一种基于用户需求协作修正的构件检索方法
2011-02-06钟鸣张尧学周悦芝田鹏伟翁林开
钟鸣,张尧学,周悦芝,田鹏伟,翁林开
(1. 清华大学 信息科学与技术国家实验室,北京,100084;2. 清华大学 计算机科学与技术系,北京,100084)
一种基于用户需求协作修正的构件检索方法
钟鸣1,2,张尧学1,2,周悦芝1,2,田鹏伟1,2,翁林开1,2
(1. 清华大学 信息科学与技术国家实验室,北京,100084;2. 清华大学 计算机科学与技术系,北京,100084)
针对当前主流的构件检索方法只从构件分类和索引的角度出发研究提高构件检索效率,却忽略用户理解与构件描述之间差异的现状,提出一种基于用户需求协作修正的构件检索方法。该方法采用向量对构件功能和用户需求进行统一描述,并基于向量内积相似度实现构件检索;并在此基础上引入反馈机制,根据用户的历史检索记录创建和维护用户需求协作修正模型,通过该模型来对新的用户需求进行协作修正,以此缩小用户理解与构件分类描述之间的差异,提高构件检索效率。在构件库原型系统中分别以平均检索时间和平均目标位置为标准对该方法进行性能评测。研究结果表明:在基于向量的构件检索方法中,对用户需求进行协作修正能有效提高构件检索的准确度,缩短构件检索时间。
软件复用;构件检索;向量;协作修正
随着计算机技术的发展,软件开发的模式逐渐由“以计算机为中心”向“以人为中心”转变。用户对各种程序和服务提出了更加智能化、个性化、综合化的需求。从这种发展趋势中可以看出,面向终端用户的应用程序个性化定制将是未来主要的软件和服务开发模式之一,因此,软件复用[1]和基于构件的软件开发技术[2]以及主动服务的思想[3]逐渐成为软件工程的主流。软件复用过程中的一个重要环节是构件检索,快速准确的构件检索技术能大大提高软件复用的效率。传统的构件检索方法[4−8]主要基于刻面分类[9]与匹配来实现,在 REBOOT等[10−12]上都被采纳使用,能保证一定的查全率和查准率。Gibb等[13]在可复用软件构件研究项目中引进了 XML作为构件描述的标记语言,并应用XML检索语言XML-SQL来完成构件检索的任务。王渊峰等[14]将树匹配的方法结合进构件刻面描述的匹配,提出了一个包含3 个层次和5 种匹配类型的可复用构件刻面描述的匹配模型,扩展了刻面检索的匹配空间。上述方法虽然在一定程度上能满足用户的构件检索需求,但仍存在一些问题。一方面,现有方法大都只注重于将满足用户需求的构件返回给用户,由于刻面分类的粒度较大,对用户需求的描述也不够细化,所以构件检索系统无法根据用户需求对检索结果集合中的构件进行有效的区分;另一方面,上述方法默认构件库的构件分类描述模式与大众用户的理解方式是完全一致的,没有采用用户反馈机制来对构件描述或者用户需求进行引导修正,当出现用户理解与构件功能描述模式出现差异时,用户将很难从大量的返回结果中检索到自己真正想要的构件。随着构件数目逐渐增多,构件功能逐渐细化,使得上述问题日趋严重。因此,为了细化构件功能和用户需求的描述粒度,增加各个构件之间的功能区分度,同时缩小用户理解与构件功能描述模式出现差异,以提高构件检索的准确率,本文作者提出一种基于用户需求协作修正的构件检索方法。采用向量空间模型[15]对构件和用户需求进行功能描述,以向量之间的内积相似度作为判断构件是否满足用户需求的标准。在此基础上,为了尽可能提高用户需求描述的准确性,设计了基于用户检索历史的用户需求协作修正算法,通过记录构件库的历史检索信息并从中提取协作修正模型,对新到来的检索需求进行协作修正,以达到缩小用户需求和实际目标构件描述之间的自然语言理解共性差异的目的,便于用户快速定位和筛选所需要的构件。
1 构件检索总体框架
要实现基于构件的软件复用,最基本的因素是有丰富的构件资源和快速准确的构件检索方法,保证在构件检索过程中有较高的查全率和查准率。构件检索的过程一般包括 3步:1) 用户提交检索请求;2) 检索系统逐个匹配构件判断是否满足用户需求;3) 系统返回检索结果列表并由用户挑选所需要的构件进行复用。显然,其中最关键的就是将用户需求与各个构件进行匹配的过程。构件分类与描述是否准确、是否能被用户理解,用户所提出的需求是否完善合理,这些都会直接影响系统查全率和查准率的高低。为解决上述问题,作者主要采用基于向量空间模型的构件检索方法,通过专家评估和实践检验的方式,不断完善用于构件分类与描述的功能特征关键词体系,使之尽量合理准确;在此基础上引入反馈机制,依据用户的历史有效检索记录对用户的新检索需求进行协作修正,以此提高用户需求描述相对于构件分类体系的准确性。引入用户需求协作修正机制后的构件检索过程如图1所示。

图1 基于用户需求协作修正的构件检索流程图Fig.1 Process of component retrieval based on collaborative revision of user requirement
1.1 基于向量空间模型的构件检索过程
构件功能是构件检索的重要指标,也是用户理解构件的基础。这里主要采用向量空间模型来表示构件功能描述和用户需求。用 1组功能特征关键词f1,f2,…,fn作为空间的基准,则构件库的构件功能向量空间F可以表示为:F=(f1,f2,…,fn)(其中,n为关键词向量的维度)。根据每个构件的功能描述文本信息,采用归一化词频统计规则可以计算各个功能特征关键词的权重,在经过归一化处理以后就形成构件的功能描述向量ci=(ci1,ci2,…,cin)(其中,cij为构件ci与第j个功能特征关键词fi的相关度)。同样,每次用户提出的检索需求也可以用向量来表示:q0=(q01,q02,…,q0n)(其中,q0i为用户在第i个功能特征关键词fi下的需求强度)。显然,所有构件描述向量和用户需求向量的维度为n。用向量内积计算向量之间的相似度,设vi=(vi1,vi2,…,vjn),vj=(vj1,vj2,…,vjn)分别表示构件功能描述向量和用户需求向量,则两者之间的向量相似度为:
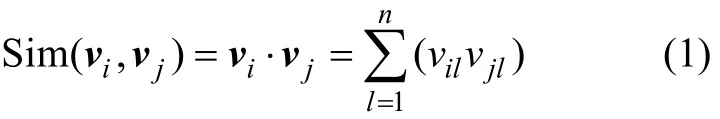
构件功能向量和用户需求向量之间的向量相似度可以作为判断构件是否满足用户需求的标准,以此实现构件检索。对于每个构件ci,相对于当前用户需求q0的匹配度Yi的计算公式为:
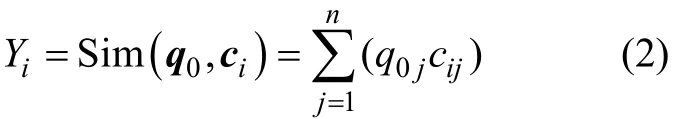
对于匹配度大于一定阈值的构件,认为满足用户需求,将这些构件与用户需求的匹配度按从大到小排序。排在前面的构件,表示其与用户的复用需求更接近,被用户选择的可能性越大。
1.2 用户需求协作修正过程
采用向量空间模型来表示构件和用户需求并实现构件检索的方法,能比较准确地提取出构件的功能特征,在功能层面上对构件和用户需求进行量化表示,在一定程度上细化了两者的描述粒度,以此在构件检索时增加各个构件之间的功能区分度,提高构件的检索效率。但是,在基于向量空间模型的构件检索过程中,用户最终所选择的构件,其功能描述向量一般不会与用户需求向量完全一致,这反映了用户对构件功能的理解和构件实际功能描述之间的差异。这种差异越大,构件检索的效率就会越低。因此,为了尽可能提高构件描述和用户需求描述的准确性,从而提高构件检索的效率,在基于向量空间模型的构件检索方法基础上增加了对用户需求进行协作修正的模块,根据构件库的历史有效检索信息,对用户检索需求进行协作修正,以缩小用户需求和实际目标构件之间的差异。用户需求协作修正模块主要由检索日志库、协作修正模型和协作修正引擎3部分组成。
检索日志库主要对构件库进行的有效检索操作进行记录。用户每一次成功的构件检索操作都包括提出构件检索需求和筛选提取构件2个动作。检索系统会将最匹配用户需求的构件按照向量匹配程度从高到低列出,用户从中选择所需要的构件;因此,用户的需求和所挑选的构件就作为1条反馈记录被保存到检索日志库中。
协作修正模型是根据检索日志库中的历史记录信息所提取出来的,其核心思想是用统计大众用户在检索构件过程中所反映出来的需求描述与构件描述之间的差异,以便于在今后的检索中消除这种差异,提高构件检索的准确度。
协作修正引擎负责对用户新需求进行协作修正。将协作修正模型作用到用户新需求中,得到1个协作修正向量,按照一定的权重融合到用户需求中,使用户检索需求更加贴近用户实际所需构件。
2 基于检索历史的需求协作修正方法
2.1 用户需求协作修正模型
在基于向量空间模型的构件检索过程中,用户每次成功检索都会产生用户需求向量和最终用户所提取构件的构件功能描述向量。在构件检索系统中,将上述信息记录下来,创建 1个检索日志库,记为R={r1,r2,…,rm}(其中,m为历史检索记录的数目)。日志中的每项ri(i=1,2,…,m)均是 1条有效的历史检索记录,定义为:ri=(qi,wi)(其中,qi=qi1,qi2,…,qin),是第i条记录中的用户需求向量;wi=(wi1,wi2,…,win),是第i条记录中的构件描述向量)。
为了避免将无意义的检索记录添加到检索日志库中,规定:如果用户在其检索需求所对应的检索结果的前100个构件中筛选出所需要的构件,则是一次有效的构件检索过程;否则,表示用户并不是真正依靠其所提出的检索需求找到的构件,这样的检索记录会影响日志库的总体参考价值,不能被添加到检索日志库中。另外,在构件检索过程中,用户需求向量是否归一化都不会影响检索结果的排序,但是在将检索记录放入检索日志库之前,每个历史需求向量都必须进行归一化处理,以保证各个记录重要程度的一致性。
用户需求协作修正是根据检索日志库中的记录对新到来的用户需求进行修正改进,使其更加接近实际目标构件。其设计思想是从构件库的历史检索记录中找出用户共性的检索习惯,统计用户各类检索需求与目标构件之间的平均差异,并作用到新的检索需求中以削弱这种差异。记用户提出的新检索需求为q0=(q01,q02,…,q0n)。通过向量内积计算,将q0与记录表中的所有历史用户需求进行相似度比较。若新用户需求与历史记录中的需求向量相似度越高,则表示该历史用户需求向量所对应的构件功能描述向量越接近用户的真实需求,也就越具有构件检索的参考价值。将新检索需求与各个历史需求进行相似度计算,其结果作为权重用于对应的构件描述向量中,再将所得向量全部累加起来,就可以得到1个新的用户检索需求向量,定义为修正需求向量qrev,其计算公式如下:
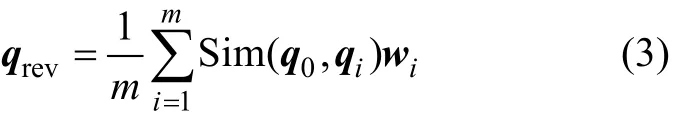
这里需要将用户原始需求向量q0和修正需求向量qrev分别进行归一化,得到q′0和q′rev。最后,将归一化修正需求向量以一定的比例t整合到用户原始归一化需求向量中,得到最终的用户检索需求向量q′rev。

其中:t是 0~1之间的一个数字,代表修正需求向量在最终检索请求中的权重,其取值范围为 0~1,可以由用户根据实际情况决定。若用户对当前所需要的构件比较熟悉,能提出比较准确的检索需求,则可以将t设置得较小,甚至为0;而当用户对当前构件库的功能特征关键词分类不熟悉,无法确定自己所提出的需求是否合适时,一般将t设置得比较高,可获得较大程度的协作修正。
上述对用户检索需求进行协作修正的过程,在每次用户检索时都需要与库中的所有记录进行比较,这样,当检索历史逐渐增多时,计算修正向量qrev所需要的时间会越来越长,不满足实际操作的实时性,因此,对上述计算公式进行推导和演化,从中提取用户需求协作修正模型。过程如下:
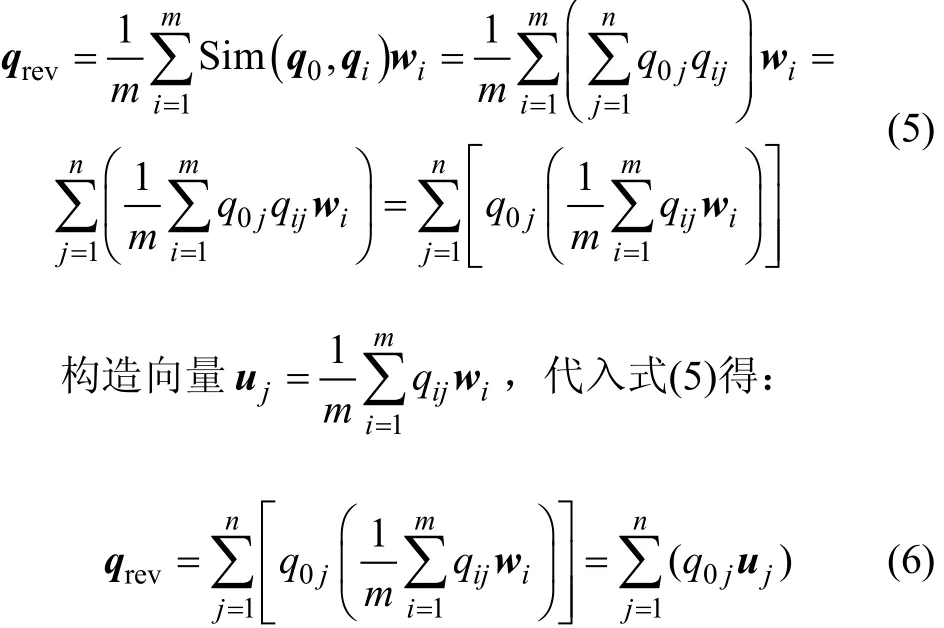
因此,得到向量集合U={uj,j=1,2,…,n}为用户需求的协作修正模型。可以发现,模型U与历史检索记录数目m无关,其规模只与向量的维度n相关。这意味着将历史检索记录进行建模以后,能有效地降低用户需求协作修正的计算量,使操作时间保持在一个恒定较短的时间内,且模型占用的空间也不会变大。
2.2 模型维护
用户需求协作修正模型U根据构件库的检索历史记录创建,当构件库完成1次新的有效检索过程之后,需要将新的检索记录融合到协作修正模型中,保证该模型实时更新。采用增量学习机制对用户需求协作修正模型U进行维护。步骤及证明过程如下。
(1) 假设原始模型U根据m条历史检索记录创建,新出现p条有效检索记录R′={rm+1,rm+2,…,rm+p}。则需要根据这p条新的检索记录,采用上述建模方法创建协作修正增量模型U′={uj′,j=1,2,…,n},其中第j个分量为:
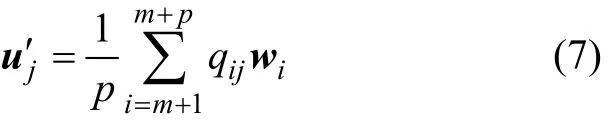
(2) 将增量模型中的每一项uj′以向量加法的形式,加到相应的原始模型各项中,得到新的协作修正模型Unew。对于Unew中的第j个分量unew−j,可得:
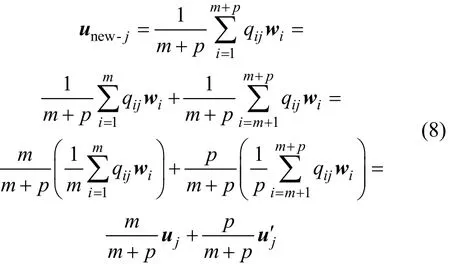
由上述推导可知:该模型U具有可加性,可以采用增量学习机制对用户需求协作修正模型进行维护,只针对新保存下来的用户有效检索记录创建增量模型,将增量模型直接叠加到原有模型上以得到新的协作修正模型。这样,就不需要在新记录到来时对整个模型重新计算,能有效地控制模型维护代价。
3 实验分析
设计了一个构件库原型系统 LCRS(Local component retrieval system)(Microsoft NET 2003 +SQL2000),实现了本文所提出的基于向量空间模型的构件检索方法,并根据历史检索记录对新到来的用户需求的协作进行修正。该构件库选择了构件功能描述中常用的且区分度较明显的500多个词作为功能特征关键词,对从 Active-X,Alphaworks,ComponentSource以及MFC和STL等库中选取出来的14 061个构件进行了统一的向量化功能描述。
实验设计为:参与实验的10人分别在基于向量空间模型的构件检索系统中完成对 10个目标构件的 2组检索。这10个构件的概要描述都提供给这些实验人员。第1组实验中,系统不支持对用户需求的协作修正,直接用实验人员提出的检索需求查找相关构件,并排序返回给用户筛选目标构件;第2组实验中,系统开启用户需求协作修正功能,该系统的检索日志库中已经保存8 000多条历史检索记录信息,并创建协作修正模型。实验人员用同样的检索需求重新查找这10个目标构件,系统在进行构件检索之前会将实验人员的需求进行协作修正。
在实验中,主要记录以下2个方面信息作为实验比较的指标:
(1) 用户检索目标构件所需要的平均时间(ART)。用户检索到目标构件的过程,包括用户提出检索需求、检索系统匹配计算并反馈结果以及用户从结果中顺序查找目标构件。通过统计用户找到目标构件的平均时间,可以比较构件检索方法的检索效率;平均时间越短,则检索效率越高。
(2) 目标构件在用户检索结果中所处的平均位置(ATP)。在不同的检索方法下,当用户提出针对同一目标构件的检索需求时,目标构件会出现在检索结果序列的不同位置。目标构件位置越靠前,越容易被用户找到,则表示该检索方法的准确度越高。
在实验中,根据实践经验,将协作修正的参数t设为0.3。10名实验人员分别用无协作修正的方法和有协作修正的方法检索10个构件,将每个构件的平均位置和平均检索时间记录下来,实验结果如图2和图3所示。
从图2和图3可见:经过对用户需求进行协作修正操作以后,构件检索的平均时间明显缩短,由原来的40~80 s范围减少到30~50 s;同时,目标构件在检索结果列表中的位置也大大提前,由原来的平均排名4~7位提高到2~4位。这说明有协作修正构件检索与没有协作修正的构件检索准确度相比提高幅度较大。对于上述实验结果,在增加了用户需求协作修正操作的检索实验中,系统进行检索操作前需要先对用户需求进行修正,这个过程需要多消耗一个恒定的时间;但修正后的用户需求使得目标构件在检索结果列表中的位置提前,基本出现在列表的前10位,有利于用户快速定位目标构件,有效缩短了整个构件检索过程的时间。

图2 2种方法的平均检索时间比较Fig.2 Comparisons of ART between two methods
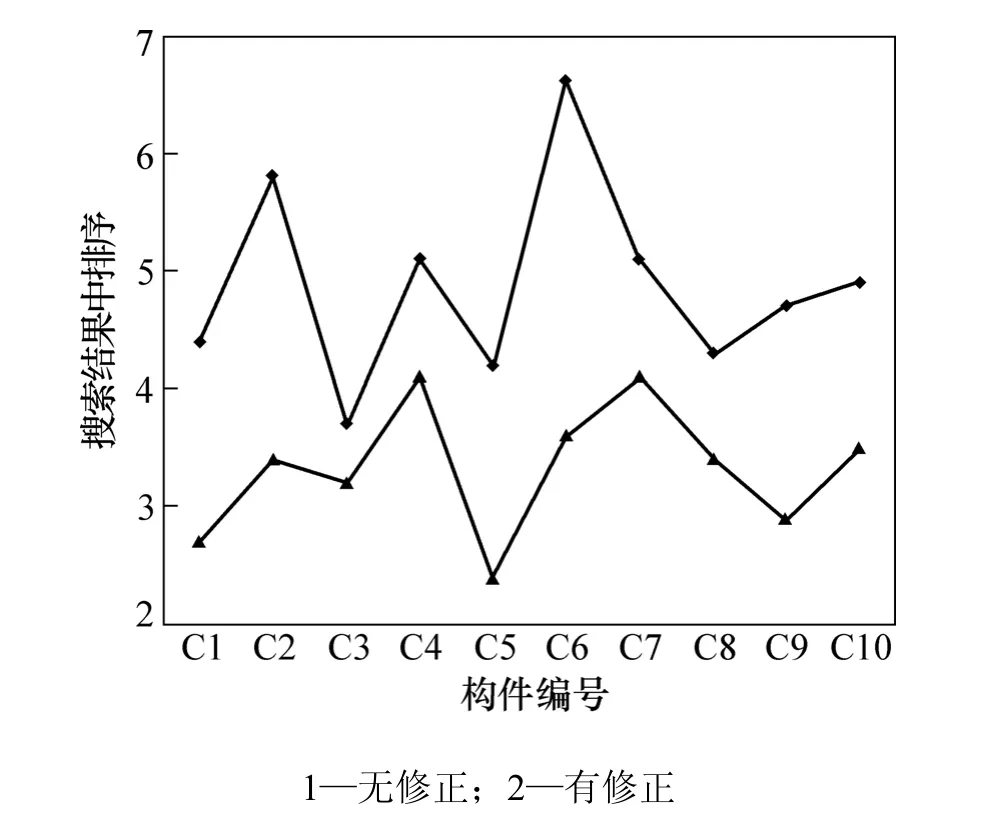
图3 2种方法的目标构件位置比较Fig.3 Comparisons of ATP between two methods
实验结果还表明:用户在不十分了解构件的分类与描述机制时,所提出的检索需求向量会与其实际所需要的构件向量存在一定的差异。这种差异导致并非用户需要的构件排名靠前,影响用户最终从结果列表中筛选构件的效率。而本文作者所提出的用户需求协作修正方法有效地削弱了这种差异,使得用户需求更加接近目标构件,目标构件在结果列表中的排名明显提升,大大提高了构件的检索效率。
4 结论
(1) 为了提高软件复用过程中构件检索的效率,提出了一种基于用户需求协作修正的构件检索方法。
(2) 采用向量对构件功能和用户需求进行描述,以向量之间的内积相似度来检索构件,并对检索结果进行排序。在此基础上,引入检索反馈机制,基于用户检索历史对用户需求进行协作修正,并针对协作修正过程计算开销较大的情况,推导和提取了用户需求协作修正模型,通过增量学习机制对该模型进行维护。
(3) 基于用户需求协作修正的构件检索方法能明显缩短构件检索的时间,有效提高了构件检索准确率,便于用户快速定位所需构件,为构件检索提供了新的思路。
[1]Mili H, Mili F, MILI A. Reusing software: Issues and research direction[J]. IEEE Transactions on Software Engineering, 1995,21(6): 222−232.
[2]Wolfgang P. Component-based software development: A new paradigm in software engineering?[C]//Proceedings of the 4th Asia-Pacific Software Engineering and International Computer Science Conference. Hong Kong: Springer Verlag, 1997:523−524.
[3]张尧学, 方存好. 主动服务: 概念、结构与实现[M]. 北京: 科学出版社, 2004: 29−41.
ZHANG Yao-xue, FANG Cun-hao. Active service: Concept,architecture and implementation[M]. Beijing: Science Press,2004: 29−41.
[4]Frakes W B, Pole TP. An empirical study of representation methods for reusable software components[J]. IEEE Transactions on Software Engineering. 1994, 120(8): 617−630.
[5]DOU Yu-hong, ZHANG Yao-xue, LI Xing: An XML-based software component description method for program mining[J].Chinese Journal of Electronics, 2004, 13(1): 100−104.
[6]YANG Yong, ZHANG Wei-shi, ZHANG Xiu-guo, et al. A weighted ranking algorithm for facet-based component retrieval system[C]//Proceedings of the 25th International Conference on Software Engineering. Portland: IEEE Computer Society, 2006:274−279.
[7]Shasha D, Tsong J, Wang L. Exact and approximate algorithm for unordered tree matching[J]. IEEE Trans on Systems Man and Cybernetics, 1994, 24(4): 668−678.
[8]姚全珠, 丁新村, 雷西玲, 等. 基于遗传算法的刻面权重构件检索方法的实现[J]. 计算机工程与应用, 2008, 44(6): 127−129.
YAO Quan-zhu, DING Xin-cun, LEI Xi-ling, et al. Implement of component retrieval method based on genetic algorithm with facet-weight[J]. Computer Engineering and Applications, 2008,44 (6): 127−129.
[9]Poulin J S, Yglesias K P. Organization and component classification in the IBM reuse library[R]. New York:Technology Support Center International Business Machines Corporation, 1993: 6−20.
[10]Morel J M, Faget J. The REBOOT environment[C]//Proceedings of the 2nd International Workshop on Software Reusability Advances in Software. Lucca: IEEE Computer Society Press,1993: 80−88.
[11]NEC Software Engineering Laboratory. NATO standard for management of a reusable software component library[C]//NATO Communications and Information Systems Agency.Tokyo, 1991: 32−43.
[12]常继传, 李克勤, 郭立峰, 等. 青鸟系统中可复用软件构件的表示与检索[J]. 电子学报, 2000, 28(8): 20−24.
CHANG Ji-chuan, LI Ke-qin, GUO Li-feng, et al. Representing and retrieving reusable software components in JB (Jadebird)system[J]. Electronica Journal, 2000, 28(8): 20−24.
[13]Gibb K, McCartan C, O’Donnell R, et al. The integration of information retrieval techniques within a software reuse environment[J]. Journal of Information Science, 2000, 26(4):520−539.
[14]王渊峰, 薛云皎, 张涌, 等. 刻面分类构件的匹配模型 [J].软件学报, 2003, 14(3): 401−408.
WANG Yuan-feng, XUE Yun-jiao, ZHANG Yong, et al. A matching model for software component classified in faceted scheme[J]. Journal of Software, 2003, 14(3): 401−408.
[15]Salton G, Lesk M E. Computer evaluation of indexing and text processing[J]. Journal of ACM, 1968, 15(1): 8−36.
(编辑 陈爱华)
A novel component retrieval method based on collaborative revision of user requirement
ZHONG Ming1,2, ZHANG Yao-xue1,2, ZHOU Yue-zhi1,2, TIAN Peng-wei1,2, WENG Lin-kai1,2
(1. Tsinghua National Laboratory of Information Science and Technology, Tsinghua University, Beijing 100084, China;2. Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China)
Current methods of component retrieval focus mainly on improving the retrieval efficiency by using advanced classification and index, but ignores the discrepancy between user understanding and component description, thus a novel method for component retrieval based on collaborative revision of user requirement was proposed, which describes both components and user requirements in the format of vectors, and calculates their inner product to get the matching degree of each component. Furthermore, a model of collaborative revision was presented to collaboratively revise user’s new requirement according to the feed-back of user retrieval history, leading to minifying the discrepancy between user understanding and component description and improving the efficiency of component retrieval. Several experiments were made on the component repository prototype by the metrics of average retrieval time and average target position. The results show that, using the user requirement of collaborative revision, the vector based component retrieval method has higher retrieval accuracy and takes shorter time to find the target component.
software reuse; component retrieval; vector; collaborative revision
TP311
A
1672−7207(2011)02−0398−06
2009−11−07;
2010−03−25
国家自然科学基金资助项目(90604027);国家“十五”计划项目(2005BA115A02)
钟鸣(1983−),男,浙江绍兴人,博士研究生,从事软件复用和软构件技术研究;电话:13810091575;E-mail:zhongm83@gmail.com
book=403,ebook=97
