基于引文排序的科技文献检索初探
2010-08-23刘松涛
刘松涛
LIU Song-tao
(吉林司法警官学院,长春 130507)
0 引言
科研人员在自己的研究领域就某些问题的研究总是要查阅和借鉴前人已有的研究成果以帮助自己在已有成果的基础上继续深入研究和创新,但随着科学发展的不断进步科技文献的数量日益庞大,如何从浩如烟海的文献资料中检索出自己关心的篇章是人们日益关心的话题。一篇完整的科学论文一般是由作者的正文部分和附于其后的被引文献构成,文献与文献之间建立起了一种引用和被引用的关系,一篇文献也往往兼有引用和被引用两种角色。我们从文献的引用和被引用关系上能够发现文献间的相关性。这种相关性有强有弱。相关强度大的对于研究人员的参考价值就大。因此按照相关强度对引文进行排序是合理的,有价值的。
本文将以一组科技文献的引文系统中的文献为研究对象探讨按照相关强度对引文进行排序的方法。我们会发现文献间的相关性与文献的被引用次数有着直接关系,我们可以以文献的被引用次数来反映文献间的相关强度并论述它的合理性。对学术期刊、文献的引用和被引用现象进行定量分析,以便揭示其数量特征和相互关系,弥补传统文献检索方法的不足,具有良好的理论价值和应用价值。
1 引文网络结构的表示
广义的引文分析,要了解引文系统中引用文献和被引文献之间的关系,也就是要了解和掌握该系统的结构,一组同一领域的有相互引用关系的论文构成的一个网络图,它们之间具有一定的结构,这个结构能表述它们的相互作用关系和相关强度,可以勾勒出相关课题的来龙去脉。引文网络图可以用链、树、网型三种结构表达。令引文和被引文献均为系统中的结点,如果我们用来表示文献间的引用关系,以箭头指向为被引文献,而箭尾为引文(即文献)。
图1的网状结构图反映了一个不同于链、树结构的复杂体:
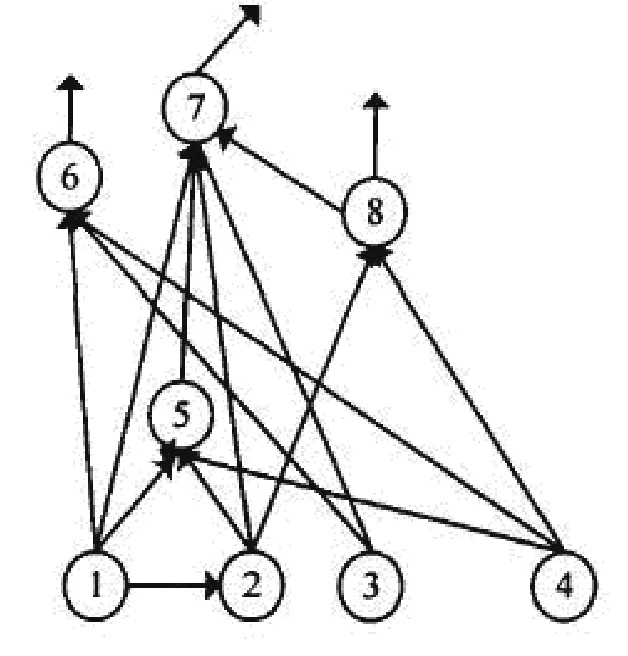
图1 引文系统的网状图
文献之间的引用关系十分的复杂,所以考虑采用网状结构表示。
2 文献间的相关强度和被引用频次的关系
根据图论中路径的相关定义,在此给出引文路径的语义定义:如果文献之间通过 n 次引文相联系,那么它们之间所经过的 n 次联系所形成的引文链,称为引文路径。文献之间的引文路径不是唯一的 。例图1中,文献[1]到文献[7]的引文 路径有多条,其中一条由1到7,另一条由1到2再到7。
引文路径长度是指文献之间形成的引文联系的次数,也就是引文路径概念中 n 的值。如果 n=0,文献 A 与文献 B 之间没有引文联系;如果 n>0,则文献A 与文献 B 之间形成了 n 次引用联系。 图1中,文献2 与文献 3 之间的引文路径长度为 0,文献 1 到文献7 之间的引文路径长度为 1或2。
引文路径宽度是指具有引文联系的两篇文献之间的引文路径长度相同的引文路径的数量。 图1中文献1 到文献7之间的引文路径长度为 2 的路径有2 条,其中一条为由1、2、7所组成的引文路径, 另一条为1、5、7所组成的引文路径。
根据引文分析路径模型的理论既通过引文路径相联系的文献之间的相关性与其之间的引文路径长度成反比。与其之间的引文路径总宽度成正比的理论。有如下公式:
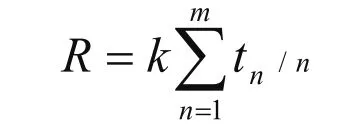
其中:R代表文献间的相关强度,n代表相关文献间引文路径的长度,tn代表当引文路径长度为n时两个引文间的引文路径宽度,K为常数。
我们以图1为例,计算文献1与其它文献间的相关强度,假设K为常数1:
1与2间:R1-2=1*1/1=1;
1与3间:0;
1与4间:0:
1与5间:R1-5=1*1/1=1;
1与6间:R1-6=1*1/1=1;
1与7间:R1-7=1*(1+2/2+1/3)=7/3;
1与8间:R1-8=1*(0+1/2)=1/2;
根据上述结果我们按与文献1的相关强度对文献排序如下:
7,5,6,2,8,3,4
从图中我们还可以看出按照各引文的被引频次排序如下:
7,5,6,8,2,3,4
再比如文献2与文献7的相关强度为2,与文献5的相关强度为1,与8的相关强度为1,其它为0。
文献3与文献7、6的相关强度都为1,其它为0。
文献4与文献7、5、6、8的相关强度都为1,其它为0。
从总体上来看我们能够发现引文网络图中的某一文献与其它文献的相关度与它的被引用次数有着直接关系,当文献的被引用频次较高时它与其它文献的相关强度也大,反之当文献的被引用频次较低时它与其它文献的相关强度也较小。但根据引文路径模型我们不但能够检索出与一篇文献发生直接引用关系的引文还能检索出间接引用关系的引文。因而利用引文路径模型我们能够得到与一篇文献相关的引文系统。
由于某一文献与其它文献的相关度与它的被引用次数有着直接关系,我们可以用引文系统中文献的被引频次来反映此文献与其它文献的相关度,从而在一个引文系统中按照文献的相关度把文献排序的问题可以转化为按文献的被引用频次的排序问题,使问题变得简化。
3 设计实现
首先,引文网络(citation network)作为一个系统,它能够反映各个要素相互之间存在的各种关系。引文关系特点就是(1)在时间上单向,(2)不能自引, (3)关系一旦形成不可更改三个限制。这都是在编程时应该注意的。检索论文后处理,先将论文格式转化成txt文件,抽出网址-URL,头部-Header,摘要-Abstract,介绍-Introduction,引文-Citations,正文-Full Text等信息,专门对Citations做解析工作,具体处理步骤不再赘述。
在得到检索、格式处理后的论文txt文件后,将数据分解成两个表导入SQL server数据库:表1 ( 论文序号,论文名,引文数量 )属性列,论文序号为此引文网络中论文的一个编号;表2 ( 引文序号,作者,引文名称,出处来源及所属论文 )属性列,所引论文表示的是此引文为表1中某一论文的引文。
利用Java 编程时,借助JDBC与数据库连接进行操作。方法1:将数据库表中数据读出到Java程序数组中进行字符串迭代匹配,得到论文引文排序; 方法2:Java程序中嵌入数据库 结构化查询语句(struct query language) 直接进行查询。方法1在对空间或是时间上都代价较高,特别是在一个引文网络中论文数量很大的情况下更加体现出效率低。与之相比较,方法2是在数据库内进行一系列操作,sqlserver的存储量大,查询速度快,方便数据的传输等优点便可以显现。
4 结束语
对引文按被引次数进行排序直接反映了文献间的相关强度,迭代法排序的查询速度不及数据库查询的方法。此结果是在引文系统只有10篇论文的请况下得到的,如果是大量论文的引文系统中可以判断数据库的优越性会更显著。此研究的目的是根据某一文献找到相关的引文系统并根据与所给文献的相关强度对引文进行排序从而提供使用者查阅。由于时间有限,本人的能力有限,考虑得不是很周到。这些有待日后进一步加工以使论文按引文排序方法更加完善。
[1]陈雪.引文分析路径模型[J].情报探索,2009 (6).
[2]严蔚敏.数据结构[M].清华大学出版社.2005.
[3]丁学东.文献计量学基础[M].北京大学出版社,298
[4]周云平.我国引文分析研究现状与21世纪发展趋势[J].图书情报工作,2001(2).
[5]Ma Jun.Retrieving Digital Artifacts from Digital Libraries Semantically.LNCS.3644,Springer,2005,340-349.
[6]T.-Y.Liu,T.Qin,J.Xu,W.Xiong,and H.Li.LETOR. Benchmark dataset for research on learning to rank for information retrieval. In SIGIR Workshop on Learning to Rank for IR(LR4IR),2007.
[7]陈雪 郑宏.基于路径的引文分析研究初探[J].情报探索,2007(4).
