连续语音识别网格技术在新闻制播平台的应用
2010-08-10张秋野王力劭
张秋野,王力劭,丁 鹏
(1.中国国际广播电台,北京 100040;2.中国科学院自动化所,北京 100080)
1 引言
众所周知,对于视音频类内容,经典的检索方法依赖于前期的内容编目过程,针对多媒体信息的元数据标引细度决定了多媒体文件日后可被资产化利用的程度。“媒体”能够成为“资产”不仅依赖内容的海量性,更重要的是在需要时能够被低成本、高精度地定位。
基于音素网络的连续语音识别技术颠覆了经典的新闻素材检索方法。如果仅考虑多媒体数据内涵而不关心其外延衍生信息,并不需要人工编目标引过程,而是通过对新闻类视音频伴音进行处理,采用音素网络技术提取发音信息并作为元数据,这种变革为多媒体新闻制播平台带来质变,并能够最大限度提升多媒体素材资产化能力。
2 非特定人连续语音识别技术
非特定人语音识别常用技术分为基于有限词表集合的词表识别技术和连续识别技术[1]。词表识别技术是指对识别结果在预先给定的有限词表中进行匹配,根据置信度来筛选结果并进行后续工作,例如语音拨号、信息查询以及设备声控等。连续识别技术则是将语音段落进行预处理,先将其形成“音素”集合,然后将待识别内容转化为“音素”短语,通过语言模型在音素集合中进行类似“全文检索”式的匹配查找。这种技术非常适合应用在语音素材检索领域。
连续语音识别技术一般有3种基本方法:有限集全文识别并匹配关键词方法[2]、关键词加垃圾网络识别法[3]和音素网络法[4-5]。只有音素网络能够连续有效地在相对开放的识别集合范围内提供良好的识别结果。因此,针对信息量大、内容灵活的新闻类素材进行检索的要求来说,该方法是最有效的连续语音识别方法。
3 连续语音识别网格技术
3.1 音素网络识别技术简介
此技术分为2个阶段,第1阶段通常称为索引阶段,系统利用音素(音节)特性产生音素网络;第2阶段为检索阶段,根据相似度在网络上搜寻关键词。这种技术的优点是更换词表方便,不需要二次识别,很适合新闻类音频信息内容的识别。
音素网络的构建就是记录语音识别过程中间结果的一种紧凑的表示方式,是1个有向无环的加权图,其中,音素网络的横坐标为时间轴,音素网络上每个节点表示1个在特定时间结尾的音素,到达该结点的边表示该词的持续时间区间,边上的权值为其对应的声学得分。音素网络的生成是通过语音识别过程得到的:每搜索到一个音素的尾部,系统就将这个词记录到音素网络结点中,并且记录相应的得分和状态信息。在音素网络上每条从起始结点到终止结点的路径,都是一个候选识别结果,利用音素网络系统就可以得到很多的识别结果候选,这些候选都是在搜索的竞争过程中保留下来的[5]。当用户输入检索词汇时,系统会自动将检索词汇转换为音素,并在索引过程中生成的音素网络上进行搜索,计算声学得分作为输出的置信度。
3.2 连续语音识别网格构建
综上所述,采用音素网络连续识别技术需要2个步骤:多媒体信息的识别索引过程和检索识别过程[6]。由于识别索引是个耗时操作,因此可以采用网格技术构建音素索引集群以构成连续语音识别网格系统(Continuous Speech Recognition Grid,CSRG),从而大规模提升系统效率。图1为应用在多媒体新闻直播平台上典型的CSRG结构拓扑图。

图1 CSRG结构拓扑图
3.3 CSRG效率分析
3.3.1 CSRG系统参数
前端的语音信号经采集系统通过AD转换形成数据,然后通过调度系统经CSRG产生音素数据集合。从排队论的观点来看,新闻素材随机到达,CSRG构成了一个M/M/n的排队模型,CSRG服务能力参数为

式中:λ为新闻素材采集强度,t为新闻素材在CSRG节点的平均服务时间。
通过上述CSRG系统参数,可以精确定义CSRG的服务能力,并且可以根据新闻素材的生成强度来确定CSRG的规模。因此,CSRG是可控的,如果素材到达强度过大,通过适度追加网格节点,无限排队过程是完全可避免的,而且并不需要重建集群,仅需追加少量设备投入。
3.3.2 CSRG相对于经典新闻音视频检索方法的优势
为了对特定短语从新闻视音频伴音素材库中进行充分检索,经典方法需要通过人工预听进行编目标引后产生元数据,方可进行全文检索。一般来说,识别检索环节的算法效率与目前主流全文检索技术是相同的,因此形成元数据所耗费的时间将产生不同检索技术间的成本差别。
设待处理的新闻有x小时,经典的人工方法中新闻阅读的平均语速为每小时μ个字,y个人类工作者,每个工作者记录每小时内容的时间为内容时间的λ倍,且每小时平均录入z个字,则最理想状态下采用经典方法,x小时的内容通过编目转化为文本元数据所需要的时间成本(先听1次进行速记后再进行录入的时间总和)t1为

同样x小时的新闻,CSRG由n个处理单元组成,每个单元处理能力为实际内容时长的m倍,则x小时内容通过CSRG转化为可识别音素集合的时间成本t2为

则时间成本比ρ为

根据上述公式给出算例如下:目前的计算机设备条件下最优的语素网络识别算法至少可以达到m=1/3[2]。假设工作者记录内容的速度均可达到140字/分钟(速记员水平),μ=280 字/分钟[7],则 λ=μ/140=2,z=140 字/分钟(速录员水平)。假设CSRG由4个节点组成,即n=4,为了达到ρ=1,即水平相当,带入式(9)得y=48。说明为了达到同样的检索目的,4节点的CSRG理论上需要48个人连续工作方可满足,如果每个工作者每天只能工作8小时,三班轮换则需要144人可达到4节点CSRG的服务水平。
上述结果是人类工作者在理想的极限条件下计算得到的,实际工作中不可能长时间集中精力进行如此高强度的工作,而且工作过程中的错误会高于CSRG,所以CSRG的表现将远优于上述计算数据。由此可知,CSRG相对于经典多媒体新闻检索方法具有极大的优势。
4 CSRG在中国国际广播电台(CRI)多媒体新闻制播平台的应用
由上述分析可知,CSRG在多媒体新闻制播平台的应用能够为其新闻素材带来更高的资产化水平。因此,CRI在2008年奥运会前搭建的多媒体全业务新闻处理平台(以下简称“平台”)上,引进并充分融入了CSRG技术。
平台涉及音频、视频、文稿等多种媒体形式的新闻内容涵盖采集、制作、存储到播出的整体流程,业务流程之间具有复杂的关系。平台设计采用云计算模型,内部通过信息门户(SOA)结构模型借助系统(ESB)/媒体(EMB)双总线及插件式系统实现异构系统的在线扩充能力,并且通过企业信息门户将所有复杂系统关系屏蔽在云体内,使用户可以快速按需获取功能,轻易享受云计算中软件即服务(SaaS)特性所带来的便捷性[8-9]。同时,在整体系统平台上根据安全极差进行了多层次网络受限连接[10],从而提供了灵活而安全的良好动态系统扩充架构。
在平台中,平行于视音频采集系统构建了CSRG系统,该系统按照SOA架构规范以插件系统方式接入平台,成为紧密连接平台的服务模块。CSRG的连接方法采用带外方式异步地对所有的新闻视音频伴音进行索引,并将音素网络数据存入主存储空间,如图2所示。
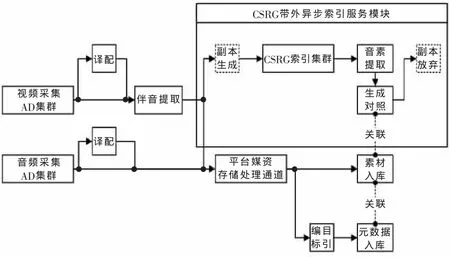
图2 CSRG在CRI平台的应用方式
伴以关键字检索和全文检索系统能够带来的外延式元数据提供,CSRG与其共同组成了企业信息门户中强大的综合检索门户,可以让用户采用多种手段快速定位到任意需要的多媒体内容。通过整体设计结构良好的云计算SaaS特性,用户使用过程非常简单,但是能够获得强大的资源素材再获取能力。同时,CSRG的存在使平台完全杜绝了多媒体新闻制播平台中任何无效“死数据”的产生,使多媒体新闻的利用率和资产化达到了极高水平。检索门户界面如图3所示,采用谷歌式(Google Like)的设计方式,便于用户使用。
在支撑2008年奥运会宣传报道及正式使用一年半的过程中,系统表现稳定,能力出色,每日数据吞吐量达数十吉字节,平均用户访问量日近百次,对于关键字和全文无法获取的数据以及未做编目标引的多媒体新闻素材,CSRG表现了异常出色的检索效果,并发峰值在50线程情况下,响应时间在3 s以内,识别正确率在96%以上,成为多媒体新闻制播平台的辅助利器。

图3 含语音识别检索的谷歌式综合检索门户界面
5 小结
非特定人连续语音识别技术是一种非常具有应用价值的模式识别技术[11-12],基于音素网络和网格技术构建的连续语音识别网格(CSRG)具有极其出色的新闻视音频伴音搜索特性。经过精确分析和充分试验后,CRI在其多媒体全业务新闻制播平台中创新性地引入并可控地应用了CSRG,提高了平台的检索应用能力及素材资产化率,获得了良好的应用效果。
[1]崔金芳,张雪英,白静.基于OMAP5912的嵌入式非特定人连续语音识别系统[J]. 电声技术,2009,33(9):70-72.
[2]WEINTRAUB M.LVCSR log-likelihood ratio scoring for keyword spotting[C]//Proc.ICASSP 1995.[S.l.]:IEEE Press, 1995:297-300.
[3]LIANG Jiaen, MENG Meng, WANG Xiaorui, et al.An improved mandrin keyword spotting system using mce training and contextenhanced verification[C]//Proc.ICASSP 2006.Toulouse,France:IEEE Press, 2006:1-7.
[4]CHELBA C,ACERO A.Position specific posterior lattices for indexing speech[C]//Proc.ACL′05.Ann Arbor, Michigan:[s.n.], 2005:443-450.
[5]MEMBER K T,SFIDHA S.Rapid and accurate spoken term detection[C]//Proc.ICASSP 2007.[S.l.]:IEEE Press, 2007:346-357.
[6]RABINER L R, JUANG B H.Fundamentals of speech recognition[M].北京:清华大学出版社,1999.
[7]孙红梅.电视新闻播音语速之我见[J].声屏世界,2004(12):31-32.
[8]周毅,王力劭.云计算与多媒体综合业务制播平台[J].宽带互联网世界,2009(6):14-20.
[9]王力劭,周毅.云模型与多媒体全业务平台的结构安全特性[J].电视技术,2009,33(10):10-12.
[10]广播电台数字化网络工作组.广播电台数字化网络建设白皮书(2009)[EB/OL].[2008-01-31].http://blog.fjtv.net/UpAttachment/2008-6/200861885613.doc.
[11]丁昊,姚天任.基于mel标度频谱和音素分割的汉语语音单词端点检测方法[J].计算机与数字工程,2005(3):57-59.
[12]江铭虎,袁保宗.一种适应域的汉语N-Gram语言模型平滑算法[J].清华大学学报:自然科学版,1999,39(9):99-102.
