粒子群算法与主成分析法在支持向量机回归预测中的应用研究*
2010-11-27周方军吕文元
周方军,吕文元
(上海理工大学 管理学院,上海 200093)
预测是国家、企业等组织制定政策和计划的主要依据,因而预测的准确度是政策与计划制定是否科学的前提。预测的方法有传统的多元回归预测,以及近几年来发展起来的人工神经网络预测[1]、灰色预测[2]。多元回归预测模型简单、易用性强,但难以处理高维、非线性模式;人工神经网络虽然能够较好地解决高维非线性预测的难题,但它需要大量的训练样本,且泛化能力不强,所以当可得到的预测样本是小样本,或者获得大量样本的成本很高时,就难免影响其实用性和经济性;灰色预测虽具有短期预测能力强,可检验等优点,但其长期预测能力较差。Vapnik等人提出的支持向量机[3-4]是在统计学习理论基础上发展起来的一种新的机器学习算法,是目前针对小样本统计和预测学习的最佳理论,支持向量机具有完美的数学形式、直观的几何解释和良好的泛化性能,解决了模型选择与欠学习、过学习及非线性等问题,克服了收敛速度慢,易陷入局部最优解等缺点,因此支持向量机在分类和回归中均表现出优越的性能。
1 支持向量回归机的基本原理
支持向量回归机[5],主要由Vapnik提出的ε-支持向量回归机(ε-SVR)和Scholkopf等提出ν-的支持向量回归机(ν-SVR)等。本文采用Vapnik的ε-SVR支持向量回归机。
支持向量机回归实质是要在Rn空间寻找一个超平面函数y=wT·x+b,并使得该超平面与各样本点的偏离最小,其中w是超平面n-1维法向量。考虑一个样本集T={(x1T,y1),…(xlT,yl)}∈(X×Y),l为样本数,xi是 n 维向量,y∈Rn。如果采用ε不灵敏函数作为误差函数,当所有的样本点到所求的超平面的距离都不超过ε时,如图1所示,中间的实线表示ε的超平面,超平面两边的ε区域为超平面的ε带。
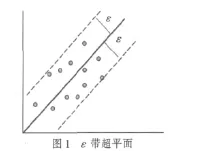
可以想象,一个最优的超平面应该是能够以最小的ε带包含训练集中所有样本点的超平面。为求得最优超平面,借鉴支持向量机分类的思想,可将其转化为一个二分类的问题:选择合适的 ε(ε≥minε),分别给每个样本点的y值加上ε或减去ε,构造新的正负两类样本点:D+=(,yi+ε;zi=+1)(i=1,2, …l),D-=(,yi-ε;zi=-1)(i=1,2,…l)。考虑会有个别样本点到超平面距离大于ε影响求解最优超平面的情况,引入松弛变量 ξi,ξ*i和惩罚参数C,构造并求解问题:

引 入 Lagrange 乘 子 ,a(*)=(a1,a*1…al,a*l)≥0, 构 造Lagrange函数,求式(1)的对偶问题得:


其中

式(2)~ 式(4)中 K(xi,xj)是 核 函 数 , 其 值 为 向 量 xi和xj在特征空间的 φ(xi)和 φ(xj)中的内积,φ(xi),φ(xj)为映射函数。核函数的作用是当样本点在原空间线性不可分时,可以通过映射函数映射到高维空间,从而达到线性可分的目的,但实际应用中映射函数的显式表达式很难找到,观察式(2)~式(4)中只用到了映射在高维空间的点积,而核函数的特点就是能使变量在低维空间核函数值等于其映射到高维空间的点积值,从而实现不需要知道显式映射函数达到向高维空间映射的目的。任何满足Mercer条件的函数均可作为核函数。
2 粒子群算法基本原理
微粒群算法最早是在1995年由美国社会心理学家Kennedy和Russell[6]共同提出,其基本思想是受鸟群觅食行为的启发而形成的。PSO算法把优化问题的解看作是D维空间中一个没有体积没有质量的飞行粒子,所有的粒子都有一个被优化目标函数决定的适应度值,而速度决定每个粒子的飞行方向和距离,粒子根据自己先前达到的最优位置和整个群体达到的最优位置来更新自己的位置和速度,从而向全局最优位置聚集。粒子根据以下公式来更新自己的速度和位置:
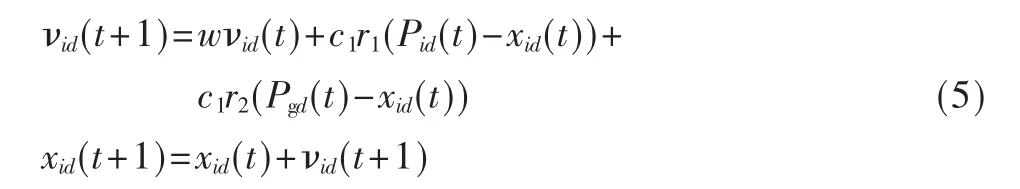
式中,下标i代表第i个粒子,下标d代表速度或位置的第 d维,t代表迭代代数,w代表惯性权重系数,c1和 c2是学习因子, 通常 c1,c2∈[0,4],r1,r2是介于[0,1]之间的随机数,Pid是粒子Pi在第 d维个体极值坐标,Pgd是粒子群体在第j维的全局极值坐标。从式(5)可知,w越大全局探测能力越强;w越小则局部探测能力越强。因此可以让w随着迭代次数的增加,而动态地减少,以保证算法有较大的机率收敛于全局最优解。但是在算法执行过程中,随着w的减少,也在一定程度上导致后期收敛速度降低,从而影响全局收敛性能。为了克服这种缺陷,Clerk构造了带收缩因子K的改进 PSO模型[7],试验结果表明收缩因子K比惯性权重系数w能更有效地控制微粒的飞行速度,同时增强了算法的局部搜索能力,模型如下:
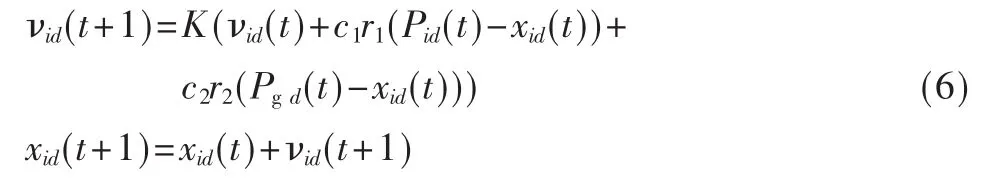
经检验,两组护生操作考试成绩不符合正态分布,故采用非参数检验Wilcoxon秩和检验,对照组护生成绩中位数为83.37分,试验组护生成绩中位数为89.73分,两组比较:Z=-6.501,P=0.000。
3 主成分析原理
主成分析[8]是利用数学上处理降维的思想,将实际问题中的多个相关性较高的指标设法重新组合成一组新的少数几个互不相关的综合指标来代替原来指标的一种多元统计方法,通常把转化生成的综合指标称为主成份,其中每个主成份都是原始变量的线形组合。主成份要尽可能多地反映原来指标的信息,而且要有较好的解释意义。降维的步骤:(1)将原始数据标准化以消除量纲影响;(2)计算变量的相关系数矩阵 R=(rij)p′p,其中 rij(i,j=1,2,…,p)为原来变量 xi与 xj的相关系数;(3)计算R的特征值及相应的特征向量,即 λ1≥λ2,…≥λp≥0然后分别求出对应于特征值 λi的特征向量 ai(i=1,2,…,p),且 ai是正交单位特征向量;(4)写出主成份 Fi=a1iX1+a2iX2+…+apiXp(i=1,…,p)。
4 应用实例
试验从UCI上选取美国波斯顿地区1993年城镇住房数据作为试验数据[9]。试验步骤如下:
(1)应用主成分析法降维
由于统计软件SPSS提供了主成份分析功能,而且具有采用交互式、图形化操作界面、结果图形化输出、直观性强等优点,故本文采用SPSS16.0作为降维工具,表1为最大方差旋转后的因子载荷图,从表中可以看出,7个主成份都有很好的解释意义(载荷绝对值>0.5,说明变量与主成份存在相关性)。主成份1为城镇生活环境,主成份2为治安环境,主成份3为人口密度,主成份4为人口层次,主成份5为是否有河流,主成份6为商业环境,主成份7为教育发展水平。
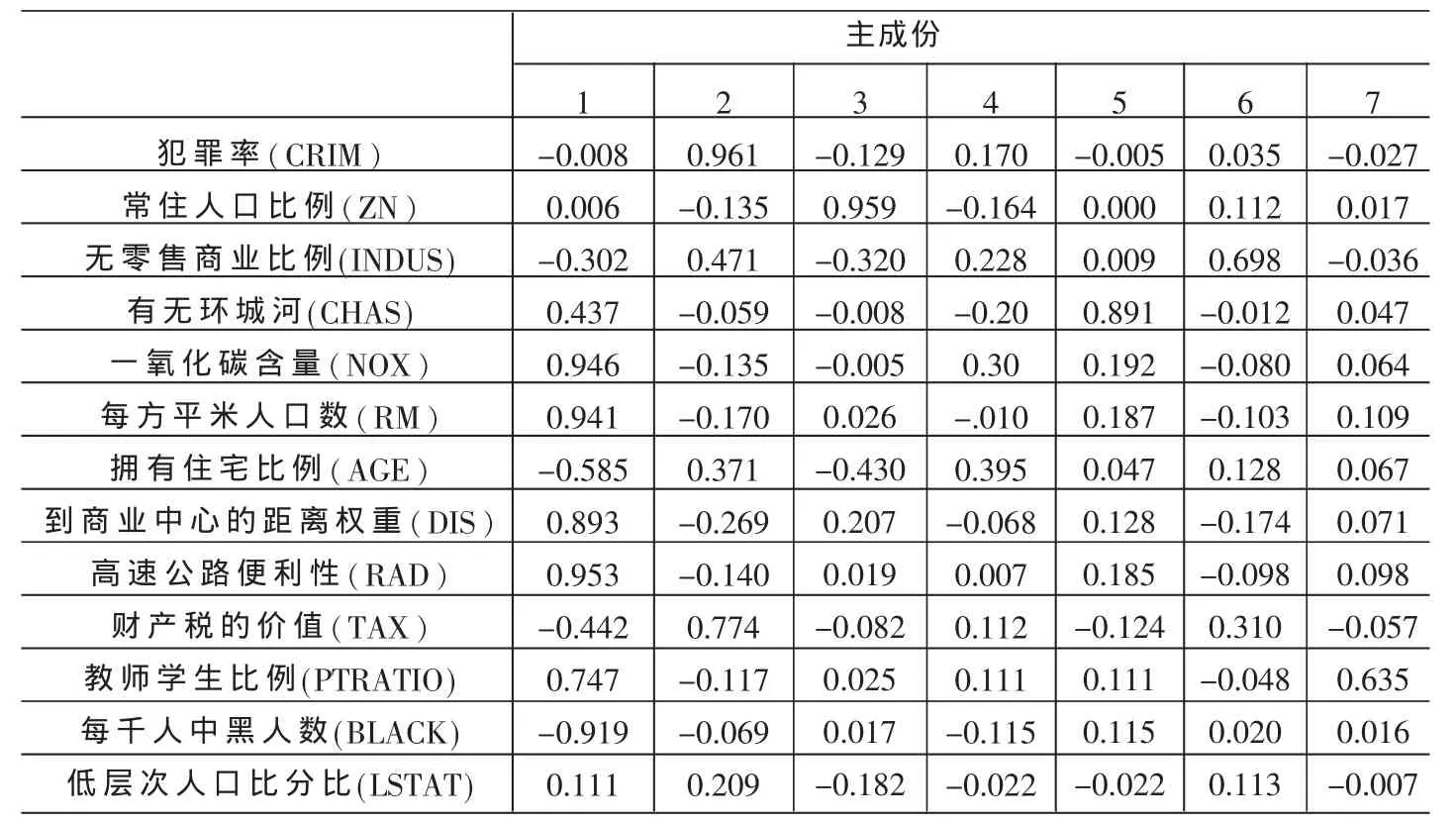
表1 主成份载荷旋转
(2)应用粒子群算法优化支持量机参数
支持量机回归待优化的参数有惩罚参数C和e带参数 e,采用高斯径向基函数 K(xi,xj)=exp(-γ‖xi,xj‖2)作为SVM模型的核函数。选取降维后试验数据前352个样本作为训练样本,后100个样本作为预测样本。设C ∈[1,500],ε∈[0.01,10],Vid_max=Xid_max,c1=2.8,c2=1.3,种群规模为30,最大迭代次数为30,采用3折交叉验证模式下的均方误差(MSRE)作为评估粒子的适应度函数。优化后得到最优C=375.754,ε=0.175,最优目标函数的适应度值MSRE=7.4801。
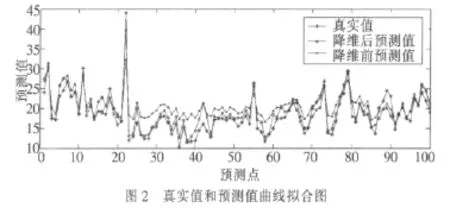
(3)应用e-SVM进行回归预测
本文把量子群优化算法和主成分析降维的方法应用于支持向量机的回归预测中,试验结果表明此法能显著提高支持向量机的预测精度,同时也表明了支持向量机在非线性、高维模式下的良好预测性能。
[1]阎平凡,张长水.人工神经网络与模拟进化计算[M].北京:清华大学出版社,2006.
[2]韦康南,姚立纲等.基于灰色理论的产品寿命预测研究[J].计算机集成制造系统,2005(10):1491-1495.
[3]VAPNIK V N.The nature of statistic learning theory[M].New York: Springer, 2005.
[4]VAPNIK V N.Estimation of dependencies based on empiric[M].Berlin Springer-Verlag,2003.
[5]邓乃扬,田英杰.数据挖掘中的新方法-支持向量机[M].北京:科学出版社,2004.
[6]KENNEDY J,EBERHART R.Particle swarm optimizat[A].Proc IEEE IntConf.on Neural[C].Perth,1995.1942-1948.
[7]CLERK, M.The swarm and the queen: Towards a deterministic and adaptive particle swarm optimization[A].1951-1957.1990.Proc.CEC 1999.
[8]林海明.对主成分分析法运用中的十个问题的解析[J].统计与决策(理论版),2007(8):16-18.
[9]http://archive.ics.uci.edu/ml/index.html 1993.07.
