基于朴素贝叶斯的农业土地适宜性评价算法设计
2010-11-22林国
林 国
(1.浙江工业大学 信息工程学院,浙江 杭州 310014;2.台州市农业局 信息中心,浙江 台州 318000)
0 引 言
农业土地适宜性是指农业土地在一定的条件下,对不同用途(农、林、牧等)生产的适宜性程度[1].农业土地适宜性评价就是利用相关的自然、经济、社会和技术数据,对特定土地利用方式是否适宜及适宜程度如何作出评价的过程.这里所指的土地利用方式在内涵上有广义和狭义之分:广义的土地利用方式指农业、林业、牧业、城建和军事等,狭义的则是指具体的用途,如用于农业中种植水稻、小麦、玉米等.
农业土地适宜性评价的算法模型就是根据样地相似的程度组成类别,然后将每一样地正确地归入某一类别.因此对一样地的土地评价,实质上是对某样地进行质量分类.具体步骤为:在己知大量类别标签样本集的基础上进行知识学习,再根据学习的结果对新的样本集做出评价和推理.
1 朴素贝叶斯算法原理
朴素贝叶斯 (Native Bayes)是基于一个简单的假设,在给定数据样本,它的各属性之间相互类条件独立.它是实用性很高的一种贝叶斯学习方法,在某些领域它的学习算法性能可以与神经网络和决策树的分类算法相媲美[2].
朴素贝叶斯分类算法的工作过程如下:[3]
1)每个数据样本用一个n维特征向量X={x1,x2,…,xn}表示,分别描述对n个属性A1,A2,…,An样本的n个度量.
2)假定有m个类C1,C2,…,Cm.给定一个未知的数据样本X,分类法将预测X属于具有最高后验概率.即是说,朴素贝叶斯分类器将未知的样本分配给类Ci,当且仅当
P(Ci|X)>P(Cj|X),1≤j≤m,j≠i
其P(Ci|X)最大的Ci称为最大后验概率.根据贝叶斯定理
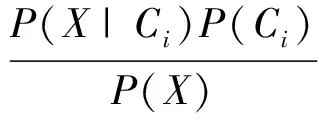
3)由于P(X)对于所有类为常数,只有P(X|Ci)P(Ci)最大即可.由于实际问题中,计算P(X|Ci)的开销可能非常大,为降低计算P(X|Ci)的开销,可以做类条件独立的朴素假设.给定样本的类标号,假定属性值相互独立,这样:
2 朴素贝叶斯算法实现
系统使用C#语言开发朴素贝叶斯核心类N_bys,该类设计了3个私有变量,其中私有字段_aryClassItem为C#ArrayList数组结构,用户存储分类对象._tokens和_prob两个变量分别为用户知识加载和学习的中间变量使用,为SortedDictionary二叉搜索树结构,其检索运算复杂度为O(logn),使用此类型可以大大提高知识学习的速度.
算法实现过程主要分为知识加载(LoadKnowledge)、知识学习(StudyKnowledge)和可能性计算(CalculateProbabilities)3个步骤,其中LoadKnowledge过程参数为一条SQL语句,用户从数据库中加载样本数据,SQL的第一个字段为假定的m个类C1,C2,…,Cm,SQL的第2,3…,n字段为n维特征向量X={x1,x2,…,xn},其中知识学习和可能性计算的代码如下:
public void StudyKnowledge()
{
_prob=new SortedDictionary
string strTag="";
foreach (string token in_tokens.Keys)
{
strTag=token.Substring(0,1);
if (strTag=="r")
_prob[token]=(double)_tokens[token]/(double)_tokens["s"];//得到P(Ci)
else if (strTag!="s")
_prob[token]=(double)_tokens[token]/(double)_tokens["r"+strTag];//得到P(Xk|Ci)
}
}
public string CalculateProbabilities(ArrayList aryCondition)
{
double douMult;
double douMaxProbabilities=0;
string strMaxProbabilityClass="";
foreach (string strClassItem in _aryClassItem)
{
douMult=1;
douMult=douMult * _prob["r" + strClassItem];//douMult=1*P(Ci)
foreach (string strCondition in aryCondition)
{
douMult=douMult * _prob[strClassItem + strCondition];//douMult=P(Ci)*P(Xk|Ci)
}
if (douMult > douMaxProbabilities)//取最大值
{
douMaxProbabilities = douMult;
strMaxProbabilityClass = "最佳评价结果为:" + SQLHelper.GetOneFieldBySql("select idx from ClassItem where idx<=" + strClassItem + ")").ToString() + ";最大概率为:" + douMaxProbabilities.ToString("0.00000");
}
}
return strMaxProbabilityClass;
}
3 评价模型设计
3.1 对条件数据进行标准化处理
对农田土壤养分、PH值、环境资源等相关检测数据,根据农业部门相技术规范,进行数据的分等定级,以1-6之间的数字从高到低表示各种土壤数据,如表1所示.

表1 土壤相关数据分级标准
3.2 空间插值
空间插值是根据一组已知的离散数据或分区数据,按照某种数学关系推求出其它未知点或未知区域数据的数学过程.农地适宜性评价中一般都涉及较多的土壤方面的影响因素,如土壤有机质、土壤速效磷、速效钾等,根据土壤采样点的属性值推求整个研究区域的土壤属性值,这就需要采用空间数据内插方法.在此采用克里格插值处理算法.
3.3 建立栅格数据集
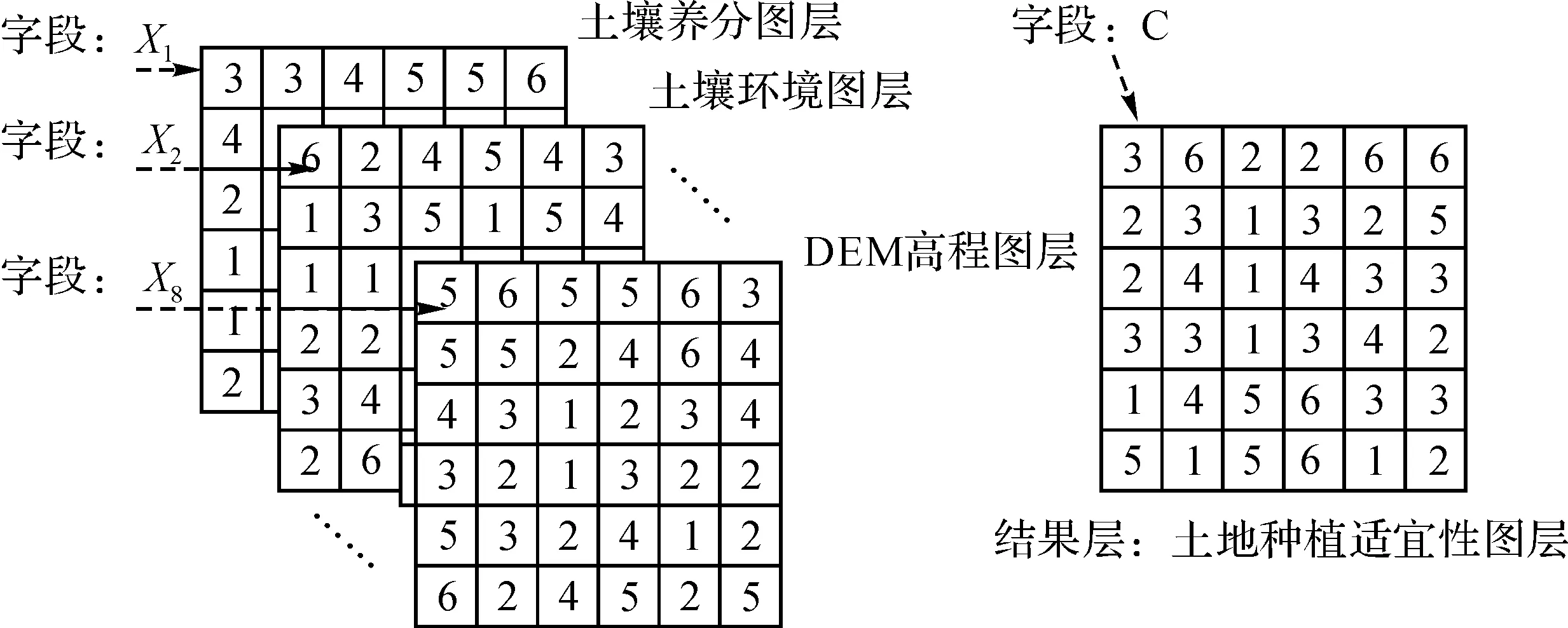
图1 栅格数据集Fig. 1 Raster data set
一个栅格数据集[4],就像一幅地图,它描述了某区域的位置和特征与其在空间上的相对位置.由于单个栅格数据集代表了单一专题,如土地利用、土壤、道路或高程等,因此必须创建多个栅格数据集来完整描述一个区域.如图1所示,系统条件图层有8个,分别由字段X1,X2……,X8表示,结果图层由字段C表示,X字段和C字段在空间上的位置是一一对应的.
3.4 建立推理知识库
根据栅格数据集,以X字段为推理条件,C字段为推理结果,按照数据集空间位置依次类推,运用朴素贝叶斯统计推理算法,对栅格数据集进行知识学习,生成系统推理需要的知识库,为空间数据挖掘做准备.
3.5 空间数据挖掘实现
建立基于ArcGIS Server空间属性查询功能[5],获取查询点上所有条件图层的属性数据存入X字段中,作为推理条件,调用贝叶斯统计推理类,进行推理,得出C值,实现空间数据挖掘功能.
4 评价算法效果验证
算法选取浙江省台州市黄岩西部山区现代农业综合开发区和仙居浙江省绿色农产品生产基地2个台州市重点农业园区为研究区域,进行农业土地适宜性算法评价.评价方法以DEM高程、行政村经济收入统计表、行政村农业人力资源统计表、农业企业信息表、农业生产合作社信息表、土壤大量元素养分表、土壤中量与微量元素养分表、土壤环境资源评价表、气象数据表、土地利用图等10个图层作为分类条件图层,分别对应X1,X2,…,X10,以农业产业基地分布图作为分类对象图层,对应C值,随机抽取300个点作为分类样点,再利用朴素贝叶斯统计推理算法对这300分类样点进行计算,得出300个检验样点,通过对分类样点和检验样点进行比较,得出以下验证结果,如表2所示.
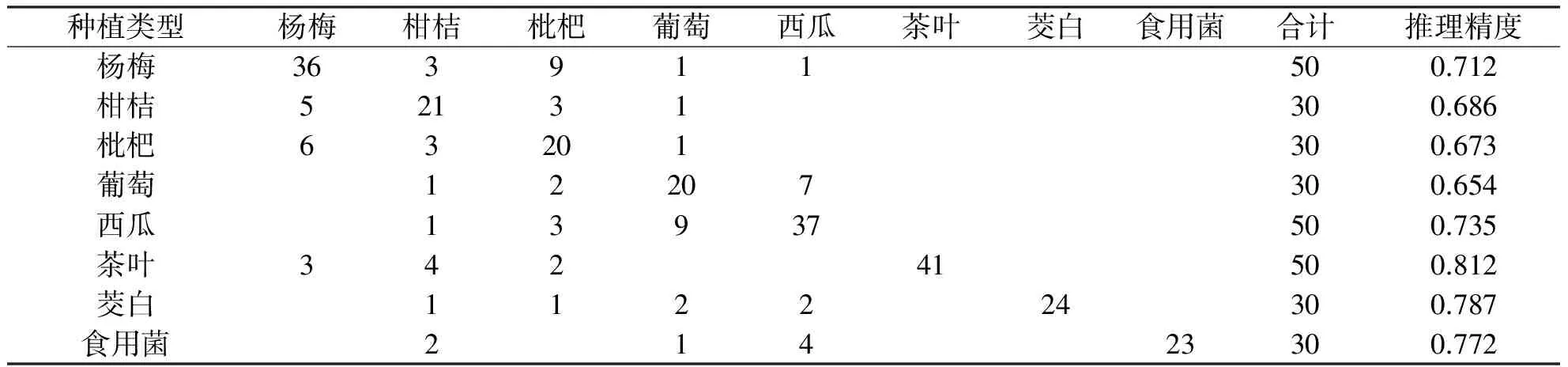
表2 土地适宜性评价算法精度验证
5 结 语
文章就农业土地利用中,如何针对农业的各类已有条件要素,建立知识库,利用朴素贝叶斯算法对新的土地进行统计推理,得出最佳适宜性种植项目.系统实现简单,算法速度快,推理精度较高,较好地解决了土地适宜性问题.
[1] 林培.土地资源学[M].2版.北京:中国农业大学出版社,1996:61.
[2] 李凡长,钱旭培,谢琳等.机器学习理论及应用[M].合肥:中国科学技术大学出版社,2009:121-126.
[3] 朱慧明,韩玉启.贝叶斯多元统计推断理论[M].北京:科学出版社,2006:69-73.
[4] 冯险峰,汪闽,孟雪莲,等.ArcGIS空间分析实用指南[M].北京:ArcInfo中国技术咨询与培训中心,2002:76.
[5] 李航飞,汤小华.福建省县域经济格局时空演变研究[J].杭州师范大学学报:自然科学版,2008(1):50-54.
