数据挖掘技术在健康管理系统中的应用
2010-05-05李娜翁惠玉
李娜,翁惠玉
0 引言
随着社会进步和科学发展,人口老龄化及生活水平的提高,人们越来越关注自身的健康状况。健康管理的概念最早起源于美国。1929年美国洛杉矶水利局成立了世界上第一个健康管理组织(Health Management Organization,HMO),该组织通过注重预防的全面健康管理的方式,有效降低会员疾病发病率,提高人们的健康水平。健康管理系统中积累大量的数据资料,如何从海量的数据中提取隐含在其中的事先未知的、潜在的、深层次、有价值的信息,辅助专家或群众个体进行诊断决策,是健康管理系统必须考虑的问题,而这正是数据挖掘的长处。
本文主要针对中老年慢性病的管理的需求,以糖尿病为例,采集居民的健康档案信息指标,利用决策树方法生成对当前数据有效的模型,并对模型进行分析,筛选高危人群,提高糖尿病的早期发现率,使人们不断提高对健康的认识程度,疾病要以预防为主,减少身体及经济上的负担。
1 健康管理中数据挖掘技术的应用
健康管理系统是对个人或人群的健康危险因素进行全面检测、分析、评估以及预测和预防的全过程的系统。它一般由以下几部分组成:基本信息管理(含基本项管理)、体检项目管理(含健康评估、健康报告、健康指导)、个人(企业)健康档案数据采集、信息查询、综合数据分析和系统管理。健康管理系统的总体结构如图1所示:
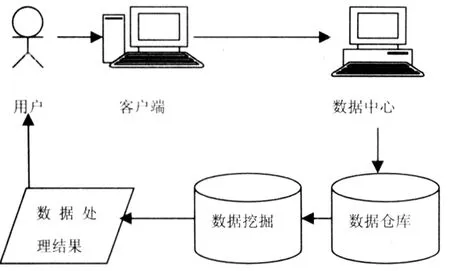
图1 健康管理系统中数据挖掘的应用
在这个系统中,输入用户(病人)的各项生理参数,诸如身高,体重,心电,血压,血氧,体温等,这些参数将与用户的个人信息,社区信息一起被存档,作为个人的病史记录。针对以上的记录,数据挖掘可以应用在以下两个方面:一是用户根据个人的生理参数,寻求合适的保健方法或治疗方法。另外一方面是相关科技工作者,社区医疗组织,计生人员主动到系统上去搜寻必要的信息,然后根据用户的病症,治疗过程以及治疗结果挖掘出更有效的治疗方法等。比如社区医务人员可以通过系统查看本辖区的慢性病表征情况,筛选出慢性病的高危人群,挖掘出引起慢性病的主要因素,提醒居民对健康情况引起注意。
2 基于决策树的数据挖掘
2.1 决策树ID3算法
ID3算法[1]是由Quinlan提出的一种基于信息增益的典型的自上而下决策树归纳算法,主要特征是在一个结点上使用最大的信息增益量,作为启发式来决定应用选择哪一个属性来进行树的展开。
ID3算法的基本原理如下:
已知训练例子集E,设训练例子集E中含有p个正例和n个反例,则一个例子属于正例集PE的概率为P/P+n,属性于反例集NE的概率为n/P+n,一棵决策树可以看作正、反例集的消息源,所需要的信息熵为:
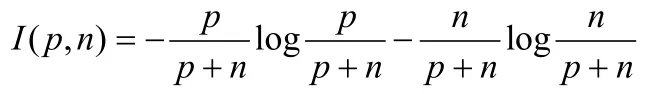
设属性A取V个不同的值,它们将E划分为V个子集,假设Ei中含有Pi个正例和ni个反例,那么子集Ei所需要的期望信息是,I(pi,ni),并且以A为根的树所需要的期望信息为各子集所需要的期望信息的加权平均值,即,以A为根的信息增益是:Gain(A)=I(p,n)-E(A)
ID3算法选择Gain(A)最大的属性A'作为根结点,对A'的不同取值对应的E的V个子集Ei递归调用上述过程生成的A'子结点B1,B2,…Bv。
健康管理系统的档案数据记录庞大,对应的属性值较多,ID3算法是基于所有属性值都确定的情况下分类的,而实际应用中经常出现有些记录的属性值缺失或空白的情况,ID3算法就直接放弃数据库中所有丢失数据的样本,在建模数据挖掘时就不能对健康档案数据进行正确的分类或预测。同时ID3算法对健康管理进行数据挖掘时确定树根节点时选择居民的年龄(有7种值)作为首选判断的属性根节点,但实际中医学专家却认为这个属性在判断糖尿病诱因时不是最重要的,ID3算法往往选择取值较多的属性作为测试属性。健康管理系统进行数据挖掘时ID3算法每选择一个分裂节点,算法都要经过多次的对数运算,影响了决策树的生成效率。
2.2 决策树ID3的算法改进
2.2.1 改进方案
针对以上ID3算法在健康管理系统应用中存在的问题,提出以下几方面的改进方案:
1)对属性值缺失或空白情况的处理,通过对训练集中其他完整的实例,进行比较来选择一个较优的填充值,在构造决策树之前,对训练集中缺失或空白的属性进行填充。
2)对算法要经过多次对数运算,影响决策树生成效率的处理,对信息增益公式的对数运算进行转换,找到一种属性选择的新方法,使算法生成决策树的时间大大减少,提高决策树分类的效率,提出了简化熵的计算方法。
3)ID3算法根据每个属性信息熵的值来判断数据集中的分裂属性,信息熵反映每个属性对整个数据集的不确定程度,ID3往往选择取值较多的属性,为克服这一缺点,我们为每个属性的信息熵引入一个权值,来平衡每个属性的不确定程度,更符合实际的数据分布。但要保证决策树生成效率,这里选择对每个属性的简化熵引入一个权值,权值为每个属性在数据集中的取值个数,再用该权值乘以简化熵,使信息熵的结果还依赖于属性的取值个数,乘积结果称为加权简化熵,再通过比较加权简化熵的大小来选择最优的属性作为决策树的分裂节点构造决策树,这样既克服了倾向属性选择较多值的问题,又可以提高决策树的构建速度。
2.2.2 改进算法
1)对训练集中属性值缺失或空白情况的处理,填充过程如下:训练集中的N个属性集合中的一个属性Ai,其中一个实例S在属性Ai上缺失数据,令M=N-1,在训练集中找出其余M个属性取值和实例S对应一致的实例,组成实例集合S',如果集合S'不为空,则计算集合S'中Ai的不同取值的比例,利用取值比例最大的值进行填充;如果S'为空,则令M=M-1,如果M<N2,则从训练集中删除实例S。
2)简化熵的计算:由公式Gain(A)=I(p,n)-E(A)得知,由于每个节点上的I(p,n)是一个定量,则可以选取属性A的熵值E(A)作为节点之间的比较标准,其中,将此式代入到E(A)中,则有:
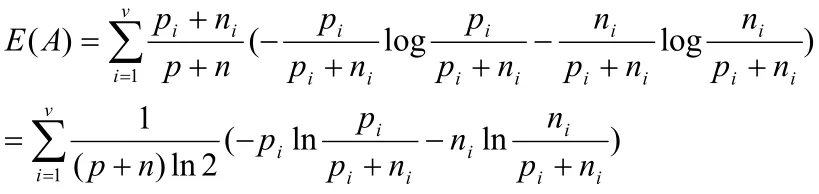
由于(p+n )ln2在训练数据集中是个常量,所以可以假设函数S(A)满足以下公式:
对候选属性Ai所对应的Vi个子结点属性值,对应的概率分别是,计算出所对应的简化熵
3)加权简化熵的计算:
取属性A值的个数作为权值,A有V个属性值,对应的概率分别是,属性iA所对应的iV个子结点属性值,对应的简化熵为。则属性的加权简化熵为:
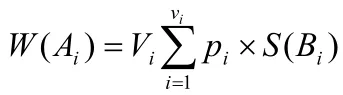
最后选择属性Ai+1,Ai+2,…,计算出相对应的加权简化熵W(Ai+1),W(Ai+2),…,通过比较熵值得出最小的加权简化熵W(),使得W(A')最小,将作为新的候选属性节点,同时向下扩展其Vk个子节点。如果有两个属性的加权简化熵相等且都是最小值,可以选择其中的一个属性作为新选的属性节点,以此方法向下直到叶节点,停止扩展。
通过对健康管理系统中多组数据集试验数据比较节点数、规则数和分类精度,得改进算法克服了决策树属性倾向取值较多的问题,并可建立较优的决策树,新算法使生成的决策树没有多余的空树,提高了算法准确性,同时降低了空间的复杂度,由于改进算法计算简化熵要比ID3算法计算信息熵简单,降低了时间复杂度。
3 实验结果
3.1 数据准备
本系统采集了某地区多个社区2005年1月1日到2006年12月31两年居民健康档案数据,包括居民基本信息、病史、家族史、生活方式(每日膳食、运动锻炼、吸烟、饮酒等)、体检信息等,共5531人。为了确保实验结果,保留2005年1月1日到2006年12月31两年的档案数据为筛选因素属性数据,从2007年1月1日到2008年12月31日期间,更新的居民健康档数据中糖尿病诊断或检查结果作为结局数据,两年内糖尿病患者总共有53人,根据个人ID号,将筛选因素数据表和结局数据表连接成一张大表,将所有记录随机分为训练集和测试集[3]两组。
数据预处理[4],需要对连续的属性进行离散化处理,并要去掉一些对挖掘来说没有意义的属性,在进行挖掘时,应该根据不同的数据有选择的选取挖掘属性,比如说去掉一些居民的基本家庭信息、联系方式等等。本系统根据数据库中数据选用了其中12个属性、属性的取值(即离散值)和人数进行数据挖掘,如表1所示:
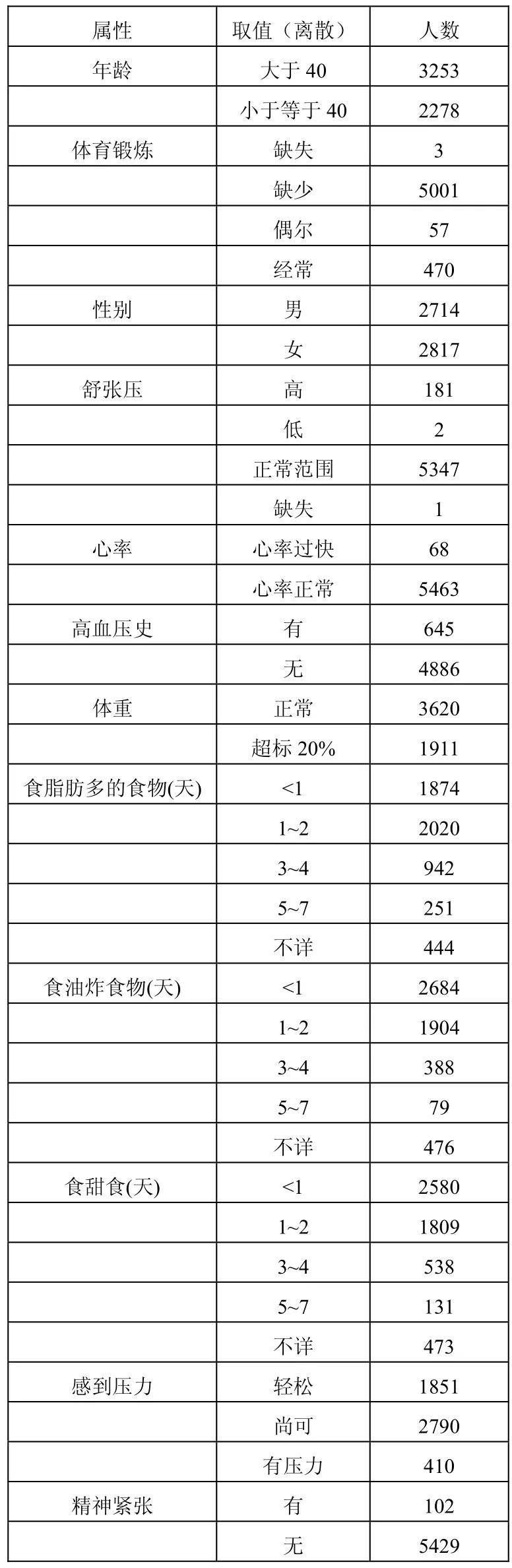
表1 筛选因素属性取值分布表
随机抽取原始数据中的3500条记录作为训练数据集,剩余数据作为测试数据集。
应用改进算法克服属性选择多值化的办法构建决策树,计算化简信息熵值及加权简化熵值,选取加权简化熵值最小的属性作为决策树的根结点,递归调用这种方法建立各棵子树。
3.2 挖掘结果
为验证改进算法的有效性,对测试数据进行分析,见表2所示:

表2 两种算法结果对比
由以上分析结果可以看出,改进的算法优于原算法,充分说明改进算法,能够以更快的速度及准确率构造决策树,基本达到实验要求,更适合健康管理系统的挖掘工作。
根据决策树对居民健康档案数据进行挖掘得出结论:具有高血压病史的人、脂肪饮食不详的人或者体重超标20%、体育锻炼缺失的人、年龄大于40岁的人可能患有糖尿病的高风险。
4 结束语
本文通过对决策树ID3算法进行研究,针对ID3算法在健康管理系统中,应用存在的一些问题提出了改进算法,克服属性选择多值性、处理属性值空白或缺失的情况及提高决策树构建速度等方法。本文使用决策树对居民健康档案数据进行糖尿病诱因的数据挖掘,得出了可能患上糖尿病的相关属性,结果和实际数据及患病背景知识相一致,证明使用其进行数据挖掘得出的结论是有效的。在其他慢性病的预防及治疗中也起到了重要作用。
[1]徐鑫,席素梅.决策树技术在高校教学管理中的应用研究[J].计算机科学,2009,(4).
[2]闪四清,陈茵,程雁等.数据挖掘——概念、模型、方法和算法[M].北京:清华大学出版社,2003.
[3]李贤鹏,何松华,赵孝敏,等.改进的ID3算法在客户流失预测中的应用[J].计算机工程与应用,2009,45(10).
[4]陈健.决策树挖掘技术在医学上的应用[J].福建商业高等专科学校学报,2009,(2).
