一种基于特征提取的简答题阅卷算法
2010-07-09唐朝霞
唐朝霞
(淮阴工学院计算机工程学院,淮安223003)
0 引 言
随着计算机技术和网络技术的发展,考试从笔试到计算机辅助考试再发展到基于Web的无纸化考试已成为现实.考试系统试题的类型主要有两大类:一类是客观题,答案比较明确、具有唯一性;另一类就是主观题,答案没有唯一标准.目前的考试系统基本己实现对客观题的自动评分,对主观题的自动评分的考试系统还很少.近年来,一些专家也提出一些较好的方法:采用自动搜索匹配技术[1-2],自动处理错位、多字、漏字、错字等问题,自动跳过非匹配部分,按照正确匹配率进行评分.使用基于模糊理论的匹配技术对填空、文字录入、程序设计等题型具有一定的智能,大大提高了计算机智能化阅卷的速度和准确率.但对简答题这样完全主观的试题阅卷方面还不完善,需要进一步研究与探索.
1 简答题阅卷算法
简答题的答案具有不唯一性,即有一定的模糊性,因此阅卷有较高的复杂性.目前采用的方法主要有:
(1)动态规划策略
文本的匹配利用动态规划策略匹配字符,采用从整体到局部的匹配策略,动态挑选可能的最佳解,大大减少了计算量.在文本匹配策略上核心是求两序列(文本字符序列)的最长公共子序列(生物信息学中常用算法)[3].

定义2:设 X,Y是两个序列,且有Z<X和Z<Y,则称Z是X和Y的公共子序列.
定义3:若Z<X,Z<Y,且不存在比Z更长的X和Y的公共子序列,则称Z是X和Y的最长公共子序列,记为Z∈LCS(X,Y).如何找出 X和Y的一个最长公共子序列?考虑用动态规划法.引进一个二维数组C,用C[i,j]记录Xi与Yj的LCS的长度.
如果是自底向上进行递推计算,那么在计算C[i,j]之前,C[i-1,j-1],C[i-1,j]与C[i,j-1]均已计算出来,再根据Xi=Yj还是Xi≠Yj,就可以计算出C[i,j].最终得到X和Y的一个最长公共子序列C.就得到了学生答案与已有试题标准答案的相似程度.
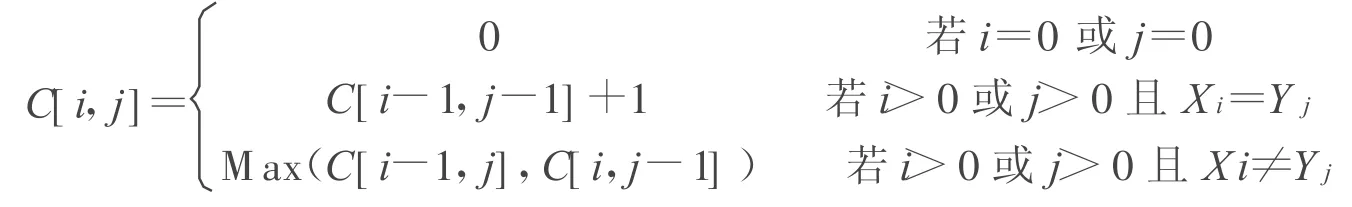
动态规划策略克服“一一对应”比较方法的弊病.然而很多的简答题,并不是答案中每个字符都可以得分,而且每个知识点的不同关键词对应不同的分值,所以该方法可以解决文本匹配的相似度问题,但不适合于简答题的阅卷评分.
(2)模糊数学中的单向贴近度
为解决学生答案和标准答案的贴近度表示问题,把学生答案和标准答案均看成字符串,以字符串S1和S2为例介绍计算字符串S1贴近于字符串S2的单向贴近度,首先把S1分解为若干个有效字符Ul,U 2,…,Un.然后判断第一个字符Ul是否包含在字符串S2中,如果不包含标记为0,否则标记为1,并从S2中去掉包含Ul的字符,对S2进行第二个字符U2的相同处理,一直把Ul,U2,…,Un判断完毕.计算Sl分解后的单字符Ul,U 2,…,Un在S2出现的次数之和m占S1总有效字符数n的比值,并记为单向贴近度[4].该种方法在一定程度上可以解决学生答案和标准答案的贴近度问题,但存在需要把S1分解为若干个有效字符进行比较的麻烦,降低了阅卷的速度.其次,由于不是答案中每个字符都可以得分,所以并不是学生答案和标准答案的贴近度越大,试题的得分就越高.
(3)句子相似度
首先将答案分解为句子,将各语句再进行分词,根据该词向量矩阵,构造句子的相似矩阵,求得学生答案与标准答案的句子相似度[5].该算法能够解决学生答案与标准答案的匹配问题,但同样存在需要分词的麻烦,且如果利用一些现有的分词系统,也不能完全正确分解出与知识点相关的关键词,降低了阅卷的质量和速度.
2 基于特征提取的简答题阅卷算法
分析教师的阅卷过程,教师在人工评阅简答题时一般先预先制定好一套评分标准,然后将每道试题的总分划分成若干部分,将分数分配到试题的求解过程中的一些关键的步骤或关键的词语上,称之为得分点.最后计算学生答案中的得分点的得分总和,即为最终得分.
根据对人工阅卷过程的分析可以发现简答题评分的因素主要有两个:一是标准答案及评分标准,另一个是学生得分点吻合的多少.因此,在简答题阅卷中,首先将标准答案分成若干个得分点,而文本的近义词问题导致每个得分点又可能有若干个特征值.系统将标准答案的基本特征存储起来,构造一个答案特征表[6],并为不同的答案特征配上权值(分值),改变上述完全匹配答案的模型,不再给出试题的完整答案,而是从答案特征表中为试题提取相关特征进行评定其小分,最后累加答案中各特征值的得分即可.
例如简答题1:因特网为我们主要提供了哪些服务,设总分为10分,构造其答案特征表如图1.
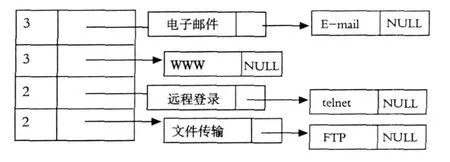
图1 答案特征表
图中答案特征表的头结点值表示标准答案的特征值的分值,表结点的值表示标准答案中某得分点的特征值,由于文本存在的近义词问题,所以标准答案的同一个得分点可能有不同的特征值.
阅卷时,首先获取学生的答案,从标准答案特征表中提取第一个得分点的特征值,然后与学生的答案进行匹配.如果匹配成功,将该特征值的分值加入该简答题的得分,再进行下一个得分点的匹配;如果匹配失败,继续提取该得分点的下一个特征值与学生的答案再进行匹配,直到匹配完答案特征表中所有得分点,最终得到该题的得分.简答题的阅卷算法如算法1.
算法1:For i=1 To n
/*n表示某简答题的答案特征表的得分点总数
从标准答案特征表中提取出第i个得分点的特征值Ti
Do
If Ti匹配学生的答案 Then
将特征值Ti的分值累加到该题总分sum
Exit Do
Else
If答案特征表第i个得分点还有下一个特征值Then
Ti=答案特征表第i个得分点的下一个特征值
Else
Exit Do
End If
End If
Loop
Next i
算法1将学生答案与答案特征表中提取的特征值进行匹配,再根据该特征值的权值完成阅卷.其优点为:
1)增加试题时只需输入试题答案得分点的特征值,减轻了教师输入标准答案的工作量.
2)阅卷按特征值进行匹配屏蔽了一些与得分点无关的字符的比较,提高了阅卷的准确性和速度.
但算法1将学生答案与答案特征表中提取的特征值进行匹配时,没有任何的顺序限制,所以只适合得分点顺序无关的简答题.为了解决将学生答案与答案特征表中提取的特征值需要依次进行匹配的问题,本文引入定位特征值的概念,简答题标准答案得分点的定位特征值定义为该得分点在标准答案中的顺序.
例如简答题2:图像是如何进行数字化的?设总分为10分,构造其答案特征表如图2.
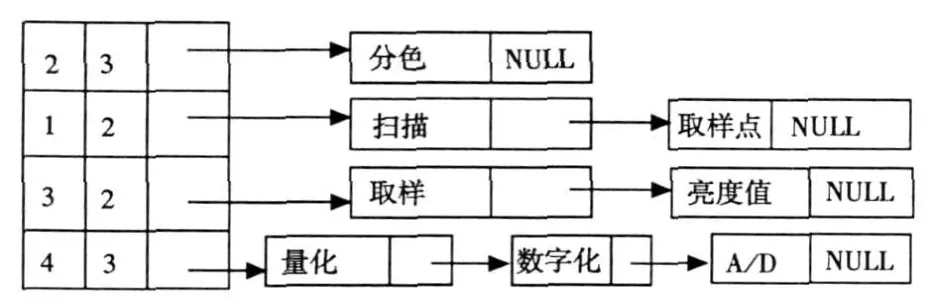
图2 答案特征表
图中答案特征表的头结点值有两项,第一项表示某得分点的定位特征值,第二项表示标准答案的特征值的分值.表结点的值表示标准答案中同一得分点的特征值.
阅卷时首先获取学生的答案,根据定位特征值顺序从答案特征表中提取特征值信息,然后与学生的答案进行匹配.如果匹配成功,将该特征值的分值加入简答题得分,并从学生答案匹配成功后的位置开始再进行下一个得分点的匹配;
如果匹配失败,继续提取该得分点的下一个特征值与学生的答案进行匹配,直到匹配完答案特征表中所有得分点,最终得到该题的总分.简答题的阅卷算法如算法2.
算法2:For i=1 To n
/*n表示某简答题的答案特征表的得分点总数
从答案特征表中提取出定位特征值为i的特征值Ti
Do
If Ti匹配学生的答案Then
将特征值Ti的分值累加到该题总分sum
学生的答案=与特征值Ti匹配位置后的字符串
Exit Do
Else
If 答案特征表中定位特征值为i的特征值Ti还有下一个特征值Then
Ti=答案特征表中定位特征值为i的下一个特征值
Else
Exit Do
End If
End If
Loop
Next i
3 阅卷结果分析
为验证算法进行阅卷的可行性和有效性,以简答题2为例,五位学生输入的答案如下:
答案1:图像数字化的过程为:1、扫描 2、取样3、量化
答案2:图像首先扫描得到若干取样点,在分色,最后数字化.
答案3:1)扫描2)分色3)取样4)A/D
答案4:1、分色2、取样3、扫描4、量化
答案5:图象的数字化过程为取样、分色和数字化.
采用算法2阅卷的结果如表1:

表1 阅卷结果表
4 结束语
目前人工智能技术中自然语言理解这一领域仍在研究之中,因而要实现计算机完全的理解阅卷有一定的难度.本文提出的基于特征提取的简答题阅卷算法,既减轻了教师输入的工作量,又提高了简答题阅卷的准确性和速度.并引入定位特征值的概念,解决了学生答案与特征值需要依次进行匹配的问题.
[1]刘 琰,周 理.基于VLCA的关键字查询匹配算法[J].科学技术与工程,2008,(2):420-423.
[2]李 明,王 丽.基于本体的信息检索系统模型[J].兰州理工大学学报,2007,(2):90-93.
[3]高思丹,袁春风.语句相似度计算在主观题自动批改技术中的初步应用[J].计算机工程与应用,2004,(14).
