基于改进CURE聚类算法的无监督异常检测方法
2010-08-04周亚建徐晨李继国
周亚建,徐晨,李继国
(1.北京邮电大学 网络与交换技术国家重点实验室 信息安全中心,北京 100876;2.北京邮电大学 网络与信息攻防技术教育部重点实验室,北京 100876;3.北京邮电大学 灾备技术国家工程实验室,北京 100876;4.河海大学 计算机与信息学院,江苏 南京 210098)
1 引言
近年来,随着计算机技术的不断发展,网络规模的不断扩大,入侵行为已经越来越严重地威胁到了计算机系统和网络的安全。入侵就是未经授权蓄意尝试访问信息、篡改信息,使系统不可靠或不能使用[1]。由于入侵方式越来越多样化,手段越来越先进,传统的静态安全技术如:防火墙、数据加密技术等,已经无法满足系统和网络的安全性需求。
入侵检测技术作为一种重要的动态安全技术,很好地弥补了静态安全技术的不足。入侵检测技术主要分为2类:误用入侵检测和异常入侵检测。误用入侵检测是指利用已知系统和应用软件的弱点攻击模式来检测入侵[2]。由于该技术主要是依赖于已知的系统缺陷和入侵,所以可以准确的检测到已知的入侵,但无法检测到系统未知的攻击行为。异常入侵检测是指能够根据异常行为和使用计算机资源情况检测出来的入侵。异常入侵检测试图用定量方式描述可接受的行为特征,以区分非正常的、潜在的入侵行为[2]。该方法可以检测未知的入侵行为,但是由于描述的可接受行为特征可能与实际情况偏差较大导致检测的准确性不高。
在异常入侵检测中,一般都要根据正常行为数据集建立一个正常行为模型来描述可接受的行为特征。但是实际上,要获取纯净的正常行为数据集是很困难的,并且代价是高昂的。为了解决这个问题,人们提出了无监督异常检测的方法。该方法不依赖于已标记的数据,所以不需要人工或其他方法对训练集进行分类,大大提高了入侵检测系统的实用性。无监督异常检测主要基于以下2个假设:第1个假设为正常行为数据量要远远超过入侵行为数据量;第2个假设为正常行为数据与非正常行为数据之间的差异很大[3]。第1个假设为识别正常簇与非正常簇提供了依据,基于第2个假设可以认为通过聚类能将正常行为数据与非正常行为数据很好分类。
近年来,无监督异常检测已成为入侵检测领域中的热点,该领域的研究工作者试着将数据挖掘和机器学习中的方法应用于无监督异常检测,目前已经取得了一定的进展。Jiang、Song等人[4]提出了一种新的无监督聚类检测方法CBUID,该方法在标记簇时考虑了簇的偏离程度(deviation degree),并且在聚类时使用了INN(improved nearest neighbor)算法,该算法有效地提高了聚类的质量。Eskin等人提出了一个无监督异常检测的几何框架[5]。该框架将未标记的数据映射到特征空间,如果数据点在特征空间的稀疏区域中,则判断该点为异常点。Oldmeadow等人在文献[5]的基础上,通过特征加权(feature weighting)和时变聚类(time-varying)的方法进一步提高了检测率[6]。Leung和Leckie提出了一种基于密度和网格的聚类算法fpMAFIA[7]。该算法基于pMAFIA算法并通过FP树对其进行优化。他们将 fpMAFIA算法用于无监督异常检测中,实验表明取得了良好的效果。但是该算法在最坏情况下的时间复杂度较高,而且随着数据维度的增长,算法的性能会迅速降低。
有些研究工作者试图将多种数据挖掘算法同时用于入侵检测中,来进一步提高系统性能。Zanero和Savaresi提出了一种新的2层入侵检测系统[8]。第1层使用了聚类算法来对数据包进行分类,并对数据包内容进行压缩,第2层则是通过传统的异常检测方法对第1层产生的数据进行检测。通过对实验结果的分析表明通过第1层机制的处理,系统的检测效果得到了显著的提高。Luo等人将无监督聚类方法与支持向量机方法相结合,提出了一种UCSUM-ID算法[9]。该方法的基本思想是将网络数据包和聚类算法生成的簇中心进行比较来确定是否需要进一步采用SVM分类,从而只将一部分对于聚类算法比较难于分类的数据包送往 SVM 分类。这样既提高了检测速度,又提高了检测率。高能等人[10]将Apriori关联算法和K-means聚类算法分别用于提取网络数据的流量特征和建立检测模型,使其能够实时、自动、有效地检测DoS攻击。肖立中等人[11]将模糊支持向量机(FSVM)与模糊C均值算法(FCM)相结合,解决了模糊C均值算法在聚类前需要确定聚类数的问题。
但是,这些无监督异常检测方法所使用的聚类算法有的因为不能对任意形状的簇聚类,导致建立的正常行为模型不理想,从而影响了检测效果。基于密度的聚类算法、神经网络的算法虽然可以对任意形状的簇聚类,但是在处理含有大规模数据量的训练集时要耗费大量时间,使得正常行为模型得不到及时的更新,导致网络或主机状况发生改变时不能很好的检测入侵行为。
为了解决这些问题,本文提出了基于改进的CURE聚类算法的入侵检测方法。CURE算法[12]是一种基于多代表点的算法,除了支持复杂形状和不同大小的簇的聚类外,从文献[13]可以看出该算法在效率、对异常数据的敏感性及对数据输入敏感性方面要优于其他一些算法,如:BIRCH、DBSCAN、CLARANS等。另外,CURE算法还可以通过随机取样和对样本点分组的办法来提高运行效率。本文对CURE聚类算法进行了合理的改进,然后用于样本数据的聚类。
本文还提出了一种新的基于超矩形的建模算法,使用该算法建立正常行为模型。该模型根据正常簇中的数据定义了待检测数据在各个维度上的正常值域,只要待检测数据在某一维度上不在正常值域中,则判断为入侵行为数据。实验表明该入侵检测方法能够有效的检测包括未知的入侵行为在内的各种入侵行为。
本文第2节提出了一种基于改进的CURE聚类算法的入侵检测方法;第3节通过对实验结果详细的分析和对比,论证了本文所述方法的有效性;第4节是结束语。
2 基于聚类算法的入侵检测
本文先是将改进的CURE聚类算法对训练集进行聚类,然后对簇进行标类,最后使用基于超矩形的建模算法建立正常行为模型。将待检测数据与该模型进行比较,如果符合该模型则判定为正常行为数据,否则为异常行为数据。
2.1 改进的CURE聚类算法
CURE算法是一种自底向上的层次聚类算法。其基本思想是每个簇用一定数量的代表点来代表一个簇,然后不停地合并相邻最近的2个簇,直到簇集中簇的数目等于某个特定的阈值。因为簇的个数一般无法事先确定,所以这有可能强制对2个簇进行合并,或者把簇强行分割开,从而降低聚类结果的质量。本文将聚类结束条件修改为:如果当最近的簇之间的距离超过某个特定的阈值时聚类过程就会停止。这样最后簇的数目就由簇之间的相似度来决定。下面给出了改进的CURE算法的详细描述。
设数据集合D由n个x维数据点di组成,D={d1,d2,…,dn},S为簇C1,C2,…,Cm的集 合。Q(Ci)为簇Ci的代表点集合,即Q(Ci)={r1,r2,…,rpi}(pi≤λ,λ为最大簇代表点数)。收缩因子为α,0≤α≤1,合并簇之间的最大距离为w。
定 义 dist(para1, para2)表示对象para1和para2之间的距离,其距离度量可以是欧几里得距离、曼哈顿距离以及闵可夫斯基距离等,本文在实验中选择欧几里得距离。当para1和para2都是簇时,定义dist(para1,para2)为2个簇中相隔最近的2个代表点之间的距离,即dist(para1,para2)
step1 根据每一个向量di创建一个簇Ci。即
step3 找出簇集S中代表点距离最近的 2个簇Cu、Cv, 即dist(Cu,Cv)=min{d ist(Ci,Cj),Ci∈ S,Cj∈ S,i≠ j} 。如果 dist(Cu,Cv)>w,执行终止。
step4 合并簇Cu、Cv。 Cnew←Cu∪Cv,tmpSet←φ。计算Cnew的质心:
step5 从Cnew中选择di。如果tmpSet=φ,则使di满 足 条 件 :dist(di,hnew)=max{d ist(dj,hnew),dj∈Cnew}。否则使di满足条件:dist(di,t mpSet)=max{d ist(dj,t mpSet),dj∈Cnew},其中 dist(dj,t mpSet)=min{d ist(dj,dk),dk∈ tmpSet }。 最 后 将di并 入tmpSet,即:tmpSet ← tmpSet ∪{di}。
step7 收缩代表点:Q(Cnew)←{dk+α *(hnew-dk),dk∈ tmpSet}。 更 新 簇 集 :S←S-Cu-Cv+Cnew。执行step2。
在实验过程中,一般用 KD树来存放数据点,用小顶堆来存放簇,并将簇按照与其最近邻簇之间的距离升序排序,这样在最坏情况下该算法的时间复杂性为:O(n2lbn)。
2.2 标类算法
在聚类之后需要对簇进行标记。该算法首先按照簇的大小降序排列。根据第一条假设,正常行为数据量要远远大于非正常行为数据,所以标记前θ个簇为正常簇。由于θ没有合适的计算方法,所以假设训练集中含有的正常行为数据比率为l,然后该算法在最坏情况下的时间复杂度为不断递增θ,直到其详细描述如下。
step1 如果S=φ,则执行终止。
step2 将集合S中的簇按照其大小降序排列,θ← 1。则执行step5。
step4 θ←θ+ 1,执行step3。
step5 标记C1,…,Cθ为正常簇。
step3 如果
2.3 基于超矩形的建模算法
本文提出了一种基于超矩形的建模算法。在对数据进行检测之前,该算法首先根据正常簇{C1,…,Cθ}建 立 一 个 超 矩 形 的 检 测 模 型M={R1,R2,…,Rθ},Ri为根据簇Ci创建的超矩形。超矩形的创建是根据正常簇Ci中的数据确定Ri在每一个维度σj上的上界U(Ri,σj)和下界 L(Ri,σj)。该建模算法在最坏情况下的时间复杂度为O(xn)。其详细描述如下。
step1 初始化i←1。
step2 k←1,如果i>θ,执行终止。
step3 初 始 化Ri:U(Ri,σj)←I(dk,σj),L(Ri,σj)←I(dk,σj)(dk∈Ci, j=1,2,…,x)。I(dk,σj)表示为dk在维度σj上的值。
step4 如果k≥ Ci,则i←i+1,执行step2。否则 k←k+1。
step5 如果 U(Ri, σj) < I(dk,σj)(j=1,2,…,x),则 U(Ri, σj)← I(dk,σj);如果 L(Ri, σj) > I(dk,σj)(j=1,2,…,x ),则 L(Ri, σj)← I(dk,σj)。然后执行step4。
基于超矩形的算法通过正常簇中的数据来计算正常行为数据在每一个维度上的正常值域。如果待检测数据被包含在任意一个超矩形中时,就可以判断为正常行为数据。反之,判断为异常行为数据。
检测算法在最坏情况下的时间复杂度为O(x θ)。假设d为待检测数据,详细描述如下。
step1 初始化i←1。
step2 对于任意维 σj(j∈{1,2,…,x}),如果U(Ri, σj)< I(d,σj)或 者 L(Ri, σj)> I(d ,σj), 则i←i+ 1。否则判断d为正常行为数据,执行终止 。
step3 如果i>θ,判断d为异常行为数据,执行终止。否则执行step2。
3 实验
3.1 训练集描述
选用的实验数据是目前入侵检测领域广泛使用的实验数据:KDD CUP99数据。该数据集主要分为训练数据集和测试数据集。训练数据集总共约有4 900 000条记录,其中包含的入侵行为种类共有22种。从中抽取了63 033条数据作为实验用的样本数据集,并且使该数据集满足第一条假设,并且使其依然包含22种入侵行为数据。测试数据集约有 3 000 000条记录,其中包含的入侵种类共有37种,而且其中有 17种入侵类型是训练数据集中没有的。从测试数据集中抽取13 491条记录作为测试数据集,同样保证所含的入侵行为种数不变。
在KDD CUP99数据中,入侵行为种类可划分为4类:DoS、R2L、U2R、PROBE。把如apache2、processtable、sendmail、xsnoop、sqlattack等测试集中含有而训练集中没有的数据类型统一标识为UNKNOW类型。实验数据详细信息见表1。
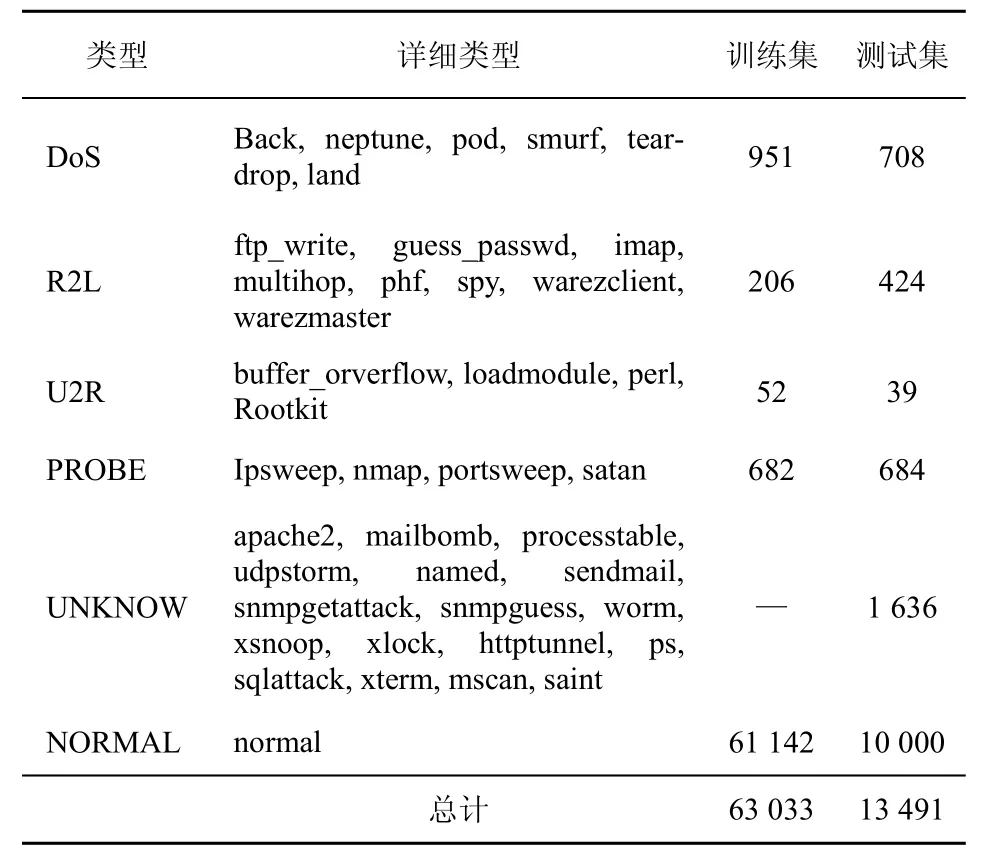
表1 实验数据集信息
3.2 预处理
预处理主要是对数据进行规范化。规范化可以提高涉及距离度量的挖掘算法的准确率和有效性[14]。在KDD CUP99数据集中,每条记录属性的数据类型主要分为二元变量(如 root_shell,is_host_login,is_guest_login)、序数变量(如 protocol_type,service_type,flag)和区间标度变量(如duration,src_bytes,dst_bytes)。
对于二元变量e,如果 e=0,e′← 0;如果e=1,e′ ← c,c > 0。e′为规范化之后的数据变量,c为某个常量,在实验中c=2。
对于序数变量 f ∈{a1,a2,…,an},则转换成n个变量来处理,具体过程如下:用变量 f1′,f2′ ,…,fn′ 对应 于 数 值 a1,a2,…,an, 如 果 f=ai, 则fi′ ← c, fj′ ←0(j∈{1,2,…,i-1,i+1,…,n})。
对于区间标度变量g主要采用如下方法对其变换。1) 计算变量g的均值绝对偏差 avedev(g):其中,z1,…,zn是 g的n个 度 量 值 ,计算标准度量值或z-score:之所以选择均值绝对偏差,是因为它比标准差对于离群点均有更好的顽健性[14]。
3.3 实验结果分析
本文方法采用的评价指标为国际上通用的检测率(detection rate)和误报率(false positive rate)指标。检测率定义为正确检测入侵样本的数量与测试集中入侵样本的数量之间的比率,而误报率则定义为错误判为入侵的正常样本数量与测试集中正常样本的数量之间的比率。
在实验过程中,要用到5个参数:分组数q,最大代表点数λ,收缩因子α,最大合并簇距w,标记阈值l。它们的实验取值范围如表2所示。

表2 参数取值
从实验结果可以看出,本文提出基于改进的CURE的无监督异常检测方法可以有效的检测出各种类型的入侵方式。表3描述的是q=8,α=0.2,λ=80,l=0.97时,系统得出的部分实验数据,从中可以看出在误警率约为 4%的情况下,检测率基本保持在80%以上。并且针对DOS和PROBE入侵有着较高的检测率,检测率一般在90%以上。而且对于未知入侵行为的检测率能够达到70%以上,说明该方法能够有效地检测未知的入侵行为。
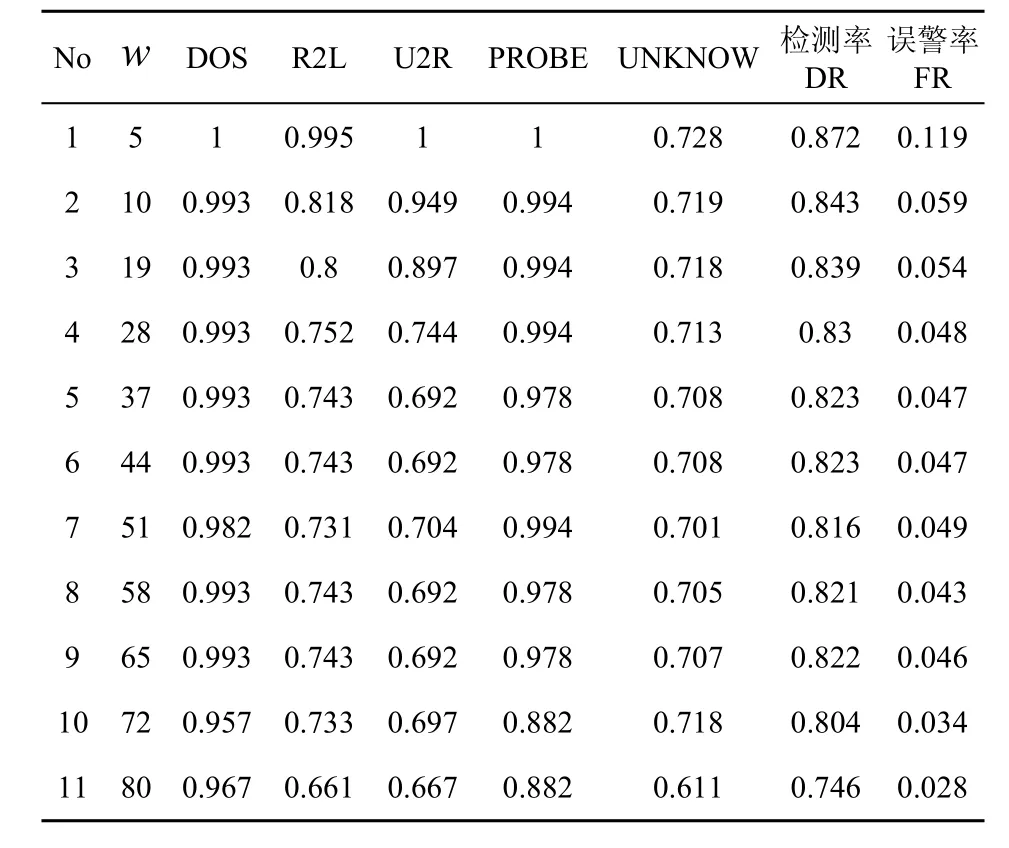
表3 部分实验结果
图1是一个ROC曲线图,它主要描述了q=8,α=0.2,λ=80,l=0.97,w为 5~600之间的若干个值时,检测率和误警率之间的联系。从总体上可以看出,检测率越高,误警率也越高;反之,检测率越低,则误警率也越低。这是因为当提高检测率时,试验中所建立的正常行为模型就要适度缩小,从而可能导致更多的正常行为数据不符合该检测模型,所以在一般情况下误警率会随着检测率的提高而提高。认为比较理想的结果应该处于误警率在0.03~0.05之间,此时检测率大约在0.8~0.85之间。
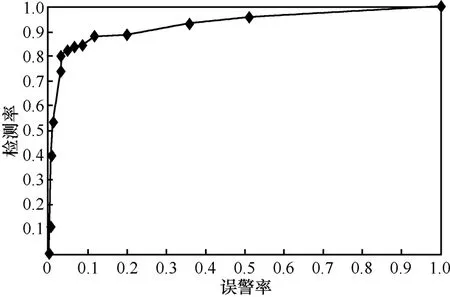
图1 检测率和误警率的ROC曲线图
根据图1得出的结论,将误警率在0.03~0.05之间时获得的实验结果与其他 5种入侵检测方法的部分实验结果对比情况(见表4),并且保证在任意一行中,每列数据对应的参数取值范围都是一致的。这6种方法所用的样本数据和测试数据均来自KDD CPU 99数据集,虽然在总体数据量和入侵数据类型比重上有些差异,但是仍然具有一定的比较意义。
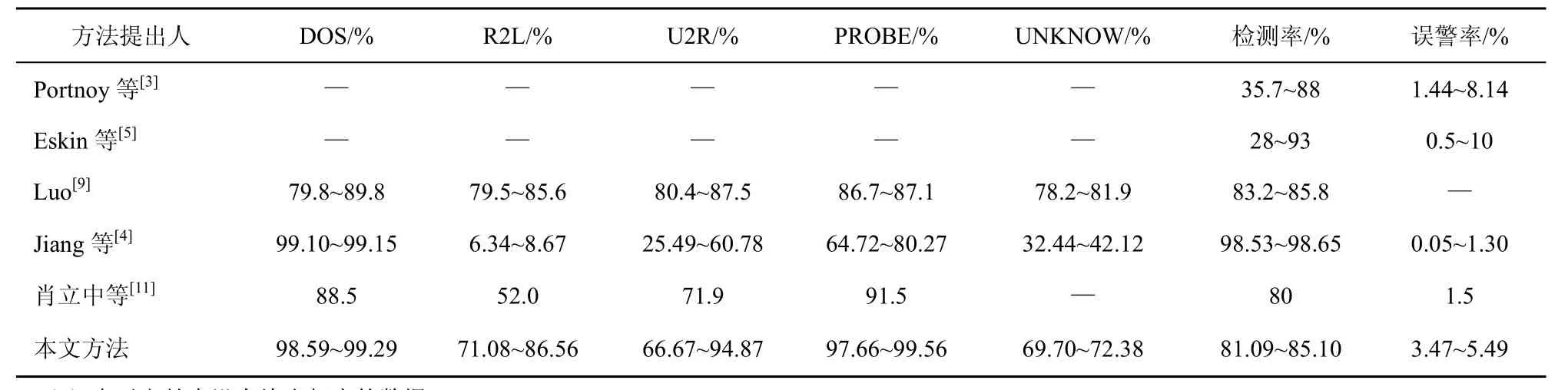
表4 与其他方法的结果比较
从中可以看出,本文的方法对于各种类型的入侵行为有着良好的检测效果,特别是对于 PROBE入侵行为的检测有着明显的优势,对于其他类型的检测也没有处于劣势。尽管误警率稍稍偏高,但作为一种异常检测技术仍然属于可接受范围,不会对系统的整体性能造成严重影响。
4 结束语
本文对CURE算法进行了适当的改进使其便于对样本数据进行正确的聚类,并且提出了基于超矩形的建模方法。实验结果表明基于改进的CURE聚类算法的入侵检测能够有效的检测入侵行为。该方法具有不需要对样本数据进行分类,并且能够比较好的检测出未知入侵行为的优点。同时,在聚类过程中还可以通过随机取样和分组聚类的方法能够加快对训练集的处理,并且在检测入侵时能够迅速做出判断。
但是由于该检测算法在如何设置参数上并没有合适的方法,只能根据经验来设置。并且,在将原始数据进行标准化之后,导致数据维度过高,影响了聚类的效果。所以下一步的工作就是考虑通过演化计算的方法自动找到合适的参数,以及通过特征变换和特征选择技术来克服维度过高所造成的不良影响。
[1] ANDERSON J P.Computer Security Threat Monitoring and Surveillance[R].James P Anderson Co,Fort Washington,Pennsylvania,1980.
[2] 将建春,马恒太,任党恩等.网络安全入侵检测: 研究综述[J].软件学报,2000,11(11): 1460-1466.JIANG J C,MA H T,REN D E,et al.A survey of intrusion detection research on network security[J].Journal of Software,2000,11(11):1460-1466.
[3] PORTNOY L,ESKIN E,STOLFO S J.Intrusion detection with unlabeled data using clustering [A].Proceedings of ACM CSS Workshop on Data Mining Applied to Security(DMSA2001) [C].Philadelphia,2001.5-8.
[4] JIANG S Y,SONG X,WANG H,et al.A clustering-based method for unsupervised intrusion detections[J].Pattern Recognition Letters,2006,27(7):802-810.
[5] ESKIN E,ARNOLD A,PRERAU M,et al.A geometric framework for unsupervised anomaly detection: detecting intrusions in unlabeled data[A].Applications of Data Mining in Computer Security[C].Boston,2002.78-99.
[6] OLDMEADOW J,RAVINUTALA S,LECKIE C.Adaptive clustering for network intrusion detection[A].Advances in Knowledge Discovery and Data Mining[C].Heidelberg,2004.255-259.
[7] LEUNG K,LECKIE C.Unsupervised anomaly detection in network intrusion detection using clusters[A].Proceedings of the Twenty-Eighth Australasian Computer Science Conference[C].Sydney,2005.333-342.
[8] ZANERO S,SAVARESI S M.Unsupervised learning techniques for an intrusion detection system [A].Proceedings of the 2004 ACM Symposium on Applied Computing[C].New York,2004.412-419.
[9] LUO M,WANG L,ZHANG H,et al.A research on intrusion detection based on unsupervised clustering and support vector machine[A].Information and Communications Security[C].Heidelberg,2003.325-336.
[10] 高能,冯登国,向继.一种基于数据挖掘的拒绝服务攻击检测技术[J].计算机学报,2006,29(6): 944-951.GAO N,FENG D G,XIANG J.A data-mining based DoS detection technique[J].Chinese Journal of Computers,2006,29(6):944-951.
[11] 肖立中,邵志清,马汉华等.网络入侵检测中的自动决定聚类数算法[J].软件学报,2008,19(8):2140-2148.XIAO L Z,SHAO Z Q,MA H H,et al.An algorithm for automatic clustering number determination in networks intrusion detection[J].Journal of Software,2008,19(8):2140-2148.
[12] GUHA S,RASTOGI R,SHIM S.CURE: an efficient clustering algorithm for large databases[A].Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data[C].New York,1998.73-84.
[13] 张红云,刘向东,段晓东等.数据挖掘中聚类算法比较研究[J].计算机应用与软件.2002,(2): 5-6,77.ZHANG H Y,LIU X D,DUAN X D,et al.The comparison of clustering methods in data mining[J].Computer Applications and Software,2002,(2): 5-6,77.
[14] HAN J,KAMBER M.数据挖掘: 概念与技术[M].北京: 机械工业出版社,2004.HAN J, KAMBER M.Data Mining: Concepts and Techniques[M].Beijing: China Machine Press,2004.
