基于柱搜索的高阶依存句法分析
2010-06-05李正华车万翔
李正华,车万翔,刘 挺
(哈尔滨工业大学 计算机科学与技术学院 信息检索研究中心,黑龙江 哈尔滨 150001)
1 引言
依存分析是针对给定的句子x=w1w2…wn,遵循某种依存语法体系,建立句子对应的依存树y。依存语法相对于短语结构语法而言,其优点在于:(1)形式简洁,不增加额外的非终结标记,易于理解。(2)侧重于反映语义关系,可以很容易地和语义分析结合。(3)适合表示交叉关系,因此适用于大多数语言。(4)有利于实现线性时间的搜索算法。因此,依存句法分析受到国内外学者广泛的关注。CoNLL 2006、2007年连续两年评测多语依存分析任务。CoNLL 2008评测英语依存语义分析任务。CoNLL 2009评测多语依存语义分析任务。这些评测任务的开展,也促进了依存分析的发展。
本文内容组织为:第2章介绍依存分析相关工作;第3章介绍基于柱搜索的高阶依存分析方法;第4章为实验;第5章给出结论及进一步工作。
2 相关工作
目前的依存分析的主流方法有两种,第一种是基于转移的方法,第二种是基于图的方法。基于转移的方法将依存树的构建分解为一个动作序列,由分类器根据当前状态来决定下一个动作。Covington[1], Yamada[2], Nivre[3]等人采用了这种方法。
基于图的方法将依存分析看成在有向图中求最大生成树的问题。对于输入的句子x=w1w2…wn,可以构建一个有向图G=(V,E)。V={0,1,…,n}为节点集合,对应每一个词,0为增加的伪节点,用以表示依存树的根节点。E={(i,j,l}|0≤i≤n,1≤j≤n,l∈L}为有向边集合。其中L表示依存关系集合,(i,j,l)表示一条从i指向j的有向边,依存关系为l。有向图G中每两个节点之间可以有多个同方向的但是不同依存关系的有向边。依存分析的目标是从图G中找到一颗分值最大的依存树。Eisner设计出了基于span的算法,使得上述搜索过程可以在O(n3)时间内完成[4]。McDonald提出了一阶依存分析模型,假设依存树中的弧相互独立,依存树的分值为所有弧分值的累加[5]。进而,McDonald又将一阶模型扩展为二阶模型,假设依存树中一条弧的分值与它相邻的兄弟弧(核心节点与其前一个儿子节点构成的弧)相关[6]。Carreras扩展了二阶模型,提出高阶模型。高阶模型假设一条弧的分值与其最左和最右的孙子弧(非核心节点与其儿子节点构成的弧)相关[7]。
3 基于图的依存分析方法
3.1 依存分析模型
本文扩展了Carreras的高阶模型,假设一条弧的分值与其所有的孙子弧相关。模型如公式(1)所示。
(1)
S(x,y)表示输入句子x对应的依存树y的分值,由三部分构成:每一条依存弧的分值Ssingle(h,c,l),兄弟节点互相影响的分值Ssibling(h,ci,ci+1),以及祖孙节点互相影响的分值Sgrand(h,c,gc,l)。第二部分中,ci和ci+1表示相邻的兄弟节点,注意在计算兄弟之间互相影响的分值时,模型没有考虑依存关系。
3.2 解码算法
3.2.1 依存关系标注策略
McDonald的方法在解码之前,利用一元特征为任意一条弧确定了唯一的依存关系,并且在解码过程中,直接使用一元特征对应的分值。这种做法虽然比较简单地解决了依存关系标注的问题,但是由于没有利用丰富的依存关系特征,因此很大程度上影响了依存关系准确率。为此,本文首先利用一元特征,为每一条弧确定K1个可能的依存关系L1(.);然后利用二元特征,对这K1个依存关系进行重排序,得到K2个可能的依存关系L2(.),进一步缩小依存关系的数量(K2≪K1<|L|)。L表示训练语料中出现的依存关系类型集合。最后,在解码过程中每条弧仅使用选出的K2个依存关系。整个过程如公式(2~3)所示,其中funi(.)表示一元特征集合,fbi(.)表示二元特征集合。整个过程的时间复杂度为O(n2|L|logK1+n2K1logK2)。

(2)
(3)
3.2.2 基于span的基本操作及分值计算
在Eisner提出基于span的算法之前,基于图的依存分析一般以组块(Constituent)为基本单位。组块表示输入句子的一个片断ws...wt(0≤s≤t≤n)对应的子树,即包括一个核心词,片断中其他词都是这个核心词的子孙节点。组块中核心词的位置是任意的,可以是片段中的任意一个词wi(s≤i≤t)。Eisner算法以span作为解码的基本单位。Span也表示输入句子的一个片断对应的子树。与组块不同的是,span的核心词必须位于片段首或尾。Span的这种特性使得解码算法独立的确定一个词左边的修饰成分和右边的修饰成分,从而降低算法的复杂度。
Span可以分为两种,完整span和不完整span。完整span中除了核心词外其他词的所有修饰成分全部找到,使用←或→表示。不完整span除了核心词外,另外一个位于片段首或尾的词的修饰成分也没有全部找到,使用|←或→|表示。图1中包含了三个span,分别记作sps→r,spr+1←t和sps→|t。其中sps→r和spr+1←t表示了两个完整span;而sps→|t表示一个不完整span。sps→r代表了以ws为核心词的一颗子树,其他词ws+1,r都是ws的右修饰成分,并且sps→r包括了ws+1,r完整的修饰成分。spr+1←t则表示了以wt为核心词的一颗子树。sps→|t包括了ws的右子孙节点,但是不包括wt的右子孙节点。
解码算法中包括两类操作。第一是将两个完整span合并为一个不完整span,如图1所示。第二类操作将一个完整span和一个不完整span合并为一个完整span,如图2所示。图1和图2中的操作得到新的span都是以最左边的词作为核心节点。得到以最右边词作为核心节点的span的操作是类似的。

图1 两个完整span合并为一个不完整span

图2 一个完整span和一个不完整span合并为一个完整span

S(sps→|t)=S(sps→r)+S(spr+1←t)
+Sicp(s,r,t,l)
(4)
Sicp(s,r,t,l)=w·ficp(s,r,t,l)
(5)
ficp(s,r,t,l)=funi(s,t,l)∪fbi(s,t,l)∪fsib(s,sck,t)

(6)
图2中sps→|r和spr→t合并为sps→t,这个操作不会增加弧。sps→t的分值由三部分构成,如公式(7~9)所示。第三部分表示由r的右侧儿子节点对应的祖孙特征贡献的分值,包括了所有t右侧儿子节点对应的祖孙特征。而Carreras的高阶模型中仅考虑t最远的儿子节点,此处指tck。

(7)
(8)
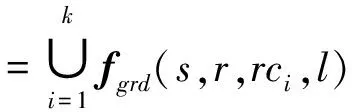
(9)
3.2.3 基于柱搜索的解码算法
由于高阶特征的引入,Eisner算法不再具有动态规划算法要求的最优子结构特性。如图2中的合并操作,sps→t的分值最大,并不意味着sps→|r和spr→t都分值最大,还取决于第三部分分值。而第三部分分值又和sps→|r与spr→t中包含的弧和依存关系相关。本文采用柱搜索的方法来获得近似解。算法如下:
1 initialization:C[s][s][c]=0.0∀0≤s≤n,c∈{cp,icp}# cp:complete; icp:incomplete
2 forj= 1..n
3 fors= 0..n
4t=s+j
5 ift>nthen break




10 end for
13 end for
线图(chart)的每一个位置保留K个最优的span,如C[s][t][icp]保存了sps→|t类型的K个最优的span。算法第6行的含义是,遍历s≤r 算法第6行和第7行的时间复杂度均为O(n2K2K2logK),其中K2=|L2|。注意由于在获取祖孙特征的时候,使用了所有的孙子节点,因此复杂度为O(n)。第8行和第9行复杂度为O(n2K2logK)。因此整个算法复杂度为O(n4K2K2logK)。由于K和K2一般很小且为常数,因此可以认为整个算法复杂度是O(n4)。 在CoNLL 2009多语语义依存分析评测任务中,作者采取将依存分析和语义角色标注级联的策略。CoNLL 2009评测任务包括汉语、英语、日语、捷克语、德语、西班牙语、加泰罗尼亚语七种语言。其中英语、德语、捷克语还提供了跨领域(ood, out of domain)的测试语料,用以评价系统对不同领域语料的适应能力。 CoNLL 2009评测包含的七种语言中,捷克语、德语、英语都不同程度的含有交叉弧的依存树。本文的模型和算法无法处理含有交叉弧的情况。对于这三种语言,作者使用了Nivre的pseudo-projective方法[8],先将含有交叉弧的句子转化为不含有交叉弧,用以训练本文的依存分析器。最后,将分析结果逆向转化,恢复为含有交叉弧的依存树。 本文借鉴McDonald采用的一阶和二阶特征,以及Carreras采用的高阶特征,对作者参加CoNLL 2008评测任务的系统使用的特征[9]进行了扩充。 本文实验的机器配置是2.5GHz Xeon CPU, 16G内存。依存分析器内存使用峰值为15G,训练时间最多约60个小时。由于CoNLL 2009年评测涉及语言比较多,并且本文的系统对内存等资源要求很高,作者没有进行细致的特征选择和参数优化。训练模型过程中,针对不同语言,参数设置为:依存关系数量K1=10,K2=2,最优span数量K=10,迭代次数T=5~10。测试阶段参数设置为:K1=20~50,K2=2~3,K=10。 本文将使用所有孙子节点构成祖孙特征的扩展模型与Carreras的只使用最左和最右的孙子节点构成祖孙特征的模型在开发数据集上作以对比,实验结果如表1所示。其中LAS表示依存关系准确率,UAS表示依存弧准确率。扩展模型在加泰罗尼亚语和西班牙语上性能有明显的提高,而在汉语、英语 (UAS)、捷克语 (UAS)上有明显的下降,其他语言则影响不大。其原因还需要深入的实验和分析。 表1 本文扩展模型与Carreras模型在develop数据集上的对比 另外,虽然扩展模型理论上时间复杂度更高,作者在实验中发现,两个模型的运行效率基本相当,原因可能是解码过程中,每个节点的儿子节点数目比较少,因此使用所有孙子节点不会产生很大的时间消耗。 作者参加了CoNLL 2009评测,七种语言上均使用扩展模型,评测结果如表2所示。在这次评测中,作者在联合任务中总成绩排名第一,依存分析总成绩排名第三。表中还给出了本文的系统和前两名系统的性能比较。其中带*表示对应项在整个评测中为第一名。在跨领域语料上测试时,依存分析性能下降比较大(4%~10%),因此如何增强依存分析模型领域适应性是一个很有意义的研究点。 表2 CoNLL 2009评测依存分析依存关系准确率(LAS)比较) % 本文提出了一种基于柱搜索,融合高阶特征的依存分析方法。这种高阶依存模型使用所有的孙子节点构成祖孙特征,扩展了Carreras的只利用最左或者最右孙子节点的模型。实验证明这种扩展能够提高加泰罗尼亚语和西班牙语的性能,却会导致汉语、英语 (UAS)、捷克语 (UAS)性能下降,对其他语言则影响不大。另外,不同于以前的依存关系策略,本文以较小的时间复杂度为代价,使用了丰富的依存关系特征,并且允许模型在解码的过程中进行依存关系选择。作者参加了CoNLL 2009年多语语义依存分析国际评测,语义分析和句法分析联合任务总成绩第一名,依存分析总成绩第三名。 下一步工作包括:细致的特征选择和参数优化,从理论和实验上分析对比扩展模型和Carreras的模型。 [1] Michael A. Covington. A fundamental algorithm for dependency parsing [C]//Proceedings of the 39th Annual ACM Southeast Conference,2001. [2] Hiroyasu Yamada, Yuji Matsumoto. Statistical dependency analysis with support vector machines [C]//Proceedings of 8thInternational Workshop on Parsing Technologies. 2003:195-206. [3] Joakim Nivre, Mario Scholz. Deterministic Dependency Parsing of English Text [C]//Proceedings of COLING. 2004:64-70. [4] Jason Eisner. Bilexical grammars and a cubic-time probabilistic parser [C]//Proceedings of the International Workshop on Parsing Technologies, MIT. 1997: 54-65. [5] Ryan McDonald, Koby Crammer and Fernando Pereira. Online Large-Margin Training of Dependency Parsers [C]//Association for Computational Linguistics (ACL). 2005. [6] Ryan McDonald and Fernando Pereira. Online Learning of Approximate Dependency Parsing Algorithms [C]//European Association for Computational Linguistics (EACL). 2006. [7] Xavier Carreras. Experiments with a high-order projective dependency parser [C]//Proceedings of the CoNLL 2007 Shared Task Session of EMNLP-CoNLL. 2007:957-961. [8] Joakim Nivre and J. Nilsson. Pseudo-Projective Dependency Parsing [C]//Proc. of the 43rd Annual Meeting of the ACL. 2005: 99-106. [9] Wanxiang Che, Zhenghua Li, Yuxuan Hu, Yongqiang Li, Bing Qin, Ting Liu, Sheng Li. A Cascaded Syntactic and Semantic Dependency Parsing System [C]//CoNLL 2008: Proceedings of the 12th Conference on Computational Natural Language Learning, 2008: 238-242.4 实验
4.1 含有交叉弧语言的处理
4.2 特征集合
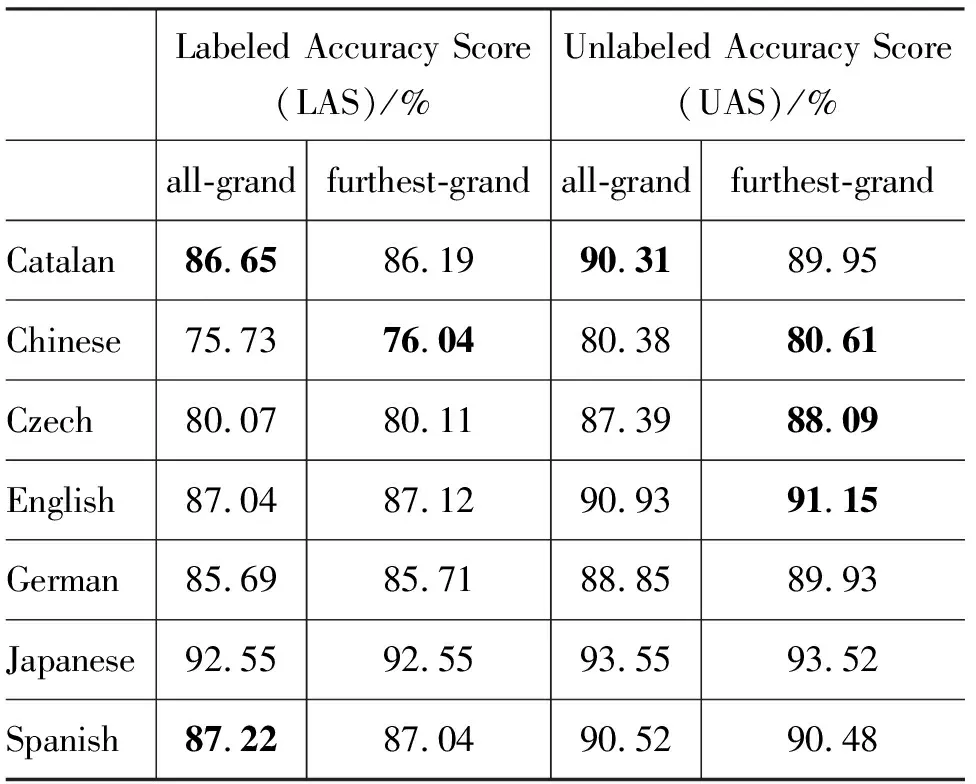
4.3 实验结果及分析

5 结论及下一步工作
