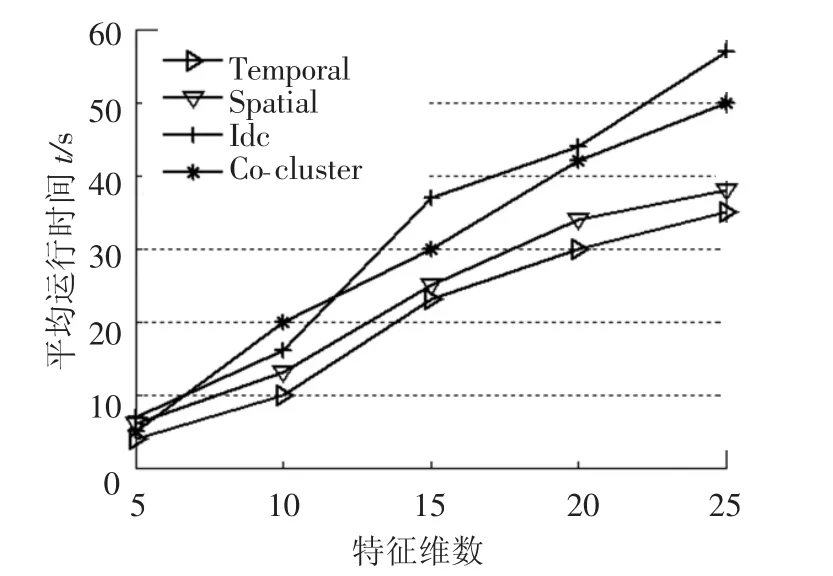
图5 行数固定时运行时间与列数关系曲线
图6表示在聚类过程中互信息熵差与算法运行时间的曲线关系.由图6可知,聚类过程中互信息熵差随着聚类算法运行时间递减,在算法运行初始阶段,2类联合聚类算法熵差达到最大值,在聚类分析10 s后开始平滑下降.图7为聚类过程中算法迭代次数与运行时间的曲线关系.由图7可知,从聚类初始阶段开始,当算法运行超过30 s后,迭代也超过50次/s且逐步达到最大值.
为评测聚类算法用于失效预测的有效性,根据标注的LANL实验室失效数据真实类别计算聚类结果的查准率(precision)和查全率(recall),如表1所示.表1的数据表明,2种联合聚类算法的聚类结果中4类失效类型的查准率均高于65%.这是因为本文所提算法在单次行聚类或列聚类时均按照KL散度计算信息熵损失.作为对比,单维聚类算法由于仅按照时间分布或空间分布2种特征进行聚类,因此对于4种失效类型的聚类分析结果均不尽理想.对聚类过程中互信息熵差与迭代次数的考察说明,联合聚类算法能有效考虑不同特征的关联性,并采用关联特征来度量失效事件间相似性,因此联合聚类较单维聚类效果更好.

图6 互信息熵差与运行时间的关系曲线
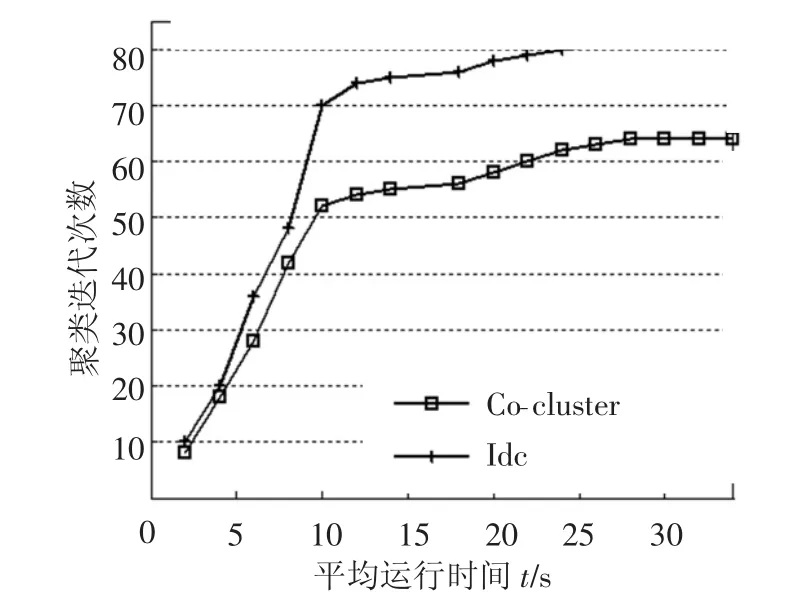
图7 算法迭代次数与运行时间的关系曲线

表1 聚类算法实验结果比较 %
4 结论
1)针对高性能计算机系统非线性相关失效数据的髙维、稀疏等特征,提出非线性相关失效数据联合聚类算法,以互信息熵损失差作为联合聚类度量标准并阐明了算法在有限次迭代后的收敛性.
2)实验计算了4种常见失效类型的时间分布,并比较了不同算法在失效数据集上的聚类效果和收敛速度.实验结果表明,本文所提出的非线性相关失效数据联合在聚类准确性、聚类计算时间耗费等方面优于单向聚类方法.
[1]KEPHART J O,CHESS D M.The vision of autonomic computing[J].IEEE Journal of Computer,2003,36(1):41-50.
[2]SOLANO-QUINDE L D,BODE B M.Module prototype for online failure prediction for the IBM BlueGene/L[C]//IEEE International Conference on Elector/Information Technology.Ames:IEEE Computer and Communication society,2008:470-474.
[3]FU Song,XU Chengzhong.Exploring event correlation for failure prediction in coalitions of clusters[C]//Proceedings of the 2007 ACM/IEEE Conference on Supercomputing.New York,NY:ACM,2007:456-468.
[4]OLINER A,STEARLEY J.What supercomputers say: A study of five system logs[C]//Proceedings of the 37thAnnual IEEE/IFIP International Conference on Dependable Systems and Networks.Washington,DC:IEEE Computer Society,2007:575-584.
[5]SCHROEDER B,GIBSON G A.A large-scale study of failures in high-performance computing systems[C]// Proceedings of the International Conference on Dependable Systems and Networks.Washington,DC:IEEE Computer Society,2006:249-258.
[6]LIANG Y L,ZHANG Y Y,SIVASUBRAMANIAM A A,et al.BlueGene/L failure analysis and prediction models[C]//Proceedings of the International Conference on Dependable Systems and Networks.Washington,DC:IEEE Computer Society,2006:425-434.
[7]LIANG Y L,SIVASUBRAMANIAM A,MOREIRA J. Filtering failure logs for a BlueGene/L prototype[C]// Proceedings of the 2005 International Conference on Dependable Systems and Networks.Washington,DC: IEEE Computer Society,2005:476-485.
[8]DHILLON I S,GUAN Y Q.Information theoretic clustering of sparse cooccurrence data[C]//Proceedings of the Third IEEE International Conference on Data Mining.Washington,DC:IEEE Computer Society,2003: 517-520.
[9]JOHN G H,KOHAVI R,PFLEGER K.Irrelevant feature and the subset selection problem[C]//Proceedings of the 11th International Conference on Machine Learning.San Francesco:Morgan Kaufmann,1994:121-129.
[10]闫雷鸣,孙志挥,吴英杰,等.联合聚类非线性相关的基因表达数据[J].计算机研究与发展,2008,45(11): 1865-1873.
[11]EL-YANIV R,SOUROUJON O.Iterative double clustering forunsupervised and semi-supervised learning[C]//Proceedings of the 12thEuropean Conference on MachineLearning. London,UK:Springer-Verlag,2001:121-132.
