基于混合语言信息的词语搭配倾向判别方法
2010-06-04王素格杨安娜
王素格,杨安娜
(1. 山西大学 数学科学学院, 山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室, 山西 太原 030006)
1 引言
有些词具有明显的语义倾向,如“优秀、聪明、漂亮、狡猾、妖艳、顽固”等,有些词语尽管其本身是中性的,但在具体的语言环境中通过与带有情感倾向或中性的其他词语组合搭配,即可表现出强烈的情感倾向。比如,在汽车评论文本中,有些中性形容词(如“大、小、高、低、松、紧”等)与一些带有情感倾向的词语组合后便具有倾向性,如“噪声大/小、缺点(损失)大/小、乐趣大/小、优势大/小”等,与某些中性词组合也可产生情感倾向,如“水平高/低、标准高/低、配置高/低”等。然而,在词语级语言粒度下,这些具有情感倾向的词语组合得不到充分挖掘与表征,获得这种比词汇粒度更大的具有情感倾向的词语搭配是进行句子的情感分类和观点挖掘的前提[1-5]。
搭配被认为是一种具有任意性、重复出现的词语组合[6-7]。根据这个一般性搭配的定义,有些学者针对搭配的识别与获取已做了相关研究工作[8-9]。随着文本倾向性分析研究的深入,不仅需要获取词语搭配,更重要是判别其情感倾向。文献[2]采用情感特征分析方法,提出了基于词汇特征、修饰特征、句子特征以及文档特征的短语极性判别方法。文献[3]提出了统一搭配框架(UCF)的搭配获取和搭配驱动(UCD)方法,但对于搭配倾向性判别仍采用了规则的方法。文献[1]采用文献[8]中一般性的搭配方法获取了搭配,但并没有考虑具有情感倾向性的词语搭配的特点,而文献[5]在一般词汇特征的基础上,加入了否定短语,用于文本的情感分类。文献[3,5]采用基于规则的方法,但仅考虑了搭配中词汇的静态情感倾向信息,并没有对搭配词的语义信息给出充分利用。文献[6]采用概率潜在语义模型对“n+a”模式的短语情感倾向判别进行了研究,并没有对潜在语义块的确定以及其他搭配模式的情感倾向判别给出更深入的研究。由于概率潜在语义模型属于概率统计方法,当样本包含较少的搭配时,会出现数据稀疏问题,为了解决这个问题,本文增加了词汇的静态信息,以提高系统的性能。
在文献[4]中,我们考察了十种模式的词语搭配,研究发现有一些副词可以加强或者减弱它所修饰词的倾向程度,也有一些副词可以用于改变它所修饰词的倾向,因此,对于“cd+a”、“cd+v”、“fd+a”和“fd+v”这四种模式的搭配的正反两类情感倾向的判别仅仅采用规则的方法便可以得到相当高的F值[4]。对于“v+n”、“v+v”、“a+n”、“n+a”、“a+v”和“a+a”六种模式的情感倾向,仅仅使用规则判断其倾向有一定的局限性,因为词语搭配的倾向并不总是组成词语倾向的简单相加,尤其对于搭配中不含情感倾向性词语的搭配时,例如,“空间大”、“标准高”和“安全性高”等。虽然在文献[4]中采用了一些个性规则进行判断,但个性规则建立比较耗时,因此,本文重点研究“v+n”、“v+v”、“a+n”、“n+a”、“a+v”和“a+a”六种模式的情感倾向。首先构建六种模式的概率潜在语义模型,通过搭配的特点,确定各模式潜在语义块聚类的词语,并确定出各模式潜在语义块的大小。然后根据问题构造出似然函数,采用EM算法估计各模式对应模型中的参数值,最后,通过确定的参数值判断各模式对应搭配的情感倾向。为了解决数据稀疏带来的性能下降,利用搭配词语的静态信息,构造搭配情感倾向判别规则,将其作为概率潜在语义模型判别搭配情感标注倾向的修正。
2 基于混合语言信息的词语搭配倾向判别
本文主要对搭配的正面、中立和反面三类情感倾向判别方法进行研究,这三类分别记为1、0、-1。
2.1 基于概率潜在语义的词语搭配倾向判别模型
概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)[10-12]是由Hoffmann提出了一种新的分析文档的潜在语义模型,它是一种基于生成概率的模型,不同于潜在语义分析(SVD)是一种满足最小方差原则的方法(映射前后能保持原向量和投影向量之间的方差最小),而是遵循最大可能性的原则,其核心叫做Aspect Model的统计模型。
根据文献[6]的讨论,图1中模型(a)为原始的概率潜在语义模型,由于缺少语义倾向变量,因此不能用于搭配的倾向判别。模型(b)可显示出具有统计基础的潜在语义模型,X、Y分别表示词类1、词类2的词语集合,Z为词类1中词语集合的潜在语义块,C为X和Y构成搭配的倾向集。通过概率p(C|YZ)直接影响到搭配(x,y)的语义倾向,在这个模型中只有词语x被聚类。当两个词语构成搭配时,有时虽然它们词形不同,但构成搭配的语义倾向有时会表现出相同的倾向,例如,“动力差、内饰差、性能差”等。为了判断搭配的语义倾向可以采用(b)图模型,此时将y看成目标词“差”,x看成搭配词“动力、内饰、性能”。

图1 模型表示
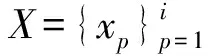
算法思想:在E步中按照当前矩阵U和矩阵Vl的值,用式(1)计算每一个三元组(x,y,c)在产生潜在语义块zk的条件下的先验概率;在M步中使用式(2)和式(3)分别对矩阵U和矩阵Vl中的概率值进行重新估计,交替进行E步和M步,直至收敛为止。具体如下:
E步骤:对每一个三元组(x,y,c),计算产生潜在语义z条件下的先验概率:
(1)
M步骤:使用式(2)和式(3)对模型中的p(c|yz)和p(z|x)重新估计。
(2)
(3)
经E步和M步迭代,当似然函数E[θ]的增加量小于一个阈值θ时停止迭代,此时得到一个最优解。
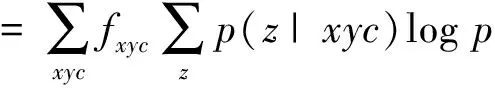
(4)
其中,fxyc表示的是数据集中三元组(x,y,c)的频率。
搭配(x,y)的语义情感倾向判定: 通过E步和M步得到式(5),再利用式(6)可以得到搭配(x,y)相对于语义倾向为C的概率值。最后,利用式(7)得到搭配(x,y)的情感倾向O(x,y)的判别。
(5)

(6)

(7)
2.2 基于混合语言信息的词语搭配倾向性判别
概率潜在语义模型的本质是统计方法,但统计方法本身有其不足,会掩盖小概率事件的发生。当搭配词语中含有明确的语义情感倾向词时,可以使用规则的方法作为统计方法的补充。由文献[4]可知,具有情感词语搭配的构成有两种情况,一是搭配中不包含任何情感词语,二是至少包含一个情感词语。当搭配中的词语仅有一个情感词语或两个具有相同语义情感倾向的词语时,利用于规则方法进行搭配情感倾向判别,其测试的可信度可达94%以上[4]。因此,本文构造出如下规则并给出其可信度CF(Ri)(i=1,2,3,4):
这里,x,y分别表示左右搭配词,Fwords为否定词集,O(x),O(y),RO(x,y)分别为左搭配词、右搭配词以及搭配(x,y)的情感倾向。对于给定搭配,按照公式(8)进行判别。

(8)
这里的Ωi为满足规则Ri的搭配集合。
由于规则具有较高的可信度,本文将基于规则(静态信息)作为概率潜在语义模型判别搭配情感倾向的修正。混合语言信息的情感倾向判别公式见公式(9)。
O(x,y)=sgn(α·PO(x,y)+β·RO(x,y))
α+β=1
(9)
当α=1,β=0时,搭配(x,y)的情感倾向仅由概率潜在语义模型判断,当α=0,β=1时,搭配(x,y)的情感倾向仅由规则方法进行判断。
3 概率潜在语义块的确定
3.1 数据集建立及评价指标
设X,Y分别为词语搭配中左右词语集合。Z={
3.2 潜在语义块的确定
根据第2节公式(7),需要确定U-型模型的潜在语义块,即确定搭配模式中词类对应的语义块。由于篇幅所限,我们仅探讨了“a+n”和“a+a”两种模式。两种模式得到聚类倾向性判别结果见表1。

表1 采用不同聚类词集的语义块得到搭配倾向判别的F值
由表1可知,对名词集N聚类出的语义块得到的搭配情感倾向各指标均优于采用形容词集A聚类的结果;对形容词集A1聚类出的语义块反面F值和宏平均均优于形容词集A2聚类的结果。说明词集基数较多的词类,成为聚类的对象得到搭配的倾向判别结果较好。
对上述模式的搭配词语倾向判别结果发现:(1)在模式“a+n”中,一个形容词可以修饰许多名词,如:“大”就可以修饰名词“空间、功率、市场、噪声、噪音、风噪、胎噪”等等,而“大”和“空间、功率、市场”搭配是褒义的,和“噪声、噪音、风噪、胎噪”是贬义的,这样便把“空间、功率、市场”归为一类,“噪声、噪音、风噪、胎噪”为另一类。(2)在模式“a+a”中,虽然具有相同的词类,但由于修饰关系不同,得到的搭配倾向判别结果的也不同。
根据上述分析,本文采用以下策略进行聚类潜在语义块:
设R为聚类语义块的词语集合,若card(X)≥card(Y),则R=X,否则R=Y。
利用上述策略得到六种模式的模型如下:

图2 六种搭配模式的U-型模型图
3.3 潜在语义块个数的确定及其聚类结果
由3.2节可知,对于聚类潜在语义块的选取与搭配中词语集的基数有关,而语义块数K的多少会直接影响系统性能与计算的复杂度。若K较大时,接近标准模型,将会减弱词语间的相关性;若K较小时,会导致一些重要信息丢失。因此,并非语义块数越多越好。我们对各种模式进行了实验测试,得到最佳搭配倾向判别结果的K值,见表2。

表2 六种搭配模式的K值
概率潜在语义模型的作用是能聚类出词语隐藏的语义信息,根据图2各个模式的模型以及表2的K值,得到词语在数据集中出现次数不小于2,并且按照序列p(z|x)排在前20位的部分聚类语义块结果,见表3。

表3 不同模式下的聚类语义块例子
表3所示的词语聚类语义块,较符合人们的认知,例如,模式“a+n”中的名词聚类块C1与形容词“大”搭配倾向为贬义的后验概率为p(贬义|大,C1)=0.997 5,而模式“v+n”中的名词聚类块C1与动词“解决”搭配倾向为褒义的后验概率为p(褒义|解决,C1)=0.999 8。因此,通过词语聚类,可以获得更多搭配的情感倾向。
4 实验结果与分析
为了验证基于潜在语义模型、规则方法和混合语言信息的词语搭配情感倾向判别,本节采用公式(9),以及第三节介绍的语义块的确定结果,进行了如下三个实验。
实验1:基于概率潜在语义模型的词语搭配倾向判断,即α=1,β=0。
实验2:基于规则的词语搭配倾向判断,即α=0,β=1。
实验3:基于混合语言信息的词语搭配倾向判别,即0≤α<β≤1。
上述三个实验的结果见表4。
由表4可知:
(1) 对于模式“a+n”、“n+a”,采用概率潜在语义模型的各项指标普遍高于规则方法,说明这两类模式的聚类效果比较好。而模式“v+n”采用规则方法的各项指标普遍高于概率潜在语义模型方法,说明该模式构成的搭配满足本文构造的规则较多。
(2) 对于模式“v+v”、“a+v”,采用规则方法的正面、中性的F值普遍高于概率潜在语义模型方法,而反面的F值则相反,说明满足规则的两类模式的正面、中性搭配较多,而满足反面搭配的规则较少。
(3) 对于所有模式,混合语言信息的词语搭配的各项指标普遍高于其他两种方法,说明该方法采用规则的方法去修正了概率潜在语义模型的判别的搭配种包含具有情感倾向词语的结果。例如,“意外事故、噪音高”原为褒义,修正为贬义,“毛病多、存在毛病、产生怀疑”原为中性,修正为贬义,“带来精神、没事故、表示满意”原为中性,修正为褒义。
(4) 对于模式“a+a”,由于符合该模式的搭配较少,规则作为概率潜在语义模型修正的结果不太稳定,导致其性能不太理想。
(5) 在混合的语言信息的词语搭配的倾向判别方法中,有些词语搭配,如“保养里程、保养费用、碰撞标准、碰撞程度、碰撞数据、碰撞测试、销售服务、售后服务、投诉中心、投诉结果”等等本身是中性,却被混合的语言信息方法判别为具有情感倾向的词语搭配,而这些搭配本身应为一个事件或被评价的对象,不具有倾向性。

表4 词语搭配倾向性判别F值
5 结束语
本文在已抽取的“a+n”、“n+a”、“a+v”、“a+a”、“v+v”和“v+n”六种模式的词语搭配基础上,研究了其情感倾向分类。针对这六种模式的词语搭配,提出了混合语言信息的词语搭配情感倾向判别方法,并与基于概率潜在语义模型和基于规则的判断词语搭配情感倾向方法进行了比较分析,实验结果表明前者优于后者。但混合语言信息的词语搭配的情感倾向判别方法主要是采用了规则修正概率潜在语义模型的判别结果,因此,有时会产生修正错误,而错误的部分原因是将一些事件或评价对象仍按词语搭配进行了倾向性判别,若能事先将些搭配识别为对象或者事件,可以避免此类问题的发生。另外,本文仅仅考虑了两个词语间搭配的情感倾向判别,对于多个词语间的搭配的情感倾向判别应是下一步研究的重点。
致谢:感谢哈尔滨工业大学信息检索研究室提供的“语言技术平台LTP”中的《同义词词林扩展版》;感谢董振东先生提供的HowNet的情感词汇和评价词汇。
[1] Faye Baron and Graeme Hirst. Collocations as Cues to Semantic Orientation [C]// Poceedings of the AAAI Spring Symposium on Exploring Attitude and Affect in Text. Theories and Application. 2004. http//citeseer.ist.psu.edu/683844.html.
[2] T.Wilson, J.Wiebe, and P.Hoffmann. Recognizing Contextual Polarity in Phrase-level Sentiment Analysis [C]// Proceeding of the HLT/EMNLP, 2005.
[3] Xia Yunqing, Xu Ruifeng, Wong Kamfai, et al. The Unified Collocation Framework for Opinion Mining [C]//Proceeding of the Sixth International Conference on Machine Learning and Cybernetics, Hong Kong, 2007: 844-850.
[4] 王素格. 基于Web的评论文本的情感分类问题研究[D].上海:上海大学2008年度博士学位论文
[5] Na Jin Cheon, Khoo Christopher, Wu Paul Horng Jyh. Use of Negation Pphrases in Automatic Sentiment Classification of Product Reviews[J]. Library Collections, Acquisitions &Technical Services, 2005, 29:180-191.
[6] Hiroya Takamura, Takashi Inui. Latent Variable Models for Semantic Orientations of Phrases[C]//Proceedings of the 11thConference of the European Chapter of the Association for Computational Linguistics. Trento, Italy,2006:201-208.
[7] Benson Morton. The Structure of the Collocation Dictionary[J]. International Journal of Lexicography, 1989,2: 1-14.
[8] F. Smadja. Retrieving Collocations from Text: Xtract[J]. Computational Linguistics, 1993, 19(1): 143-177.
[9] 王素格, 杨军玲, 张武. 自动获取汉语词语搭配[J].中文信息学报,2006; 20(6): 31-37.
[10] T.Hofmann. Probabilistic Latent Semantic Indexing[C] //Poceedings of the 22nd International Conference on Research and Development in Information Retrieval. Berkeley, California: [s. n.], 1999: 50-57.
[11] T.Hofmann. Probabilistic Latent Semantic Analysis[C]//Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence. Stockholm: [s. n.], 1999: 289-296.
[12] T.Hofmann. Unsupervised Learning by Probabilistic Latent Semantic Analysis[J]. Machine Learning, 2001, 42(1): 177-196.
