自中心网络生成的高效分布式设计与实现*
2010-08-09沈奇威
金 欣,王 晶,沈奇威
(北京邮电大学网络与交换技术国家重点实验室 北京100876;东信北邮信息技术有限公司 北京100191)
1 概述
随着社会的发展和技术的进步,人与人之间的联系越来越紧密,手机正是一种为了满足人们互相沟通需求而出现的工具。根据工业和信息化部2010年2月公布的数据,中国的手机用户已经达到了7.74亿[1],而在这个庞大的数字之后,慢慢浮现出来的是更加丰富的用户需求,用户不仅仅满足于打电话、发短信,各种数据业务正在飞速走进我们的生活,如手机阅读、多媒体业务、移动广告等。
随着数据业务的不断丰富和电信运营商之间的竞争愈发激烈,提供更好的服务,提高用户体验成为降低用户流失、保证市场份额的关键。然而,如何提供更好的服务呢?通过对用户数据的分析了解用户喜好,并向用户提供个性化的信息服务是最主要的方式之一。通过数据挖掘的方式,电信运营商可以了解用户的个人喜好、消费倾向等,利用这些信息,在提高服务质量的同时努力实现精准的广告投放增加收益。如何高效地对数以亿计的手机用户的个人数据、业务数据、通话数据等进行处理,成为运营商面临的新挑战。
社会网络分析是数据挖掘的一个分支,它通过分析人与人之间的关联寻找有价值的信息。自中心网络是指以个人为中心的社会网络,通过分析个人与周围环境的交互来挖掘个人特征。手机本身就是人们之间沟通的工具,运用社会网络分析方法对手机用户的通话网络、短信网络等进行分析是利用数据挖掘寻找用户特征的重要手段。
本文将逐步设计基于hadoop分布式计算平台的自中心网络生成算法实现,该算法针对mapreduce的分布式计算模型,从数据分布、IO等方面对算法进行改进,最终给出一种适合mapreduce的高效、自中心网络生成算法。
2 社会网络分析和自中心网络
传统的机器学习和数据挖掘任务处理的对象是单独的数据实例,这些数据实例往往可以用一个包含多个属性值的向量来表示,同时假设这些数据实例之间是统计上独立的。而社会网络分析以人为个体,通过分析人与人之间的关联寻找网络和个人特征。社会网络分析分为两个部分:一是对网络整体进行分析,例如对分群、网络演变等的研究;二是自中心网络,就是以个人为中心通过分析其与周围环境的交互来分析其特征。由于自中心网络的分析可以挖掘出个人的特征,相比整体网络分析更加适合个人喜好、消费倾向、骚扰电话分析等信息的挖掘。
相比facebook等构建的社会网络,手机用户构建的网络更加生活化和真实,因此对社会网络分析具有更大的价值。随着手机用户的不断增多和移动业务的不断丰富,人与人之间的交互越来越复杂,用户交互数据无论从维度上还是数量上都对移动运营商的数据分析工作提出了挑战。近年来分布式计算技术的高速发展为这种海量数据分析的应用提出了新的解决方案,并且随着分布式计算技术的愈发成熟,其在移动领域的应用也越来越多[2]。通过将用户数据分布在各个节点上进行分布计算可以显著提高运算速度,特别是对于自中心网络,由于是以每个用户为中心来分析数据的,因此更加适合通过分布式方式进行计算。由于社会网络分析是通过数据之间的关联进行的,所以用户与用户之间的数据传递会使得系统的IO消耗十分严重,这是研究分布式社会网络分析算法必须要解决的问题。
3 基于mapreduce的传统自中心网络生成算法
mapreduce是一种计算模型,每个mapreduce分为一个map过程和一个reduce过程,map和reduce的输入、输出数据采用键值对的方式进行描述,map会对每一个键值对进行处理,处理结果用键值对的形式进行输出,输出结果相同键值的会汇总到一起,由reduce进行处理。详细的mapreduce编程模型介绍可以参照参考文献[3]。
算法的存储模型采用以点为基础存储整个社会网络图。每个点被分配一个ID,用一个对象表示。这个对象除了存储点的ID之外,还有与该点所有相连的边。对象表示的点本身为中心点,边用除了中心点之外的另外一个点来表示,这样就可以构成一个完整的社会网络图。
一个点的自中心网络由两部分组成:一是所有与自己相连的点,二是这些点之间的边。任何一个自中心网络算法都要首先找出每个点所在的自中心网络。在现有的存储模型中,对于一个点对象来说,已经存储了自己中心网络中的点以及和自己相连的边,因此,自中心网络生成工作的核心就是找到这个点的邻居之间的边。传统的自中心网络生成算法就是遍历自己所有邻居的邻居来找到自己邻居之间相连的边,下面给出传统自中心网络算法的分布式实现。
整个算法由一次mapreduce过程就可以完成。在map中对所有点依次进行处理,每个点的处理过程如下。
·遍历该点的所有邻居,以邻居的ID为键,以点对象本身为值输出记录。
·以自身点ID为键,对象本身为值输出数据。
经过map过程,reduce接收到的每个键值对应的是中心点和它的所有邻居,邻居对象包含了这个邻居的边信息。通过将邻居对象和中心点对象的边进行比较可以找到该邻居与中心点其他邻居之间是否有边存在。最终,我们可以找到所有相连的邻居,从而形成该点的自中心网络,如图1所示。
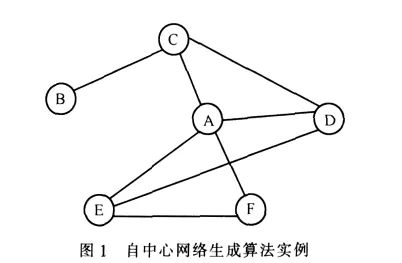
A至F是其中的6个点,设A至F代表的是点对象,而a至f是点的ID,则在map中,A会输出5条键值对分别为a→A、c→A、d→A、e→A、f→A;在reduce中,a对应的数组包含的是(A,C,D,E,F),通过对这些对象的边信息的遍历,可以找到
由于在reduce中相同键值下的数据排序不能确定,所以不能知道哪一个是中心点,所以不得不将所有数组中的数据先存储在内存中,然后通过将每个对象的ID和键值进行比较,相等的就是中心点。这种方式在一个点有很多邻居的情况下会导致内存消耗非常严重。这个问题可以用mapreduce中常用的技巧secondary sort[4]来解决,这里不再详述。
4 基于寻找三角形的分布式自中心网络生成算法设计与实现
§3描述的算法是自中心网络生成算法基于mapreduce的一个直接而简单的实现,该算法有3个明显的不足。
·mapreudce程序的主要瓶颈在IO,而社会网络分析算法的IO消耗也是非常严重的。在这个算法中传输了许多不必要的信息,比如点C以a为键输出的数据是为了生成以A为中心的自中心网络,由于传输的是对象,所有该点的邻居信息,包括B都在对象中,但实际上是不需要的,由于其不了解A的情况,所以不能判断哪些边是冗余的。在一个庞大的网络中,这种不必要的数据将是非常巨大的,大大影响了系统的IO负载,降低了算法的性能。
·分布式算法的效率和数据的分布有很大关系。根据参考文献[5]分析,在一个真实的网络中,往往有很少的一些点,这些点的度数非常大,在一个庞大的社会网络图中点的度数呈指数分布。§3描述的算法由于以中心点为计算的核心,必然会因为一些度数很大的点使得某些点的计算量非常大,从而影响整个程序的执行效率。
·一个点如果有很多的邻居,为了找到所有相连的边,对每一个邻居的边都要进行一次完整的遍历,在遍历过程中有很多是不必要的。
可以看出,这些缺陷都是由于算法实现采用基于中心点遍历邻居的方式导致的。这种方式由于图中点的差异必然导致数据分布的不均衡,而由于在每个点的处理过程中的重复且复杂的计算,使得单点负载严重影响性能。
因此,需要换一种思路才能解决上述问题。一个点的邻居如果相连,那么这两个相连的邻居和中心点就可以构成一个三角形。如果找到与一个点相关的所有三角形,就相当于找到了所有属于该点自中心网络的边。通过参考文献[6]的介绍可以看出,找三角形这种操作实际上是将一个大的图打散成为许多很小的部分,非常适合分布式计算。
基于以上分析提出了一种新的生成自中心网络的算法。该算法首先要找出图中的所有三角形,之后只要计算每个点存在于哪些三角形中,就可以判断该点有哪些邻居之间是相连的。
改进后的算法需要两个mapreduce过程,第一个mapreduce过程是找出所有三角形,第二个过程是通过三角形得到自中心网络。
在第一个mapreduce过程中,在map中输出一个点邻居的所有邻居对,以中心点和两个邻居用分隔符相连作为键,值为空。reduce中每个键对应的相当于是一个3个点组合。如果一个三角形存在,则这个组合会收到3条记录。通过简单的计数就可以判断这3个点在图中是否可以组成三角形,如果可以,则将该记录分别以3个点为键值输出3条记录。例如图1,A点需要输出6条记录,每条记录是一个字符串,而采用原算法需要输出4条记录,每条记录都是保存该点所有边信息的点对象。由于新思路没有以点为中心来计算,所有的数据会更加均匀地分布在各个节点上,保证了负载的均衡,解决了单点负载问题。实际上,这个过程可以优化,如果3个点构不成三角形,那么肯定只能接收到一条记录,这样利用ID排序可以为每个三角形只输出两条记录,相当于节省了三分之一的IO。通过这个mapreduce过程,可以得到
在第二个mapreduce过程中,将原图和第一个mapreduce运算的结果同时作为输入进行一次计算,在reduce中一个点可以接收到许多三角形,每个三角形对应一条边,将这些边汇总起来可以形成该点的自中心网络。这个过程也有单点的问题,但是由于运算过程仅仅是简单存储,所以负载问题并不严重。
5 算法比较
为了比较两种算法的性能,对算法进行了测试。测试数据是某论坛数据,通过回帖信息建立起一个社会网络。用户数量为78 790,为了使得输入会分布在不同的机器上,我们将其按大小均匀分为6个文件,相应地使用3台性能相同的机器搭建了一个hadoop集群,每台机器可以同时执行两个map任务和两个reduce任务。
使用原算法总共运行时间为1 min 57 s,而使用找三角形方式两步过程运行时间总共为44 s。效率提升的原因主要有3个:一是map到reduce的IO,原算法为794 MB,新算法两步总共为296 MB,IO消耗降低很明显;二是原算法不同reduce之间运行时间最短为1 min 18 s,最长为1 min 42 s,运行时间最长的机器使得整个算法运行时间延长了24s,而新算法中不同reduce运行时间相差不超过2s;三是由于算法的不同,每个reduce运行时间都少了很多。
虽然这个数据量不是很大,但是可以明显看出新的实现方式对算法性能的影响。如果数据量进一步增大,那么由于IO和负载平衡的原因,新算法的优势将会更加明显。新算法的优势在于利用了社会网络的整体稀疏和度数指数分布的特点改进了算法的IO和负载平衡,从而提高了算法性能。如果图的密度很大,且所有点度数都很大,新算法的优势就不存在了,而且由于多了一个mapreduce过程,整个算法的性能可能还低于原算法,但是根据参考文献[5]中的验证和分析,几乎所有的真实网络都是属于前一种的。
6 结束语
本文针对真实的社会网络特征和mapreduce分布式计算模型,提出了一种基于三角形查找的分布式自中心网络生成算法,用于解决海量数据自中心网络生成问题。该算法在处理真实社会网络过程中,很好地利用了真实网络的分布特征,通过对IO和负载均衡的优化大幅提高了算法性能。如果整个网络是高密度且度数均匀分布的话,算法性能会低于直接的网络生成算法。对于手机用户构建的真实的社会网络的分析问题,该算法的优势还是比较明显的。
1 http://www.enicn.com/article/2010-02-04/0204610402010.shtml
2杨戈,廖建新,朱晓民等.流媒体分发系统关键技术综述.电子学报,2009(1):137~141
3 Jeffrey D,Sanjay G.Mapreduce:simplied data processing on large clusters.In:Proceedings of the 6th Symposium on Operating Systems Design and Implementation(OSDI04),San Francisco,California,USA,December 2004
4 Venner J.Pro hadoop.USA:Berkely,2009
5 Albert R,Barabasi A L.Statistical mechanics of complex networks.Rev Mod Phys,2002(74):10~97
6 Graph twiddling in a mapreduce world.Computing in Science and Engineering,2009,11(4):29~41
