重复数据删除技术在数字图书馆中的应用*
2011-03-10申彦舒
申彦舒
(湖南人文科技学院图书馆,湖南 娄底 417000)
1 引言
如今,无论规模大小,无论行业差别,都面临数据量不断增长的困境,而且在海量的存储数据中,又存在大量重复的数据,保存这些重复的数据,实际上无形中占用了存储系统太多的资源空间,也间接耗掉了数据中心很多不需要的电力以及管理成本。
同时,当虚拟化技术在各行各业中扮演越来越重要的角色时,越来越多的逻辑服务器整合到现有的物理计算机系统中,服务器虚拟化成为一种趋势。在服务器虚拟化后,虚拟机上大量的数据是重复的,虚拟机镜像文件也很大,每天产生的虚拟机文件给存储空间带来了特殊的挑战。可见,基于磁带的传统备份和恢复方法无法满足数据增长和服务器虚拟化影响的需求,那么如何才能实现高效的重复数据删除,大大节省存储空间,降低存储成本,确保业务连续性和数据安全性,提高数据保护级别,实现高效数据恢复,重复数据删除技术的引入为我们提供了一套可行的方案。
2 重复数据删除技术
重复数据删除[1](data deduplication)也称为智能压缩(intelligent compression)或单一实例存储(single-instance storage),是一种可自动搜索重复数据,将相同数据只保留唯一的一个副本,并使用指向单一副本的指针替换其他重复副本,以达到消除数据冗余、降低存储容量需求的存储技术。通过重复数据删除技术不但能解决单数据中心多副本占用空间的问题,还可以减少传输备份数据所需要的带宽。
2.1 重复数据删除技术分类
重复数据删除技术主要分为基于硬件的重复数据删除和基于软件的重复数据删除两种方式。
基于硬件的重复数据删除在存储系统本身进行数据削减。正常情况下,备份软件会将专用设备看成一般的“磁盘系统”,并且不会感知其内部正在进行的重复数据删除进程。基于硬件的重复数据删除技术具有更高的压缩比,成本高,适合大型企业使用。
基于软件的重复数据删除旨在消除源的冗余,以此获得带宽的补偿。软件本身是具有重删功能的备份软件,使用Client/Server结构。Server制定策略并在指定时间发起备份,调度Client对备份数据进行分块,将数据块输入Hash程序进行运算,结果计入Hash表。后面的数据块运算结果与表内存在的值相同就删除数据,不同就记录结果并保存数据块。数据恢复根据表值和保存数据块还原被删除数据,重组数据后恢复到系统中。实现方式优势是数据输出到网络前,在业务主机就实现了重删操作,减少了网络流量并降低了存储空间用量。基于软件的重复数据删除产品有EMC的Avamar和赛门铁克的veritas netBackup等。笔者主要论述以Avamar为例的重复数据删除技术在数字图书馆的应用。
2.2 重复数据删除技术原理
从工作原理上讲,重复数据删除技术可区分为基于哈希(Hash)算法的重复删除、基于内容识别的重复删除和基于ProtecTier VTL的重复删除[2]。
2.2.1 哈希算法
Hash,一般翻译为散列,或音译为哈希。备份时,数据将被分块计算Hash值,按照索引把新数据块的Hash值和所有已存数据块的Hash值进行比较,如果发现有相同的Hash值,就判定它对应的数据块是重复内容,使用Hash值替换数据块写入存储系统中,并且建立存储系统保存位置Hash值与Hash表中相同值的索引指针,删除重复的数据块。这样存储系统当中保存的备份数据副本是由唯一数据块和那些重复数据块对应的Hash值合成的,而且数据块和Hash值的排列顺序保持和原数据一致。而找不到匹配的数据块将被直接以原有形式保存到存储系统中,并且建立数据块与Hash值的索引指针,以供日后比较。
2.2.2 内容识别
内容识别软件技术不是以算法技术为核心的技术理论,而是针对数据实体的内容进行识别、区分、标注、记录及删除等处理操作的重复数据删除软件技术。其原理是:当备份数据第一次被写入重复数据删除软件技术核心的时候,不会进行数据扫描、切分、计算、构建指针、重复数据的删除等这些操作,而是直接保存到存储系统中,对备份数据副本进行扫描、内容识别、信息抽取操作,并且将元数据保存到软件技术的数据库中。当来源相同的下一备份数据再次被写入的时候,还是被直接保存到存储系统中,进行扫描、内容识别、信息抽取操作,然后用新的抽取信息和原来保存的抽取信息进行比对。根据比较结果构建索引指针,在两份完整备份数据副本中重复的数据内容之间建立索引指针指向关系,再进行一次数据指针对应关系的完整性检查,最后删除先保存的备份数据副本中的重复数据内容,将后保存的备份数据副本完整真实地保存到存储系统中。
2.2.3 ProtecTier VTL
这种方法像基于哈希算法那样将数据分成块,并且采用自有算法决定给定的数据块是否与其他数据块相似,然后与相似块中的数据进行逐字节的比较,以判断该数据块是否已经被存储。
2.3 使用重复数据删除技术的核心价值
第一,利用重复数据删除技术可以对存储空间的利用率进行优化,以消除分布在存储系统中的相同文件或者数据块,大幅降低需要采购和管理的物理存储容量。第二,利用重复数据删除技术可以减少在网络中传输的数据量,进而降低能量消耗和网络成本[3],并为数据复制节省大量网络带宽。第三,VMware备份映像文件非常大,而这些备份映像的冗余程度极高,重复数据删除可使备份数据缩小几十倍,并可缩短多达90%的备份时间窗口,这就大大提高了VMware备份速度,减少了基础架构压力,允许更大规模的服务器整合,并消除了共享资源上的传统备份负担。第四,重复数据删除技术还充分利用随机存取磁盘存储,可以大大缩短多种应用程序的恢复时间,与顺序存取(磁带)方法相比提高了恢复性能。
3 重复数据删除技术与数字图书馆
以某高校图书馆为例,该图书馆拥有图书馆自动化集成系统、光盘数据库系统、一卡通系统、论文提交系统、门禁系统、监控系统、数台存储设备、各类型数据库资源服务器等,各个应用系统的技术环境不一样,面临着如下的困难:业务数据重要,恢复时间长;各系统的数据采用分散模式各自独立保存,其数据备份一般采用磁盘、磁带、光盘等方式,分散管理,复杂度高,备份系统不可靠;大量备份数据只有单份拷贝,存在数据丢失风险;试图利用虚拟化技术实现服务器的整合,但又存在着虚拟化平台数据量大,重复数据多,传统的备份方案难以满足需求等问题。
3.1 重复数据删除技术在数字图书馆应用的设计
针对上述情况,购置4台高配置的服务器,利用VMware软件将数据库资源服务器以及各系统服务器进行整合,在其中心机房搭建一台备份服务器,用来部署Avamar技术,Avamar可以与VMware虚拟化系统紧密集成,采取多种方式结合制定出利用重复数据删除技术实现数据备份和恢复平台方案。具体实施如下:
①配置虚拟机。建立虚拟机模板,根据各应用的要求建立Windows2000和Windows2003、SCO UNIX3个模板,利用3个模板转换出虚拟机,然后根据各应用对各个虚拟机的CPU、内存和硬盘进行调拨,淘汰原有旧服务器。
②使用GuestLevel方式,把Avamar软件直接安装在每个虚拟机上,根据每个客户端的不同需求,采用灵活多样的备份策略。该方法可方便实现客户系统级别/文件级别的备份。此类备份一般不需要编写脚本,可能需要基本客户端设置以外的配置来支持特定应用程序,如MicrosoftSQL Server或者Oracle等。此方式的主要优点:可实现最高级别的重复数据删除;支持虚拟机内应用程序的备份;物理机和虚拟机的备份方法完全相同,可轻松完成虚拟机的恢复。恢复整个虚拟机映像的方法如图1所示。

图1
若要实现完整系统恢复,可使用模板或现成的操作系统映像,创建安装操作系统和AVamar代理的虚拟机。若要恢复服务器上的整个文件系统,可执行以下步骤:从模板和映像部署新虚拟机;开启虚拟机并向Avamar服务器注册该虚拟机;执行到新虚拟机的重定向恢复。
③使用VCB代理服务器,在代理服务器级别利用AVamar重复数据删除功能。此方式可以实现对所有虚拟机image级别的备份,方便虚拟的整机恢复。不仅提供了源位置重复数据删除的所有优势(降低基础架构成本、减少网络带宽、缩短备份时间),而且还将备份和恢复任务移至代理服务器。
使用重复删除技术后新备份系统运行环境如图2所示。
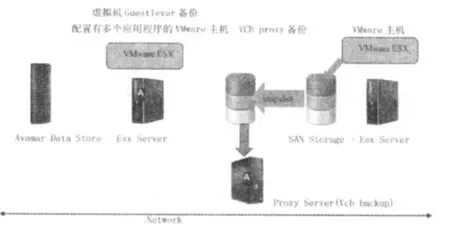
图2
在数据中心放置Emc Avamar Data store 10TB,集中管理Vmware虚拟化环境操作系统和应用数据的快速备份与恢复。在VMware虚拟化系统中使用代理服务器和Guest备份相结合的方式,在源位置上缩减备份数据集。备份任务通过Avamar管理控制台实现集中管理。
3.2 实施效果
使用Emc Avamar重复数据删除方案,虚拟机的数据在传输之前就进行了重复数据删除,删除比可达90%以上,极大地减少了备份作业需要传输的数据量,大大节省了带宽,缩短了备份时间,也节约了备份空间;提高了备份设备利用率,降低了成本;Avamar备份是生成的完全备份,而不是传统备份方式的“全备份+增量备份”,只需操作一次就可以恢复所需要的时间点数据,能轻松实现快速恢复。由于数据是备份到存储阵列的,存储阵列上有RAID冗余磁盘技术,可以随时、自动对数据进行校验,可靠性大大提高。
4 结束语
随着数据的爆炸式增长,所占空间越来越大,而应用系统保存的数据中高达60%是冗余的,并随着时间的推移越来越多[4],保存这些重复数据无形中占用了大量存储系统的资源空间,管理成本及数据中心空间的消耗也变得越来越严重。重复数据删除技术的出现在很大程度上缓解了该问题,能有效减少存储介质数量、减少数据传输所需的带宽、降低成本、提升备份和恢复性能,该技术会得到越来越广泛的认可。
[1]廖海生.基于重复数据删除技术的数据容灾系统的研究[D].华南理工大学,2009.
[2]王树鹏.重复数据删除技术的发展及应用[J].中兴通讯技术,2010(10):9-13.
[3]Muthitacharoen A,Chen B,Maziéres D.A low-bandwidth network file system.In:Proc.of the 18th ACM Symp.on Operating System Principles(SOSP 2001).New York:ACM Press,2001:174-187.
[4]敖莉,舒继武,李明强.重复数据删除技术[J].软件学报,2010(5):916-929.
