基于KIM的语义检索系统研究
2010-08-31白如江王效岳山东理工大学图书馆山东淄博255049
●白如江,王效岳(山东理工大学 图书馆,山东 淄博 255049)
●芮文浩 (安徽安庆师范学院 文学院,安徽 安庆 246133)
1 KIM是什么
KIM是OntoText实验室的研究项目。该项目的研究成果KIMPlatform(Knowledge andInformationManagementPlatform)提供了一个语义服务平台构架和在此构架上的应用,包括网页内容的半自动的语义标注、本体部署、基于内容的语义索引、检索和知识导航以及知识问答。
2 KIM的体系结构
KIM平台包括以下四个部分:KIMOntology、KIM WorldKB、KIMServer和Front-ends。如图1所示。
KIM的中部是API模块。语义标注模块API对与KIM本体和KB有关的文档进行标注,同时还提供内容和标注管理的基础设施。文档持久API模块通过存储文档和相关标注从数据集中加载。索引API基于Lucene信息检索引擎,通过修改索引策略允许对命名实体建立索引。查询API模块可以看成是语义检索API,允许传统的关键字搜索和其他基于本体的访问方法。同时它还能够建立复合型搜索,将实体搜索、关键字搜索和实体模式搜索集成在一起。语义存储API能够管理和访问知识库,通过RDFS和方法集访问已有的知识库。
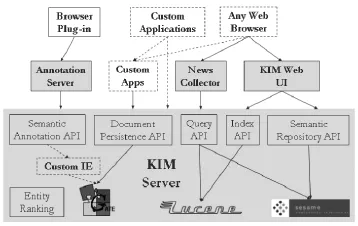
图1 KIM体系结构
3 KIM的技术实现
KIM在技术上借助了目前在本体及自然语言处理领域比较受推崇的三个开源项目:GATE[1]、Sesame[2]和 Lucene。[3]
3.1 GATE
GATE项目开始于1995年英国的谢菲尔德大学,其全称是General Architecture forText Engineering,文本工程通用框架。经历了近10年的不断发展,GATE已经被应用于广泛的研究和项目开发。GATE的主要开发者认为,GATE可以被看作是语言工程的软件架构。
GATE框架采用了基于组件的软件开发方式和面向对象的灵活编程。GATE框架是由纯Java语言开发的免费开源软件,遵循GNU library license。GATE使用的编码方式是Unicode,可以支持多种语言编码,并且针对各种斯拉夫语言、日尔曼语言、拉丁系语言和印度语做过系统测试。GATE支持的文档类型包括XML、RTF、Email、HTML、SGML以及纯文本文件。
GATE作为一个框架,规定其框架内所有的自然语言处理软件系统元素都可以有效地被细分成不同的几种组件,在GATE中它们被称为资源。在GATE框架下组件的集合被称为CREOLE(a Collection of Reusable Objects forLanguage Engineering)。CREOLE组件是通过Java Beans的形式来实现的,CREOLE在GATE中分为三种形式:语言组件(LR)、处理组件(PR)和可视化组件 (VR)。
GATE除了提供语言组件(LR)、可视化组件(VR)和处理组件(PR)之外,还提供了一些其他组件,比如GATE 提供了 JAPE(a Java Annotation Patterns Engine)作为建立规则库的语法工具组件,用于英文信息抽取 的组件 ANNIE(ANearly-NewInformationExtraction System)。其中,JAPE提供了基于正规表达式的标注有限状态转换,我们通过JAPE手工设立各种规则来实现分词、分句和命名实体识别等功能。优秀的规则设置可以大大提高信息抽取的准确性。
3.2 Sesame
Sesame是一个本体存储工具,可以用来存储和查询由RDF、RDFS语言构建的本体,是欧洲IST项目On-To-Knowledge的一部分。值得指出的是,Sesame的设计和实现与具体的存储设备无关,这意味着Sesame可以部署在各个不同的存储设备之上,如关系型数据库、面向对象数据库、文本文件等,但对外可提供一致的访问接口,从而屏蔽了底层存储设备的异构性。我们采用Sesame来存储protonontology,以及信息抽取出的ontology。
3.3 Lucene
Lucene是一个基于 Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为应用程序提供索引和搜索功能。Lucene目前是 Apache Jakarta家族中的一个开源项目。也是目前最为流行的基于 Java开源全文检索工具包。
4 KIM Ontology
在KIM中KIMOntology中定义了实体的类型、实体类型的关系和属性,而实体的具体描述则保存在KIMKnowledge Base中。所谓KIM Knowledge Base,就是所有实体的描述集合。可以把KIMOntology看作是KIM Knowledge Base的模式(Schema),两者都采用RDFS存储在语义数据库中,该语义数据库存储工具能够支持知识推理、检索,甚至版本控制、访问控制、事务处理等功能。
KIM KB已经建立了一些重要实体的知识库,目前包括8万个实体。例如KB包含了5万个位置实体,包含大陆、地区、282个国家、4700座城市以及山峰、河流、海洋甚至油田。为了使IE处理能够识别KB中不包含的新实体和关系,KB还提供了词汇资源的集合,该集合覆盖了组织机构的后缀、人名、时间、货币前缀,等等。为了保证KB对重要实体的覆盖率,KB要一直处理和分析全球主要新闻的内容,每周要更新4000份文档,包括从15个媒体收集的重要报道、经济、政治新闻。
5 基于KIM语义检索系统
基于KIM语义检索系统分为实体搜索、实体模式搜索、预先定义模式搜索、本体浏览、关键词搜索等几部分功能。下面就几个重要的功能分别进行介绍。
5.1 实体模式搜索
在实体模式搜索界面中读者可以根据自己的要求进行检索资源。举个例子,如果要查询“座落于中国的员工人数大于300的企业是哪些?并输出这些企业的信息”。在实体模式搜索界面下,我们首先选择X是一个organization,然后,确定X和Y的关系是X座落于Y,Y的值是“CHINA”;在属性约束栏目中,我们定义X的“numberOfemployee”属性大于“300”,最后点击Entites按钮就可以得到搜索结果了。如图2所示。
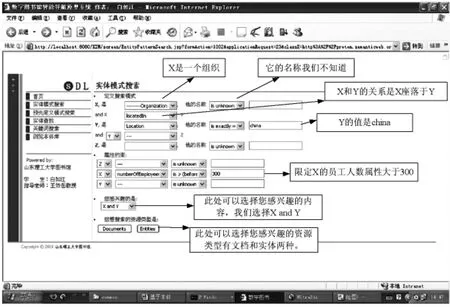
图2 实体模式搜索界面
在实体模式搜索结果界面,我们可以看到刚才定义的想要查找的内容,总共有3条记录符合要求,分别是 Yanzhou Coal Mining Company Limited、Qiao Xing Universal Telephone,Inc.、HaierGroupCompany。
如果想继续了解海尔公司的情况,我们点击“HaierGroup Company”,这样就可以看到与海尔公司相关的信息。如果点击“D”按钮,就可以获得与海尔公司有关的文档。此外我们还可以通过点击“V”按键得到有关海尔公司的可视化信息。这样就能帮助读者方便迅速地了解了海尔公司的主要情况,而这是传统信息检索系统所不能的。
5.2 预先定义搜索模式
在预先定义搜索模式中,可以选择预先定义好的搜索模式。比如,我们要查询海尔公司的CEO是谁,我们就可以选择“Person has Position Job Position within Organization Organization”模式,然后在person栏目中留空,在who has position一栏中填入CEO,在within Organization一栏中填入HaierGroup Company。然后点击entity按钮就可以找到海尔的CEO是张瑞敏。如果想要继续了解有关张瑞敏的信息可以继续点击“Zhang Ruimin”,如果想查看与“Zhang Ruimin”有关的文档点击“D”按钮;如果想查看与“ZhangRuimin”有关的可视化信息点击“V”按钮。我们还可以自己设定自己经常需要用到的一些查询模式存储到预先定义搜索模式中。
5.3 关键词搜索
基于KIM语义检索系统还提供了通过传统的关键词查找来搜索我们想要的资源。比如我们要查询有关于石油(oil)方面的文档,可以在content栏目中输入“oil”一词,然后点击Documents,就可以得到查询结果。除此之外,我们还可以按照标题、副标题、作者等选项查找资源。查询到某篇文章后,我们可以在系统中将其打开,然后通过系统对文章进行标引。这样,读者可以随时点击自己感兴趣的内容,做到了真正的智能检索。如一篇题为“Spy claim threat to SingTel's buyinAustralia”的文章,我们通过系统打开,然后对其进行标引。当我们看到“Australian National University”这个词条时,如果读者不熟悉Australian National University的有关信息,就可以点击它。这时系统会弹出与Australian National University有关的信息。同样,如果我们想浏览和“Australian National University”有关的文章时可以继续点击“D”按钮,想浏览与“Australian National University”有关的可视化信息可以点击“V”按钮。
6 结论
本文介绍了一个语义信息检索平台KIM。KIM通过对文档建立基于本体的语义模式,结合传统的IR技术,一定程度上能够提高检索的查全率。它开拓了信息检索的新领域,利用了文档丰富的语义信息和传统的信息检索技术,会是未来检索技术发展的一个热点领域。
KIM的解决方案为协同环境下基于搜索的文档定位提供了一个很有价值的研究方向。传统的信息检索技术目前已经非常成熟,但是查询效果不是令人很满意。传统的信息检索根本不会理解查询者的意图,不会理解文档中每句话中的语义信息。显而易见,KIM现在可以解决这个问题,但尚不完美。
KIM的信息抽取是基于英文的,我们未来的工作目标应该是使KIM实现中文的语义信息检索。
[1]Gate Research Group.General Architecture for Text Engineering[EB/OL].[2010-02-10].http://www.gate.ac.uk/,2009-09-01.
[2]Open RDF org.Sesame Project[EB/OL].[2010-02-19].http://www.openrdf.org/,2009-09-07.
[3]TheApacheSoftwareFoundation.LuceneProject[EB/OL].[2010-02-19].http://lucene.apache.org/,2009-09-07.
