基于混合Q学习的多Agent系统
2010-07-07陈玉明张广明赵英凯
陈玉明,张广明,赵英凯
(南京工业大学 自动化与电气工程学院,南京 210009)
0 引言
强化学习允许多Agent能够在没有关于任务和环境的先验知识的条件下,只有通过不断与变化的环境进行“试错式”交互,并从环境中获取强化信号来学习一种从状态到动作的映射,以便能获取最大的奖赏,并且它所做出的合理的策略将被得到加强。在多Agent系统中,对学习Agent而言,当前的环境状态可以通过自身执行的动作来改变,但由于同时其他Agent也在进行学习,它们执行动作也在改变环境状态。此外,多Agent强化学习从环境中获得的强化信号是基于多Agent系统,而不是基于独立的学习个体。在多Agent强化学习中,所有学习Agent的状态变量构成联合状态,它们执行的动作构成联合动作,每个Agent学习各自的策略。所有Agent的联合动作作用于环境并使环境状态发生改变,同时得到回报。回报根据某种信度分配策略分配给每个独立的Agent,以完成各自的强化学习 。本文提出了基于Agent独立学习的情形下,多Agent通过协作的混合Q学习算法,多Agent根据环境情况,进行联合动作学习,提高了整体的学习性能;通过神经网络的泛化和存储能力,优化学习状态,提高学习效率。
1 多智能体联合强化学习
在多Agent系统中,Agent不但表现为个体的行为,应该依照自己的规则行动,更重要的是它所应当表现出来的社会行为。多个Agent共同完成任务,可能会比单个Agent完成更有效率,或者是完成单个Agent所不能独立完成的任务。因此在Agent做出行动的决策之前,了解其它Agent的可能决策是相当地有用 。由于每个Agent的动作都会带来环境状态的变化。Agent成为了环境动态的一个因素,环境变化很难用一个MDP来表示。因此Agent在多Agent的环境中做出决策的过程,是一个通过推测其它Agent而综合做出决策的过程,把它称为推测决策过程。Agent的决策过程分作三步:第一步是根据对等原理推测其他Agent的过程;第二步是选择自己的最优动作的过程;第三步是更新学习的过程 。
本节将研究基于Multi-Agent的联合Q学习方法,其中Multi-Agent强化学习的Q函数依赖于所有Agent执行的动作效果总和。定义学习目标为学习策略π,,S为有限状态集,A为Agent动作集合。时刻t在状态st下,Agent选择动作的概率分布表示为π={P1,P2,...,Pi},策略π={π1,π2,...,πn},从状态st开始,按策略了获得的期望累计折扣回报为[4]:

其中,0≤γ<1为折扣因子,反映了对当前回报与未来回报的取舍,rt指每次获得的有界回报,由于是在非确定马尔可夫环境下进行学习,累计回报加上期望运算,最佳策略是使(1)式获得最大值的策略,其中Agent执行联合动作其后继状态为s'。Multi-Agent强化学习的Q函数依赖于所有Agent执行的联合动作,对于强化学习算法改进为:

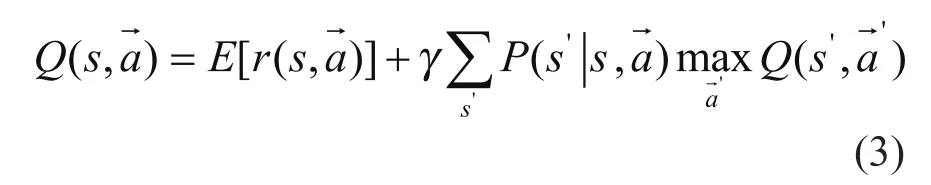

at是动态学习率。用表示学习Agent的最佳策略,用Tn表示n个Agent联合状态转移函数其中Agent联合环境状态自身状态为,将(4)式变为:

强化学习过程如下:
1)初始化所有的Q-表
2)通过输入和知识库系统判断当前的联合状态
3)推测联合动作
4)选择一个使群体最优行为
5)Agent实现行为 ,然后当环境的状态从 迁移到 , Agent将得到一个奖赏值
6)更新Q-表的值
7)进行到下一个时刻
2 Multi-Agent基于神经网络的联合强化学习
传统的强化学习算法,如Q学习算法利用表格来表示Q(s,a)函数,但当状态集合S、系统动作集合A较大时,但该方法需要占用大量的内存空间,而且也不具有泛化能力。将强化学习和神经网络相结合,主要是利用神经网络的强大存储能力和函数估计能力。一般来说,神经网络在系统中的工作方式 是:接收外界环境的完全或不完全状态描述,作为神经网络的输入,并通过神经网络进行计算,输出强化学习系统所需的Q值,网络的输入对应描述环境的状态。采用神经网络实现Q学习克服了传统Q学习存在的问题,采用这种方式在较大程度上发挥这两种技术各自特有的优势[6]。本文提出了基于神经网络的Q学习,即用神经网络来逼近Q函数,从而可以克服图表存储Q值所存在的缺陷,提高了混合算法的学习速率,应用一个3层的BP神经网络,BP算法是由两部分组成:信息的正向传递与误差的反向传播。BP网络隐层的输入为状态矢量S=(s1,s2,...sn),网络的输出为每一状态下可选动作的Q-值,即。
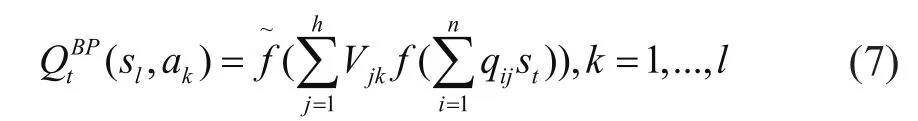
式中可取:

由式(4)可知,每次执行一个动作后的Q值会更新,其Q值的变化为:

而ΔQ可以看作是BP网络输出层的误差,隐层与输入层的权值q更新公式如下:

利用BP算法的误差反向传播就可以调整权值保存调整后的Q值,从而实现Q值的学习[7]。其框图如图1所示。
3 实验结果
3.1 实验设计

图1 基于Multi-Agent的混合Q学习算法实现结构图
为了能验证Multi-Agent混合强化学习的有效性和功能的正确性,利用hunters-prey模型,设计仿真实验如下:1)用实验空间为20 *20格的类似棋盘的平面,一个prey和四个Hunter速度相同,均为全局视觉,每次行动一格有5种可能:原地不动、上、下、左、右移动一格,初始位置随机生成;2)环境无边界,如果围捕的步数超过100步,则认为围捕失败;3)4个Hunter在prey临近上下左右四个方格中,认为围捕成功;4)prey的逃跑策略是:向离自身最近的 的反方向逃跑, 移向prey所在格时会被随机传送的棋盘中的一个空格中作为惩罚,如果两个捕食者同时移向同一个格子也会收到惩罚。实验初始态模型如图2-1所示,图2-2是成功围捕的状态图。

图2-1 Hunters-prey模型初始状态图

图2-2 Hunters-prey模型成功围捕图
3.2 实验结果
设定学习结束条件为学习次数到达10000次,利用3种学习agent进行实验,即Multi-Agent Independence Q-Learning(MIQ)、Multi-Agent Coordination Q-Learning(MCQ)和Multi-Agent Coordination Q-Learning at Neural Network(MCQNN) ,其中, MIQ采用的是MAS中agent采用单独Q学习算法;即Q-学习; MCQ采用的是MAS中采用联合Q学习算法; MCQNN采用的是本文所提出的基于神经网络的联合Q学习算法,实验结果如表1所示,每种情况都运行1000次,计算实现围捕的成功率.

表 1 围捕的成功率比较
由结果可以看出,MAS都采用单独Q学习算法时,实现成功率为23%,这是单Agent不对其他Agent建模的原因所致; 使用联合Q学习算法时,实现成功率为77%,较第一种情况有了很大的提高,Multi-Agent采用了协作学习,对于全局控制远远好于单独Q学习,而第三种基于NN的联合Q学习在效果上,比联合Q学习又得到了一定的提升。
图3是三种不同Q-学习算法学习的策略成功抓取prey时间的结果图。从图中可以看到,在 周期中CAQNN算法和MCQ算法相比于MIQ算法都显示出了更快的学习速度,结合图4中所示的实验结果,出现这种现象是因为MCQNN算法使用神经网络替代了状态—动作对的表格搜索,而MCQ算法其需要考察的状态一动作对远远少于MIQ算法。同样在这次实验中也注意到其后不久MIQ算法的效能急剧减退并且始终存在着剧烈的振荡,而最后的结果也无法收敛到较好的值,其原因是MIQ算法没有考虑其他智能体的动作,无法与别的智能体交互的同时导致环境的不稳定而无法收敛。考察到 周期时,MCQ算法的学习结果与到MCQNN的学习算法效果还有一定差距。由此可见,MCQNN学习算法拥有良好的学习效能,一般情况下也可以找到达成学习目标解。
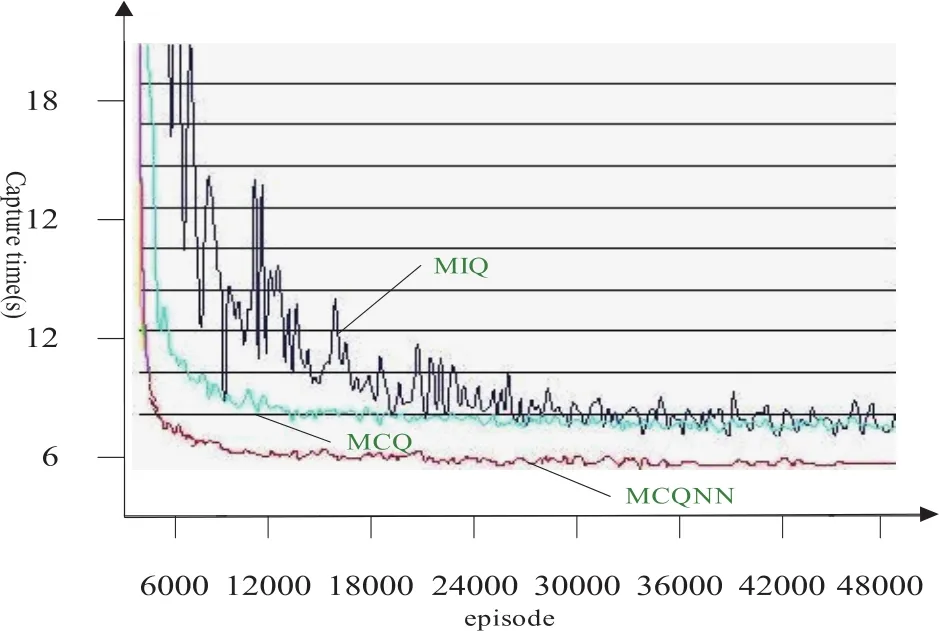
图3 三种算法策略的成功抓捕Prey的时间
4 结论
本文使用的多智能体神经网络联合Q学习算法,结合了联合Q学习和神经网络的特点,既考虑到了智能体的交互学习,同时通过神经网络的泛化能力替代了传统的Q学习表格法。减少了搜索表格的时间和节省了大量的内存空间,在提高学习速率的同时,又取得了较好的学习效能,也解决了由于“维数灾难”带来的Q值表示所引起的内存开销问题。
[1] 高阳,陈世福,陆鑫.强化学习研究综述[J].自动化学报,2004,30(1):86-100.
[2] Bevan Jarvis,Dennis Jarvis,Lakhmi Jain.TEAMS IN MULTIAGENT SYSTEMS[J].Intelligent Information Processing III,2006:1-10.
[3] 唐文彬,朱淼良.基于强化学习的多Agent系统[J].计算机科学,2003,30(4):16-18.
[4] 郭锐,吴敏,彭军,等.一种新的多智能体Q学习算法[J].自动化学报,2007,33(4):365-372.
[5] Suton R S.Learning to predict by the methods of temporal differences[J].Machine Learning,1988,(3):9-44.
[6] 张彦铎,闵锋.基于人工神经网络在机器人足球中的应用[J].哈尔滨工业大学学报,2004,36(7):859-861.
[7] Jim Duggan. Equation-based policy optimization for agentoriented system dynamics models[J].System Dynamics Review Volume,2008,24(1):98-118.
[8] 苏治宝,陆标联,童亮.一种多智能体协作围捕策略[J].北京理工大学学报,2004,24(5):403-406.
