基于语料库的The Bridges of Madison County两个中译本研究
2011-01-04丁峻
丁 峻
(天津科技大学 外国语学院英语系, 天津 300222)
基于语料库的The Bridges of Madison County两个中译本研究
丁 峻
(天津科技大学 外国语学院英语系, 天津 300222)
美国作家罗伯特·詹姆斯·沃勒的代表作The Bridges of Madison County是20世纪最有深度和影响力的小说之一。中文译本中以大陆梅嘉的《廊桥遗梦》和台湾吴美真的《麦迪逊之桥》最为流行。采用语料库的研究方法,将梅嘉译本和吴美真译本与沃勒的小说原著建成一个小型双语语料库,从词汇和句法两个层面对译本进行分析。
语料库;翻译;词汇特征;句法特征
一、引言
传统的译本研究侧重对译本的语法、词汇、修辞或文体进行范文详解。虽然传统的译本研究比较具体、细致,但很难进行宏观和多层面的描写分析,所得出的结论往往有一些主观和片面,缺乏统计数据的支持。本文将沃勒(Robert James Waller)的小说The Bridges of Madison County、大陆梅嘉的《廊桥遗梦》译本和台湾吴美真的《麦迪逊之桥》译本建成一个小型双语平行语料库,从词汇和句法两个层面进行译本对比分析。词汇方面主要从类符形符比、词汇密度、高频词的词频分布和成语的使用五方面来分析。句法方面主要从平均句长和文本对话中语气词的使用进行分析。除了进行两个译本与原著、两个译本之间的对比外,还将译本与汉语原创小说文本进行比较。研究采用语料库的研究方法,应用语料库工具,如WordSm ith 4.0,ParaConc 269, UltraEdit等,将定量和定性研究相结合,对两个译本进行比较分析。
本研究使用的小型双语平行语料库是由陈建生教授主持的天津市“十一五”社科研究规划项目“小规模英汉双语语料库的建设与应用研究”中的一部分。汉语原创文本出自兰卡斯特现代汉语语料库(LCMC),它是2003年由Tony McEnery和肖忠华建立,容量为100万词,包括15种文体,收录的样本为500篇字数约为2 000词(3 200个汉字)的从1989到1993年中国大陆的出版物。本文使用LCMC中小说部分的语料(以下简称LCMC(W)),与梅、吴译本进行比较研究。这与传统意义的对比翻译研究有显著的区别,不仅限于原文与译文的比较。
二、两个译本的词汇特征
1 类符形符比
类符形符比(TTR)指的是文本中类符(type)和形符(token)的比率,它可以在一定程度上反映语料用词的变化和丰富程度。Baker(1995)指出,TTR的比率越高,该文本所使用的不同词汇越多。通过这一比率可以比较不同语料词汇变化的大小。但如果语料库的容量越大,类符形符比就会越小,不同容量的语料库就不具有可比性。语言学家一般用标准类符形符比(STTR)来衡量语料库词汇的变化,即每1 000个形符计算一次类符形符比,再求平均值。表1是用WordSmith 4.0分别统计的三个语料的类符、形符、类符形符比和标准类符形符比。
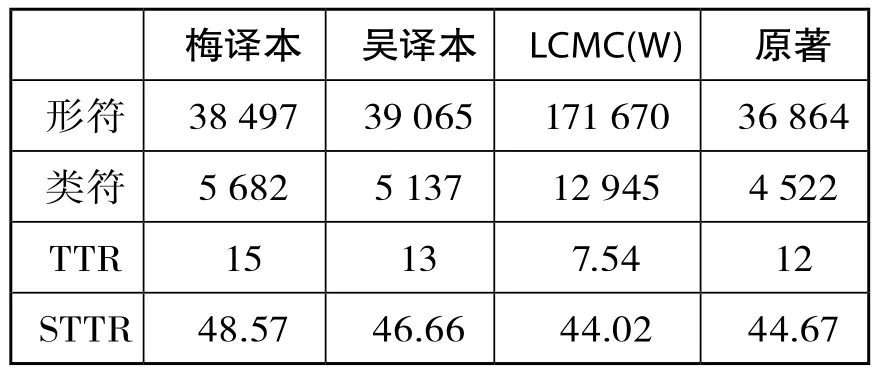
表1 三个语料的类符形符比
从表1的统计数据可以看出,梅、吴译本、LCMC(W)和原著的形符分别为38 497、39 065、171 670和36 864。由于四个语料的容量有一些差异,我们采用标准类符形符比进行比较。梅、吴译本的STTR分别为48.57和46.66,前者比后者高1.91%,也就是说,梅译本中的不同词汇量比吴译本要高。虽然吴译本比梅译本多568个形符,但梅译本的词汇变化还是比吴译本更丰富、更多样。比如,梅译本将carefully译为“小心翼翼”、“小心”、“仔细”和 “好好”,而吴译本仅用了“小心翼翼”。
和 LCMC(W) 中 的 STTR 44.02相 比,梅译本和吴译本分别比其多4.55和2.64。Laviosa(2002)认为,在来自多种英语源语的可比语料库中,翻译文本的词汇范围比非翻译文本的词汇范围窄。Laviosa发现这一现象与源语的类型无关,即无论译文译自何种语言,都有这种简略化的趋势。和Laviosa的预测相反,梅译本和吴译本在用词的丰富程度上都高于汉语原创小说。从某种程度上讲,梅译本和吴译本属于个案。Laviosa的观点反映的是译本总体的简化趋势。差异的产生可能受语料库工具的精度和LCMC(W)取样范围的影响。
和原文本相比,梅译本和吴译本分别多1 663和2 201个形符。译本比原著长是因为要把原著中隐含的意思表达清楚(Nida &Taber, 2004)。吴译本共加注22次,而梅译本只有4次。例如:
(1)He liked other words, such as “distant,”“woodsmoke,” “highway,” “ancient,”“passage,”“voyageur,” an “India” for how they sounded, how they taste and what they conjured up in his mind.
吴译本: 他也喜欢其他字,例如 distant,woodsmoke,highway, ancient,passage,voyageur和India(意思分别是遥远、林烟、公路、古代、航海、樵夫和印度),他喜爱这些字听起来和尝起来的感觉,以及它们在心中唤起的事物。
吴译本不但将原作者使用的词列举出来,还分别把这些词以加注的形式翻译出来。加注的翻译形式可以使译文更清楚易懂,这也是吴译本在三个语料中最长的原因之一。
英语在台湾比大陆更普及,吴译本常常直接使用原文而不加翻译和标注。吴译本尽量保留原文的表达特点,以便将源语文化原汁原味地呈现给目的语,有外显化的趋向。而梅译本中无此现象,它的目标读者是对美国文化不太了解的大陆读者。梅译本运用流畅、清晰的表达尽量消除原文的异域感。两个译本采用了不同的翻译策略。
Baker(1995: 236-237)认为,比较译文和原文的TTR可以看出翻译过程中词汇的简略化。两个中译本的STTR都高于原著从某种程度上说明两个译本的独特性。两位译者都是非常优秀和经验丰富的翻译家,不仅精通英语,汉语也有很深的造诣。在翻译过程中,她们都努力使译文更流畅,使读者读起来更赏心悦目,符合目的语的规范。就类符形符比而言,梅译本和吴译本仍属于小说文本,它们的STTR高于非小说文本。与其他翻译小说不同的是,它们的STTR高于原著,说明两个译本用了更多的词汇,且词汇更富于变化。吴译本比梅译本的词汇变化要少,选词范围更窄。
2 词汇密度
词汇密度是指一个文本中实义词占总词数的比例。通常词汇密度越高,文本的实词比例越大,信息量也越大,难度也随之增大。词汇密度的统计根据Ure (1971)和Stubbs(1986)提出的计算方法:词汇密度= (实词数/总词数)× 100%。Stubbs把英语的实词分成四个词类:名词、动词、形容词和副词。汉语的词类分为实词和虚词。本文综合王力的《中国现代语法》和吕叔湘、朱德熙的 《语法修辞讲话》中对词类的分类,将名词、动词、形容词和数量词划分为实词。语料库中使用词性赋码进行词性标注。

表2 三个语料的词汇密度
从表2可以看出,梅、吴译本和原著的词汇密度分别为54.64%,53.59%和49.97%,两个译本的词汇密度分别高出4.67%和3.62%。词汇密度一般在60%~70%为高密度,40%~50%为低密度。两个译本的词汇密度介于高低密度之间。与原著相比,译本中使用了更多的实词,而原著更多地使用了功能词。梅、吴译本和原著中的介词分别为1 702,1 784和3 973个,连词分别为844,1 274和1 961个。因为汉语与英语的差异,汉语倾向意合,而英语倾向形合,英语要借助功能词,如介词或连词来传达意义,这也是原著中的介词和连词远远高于译本的原因。实词多而虚词少是两个译本的特点。梅、吴译本的词汇密度非常接近,梅译本只比吴译本高1.05%,所以阅读起来要比吴译本稍难。
两个译本的词汇密度要低于LCMC(W)的59.15%(胡显耀, 2007:217)。这进一步验证了Laviosa(2002:60-62)的观点,即翻译文本实词与语法功能词的比率低于非翻译文本(词汇密度更低)。两个译本密度降低的原因之一是名词数量的减少。名词的比例在梅、吴译本和LCMC(W)中分别为18.91%,18.97%和23.26%(胡显耀,2007:217)。名词的密度是衡量文本复杂程度的一种方法,密度越低名词使用越少,文本越简化,更易于读者理解和接受。这符合Baker(1996:176-177)提出的在翻译文本中译者无意识地简化语言或信息的翻译普遍性之一。
3 高频词
词频列表是根据类符频率的高低列出的类符表,它可以准确、快速地显示出类符的分布情况。表3是通过WordSmith统计的词频由高到低两个译本类符的频率及其在总词频数中所占的百分比。LCMC(W)的词频数是参考胡显耀(2007)的统计结果。

表3 两个本和LCMC(W)词频表前10位的词

8一620 1.61着399 1.02在2 329 1.36 9不406 1.05了387 0.99她1 732 1.01 10着400 1.04不383 0.98你1 718 1.00
表3中梅、吴译本前10位的高频词在LCMC(W)中几乎也是高频词。表示所属关系的“的”在三个语料中都居第一位,分别占5.78%,6.80%和6.75%,其中吴译本的使用频率最高。两个译本中有8个高频词的比率都高于LCMC(W),说明和非翻译文本相比,两个译本倾向重复使用更多的高频词。从某种程度上说,这也反映出译者有尽量使用更符合目的语规范词的倾向,但过多地使用高频词会使译文有简略化的倾向,这种翻译策略会降低译本的信息量和难度。两个译本中人称代词“他”、“她”、“我”位居高频词的前五位,第三人称单数“他”更是位列第二,比率分别为3.03%和3.61%。但在LCMC (W) 中,排前4位的高频词没有人称代词,“他”位列第六。由此可见,译本中代词的使用和非翻译小说文本存在一定的差异,译者和汉语原创作者相比,更倾向使用代词,这也体现了译文明朗化和简略化的特征。
为了进一步比较两个译本的用词情况,我们以每100词为单位计算出它们的词频分布。梅译本中使用一次的词为2 917个,占总词量的7.6%,使用两次的占2.4%,三次的占1.2%;吴译本中使用一次的词为2 523个,占总词量的6.5%,使用两次的占2%,三次的占1.1%。从表4中10个等级来看,在不同的词频阶段,梅译本使用的高频词数量比吴译本要少,总体要比吴译本少5%,不仅数量相对少,而且频率相对较低,即重复的词较少,这表明梅译本比吴译本要相对难懂。词频的分布不仅反映了译本的简略化,也反映了译者倾向重复使用更多高频词。
4 成语的使用
成语、四字词或习语在汉语中很常用。在忠实于内容和风格的前提下,译文使用这样的表达可以更生动有力。借助语料库工具Concord,通过检索译本中成语和习语的赋码/i和/l,统计出梅译本共用成语和习词289次,吴译本148次。梅译本更接近汉语读者的审美要求和标准,成语或习语的使用使译文更流畅、生动。两个译本有意识地使用成语或习语体现了译本规范化的倾向,即向文本读者易于接受的表达方式靠近。这样可以使译本可读性更强,更符合译语表达习惯,更为大家所熟悉,组织结构更加连贯(Baker,1998:290)。

表4 两个译本中高频词的词频分布
三、两个译本的句法特征
1 平均句长
句子的定义通常分为两种:一是从功能上讲,是否表达了完整的意思;二是从形式上看,标点符号通常作为划分句子或分句的标志。本研究中将句法结构分为两个层面:句子层面,即以句号、问号和感叹号结尾;分句层面,即以逗号、分号、顿号、冒号、破折号结尾。
Butler (1985:21)根据句子的长度将句子分为三类:短句(1~9词)、中句(10~25词)和长句(超过25词)。沃勒原著的平均句长是12.46,属于中等长度的句子,接近短句,分句长度属于短句范畴。梅、吴译本的平均句长分别为15.97和14.47,也属于中等长度的句子,分句长度分别为6.71和6.19,属短句。和原著相比,梅、吴译本的句子更长,平均分别长3.51和2.01词。译者为了使译文更清楚明白,常常要采取一些翻译策略提高译文的明朗化程度,如增加解释性的句子、修饰语、定语或连接词,有时还要添加一些相关信息和背景材料,这无形中加长了句子的长度。但两个译本的平均句长要小于LCMC(W)的 16.68。这符合 Laviosa(2002:60-62)提出的简略化理论,即翻译文本的句子平均长度要比非翻译译本的短。数据再次印证了简略化是翻译文本的特征之一。和吴译本相比,梅译本的平均句长更接近汉语原创小说文本,这表明梅译本更接近汉语表达的规范。

表5 三个语料的平均句长
梅译本的形符数比吴译本少568个,但句子平均却比吴译本长1.5词。梅、吴译本除使用分译方法各112和104次外,还使用合译方法各479和201次。为了使译文读起来更自然、连贯,更符合汉语的表达习惯,梅译本有时改变了原著中的句子结构或表达顺序,这也是它的句子要比吴译本长的原因之一。例如:
(2)There are songs that come free from the blue-eyed grass, from the dust of a thousand country roads.
梅译本: 从开满蝴蝶花的草丛中, 从 千百条乡间道路的尘埃中 , 常有关不住 的歌声飞出来。
吴译本: 有些歌悠然自在地从鸢尾草, 从千条乡村道路的灰尘中传来。
这是小说的第一句,两位译者可以说都译出了句子的韵味和意境。吴译本共用了17个词,是完全按照句子结构顺序的直译。梅译本共用24个词,为了更接近和符合汉语读者的表达习惯,将状语放在了句子开头,译文读起来更自然顺畅。
2 文本对话中语气词的使用
现代汉语可以用各种语气词表示不同的语气。语气词在现代汉语口语里运用得很普遍。语气词本身并没有意义,常附着在句尾,表明说话人的态度。根据语气的不同,句末语气词可以分为四类:(1)表示陈述语气的语气词,如“吧”、“呢”、“啊”、“啦”等 ;(2)表示疑问语气的语气词,如“吗”、“呢”、“吧”、“啊”等;(3)表示祈使语气的语气词,如“吧”、“啊”等;(4)表示感叹语气的语气词,如“啊”等。在文学作品中,研究对话是分析人物思想最有效的手段之一。对话在形式和内容上都不同于非对话句子。译者要将英语对话翻译成汉语,就要考虑对话的语言特征。语气词的使用可以作为研究翻译文本句法特征的一个方法。

表6 两个译本中的语气词
总体来看,梅译本比吴译本使用语气词更频繁,分别为92次和65次。两个译本在语气词的使用上有一些差异,比如,“呢”、“吧”、“吗”和“啊”的使用在两个译本中就相对悬殊,这种差异反映了译者的选词倾向。梅译本中使用“呢”、“吧”和“吗”分别为10,32和38次,而吴译本则分别为2,17和22次。但吴译本使用“啊”的次数远高于梅译本。梅译本使用“啦”和“哦”各2和4次,而吴译本没有涉及。吴译本使用“喔”和“哩”各1和3次,而梅译本没有使用。两个译本选择语气词的倾向反映了不同方言区的特点,梅译本使用的是大陆普通话,而吴译本使用的是台湾国语,两种译本显示出同一种语言的地域化差异。根据统计,梅译本比吴译本更多地使用了句尾语气词,也就是用于连接语篇的标志词。梅译本更注重语篇的衔接,译者尽量用更多的语气词使译文更符合、更贴近汉语的表达习惯和形式。
四、结语
就词汇层面而言,两个译本的标准形符类符比要高于原著和汉语原创小说文本,反映出两个译本用词的丰富性和多样性。两个译本的词汇密度高于原著,也就是实词的比例高于原著,但低于汉语原创小说文本,这印证了Laviosa的理论。两个译本高频词的使用比例远远高于汉语原创小说文本和高频词的词频分布都说明了译本的用词倾向。就句法层面而言,两个译本的句子比原著长,但比汉语原创小说文本要短。两个译本中语气词的使用也反映了译者不同的翻译风格。两个译本倾向使用更多的词汇,特别是实词,重复使用一定数量的常用词等特征反映了Baker提出的翻译简化和常规的操作规范。
通过基于语料库的研究可以看出,梅、吴译本存在一定的差异。梅译本在用词的丰富性、实词的比例等方面都高于吴译本,语气词和成语的大量使用表明梅译本更偏重汉语的表达习惯。清晰、流畅的翻译风格减少了目标语的异域感,尽可能使用符合汉语的表达习惯。吴译本则更忠实于原文,无论从词汇密度还是标准形符类符比上看,都更接近原文,更忠实地再现了原文的意境,整个译文有外显化的倾向。
[1] Baker, M. Corpora in Translation Studies: An Overview and Suggestions for Future Research [J].Target, 1995, 7 (2):223-243.
[2] Baker, M.Routledge Encyclopedia of Translation Studies[M]. London : Routledge, 1998.
[3] Butler, C.Statistics in Linguistics[M]. Oxford: Basil Blackwell, 1985.
[4] Laviosa, S.Corpus-based Translation Studies: Theory, Findings, Applications[M]. Amsterdam: Rodopi, 2002.
[5] Nida, E. A. & C. R. Taber.The Theory and Practice of Translation[M]. 上海:上海外语教育出版社, 2004.
[6] Stubbs, M. Lexical Density: A Technique and Some Findings [A].In M. Coulthard (ed.)Talking about Text: Studies Presented to David Brazil on His Retirement,Discourse Analysis Monograph (13)[C]. Birmingham: English Language Research, University of Birmingham, 1986. 27-42.
[7] Ure, J. Lexical Density and Register Differentiation[A]. In G. Perren & J. L. M. Trim (eds.)Applications of Linguistics[C].Cambridge: Cambridge University Press, 1971. 443-452.
[8] Waller, R. J.The Bridges of Madison County[M]. 北京:外文出版社, 1996.
[9]胡显耀.基于语料库的汉语翻译小说词语特征研究[J]. 外语教学与研究,2007,(3).
[10]梅嘉.廊桥遗梦[M]. 北京:人民文学出版社,2004.
[11]吴美真.麦迪逊之桥[M].台北:时报文化,1993.
The Bridges of Madison Countyby American w riter Robert James Waller is considered one of the most profound and powerful novels in the 20th century. The two most popular Chinese versions areLang Qiao Yi Mengby Mei Jia in mainland China andMai Di Xun Zhi Qiaoby Wu Meizhen in Taiwan. From a corpus-based approach, this paper builds a small-scale parallel corpus of two Chinese versions and the original to make a lexical and syntactic analysis on the Chinese versions.
corpus; translation; lexical features; syntactic features
H 315.9 < class="emphasis_bold">文献标识码:A文章编号:
1008-665X(2011)01-0044-06
2010-06-28
丁峻(1971-),女,副教授,研究方向:语料库语言学、文体学
