基于博主背景的博客倾向性检索归一化策略
2010-06-04廖祥文许洪波钟尚平
廖祥文,许洪波,钟尚平
(1. 福州大学 数学与计算机科学学院,福建 福州350108;2. 中国科学院 计算技术研究所,北京 100190)
1 引言
近年来,博客作为Web 2.0的典型应用之一,得到越来越多的关注。易用的博客工具软件、政治因素催化(比如,“9·11”事件爆发后许多人通过博客发布资讯、2008年奥巴马竞选美国总统为宣扬自己政见推出竞选博客)、媒体炒作(比如,娱乐人士在博客上自我炒作)等因素驱使博客规模迅猛增长,从而使得博客发展成一种重要的在线内容(Online Content)媒介。在博客上,人们可以发表新闻、分享日常生活经历、表达他们对感兴趣主题的情感、观点和看法等。与诸如网页、BBS等传统媒介不同,博客有着其自身特点[1]:
• 首先,每个博客通常由博主本人维护和更新。因而,博客是私有的,代表博主的兴趣、观点以及博主与他人的互动情况。
• 其次,博主经常更新、添加新的博文。所以,与不怎么更新的普通网站相比,它包含更多新内容,更新的频率也更高。
• 最后,与普通网页不同的是,博客以日记体形式存在,每篇博文都有确定的时间戳。
因此,博客是博主个人情感的表达和体现,其核心价值在于个性化情感表达与社会属性,从而使得博客的倾向性价值引起国内外学术界的广泛关注[2-4]。自2006年以来NIST连续举办了国际TREC 博客倾向性检索(Opinion Retrieval)评测比赛[2-3]。与传统的检索不同,博客倾向性检索的目标是检索出与给定查询既要主题相关又要包含查询相关评论的博文单元,并依据倾向性强度进行排序。它更侧重于挖掘博客空间中博主对特定查询所体现的意见和情感。从某种意义上说,倾向性检索是信息检索和倾向性分析技术的融合。
如何合理度量博主对特定查询的倾向性强弱是博客倾向检索的关键,也是其面临的最大挑战。国内外研究者已经做了比较深入的研究,主要有如下两类方法:第一类,对每个博文单元直接建立模型度量其对特定查询的评论程度;第二类,先度量博文单元与特定查询的主题相关性得到主题相关分数,然后在此基础上计算博文单元对博文的评论强弱得到倾向性分数,最后融合二者分数得到最终倾向性检索分数进行排序。这两类方法都是基于单个博文单元内容对特定查询进行倾向性评分。然而,因为博客是博主表达自己观点情感的媒介,所以博主的个性风格能够很大程度上影响着倾向性强度。例如,乐观的博主往往用褒义程度比较强的倾向词来赞美某一事件(比如,“很好、非常棒”等),而悲观的博主则往往用褒贬程度比较弱的倾向词(比如,“一般、还可以”)。因此,同样一个倾向词对于不同的博主所表达的倾向性强弱不一样,忽略博主因素,而仅仅使用单一的博文单元获取倾向性评分,会给倾向性评分带来较大偏差。为了解决该问题,我们首先分析博主背景因素对倾向性评分的影响并建立博主背景模型,然后提出一个基于博主背景的博客倾向性归一化策略,最后使用该策略对基于概率推理的博客倾向性检索算法进行归一化以验证该策略的有效性。实验结果表明,基于博主背景的倾向性检索归一化策略能够更加合理地对博文单元进行排序。
本文的组织方式如下:第2节介绍相关工作;第3节对博主背景建模;第4节介绍基于博主背景的博客倾向性归一化策略,并利用该策略对基于概率推理的博客倾向性检索算法进行归一化;第5节介绍实验方法及结果分析;最后一节得出本文的结论。
2 相关工作
倾向性(英文为“Opinion”或“Sentiment”,本文不做区分)检索指的是对某个特定查询所持有的意见、观点或评论。随着计算技术的发展,倾向性相关研究从2002年以来逐渐成为研究热点问题。国内外探讨与倾向相关的研究起源于倾向性判别,比如电影领域影评倾向性判别。它的目标是判定给定的文档对某特定查询是正面态度、负面态度还是中性。大多数的研究工作采用基于机器学习的方法判别文档对特定查询所持有的态度:它们主要从寻找表达倾向性的特征[5]、分析比较已有机器学习方法[6]和寻求新的机器学习方法[7]三个方面开展工作。然而,所有这些研究工作往往都基于这样一个前提:假设所有文档只与特定查询相关。但是一篇文档中,作者在不同的段落可能描述不同的主题,在不同段落中的倾向词作用范围也不尽相同,可能描述的主题与文章的主题一致,也可能是与主题不一致(比如,虽然文档存在大量的倾向词,但是并不描述特定查询)。因此在研究过程中,需要验证该假设是否成立,否则可能产生较大的偏差。为了减少这种偏差,越来越多的研究者转向研究倾向性检索。倾向性检索的目标是依据文档对特定查询的倾向性强弱对文档进行排序。排序靠前的文档不仅与特定查询主题相关,而且与对特定查询的评论强弱程度有关。由此可以看出,倾向性检索是信息检索和文本倾向性挖掘领域的交叉学科。它成为近年来众多研究者关注的热点问题之一。
近年来,国内外众多研究者依托博客这个巨大的倾向性知识库,开展倾向性相关研究,特别是博客倾向性检索。自2006年以来NIST组织的国际文本评测比赛连续三年举办了博客倾向性检索(Blog Opinion Retrieval)评测比赛。该评测侧重于挖掘博客空间中博主对特定主题所体现的意见和情感。国内中科院计算所、中科院自动化所和复旦大学联合举办的第一届中文倾向性分析评测(COAE2008)中也设置了倾向性检索任务。与传统的检索不同,博客倾向性检索的目标是检索出与给定查询既要主题相关又要具有倾向性的博文单元(包含博文和评论两部分)[2]。从某种意义上说,倾向性检索是信息检索和倾向性分析技术的融合。目前国内外博客倾向性检索的研究主要分为如下两大类。第一类,对每个博文单元直接建立模型度量其对特定查询的评论程度。M. Hurst 等人[8]首次同时综合考虑了主题因素和倾向性因素,用于寻找与给定主题相关的倾向性。K. Eguchi 等人[9]给出了一个统计语言模型检索框架,并提出一个评分公式试图对倾向性强弱进行度量,但是在TREC评测上的结果并不尽如人意。Min Zhang等人[10]提出了一种基于词典的产生式模型(Generation Model)倾向性检索模型,从一定程度上为分析倾向性检索提供理论工具。廖祥文等人[11]把概率推理模型应用于博客倾向性检索中,提出一个基于概率推理模型的博客倾向性检索算法,有效地提高倾向性检索效果。第二类,先度量博文单元与特定查询的主题相关性得到主题相关分数,然后在此基础上计算博文单元对博文的评论强弱得到倾向性分数,最后融合二者分数得到最终倾向性检索分数进行排序。这类算法取得比较好的结果,因而TREC2006和TREC2007的大部分参与评测队伍都采用这类方法。关于主题相关检索,参加TREC评测的队伍[2-3]往往采用他们认为能取得比较好检索结果的经典检索方法,而把精力更多地关注倾向性评分,典型的如Okapi BM25检索算法和语言模型算法。在检出与特定查询主题相关的博文单元后,需要对博文单元进行倾向性评分,目前主要有如下三类评分方法[2-3,12-16]:(1)基于倾向性词典方法。D. Hannah等人[12]收集各种可以获取的倾向词资源构建倾向词典,通过Divergence from Randomness (DFR) 模型进行倾向性评分,获得了达到15.87%的性能提升。Kiduk Yang 等人[13]首先用半自动化方法构建倾向词典,更细粒度地区分出高频词、低频词对文档进行倾向性评分,最后用加权和方法进行融合得到最后倾向性评分。因此,对于这类方法来说,倾向词典的质量对倾向性评分起着至关重要的作用,能够准确反映数据集倾向词分布与区分规律的倾向性词典对性能的提升非常明显。(2)基于距离的评分方法:通过计算查询词与倾向性词的距离对文档进行倾向性评分。GuangXu Zhou 等人[14]计算查询词与特殊词(如“I”, “you”, “me”, “us”, “we”等等)、查询词与倾向词的距离对文档倾向性评分,获得达到13.98%的性能提升;这种方法虽然有效,但是存在着不确定因素,泛化能力比较差,对于其他的语言可能不适用。(3)基于统计机器学习的评分方法:Liao Xiang-wen 等人[15]基于推拉策略的分类方法用Trec2006的答案集进行训练倾向性分类器对文档进行倾向性评分。Wei Zhang等人[16]针对每个主题,通过在rateitall.com、wikipedia.org和www.google.com收集的观点句子集和客观句子集训练支持向量机(SVM)分类器识别其中的观点句子进行倾向性评分。该方法连续在TREC2006和TREC2007取得第一名的成绩。但它不仅需要对每个查询主题训练分类器,而且还需要针对每个不同的主题访问外部资源建立训练集进行训练。可以看出,本类方法的关键在于如何构建训练集训练机器学习的模型,但是由于查询主题往往属于不同的领域,对它们的评论所采用的倾向性用语往往不一样,而目前又没有现成通用的训练集,需要针对每个主题收集不同的训练集,往往需要加入手工手段,付出的代价比较大,效率比较低。在获得倾向性评分和主题相关性评分后,需要对二者进行融合得到最后的倾向性检索评分。目前大多数的做法[2-3]是通过线性组合方式进行融合。这种方法虽然简单有效,但是缺乏详细分析和理论依据。因此Min Zhang等人[10]提出了一种基于词典的产生式模型(Generation Model)新组合方法,从一定程度上,为分析倾向性检索提供理论分析工具,廖祥文等人[11]引入了概率推理模型,提出一种直接度量博文对特定查询倾向性强弱的方法。
博客是博主表达自己观点情感的媒介,博主的语言习惯、个性风格能够很大程度上影响着倾向性强度。例如,发文频率、博主语言风格等。然而,目前所有这些研究都是基于单个博文单元的文本内容对特定查询进行倾向性评分,而没有以博客站点为研究对象分析博主的语言风格、行为习惯等博主个人背景因素对倾向性评分的影响。同样一个倾向词对于不同的博主所表达的倾向性强弱不一样,不能忽略博主因素,而仅仅使用单一的博文单元获取倾向性评分,否则会带来倾向性评分的较大偏差。为了解决该问题,本文主要开展如下三个方面工作:首先分析博主背景因素对倾向性评分的影响并建立博主背景模型,然后提出一个基于博主背景的博客倾向性归一化策略,最后为了验证该策略的有效性,使用该策略对基于概率推理的博客倾向性检索算法进行归一化。
3 博主背景对倾向性评分的影响以及博主背景模型
博客是博主真实观点和情感表达的载体,不同的博主表达相同观点的形式和风格各不相同。仅仅依据单个博文单元进行倾向性评分,忽视了不同博客的社会属性,即每个博客往往是博主行为风格的体现,容易造成倾向性评分的偏差。我们通过分析博主的背景因素对倾向性评分进行修正,把社会属性体现到倾向性计算环节中,从而可以更加合理地对博文单元进行评分。
3.1 博主背景对倾向性评分的影响
目前体现博主行为风格的背景因素主要包括:博文数目、发文频率、博文被引用状况、同一主题的博文数目、博主书写博文的倾向性用语风格等等。具体分析如下:
• 博文数目、发文频率。当博主所写的博文数目比较多,发文比较频繁,那么该博主是个比较外向、乐于与人分享的人,所写的博文也比较完整、可信,在进行统计分析时,有助于消除偏差。
• 博文被引用状况。可以通过引用通告获得博文的被引用状况,被引用的次数越多,博文越受欢迎,它的质量往往也比较高,因此该博文单元对主题的倾向性评分也应该获得更高的权值。
• 博主与读者的互动情况。博主可以通过博文正文下面的评论栏回复评论与读者进行互动。当评论数目越多,说明该篇博文受关注度越高,博主所表达的观点较为完整、可信,人们对它所阐述的观点越感兴趣,因此该篇博文单元对给定主题的倾向性评分也较为可信。
• 博主书写博文的倾向性用语风格。博文单元是博主情感的表达,不同的博主对同一种观点的表达形式、用语风格不尽相同,有些博主往往用比较夸张的、褒贬义强度比较强的倾向词,而另一类博主则可能用比较温和的、褒贬义强度比较弱的倾向词。因此对于单篇博文的评分,相同的倾向性评分所代表的不同博主的情感是不一样的。比如,有些博主习惯于使用倾向性强度非常强的词(用“非常、十分”等副词修饰),在他们的博文中如果采用倾向性强度强的词如“愤怒”等表达对某个主题的批评,可能是一种比较委婉的批评,而并不是非常严厉的批评;同样是对上述主题的批评,另外一些比较温和的博主,如果使用了“愤怒”之类的倾向性词,则代表非常严厉的批评。因此,仅仅依据单篇博文的评分不能真正体现博主观点的倾向性强弱,会带来偏差。
基于以上分析,有必要对体现博主行为风格的背景因素建模,把背景因素引入到博客倾向性检索中,对倾向性评分进行修正,从而更加合理地进行倾向性评分。
在本文中,为了验证博主背景因素对倾向评分的影响,我们主要考虑博主书写博文的倾向性用语风格因素对倾向性评分的影响:对博主的所有博文分析,得到其倾向性用语风格数学模型,并利用该模型对与主题相关的倾向性评分进行归一化,从而达到修正倾向性评分的目的。
3.2 博主背景模型
对博主书写博文的倾向性用语风格因素的具体建模过程如下:
假设博主发表的所有博文的倾向性评分符合正态分布:X~N(μ,σ),则有:
χi
(1)

(2)
其中,δi是博主所有博文单元倾向性评分的方差,反映博主书写博文单元风格的稳定性。
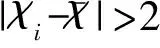
χj
(3)
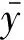
(4)
上式中,δo为粗差剔除后的方差。此时,δi≠δo。
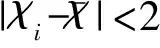
δo=δi
(5)

根据式(1)~(7)可得:第10个考核期Cpv为3.976万元,Cav为4.704万元,Ev为3.96万元,Vs为-0.016万元,Vc为-0.744万元,Is为1.034,Ic为0.842。由计算结果可知:该项目在第10个考核期实际安全成本投入处于超支状态,实际安全保障水却没有达到计划水平,可以排除是由于安全成本节约导致了安全度的降低,很明显是由于管理措施不到位而造成的,项目经理部应结合专家对当月安全评价体系的评分情况和项目实际安全投入情况进行深入分析,找出原因,加强安全管理力度的同时严格控制安全成本的支出,保证项目施工安全顺利开展。
4 基于博主背景的博客倾向性归一化策略
在对博主的倾向性用语风格进行建模后,我们用该模型对主题相关博文单元的倾向性评分进行归一化修正。在归一化之前,首先定义如下两种博主类型:
• 如果博主撰写博文所用倾向词的褒贬程度比较激烈,则该博主属于激进型博主;
• 如果博主撰写博文所用倾向词的褒贬程度比较温和,则该博主属于保守型博主。
假设博主A和博主B都发表了与某一主题相关的博文。假设博主A为激进型博主,那么他所写博文往往都用褒贬义程度比较强的词(比如“非常喜欢”、“愤怒”等等),从而一定程度上放大了对博文主题的倾向性评论强度;假设博主B为保守型博主,那么他所写博文往往都用褒贬义程度比较弱的词(比如“还行”、“一般”等等),从而一定程度上弱化了对博文主题的倾向性评论强度。因此,我们给出如下归一化策略:
• 博主背景在一定程度上影响倾向性得分,可以根据“博主背景模型”(即,N(μ,σ)),对倾向性得分进行归一化;
• 风格稳定博主的单个博文单元的倾向性得分,其方差σ较小,较为可信;而风格不稳定博主的方差σ较大,较为不可信;
• 激进型博主的倾向性得分往往偏高,保守型博主倾向性得分往往偏低,因此可采用“博主背景模型”中的平均值μ对其倾向性分数进行平滑。
5 归一化的博客倾向性检索算法
我们采用基于概率推理模型的倾向性检索算法(PRIB算法)[11]进行博客倾向性检索:对于给定的查询主题Q和文档d,PRIB算法的倾向性评分如下:
(6)
其中,c是所有文档的集合,s为倾向词典。上式的后一项是计算博文单元对特定查询主题的倾向性强弱程度,记为ORprib,则(6)可改写为:
Rank=Rank(1+ORprib)
(7)
根据前一节的归一化策略,倾向性评分可以归一化为:
(8)
6 实验及相关分析
我们采用TREC2006 Blog Opinion Retrieval track提供的数据集和20个查询主题(851~870),对归一化的博客倾向性检索算法(Normalized Probabilistic Inference Based Method,NPRIB)进行测试,实验结果如表1所示。图1是归一化的博客倾向性检索算法在查询851~870上的性能提升分布情况。图2是归一化的博客倾向性检索算法在查询851~870上的Recall-Precision曲线图。
从表1可以看出,相对于Baseline语言模型(Language Model,LM),NPRIB的检索性能有明显的提升,但略低于PRIB的检索性能。我们认为,可能的原因主要有如下三方面:
• TREC提供的评判答案并没有考虑博主背景因素,此时基于博主背景的NPRIB归一化算法对于倾向性评分的修正不能显示出优势。
• 由于NPRIB算法对单个博客单元的倾向性评分进行平滑,带来了与评判答案的偏差,导致了性能的下降。
• 此外,TREC的评判机制中,对所有答案平等对待,而基于博主背景的归一化方法优势在于检索结果排序的精细化调整,对细化的评判标准(如NDCG)更为有效。

表1 归一化的博客倾向性检索算法在TREC2006查询主题上的检索性能
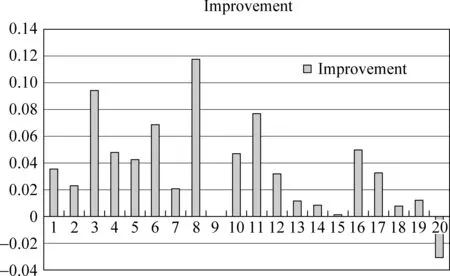
图1 归一化的博客倾向性检索算法在查询851~870上的性能提升分布

图2 归一化的博客倾向性检索算法在TREC2006查询主题上的Recall-Precision曲线
7 结论
博主的行为风格背景因素(如博文数目、发文频率、博文被引用状况、同一主题的博文数目、博主书写博文的倾向性用语风格等)很大程度上影响着博客的倾向性评分。仅仅考虑单个博文单元对某个主题进行倾向性评分往往会带来偏差,因此我们考虑利用博主的语言风格因素对倾向性评分进行修正,对博主的倾向性用语风格建立数学模型,提出基于博主背景的倾向性归一化策略,把博主风格因素引入到博客倾向性检索算法中,从而更加合理地度量博文单元对查询主题的倾向性强弱程度。为了验证该策略,利用所提出模型对基于概率推理的博客倾向性检索算法中的倾向性评分进行归一化修正,从实验的角度验证了倾向性用语风格对博客倾向性检索算法性能的影响。实验结果表明,基于博主背景的倾向性检索归一化策略能够更加合理地对博主单元进行排序。
[1] Arun Qamra, Belle Tseng and Edward Y. Chang. Mining Blog Stories Using CommunityBased and Temporal Clustering[C] // Proc. ofCIKM’06. Arlington, Virginia, USA: ACM 2006.
[2] Ounis Iadh, de Rijke Maarten, et al. Overview of the TREC-2006 Blog Track[C/OL] //Proc. of the Fifteenth Text REtrieval Conference (TREC 2006). Gaithersburg, Maryland, USA: NIST 2006. [2007-01-23], http://trec.nist.gov/pubs/trec15/papers/BLOG06.OVERVIEW.pdf
[3] Craig Macdonald, Iadh Ounis , Ian.Soboroff Overview of the TREC-2007 Blog Track[C/OL] // Proc. of The Sixteenth Text REtrieval (TREC 2007). Gaithersburg, Maryland, USA: NIST 2007. [2007-12-12], http://trec.nist.gov/pubs/trec16/papers/BLOG.OVERVIEW16.pdf
[4] 杨宇航, 赵铁军, 于浩, 郑德权. Blog研究[J]. 软件学报, 2008, 19(4): 912-924.
[5] Turney P. Thumbs up or Thumbs down? Semantic orientation applied to unsupervised classification of reviews[C] // Proc. of ACL’02. Philadelphia, PA, USA: Association for Computational Linguistics, 2002: 417-424.
[6] Pang B, Lee L and Vaithyanathan S. Thumbs up? Sentiment Classification Using Machine Learning Techniques[C] // Proc. of ACL’02. Philadelphia, PA, USA: Association for Computational Linguistics, 2002: 79-86.
[7] Pang Bo, Lee Lillian. A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts[C] // Proc. of ACL’04. Barcelona, Spain: Association for Computational Linguistics, 2004: 1030-1035.
[8] M. Hurst and K. Nigam. Retrieving Topical Sentiments from Online Document Collections [C]// Document Recognition and Retrieval XI, 2004: 27-34.
[9] K. Eguchi, V. Lavrenko. Sentiment Retrieval using Generative Models [C]// Proceedings of Empirical Methods on Natural Language Processing (EMNLP), 2006: 345-354.
[10] Min Zhang, Xingyao Ye. A Generation Model to Unify Topic Relevance and Lexicon-based Sentiment for Opinion Retrieval [C]// the Proceedings of SIGIR’08, Singapore, July 20-24, 2008.
[11] 廖祥文, 曹冬林, 方滨兴,许洪波, 程学旗. 基于概率推理模型的博客倾向性检索研究[J]. 计算机研究与发展, 2009, 46(9):1530-1537.
[12] D. Hannah, C. Macdonald, et al. University of Glasgow at TREC 2007: Experiments in Blog and Enterprise Tracks with Terrier [C]// Proceedings of 15thTREC, 2007.
[13] Kiduk Yang, Ning Yu, Hui Zhang. WIDIT in TREC-2007 Blog Track: Combining Lexicon-based Methods to Detect Opinionated Blogs [C]// Proceedings of TREC’07, 2007.
[14] GuangXu Zhou, Hemant Joshi, Coskun Bayrak. Topic Categorization for Relevancy and Opinion Detection [C]// Proceedings of TREC’07, 2007.
[15] Liao Xiangwen, Cao Donglin, Wang Yu,et al. Experiments in TREC 2007 Blog Opinion Task at CAS-ICT[C/OL] // Proc of The Sixteenth Text REtrieval (TREC 2007). Gaithersburg, Maryland, USA: NIST 2007. [2007-12-12],http://trec.nist.gov/pubs/trec16/papers/cas-ict.blog.final.pdf.
[16] Wei Zhang, Clement Yu, Weiyi Meng. Opinion Retrieval from Blogs [C]// Proceedings of the sixteenth ACM conference on Conference on information and knowledge management, Lisbon, Portugal, 2007:831-840.
