一种基于文档相似度的检索结果重排序方法
2010-07-18岑荣伟刘奕群金奕江马少平
周 博,岑荣伟,刘奕群,张 敏,金奕江,马少平
(智能技术与系统国家重点实验室,清华大学计算机科学与技术系,北京100084)
1 引言
怎样根据用户的反馈信息提高检索系统的检索性能,这个问题在研究界已经有很多的相关工作。主流的工作可以被分为两个方向:1)查询扩展;2)检索结果重排序。查询扩展的思路是利用用户反馈信息中的相关文档,扩充用户原始的查询,从而使新的查询能够更好的描述用户的意图,再利用新的查询进行信息检索。文档重排序则不需要进行二次检索,只需要根据用户的反馈信息将原始的检索结果重新排序,排序算法会保证用户所需的文档被排在前列。
反馈这个问题有很多方面,其中首先需要明确的一条是反馈信息的来源。如果反馈信息直接来自于用户标注的结果,则我们称建立在这种反馈信息之上的技术为相关反馈技术;如果反馈信息来源于搜索引擎前几位的检索结果,则建立在这种反馈信息之上的技术成为伪相关反馈技术(因为反馈信息并不是由用户有意提供的)。近几年来,有关伪相关反馈的研究越来越多,主要原因是在大规模信息检索中很难由用户直接提供反馈信息。
在TREC 2008上,相关反馈被作为一个独立的任务集中研究如何根据反馈信息提高检索性能,不同研究队伍对相同的查询主题,根据相同的反馈信息,通过不同的方法进行检索性能的改进。
本文的方法是在已经确定了反馈信息的情况下,根据反馈信息对初次检索的结果进行重信排序。该方法主要基于反馈信息中的文档与初次检索结果中文档之间的相似度距离,在利用反馈信息时,同时考虑反馈信息中的不相关文档与相关文档两方面的因素。
2 相关工作
已经有很多研究表明相关反馈是提升信息检索性能的有效方法[1]。虽然有关相关反馈的研究可以追述到几十年以前,但是研究界最近几年仍然有不少有关相关反馈的工作[2-4]。主流的相关反馈方法可以分为两种:第一,基于查询扩展的方法;第二,基于搜索结果重排序的方法。本文关注的是第二种方法。
虽然在研究界相关反馈已经可以在很大程度上提高检索系统的性能,但是在实际的应用中,相关反馈却有很大的局限性,在网络搜索中这种局限性更加明显。其中一部分原因是由于技术上的不足,例如无法准确地确定用户一个查询需求所对应的完整的查询点击序列,另一部分原因是因为用户已经习惯了手动改变查询。
还有一些相关的方法是在将检索系统返回的前几位搜索结果作为用户的反馈信息来进行查询扩展,即伪相关反馈。而一些研究者认为:伪相关反馈的方法在大的文档集合上的性能很不稳定[5]。基于伪相关反馈的方法还有一个主要问题是将前多少位的返回文档作为反馈信息[6-11]。但是事实证明这是很难确定的,如果窗口较小,则很少的相关文档会落入窗口,如果窗口过大,则很多不相关文档会进入窗口,从而影响性能的提升。
研究界也有提出许多基于检索结果重排序的方法,文献[8]提出了一种基于文档所在的文档重排序方法。文献[8]中的方法是基于一个在整个文档集合上的层次聚类结构,根据聚类结构对文档进行重排序。文献[9]提出了根据文档的标题信息进行重排序的方法。文献[6]则是查询中的词对结果进行重排序。文献[12-13]利用全局与局部信息对局部的上下文进行分析,利用分析后的结果对文档进行重排序。文献[14]利用手动构建的同义词库对文档进行重排序,其中利用同义词库中原始查询的同义词扩展原始查询。文献[7]则是通过赋值可控制词典库对搜索结果进行重排序。文献[10-11]中则提出了同时利用查询中与前几位检索结果中的 term进行重排序的方法。
3 基于文档相似度的搜索结果重排序
基于假设:相关文档与标注为相关文档的相似度应该大于相关文档与标注为不相关文档的相似度,我们认为标注文档与其他文档间的相似度信息对于描述查询与文档间的相似度是有帮助的。在基于文档相似度的相关反馈方法中,根据标注文档与其他文档的相关性,初始的搜索结果被重排序。所以这里涉及两个基本的问题:第一,如何描述文档之间的相关性;第二,如何根据文档间的相关性对检索结果进行重排序。
首先,我们来解决文档相关性的问题。在本文中我们使用向量空间模型[2]来表示一篇文档。在向量空间模型中,每篇文档被表示为一个向量,向量的每一维是由这篇文档中的term的特征构成的。在这个模型的简单表示形式中,每篇文档可以被表示成为词频(Term Frequency,TF)向量:

其中t fi为文档的第i个term在所在文档中的词频。对于该模型的比较常用的改进方法是:对与每一个 term进行加权,所加权值是倒序文档频度(Inverse Document Frequency,IDF)。这样改进的目的是:如果一个term在很多文档中均出现过,那么该term在文档中的重要性就没有那些仅在几个文档出现过的term高。所以这样的term在表示一篇文档的时候需要加以相应的惩罚因子。一般的做法是将t fi与log(N/d fi)相乘,其中N代表文档集合中的所有文档数目,d fi代表包含第i个term的文档数目。这样我们就得到了一篇文档t f-id f的表示:

有了一篇文档的向量表示,我们就可以利用各种距离来计算文档之间的相关性。在多年的研究中有两种距离经常被用来计算两篇文档之间的相似度。第一种是余弦距离:
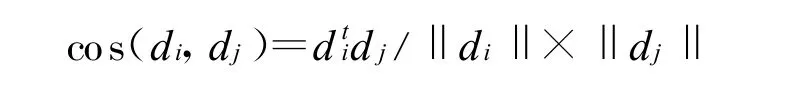
由于文档的长度为1,公式可以简化为cos(di,dj)=dj。当两篇文档相同的时候,该距离取值为1,当两篇文档完全不同的时候,该距离的取值为0。
另一种是欧氏距离:
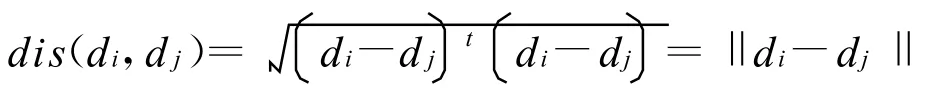
当两篇文档完全相同的时候,该距离的取值为0;当两篇文档的完全不相同的时候,该距离的取值为。我们在本文中采用了余弦距离来衡量文档之间的相关性。
在搜索结果重排序中我们需要考虑的因素有:搜索结果原始的评分值、搜索结果与标注为相关文档的相关性、搜索结果与标注为不相关文档的相关性、这几个特征如何整合。搜索结果的原始评分值反映了用户查询与各个搜索结果之间相关性,体现了用户的需求。搜索结果与标注为相关文档的相关性越高,则该搜索结果就越有可能是用户需要找的相关文档,我们在重排序中就应该将这种文档向前排。搜索结果与标注为不相关文档的相关性越高,则该搜索结果就越不太可能是用户所希望得到的文档。所以我们希望重排序公式中可以体现出这些特征,将与正例文档近而与负例文档远的文档向前排。具体对一篇文档的排序公式如下:

其中Dres表示原始搜索结果的文档集合;Drel表示被标注为相关的文档集合;Dnrel表示被标注为不相关的文档集合,d is(di,dj)表示文档di与文档d j之间的余弦距离;最后一篇文档与查询相似度计算的公式如下:

从上述公式中我们可以看到:如果一篇文档与被标注为相关的文档近似,而与被标注为不相关的文档差别较大,那么r fscore(di)的取值偏高;反之,如果一篇文档与被标注为相关的文档差别较大,而与被标注为不相关的文档较近似,那么r fscore(di)的取值偏低。在计算score(di)时需要对r fscore(di)和sim(qk,di)这两个不同量纲的值分别进行归一化;在公式中有两个控制因子,它们之间的关系是α+β=1。
sim(qk,di)表示文档di与查询qk相似度的评分,在本文中sim(qk,di)使用的是BM 2500检索模型[15],BM 2500公式的定义如下:
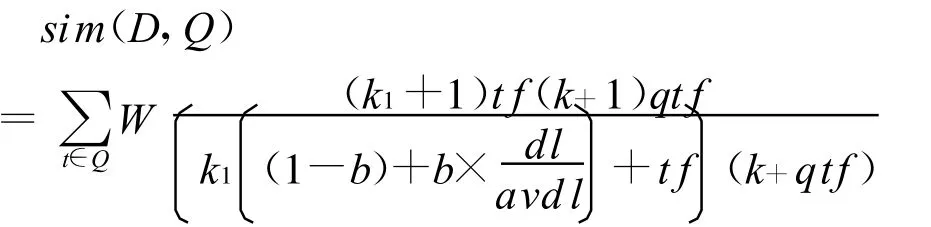
其中Q表示查询;tf表示一个查询词在某一篇文档中的出现频次;qt f表示查询词在所有Q的检索结果集合中的出现频次;d l与avd l分别表示文档的长度和平均的文档长度。权值W的计算方法如下:
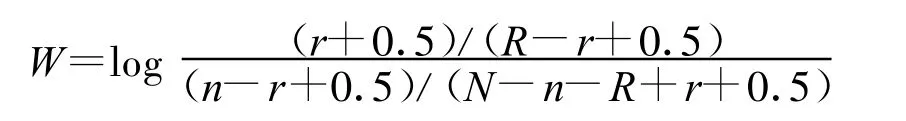
其中N表示文档的数量;n表示包含查询词的文档数量;R表示与查询词相关的文档数量;r表示相关文档中包含查询词的文档数量。
4 性能评测
4.1 评测集合
为了验证本文中提出的搜索结果重排序方法,使用了TREC feedback任务制定的数据集合,该任务采用了前些年TREC中M illionQuery任务与Teraby te任务的数据集合,并根据查询主题编号的奇偶制作了两个评测查询集合Even_Set与Odd_Set(各150个Topic)。为了测试不同规模的反馈信息对于重排序结果的影响,对于每一个Topic都有不同规模的反馈信息。其中B、C、D、E集合分别体现了反馈信息的多少,B集合中只有一篇被标注为相关的文档,C集合中有3篇被标注为不相关的文档,3篇被标注为相关的文档,D中有10篇经过标注的文档,E集合中的被标注文档数不定,但是平均值为246篇。需要注意的是B、C、D、E集合是超集的关系。表中给出了重排序之后MAP值的提高数值。
4.2 实验结果及对比分析
首先给出的表1与表2是本文中的方法在两个评测集合上对于MAP的提升。从表中我们可以发现随着反馈信息的增加,M AP值的提高程度也逐渐的增加。这是比较容易理解的。

表1 MAP在Even_Set上的提升

表2 MAP在Odd_Set上的提升
为了横向比较本文中的重排序方法较经典查询扩展方法在性能上的差异,我们采用了文献[19]中的查询扩展方法。该方法采用如下公式度量 term与查询的同现程度:
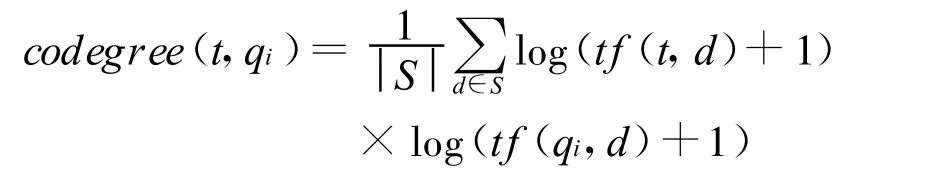
其中t f(t,d)与 tf(qi,d)分别表示t与qi在文档d中出现的频次。我们用上述公式度量t与qi在集合S中同现的可能性。在整合多个查询term的同现取值时,我们使用了下面的公式:
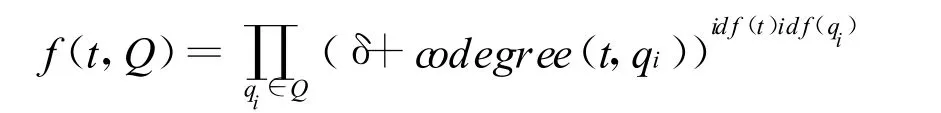
其中id f(t)的定义与第三节中介绍的相同,δ表示平滑因子。
基于文本相似度的重排序方法,目前在本文中给出的是TREC Relevance Feedback官方评测结果。表3则给出了基于查询扩展方法的性能提升,用QE表示,其中QE-X代表不同的反馈信息规模。
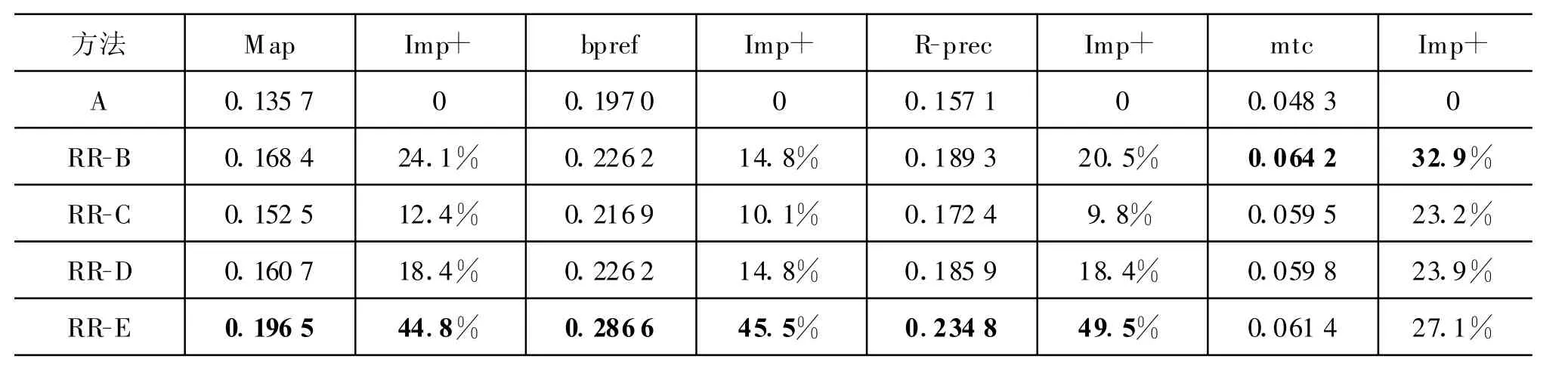
表4 基于检索结果重排序方法的评测结果
表4中列出了在280个官方Topic上,基于文本相似度的重排序方法对各种性能指标的提升,用RR表示,其中RR-X表示不同的反馈信息规模。
表5则给出了两种方法的性能对比。表5中Imp+列表示针对左列性能指标的提升程度;表中的项标识为粗体,则表示在使用同样规模的相关反馈信息时,本文中的方法性能优于查询扩展的方法。从表5的性能对比可以看出本文提出的方法在B与E上的性能明显要好于查询扩展的方法,这也说明在反馈信息很少(B只有一篇相关文档)与反馈信息很多(E)的情况下本文的方法有明显的优势。
从表5中我们还可以知道查询扩展方法在D集合时的性能最好,而本文中提出的方法则在E上的性能最好,因此图1中给出了在这两种情况下不同Topic上的性能提升程度。从图中我们可以看到本文的方法对于不同Topic有着很好的普适性。相较之下,查询扩展的方法则比较依赖于具体的Topic,即在有些Topic上性能提升很多,在有些Topic上提升很少或者没有提升。
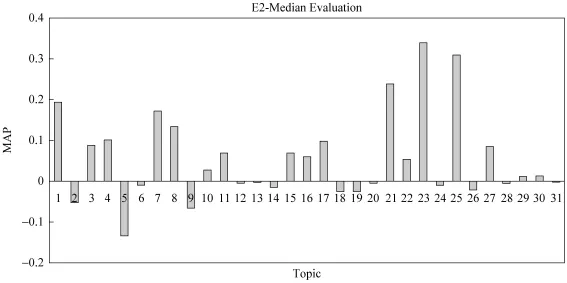
图1 在每个Topic上E2与平均水平对比的结果

表5 TREC官方对全部结果的评测结果
图1中体现了基于文本相似度的重排序方法,在每个Topic上相较于Median Level(所有参赛队在每个Topic上表现的平均值)。我们可以看到基于文本相似度的重排序方法在16个Topic上的表现明显高于M edian Level,在14个Topic上的表现略低于Median Level。但是,从总体角度出发,基于文本相似度的重排序方法的表现高于M edian Level。
5 结论
本文提出了一种基于文本相似度的重排序方法,该方法在相关反馈中可以有效地提高检索系统的检索性能。这种重排序方法综合考虑了:原始检索系统评分、与被标注为相关文档的相关性、与被标注为不相关文档的相关性三种特征。在大规模网络信息检索标准实验数据上的实验结果表明:该方法不仅可以稳定的提高系统的检索性能,并且相较于经典的查询扩展方法有着明显的优势。
在未来的工作中,我们会尝试将基于文本相似度的重排序方法与查询扩展的方法结合起来。另外,选择对什么样的查询做相关反馈,怎样选择反馈信息也是非常值得研究的问题。
[1] Jinxi,X.,W.B.Croft.Imp roving the effectiveness of information retrieval with local context analysis[J].ACM Trans.Inf.Syst.,2000,18(1):79-112.
[2] Gerard,S..Automatic tex t processing:the transformation,analysis,and retrieval of in formation by computer[M].Addison-W esley Longman Publishing Co.,Inc.1989:78-99.
[3] Kamps,J..Improving Retrieval Effec tiveness by Reranking Documents Based on Contro lled Vocabu lary[C]//Proceedings o f the 21th European Con ference on In formation Retrieval,2004:283-295.
[4] Qu,Y.L.,G.W.Xu,etal..Rerank Method Based on Individual Thesaurus[C]//Proceedings of NTCIR2 Workshop,2000:79-112.
[5] Bodo,B.,Z.Justin.Questioning query expansion:an examination of behaviour and parameters[C]//Proceedings of the 15th Australasian database con ference-Volume 27.Dunedin,New Zealand,Australian Computer Society Inc.,2004:69-76.
[6] Carolyn,J.C.,B.C.Donald.Im proving the retrieval effectiveness o f very short queries[J].Inf.Process.M anage.2002,38(1):1-36.
[7] Jones,K.S.,S.W alker.A p robabilistic model of information retrieval:development and comparative experiments[J].Inf.Process.Manage.2000,36(6):779-808.
[8] Kyung Soon,L.,W.B.Cro ft,et al..A clusterbased resamp ling method for pseudo-relevance feedback[C]//Proceedings o f the 31stannual international ACM SIGIR conference on Research and development in information retrieval.Singapore,Singapore,ACM.2008:235-242.
[9] Lee,K.,Y.Park,etal..Document re-rankingmodel using clusters[J].Information Processing and Management,2001,37(1):1-14.
[10] Xuanhui,W.,F.Hui,et al..A study of methods for negative relevance feedback[C]//Proceedings o f the 31st annual international ACM SIGIR conference on Research and development in information retrieval.Singapore,Singapore,ACM,2008:219-226.
[11] Yang,L.,D.Ji,et al..Document re-ranking based on automatically acquired key terms in Chinese in formation retrieval[C]//Proceedings of the 20th international conference on Computational Linguistics.Geneva,Sw itzerland,A ssociation for Computational Linguistics,2004:480-481.
[12] Guihong,C.,N.Jian-Yun,et al..Selec ting good expansion terms for pseudo-relevance feedback[C]//Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval.Singapore,Singapore,ACM,2008:243-250.
[13] Jinxi,X.,W.B.Croft.Query expansion using local and global document ana lysis[C]//Proceedings of the 19th annual international ACM SIGIR conference on Research and development in information retrieval.Zurich,Switzerland,ACM,1996:4-11.
[14] Luk,R.W.P.,K.F.W ong.Pseudo-Relevance Feedback and Title Re-Ranking for Chinese IR[C]//Proceedings of NTCIRWorkshop 4,2004:315-326.
[15] S.E.Robertson,S.W alker,S.Jones et al..Okapi at TREC-3[C]//The Third Text Retrieval Conference(TREC-3),1995:109-126.
