基于麦克风阵列的声源定位研究*
2010-07-02邓艳容景新幸任华娟
邓艳容,景新幸,任华娟
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
麦克风阵列的声源定位是指用麦克风阵列拾取声音信号,通过对多路声音信号进行分析与处理,在空间域中定出一个或多个声源的平面或空间坐标,即得到声源的位置,以进一步控制摄像机和麦克风阵列波束对准正在说话的人。它在视频会议、语音识别、说话人识别和助听设备等领域中都有广泛的应用。目前,基于麦克风阵列的声源定位方法大体上可分为三类[1]:(1)基于子空间的定位技术;(2)基于可控波束形成的定位技术;(3)基于到达时延(TDOA)的定位技术。TDOA方法首先求出声音到达不同位置麦克风的时延,再利用这些时延求得声音到达不同位置麦克风的距离差,最后用搜索或几何知识确定声源位置。
在现有的麦克风阵列声源定位方法中,基于到达时间差(TDOA)估计定位法计算量较小,硬件成本较低,定位精度较高,同时也易于实时实现,是目前声源定位法中常用的方法。
1 声达时间差TDOA估计
基于声达时间差(TDOA)估计定位法的关键技术是时延估计,其精确性直接决定了整个定位系统的有效性。目前,时延估计的算法有很多,本文在传统的LMS自适应时延估计的基础上,提出一种改进的LMS自适应时延估计法,其主要思想是提取语音的激励信息来进行时延估计。
1.1 传统的LMS自适应时延估计
1982年Youn等人提出了LMS自适应时延估计算法[2],该算法通过最小均方的准则,在收敛的情况下给出时延估计值,因此不需要信号和噪声的先验知识,但对噪声和混响都比较敏感。
基于Widrow的LMS自适应时延估计算法的原理如图1所示。
从图1可以看出,用自适应滤波求时延时,将2个麦克风的接收信号x1(n)和x2(n)分别当作目标信号和输入信号,用 x2(n)去逼近 x1(n)。对 x1(n)加 z-p是为了保证因果性而加入P个采样周期的延迟,以保证该结构能适应正延迟和负延迟两种情况。自适应时延估计法的算法如下:
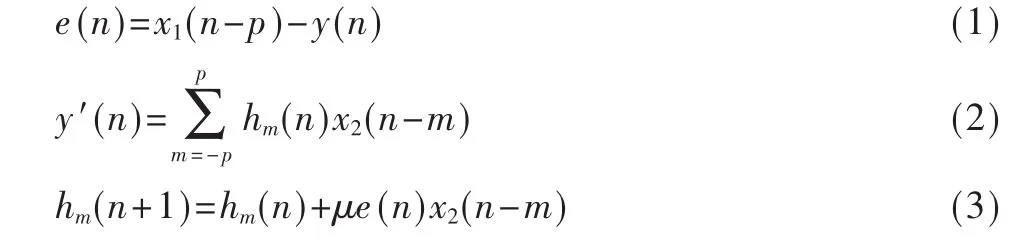

图1 LMS自适应时延估计原理图
根据最小均方误差(LMS)准则,当滤波器系数为:

时,信号 x1(n)和 x2(n)之间的均方误差 E{e2(n)}取最小值。此时滤波器系数h(n)收敛,找出h(n)中最大值对应的 m,再减去 P,就求得信号 x1(n)和 x2(n)间的时延 τ12。
1.2 改进的LMS自适应时延估计
传统的LMS自适应时延估计法很容易受到噪声和房间混响的影响,本文结合语音信号的特点,提出了一种利用语音激励信息的LMS自适应时延估计算法[3]。
1.2.1 语音激励信息的提取
语音在传播过程中,激励信号中的脉冲激励的位置不会改变,因此利用语音激励信息的时延估计算法不易受到噪声和混响的影响。根据语音的生成模型,线性预测残留误差e(n)包含了产生语音的激励脉冲信息,可以作为语音激励信号的一个估计[4]。通过线性预测(LPC)分析即可得到残留误差e(n)。

其中 ai为预测系数,s(n)表示 n时刻的纯净语音,(n)为其预测值。由于噪声和混响的影响,残留误差e(n)中的脉冲激励被削弱,为了锐化峰值,利用LPC残留误差e(n)的包络h(n)代替e(n)。为了进一步减少噪声和混响的影响,可以采用削波的方法对h(n)进行处理。
1.2.2 基于语音激励信息的自适应时延估计
基于语音激励信息和LMS自适应时延估计算法的原理,采用语音激励信息的LMS自适应时延估计(LPCLMS)原理如图2所示。
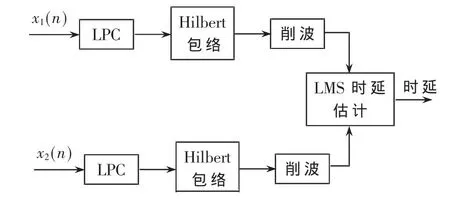
图2 LPC-LMS时延估计原理图
LPC-LMS时延估计的步骤:
(1)把麦克风1和麦克风2采集的语音信号x1(n)和x2(n)分别通过相应的预测误差滤波器,得到LPC残余信号 e1(n)和 e2(n)。
(2)利用 Hilbert变换分别提取 e1(n)、e2(n)的 Hilbert包络 h1(n)和 h2(n)。
(3)对h1(n)和 h2(n)分别进行削波处理。
(4)将削波处理后的语音激励脉冲进行LMS自适应时延估计。
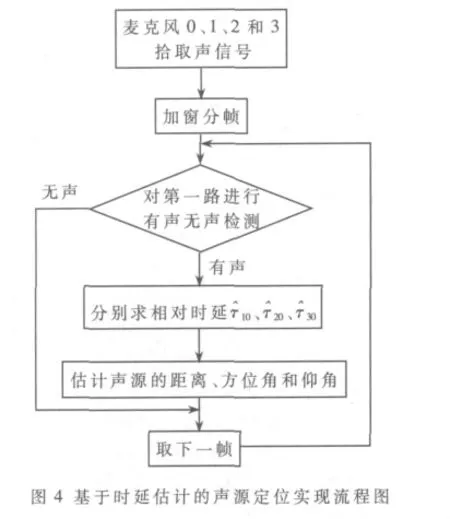
2 基于时延估计的声源定位
基于时延估计的定位技术是通过麦克风阵列接收声源发出的语音信号,再根据麦克风和声源的几何模型,利用语音信号到达不同麦克风的时间差来估计声源位置。本文采用的是平面四元几何定位法[5],阵列结构如图3所示,由4个全向麦克风0、1、2和3组成。设麦克风0为参考麦克风,并以其所处的位置为原点建立直角坐标系。其余3个麦克风与参考麦克风0的距离均为d。

图3 平面四元阵列定位示意图
设声源入射波到达麦克风1、2和3相对于到达参考麦克风 0的时间延迟分别记为 τ10、τ20和 τ30。声源的方位角为φ,定义为声源入射方向在xoy平面的投影与x轴正向的夹角;仰角为θ,定义为声源入射方向与其在xoy平面的投影的夹角。声源距参考麦克风的距离记为R,空气声速为c。由声源和麦克风阵列的几何位置关系,利用余弦定理,可得声源距参考麦克风0的距离R为:

声源方位角φ为:

声源的仰角θ为:
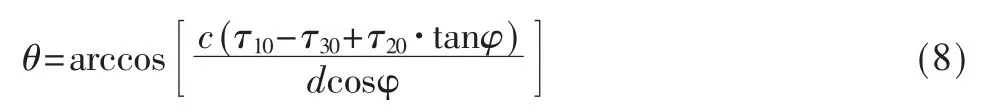
综上所述,基于时延估计的声源定位的实现流程如图4所示。
3 实验仿真
下面用MATLAB仿真来验证前面的算法。仿真环境设定为普通会议室,房间大小为7 m×5 m×3 m。声源在实验室录制完成,采样频率为16 kHz,16 bit。采用矩形窗进行分帧,帧长为1 024点,帧移为512点。本文采用短时平均过零率和能量阈值法对每帧数据进行有声无声检测,得到的语音帧为209帧,线性预测阶数为12。麦克风阵列和声源的几何模型如图3所示。设以麦克风0为参考麦克风建立直角坐标系,语音源坐标为(2.15,2.15,1.62),噪声源坐标为(5.00,1.50,1.50),参考麦克风 0的坐标为(1.00,1.00,0.90),其余3个麦克风坐标分别为 mic1(1.25,1.00,0.90),mic2(1.00,1.25,0.90),mic3(0.75,1.00,0.90)。声源到传声器的脉冲响应函数由IMAGE模型[6]产生。混响时间与反射系数β的关系为:
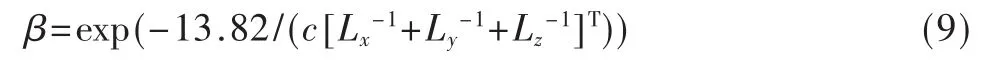
其中 Lx,Ly,Lz表示房间的大小,c 表示声速(340 m/s)。
图5从上到下分别为麦克风0接受的语音混响序列、其 LPC误差信号 e(n)、Hilbert包络 h(n)、削波处理后的语音激励信息。从图5可以看出,经过Hilbert变换,削波处理后的信号削弱了无关峰值,使有用峰值变得更加尖锐,从而抑制了噪声和混响的影响。
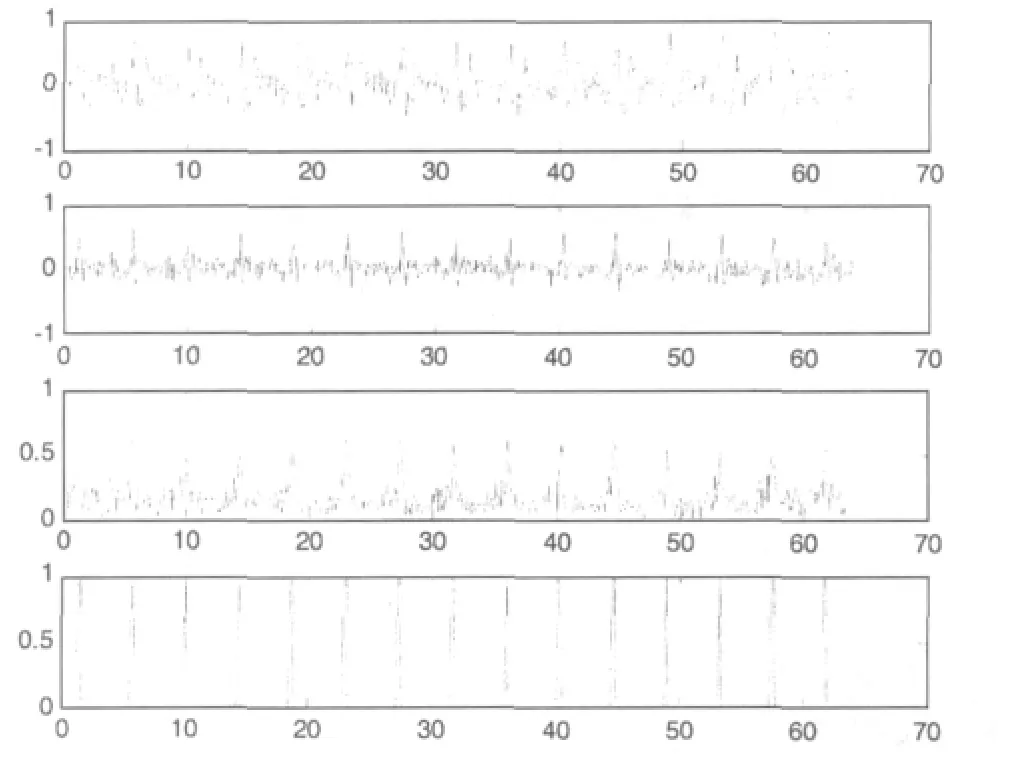
图5 参考麦克风0采集的语音
图6和图7分别为混响时间T=100 ms和T=300 ms时,在不同信噪比情况下的时延估计。由图可得,无论是在强混响(T=300 ms)还是在弱混响(T=100 ms)的情况下,LPC-LMS法的有效率都要高于传统的LMS法。特别是在强混响(T=300 ms)、低信噪比(SNR=-10 dB)的环境下,LMS法的有效率只有3.76%,而LPC-LMS法还能获得41.04%的有效率。由实验结果可见,改进的LPC-LMS法对混响和噪声都有很好的抑制作用。

实验采用改进的LPC-LMS方法进行时延估计,结合平面四元几何定位法对声源进行定位。声源距参考麦克风的真实距离为1.778 6 m,真实仰角为23.880 9°,真实方位角为135°。图8分别示出了距离、仰角和方位角的定位情况。实验结果表明,声源的定位误差很小,在实际的声源定位中是可行的。理论分析和实验仿真结果表明,采用本文提出的基于语音激励信息的LMS自适应时延估计(LPC-LMS)结合平面四元几何定位法来进行声源定位,抗噪声、抗混响能力强,算法稳健,容易实现,定位精度高,用该方法实现实时的声源定位是可行的。

[1]李海成.基于传声器阵列的自动声源定位方法[J].辽宁师范大学学报,2006,29(2):168-171.
[2]YOUN D H,AHMED N,CARTER G C.On using the LMS algorithm for time delay estimation[J].IEEE Transactions on Acoustics,Speech Signal Processing,1982,30(5):798-801.
[3]郭威,曾庆宁,刘庆华,等.基于声门脉冲的自适应时延估计算法[J].计算机应用研究,2008,25(3):726-728.
[4]MURTHY P S,YEGNANARAYANA B.Robustness of group-delay-based method for extraction of significant instants of excitation from speech signals[J].IEEE Trans.Speech Audio Processing,1999,7(6):609-619.
[5]郭威.基于麦克风阵列的说话人定位技术研究[D].桂林:桂林电子科技大学,2007.
[6]ALLEN J B,BERKLEY D A.Image method for efficiently simylating small-room acoustics[J].Journal of Acoustical Society of America,1979,65(4):943-950.
