H.264帧内4×4块预测模式选择及其IP核设计
2010-09-29吴从中李本斋胡有刚
吴从中,李本斋,胡有刚
(合肥工业大学 计算机与信息学院,安徽 合肥230009)
新一代视频编码标准H.264以其高复杂度为代价获得了优异的编码效率,但运算复杂度的增加给实时编码带来了很大困难,因此H.264编码器的硬件化是必然趋势。随着FPGA技术的发展,用SoPC实现H.264视频信息的实时编码是一种极佳的选择。本文介绍的H.264帧内4×4块预测模式选择及其IP核是基于SoPC的H.264编码器的一个硬件加速器。
帧内预测是H.264/AVC的一个重要组成部分,它充分利用了帧内图像的空间相关性,提高了压缩效率,对编码器整体性能的提高具有重要作用。在帧内预测编码过程中,预测块P基于已编码重建块和当前块形成。对亮度像素而言,P块用于4×4子块或者16×16宏块的相关操作。其中,4×4亮度子块有9种可选预测模式,独立预测每一个4×4亮度子块,适用于带有大量细节的图像编码。16×16亮度块有4种预测模式,预测整个16×16亮度块,适用于平坦区域图像编码;色度块也有4种预测模式,类似16×16亮度块预测模式。编码器通常选择使P块和编码块之间差异最小的预测模式。实验表明,H.264的帧内预测约占编码总时间的29%,提高了帧内预测的速度,对实现实时编码具有重要的意义。
本文结合实际应用,通过对帧内预测模式选择原理的分析,根据图像空间方向的相关性,提出了一种适合于硬件实现的算法,并将其设计成IP核,作为PowerPC的一个硬件加速模块在Xilinx Virtex-II PRO开发板中进行了验证。
1 基于抽样的帧内预测模式选择方法及硬件结构
FS(全搜索)能达到很好的预测效果,而且易于硬件实现,但计算量过大。本文提出的基于抽样的模式选择算法,不仅易于硬件实现而且减少了计算量。
1.1 帧内预测的原理[1]
如图1(a)所示,4×4亮度块包括标示为 a~p的16个待预测像素,与之相邻的左上方标示为A~M为已编码并重构的像素,帧内预测就是利用A~M来预测a~p。根据预测方向的不同,共有9种可选预测模式,其中DC预测(模式 2)根据 A~M中已编码像素预测,即当 A、B、C、D、E、F、G、H、I、J、K、L 都可用时,用(A+B+C+D+I+J+K+L)>>3来表示其所有像素;若 A、B、C、D可用而 I、J、K、L不可用,用(A+B+C+D)>>2来表示,反之用(I+J+K+L)>>2表示,若都不可用,则预测值为128。其余8种模式的预测方向如图 1(b)中的箭头表示。模式 0是垂直预测,即a=e=i=m=A;模式1为水平预测,即 a=b=c=d=I;模式3~8的预测像素由A~M不同加权平均得到。

图1 4×4亮度预测
确定最佳预测模式的代价函数模型有RDO和SAD两种,其中RDO计算方法比较复杂且不易于硬件实现。本文使用SAD计算方法,其计算主要是加减平均等运算,适合于硬件实现。其计算公式为:

其中,4R是对使用某种预测模式后比特数的估计;λ(Qp)=0.85×2(Qp-12)/3,当 Qp 一定时为 常数;SAD(绝对差和)是16个像素预测值与图像像素值的差值。
1.2 基于抽样的帧内预测模式选择
在H.264帧内预测模式选择中,4×4块每种模式判别时需要计算16个像素点的预测值,还要计算16个像素点的SAD值,计算量较大。同时,如果一次输出16个预测值,则预测电路消耗的硬件资源很大,且在H.264的后续处理中需要大容量的存储器与之匹配。如果一次只输出一个像素,消耗的资源会减少,但对硬件的频率要求变高。在一个时钟周期预测一个像素情况下,如果要实现 SDTV(720×480×30 fps)的实时处理,频率就要达到 202 MHz(720×480×1.5×30×13)。 所以,如果对 4×4 块中16个像素进行抽样计算,不仅大大减少了计算量,而且对硬件的频率要求也会降低。由于4×4块与16×16块相比较小,块内纹理变化比较平缓,抽样的像素可以大致代表块内纹理方向。本文将4×4宏块抽样为4个部分[2],图 1(a)中 4 部分像素抽样为(1)a,c,i,k;(2)b,d,j,l;(3)e,g,m,o;(4)f,h,n,p。 在这 4 个部分中选取一个部分进行SAD失真计算,从而省略了大部分的运算代价。每一组抽样的代价表示为:

其中,SAD4是每个抽样组的4个像素点与图像像素值的绝对差值和,其他参数同式(1)。
通过以上抽样,可以减少3/4的运算量,要实现SDTV所需的硬件频率仅为 50.54 MHz(720×480×1.5×30×13/4)。为了验证抽样对图像质量的影响,将这种抽样的方法在JM中与FS进行了比较。
1.3 硬件结构设计
本文的抽样算法在FPGA中实现的系统结构框图如图2所示,包括每种模式的预测值计算和4点的SAD值计算模块。由于λ(Qp)的计算比较复杂,不易于硬件实现,这里先将计算结果存放在FPGA中,通过Qp查表的方法获得。

图2 帧内预测模式选择系统结构框图
H.264帧内4×4块预测模式共有9种,每一种都有对应的预测值计算公式。在硬件设计时要为每一种预测模式设计一个预测值计算模块。对于mode0(垂直预测)和mode1(水平预测),电路的输出直接等于输入;其他的模式计算比较相似,都是通过加法和移位来完成的[3],这里以mode3(上下对角预测)为例给出其硬件结构如图3所示。该结构通过对已知像素值进行累加和移位来得到相应的预测像素的值。系统中9种预测模式并行计算,使每个计算模块都处在工作状态[4],提高了运算效率。

图3 mode3抽样像素预测值计算硬件结构
在帧内预测模式选择中,SAD值的计算最复杂。本文对像素点的抽样只需要进行4点的SAD值计算即可,降低了计算复杂度和硬件资源的消耗。4点的SAD值计算式如式(3)所示,其硬件结构如图4所示。

图4 SAD值计算硬件结构

其中,a(m,n)表示预测值,b(m,n)为图像像素值。
2 基于PLB总线的IP核设计与测试
2.1 PLB总线简介
PLB总线(Processor Local Bus)是IBM开发的一种高性能片上总线,主要应用于PowerPC405处理器系统中,它支持32位、64位和128位数据宽度,本文对IP核的设计使用了64位总线宽度。虽然PLB接口总线协议非常复杂,但是Xilinx为用户专门设计了一套可以用工具生成的接口协议,称作plbv46_slave_single。它在用户IP核和PLB V4.6总线标准之间提供了一个双向的接口。plbv46_slave_single让用户可以便捷地在IBM PLB Bus和用户IP核之间进行交互。这个slave服务使得用户能在不同地址范围内提供地址译码,从而配置多个用户IP的接口到PLB Bus上。plbv46_slave_single可以优化以减少点到点连接设计的延时和FPGA资源消耗。
2.2 基于PLB总线的软核设计
H.264帧内预测模式选择软核的设计包括总线接口和帧内预测模式选择模块两部分。PLB总线接口使用Xilinx为用户设计的plbv46_slave_single。而帧内预测模式选择模块与硬件体系无关,方便移植。
H.264帧内4×4块预测模式的系统硬件结构如图5所示。输入寄存器由 4个 32 bit的寄存器0、1、2和 3组成,输入已编码并重构的像素 A~M,寄存器 3的高位用于输入Qp值;寄存器4为原始图像抽样出用于SAD计算的 4点像素值;寄存器 5、6、7、8为输出数据寄存器;寄存器9为控制寄存器,包括启动、完成、复位等。预测值计算模块就是根据A~M对抽样像素进行每种模式的预测值计算,SAD值计算模块计算每种模式预测值与图像像素值的差值,第三个模块根据每种预测模式的计算结果选择最优的预测模式输出。其中,Rλ(Qp)根据Qp值在FPGA中查表得到。

图5 帧内预测模式选择硬件结构
2.3 软核的仿真与测试
测试中首先使用IBM的CoreConnect工具和Modelsim6.0a来仿真设计软核,仿真使用虚拟平台来测试,仿真的目的是保证PLB总线接口能被处理器正确访问。通过虚拟处理器将虚拟内存中的数据写入待测软核,然后读取待测软核中的数据并判断是否正确。
仿真通过以后,再将软核集成到系统中,以便验证软核在实际系统中的工作是否符合要求。软核验证使用PC机和目标板相结合的方法,目标板使用Xilinx公司XUP Virtex-II PRO开发板,内部含有2个PowerPC内核。
验证时,首先使用EDK9.1将软核集成到PowerPC系统中,编译通过后由USB接口下载到目标板,系统开始运行后通过RS232从上位机下载待编码的图像数据,下载的数据保存在目标板上的256 MB DDR SDRAM中。数据下载完毕后程序将待编码数据依次写入软核并启动,将计算完的数据写入DDR SDRAM,待全部数据处理完毕,PowerPC将处理结果一起发送给上位机。上位机将结果与本机C代码执行结果相比较,最终确认软核是否正确工作。
3 综合性能分析
首先在JM中对基于抽样的帧内预测模式选择方法进行验证。通过对Foreman和Akiyo两个视频序列选择不同的Qp值与全搜索进行比较,结果如表1所示。可以看出,通过这样的抽样并没有带来PSNR(信噪比)的明显下降和编码比特数的增加。
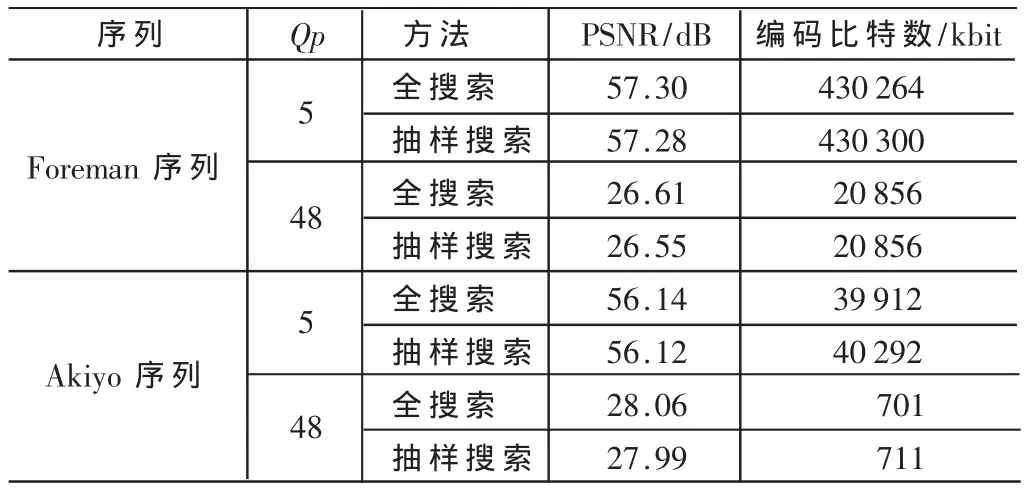
表1 本方法与全搜索比较
同时将该模块在Xilinx的XC2VP30 FPGA中进行综合,XC2VP30含有 13 696个 Slices和 136个 18×18乘法器,综合工具使用Xilinx的ISE9.1。综合的结果和资源消耗情况如表2所示。可以看出,本文中所设计的模块在关键路径和资源消耗上都优于参考文献[5]中所述的方法。
本文将H.264的帧内4×4块的预测模式选择方法进行优化。表1和表2所示的实验数据表明,在不损失图像质量的同时明显地降低了运算的复杂度。同时,与硬件相结合,设计出基于PLB总线的IP软核,并在Xilinx XUP Virtex-II PRO开发板中做了验证。

表2 软核综合结果
[1]毕厚杰.新一代视频压缩编码标准——H.264/AVC[M].北京:人民邮电出版社,2005.
[2]MENG Bo Jun,OSCAR C A.Fast intra-prediction mode selection for 4×4 blocks in H.264.IEEE International Conference on Acoustics Speech and Signal Processing,2003(3):389-392.
[3]黄凯,秦兴,严晓浪,等.一种 H.264帧内预测模式判决算法及 VLSI实现体系[J].电子学报,2007,35(2):207-211.
[4]HUANG Yu Wen,HSIEH Bing Yu,CHEN T G,et al.Analysis,fast algorithm,and VLSI architecture design for H.264/AVC intra frame coder.IEEE Transactions on Circuits and Systems for Video Technology,2005,15(3):378-401.
[5]朱总平,冯建华,曹喜信.H.264/AVC帧内预测器的VLSI实现[J].北京大学学报,2008(1):44-48.
