面向知识工作者的个人信息管理模型
2010-04-27陈明炫周明骏戴国忠
陈明炫, 周明骏, 田 丰, 戴国忠
(中国科学院软件研究所人机交互技术与智能信息处理实验室,北京 100190)
面向知识工作者的个人信息管理模型
陈明炫, 周明骏, 田 丰, 戴国忠
(中国科学院软件研究所人机交互技术与智能信息处理实验室,北京 100190)
为满足知识工作者对个人信息管理的灵活分类、时序管理和智能推荐的要求,提出一种个人信息管理系统模型。首先分析了知识工作者的个人信息管理特点,接着提出了模型的框架,描述了框架的层次结构。然后介绍了基于标签的个人信息推荐算法。最后对原型系统进行了评估。评估结果表明,该模型能够满足知识工作者对个人信息管理的要求。
计算机应用;个人信息管理模型;标签;知识工作者
个人信息管理(PIM)是对于日常信息的处理、分类、访问。它主要研究人们每天对信息的获取、组织、维护的活动[1]。Bush最早提出阐述PIM概念的Memex系统[2]:Memex是一种能够记录所有书籍、唱片、交流信息的设备,它能够快速、自动、灵活的帮助人们找到所需要的信息。随着信息技术的不断发展,越来越多的人们参与PIM的研究,涉及的领域非常多,包括人工智能、数据库技术、信息抽取、人机交互等,引起了广泛的关注。
由于不同的人群对信息处理的要求不同,单一的信息处理方式已经不能适应不同人群的需要,根据Kidd的研究[3],做日常信息处理的计算机用户大体分为三类:知识工作者、交流工作者和文秘工作者,他们都要进行管理型活动和研究型活动,只是侧重不同。管理型活动的特点在于重复性、结构化的、文档驱动的,而研究型活动特点在于灵活性、非结构化和信息驱动的。知识工作者偏重于研究型活动,后两者偏重于管理型活动。当前大多数人使用的信息管理系统是基于传统的WIMP界面,对文档的管理采用树状的层次化管理结构。当前系统在支持交流工作者和文秘工作者的同时,却不能很好的支持知识工作者,原因在于:
首先,知识工作者的工作具有创造性和随意性,与其他用户比较,更需要以人为中心的设计,要求系统在分类上符合人的心理模型:分类方式灵活、非结构化、信息可重叠。而传统的层次化组织方式具有结构固定、层次单一和排它的特点,这显然与用户心理模型相矛盾[4]。
其次,知识工作者是信息驱动的工作方式,常常围绕一个问题在一段时间内进行思考,工作具有很强的持续性和专一性,要求系统能在管理上具有时间连续性,而传统的信息管理方式没有足够地支持这一点。
最后,知识工作者的发散型思维常常需要获取与当前工作内容相关的信息,这就要求系统能够通过分析用户的当前活动,进行合理的推荐。这显然是当前的个人信息管理系统所不能满足的。
针对这些问题,作者提出了面向知识工作者的PIM模型,能够很好的解决上述存在的问题,为知识工作者提供完善的个人信息管理服务。
1 相关研究
计算机技术的发展使得人们对信息管理环境的要求越来越高。虽然当前存在着一些个人信息管理系统,但是由于缺乏对知识工作者本身和其任务的分析建模,使得现有系统存在着设计上的缺陷。
William Jones考察了传统信息管理系统的层次化的管理方法,发现当人们管理某个项目文档时,通常把文档通过“文件夹-子文件夹”的方式一步步把文档放入叶子结点,这样做的同时伴随着用户对项目进展的理解,然而对于没有上下级关系的文档而言,很难通过这样的手段来组织文档,当文档涉及的方面横跨了多个层级结构时,更是如此[5]。
针对当前层次化管理方式的不足,很多研究者提出了各种模型方法或者结论。Scott Fertig等人提出了时间流隐喻,把文档按照使用时间进行排序,并开发了Lifestream系统[6-7]。类似Lifestream的系统还包括同时期的Lifelines[8]和后来的MyLifeBits[9]。时间流隐喻的好处在于用户总是可以快速访问到最近浏览过的文档,但它存在的问题在于,分类方式单一不灵活,仅仅利用了文档的使用时间属性,对于其他描述文档的属性没有充分利用起来。而且在用户无法回忆起使用文档的时间时,该隐喻不仅丧失了最大的优点,而且无法为用户查询文档提供更多的帮助。
Malone在1983年的研究中发现,人们对文档的管理可以分为松散管理的Pile方式,和严密管理的File方式[10]。Richard Mander借鉴了Malone的Pile思想,提出Pile隐喻,即在桌面环境下对文档进行松散管理[11]。Ravin等人实现了基于Pile隐喻的系统,并在交互上进行了完善[12]。Piling的好处在于文档组织的随意性,不受固定的层级结构的影响,部分解决了层次化管理存在的不灵活的问题。然而Piling隐喻的最大问题在于文档数量的无限性和桌面空间的有限性之间的矛盾。对于PIM而言,文档的数量是惊人的,仅靠桌面管理是无能为力的。
Paul提出的基于属性的文档管理系统Presto,用户可以给文档指定任意数目的属性,查询时指定属性值即可[13-14]。Wisam Dakka提出了从文档内容中自动提取关键词对文档进行描述[15]。两者的相同点在于都对文档进行了多方面描述,尽可能全面反映文档特点;区别在于前者是用户指定,后者是系统自动提取。多角度全方位描述文档的思路是好的,但前者存在的问题在于,描述属性的形式过于单一,只限于文本属性,而且“Name=Value”的属性定义形式必然要求用户在描述时思考对Name的定义,无形中要求用户对文档进行分类,而根据Malone[10]的研究,用户管理文档的困难之一正在于分类对认知负担的加重。后者的缺点在于系统过度的智能化。Kidd[3]曾指出,对PIM的设计时要知道,只有用户自己知道想要的是什么,不过度揣摩用户的心思。自动提取文档关键词描述,往往会导致提取的关键词并不是用户想要的,因此用户在使用中不能很好的掌握对文档的描述。
综合上面的前人研究工作可以看到,不论是时间流隐喻,还是pile隐喻,或者是基于属性的管理方法,都是为了摆脱当前文件层次化管理方式的限制。但他们在解决问题的同时也带来了新的问题,共同的问题有:① 分类方式单一,有的靠时间属性,有的靠自定义属性;② 没有对用户的行为进行分析,并适当推荐。这些显然不能支持知识工作者的活动。
本文提出的面向知识工作者的PIM模型,以时间线为可视化手段,以标签的形式对文档进行统一管理,建立了面向知识工作者个人信息管理模型的三层结构。本文的贡献在于:① 建立了面向知识工作者的个人信息管理模型;② 为知识工作者提供时间连续性的工作支持;③ 为知识工作者提供基于标签的灵活分类方法;④ 对用户行为进行分析,并适当推荐。
文章接下来的组织顺序是,首先分析知识工作者的工作模型,其次阐述模型总体框架并详细论述各组成部分,接着介绍原型系统,最后做出总结。
2 知识工作者活动模型分析
日常生活中,知识工作者在创造知识的时候往往是从思考的问题出发,一有想法就马上记录下来,放在桌子上不进行归类,对问题的思考经常要经历一段时间才会形成清晰的思路,这时候桌面上往往是许多草稿纸和便签,这些都记录了知识工作者工作时的灵感,对他们有提醒的辅助作用。当他们需要查找以前写过的东西时,往往直接想到要查找的文档的特征,例如要查找ACM有关交互的文章,反映在他脑中的都是与ACM、交互、最近在哪里使用过该文档等关键信息。知识工作者往往需要一目了然地看到自己想看到的东西,无论是经常工作过的文档,还是与该文档有关,但好久不用的文档,只要与该文档有关,都希望马上获取到。作者把活动模型概括如图1所示。
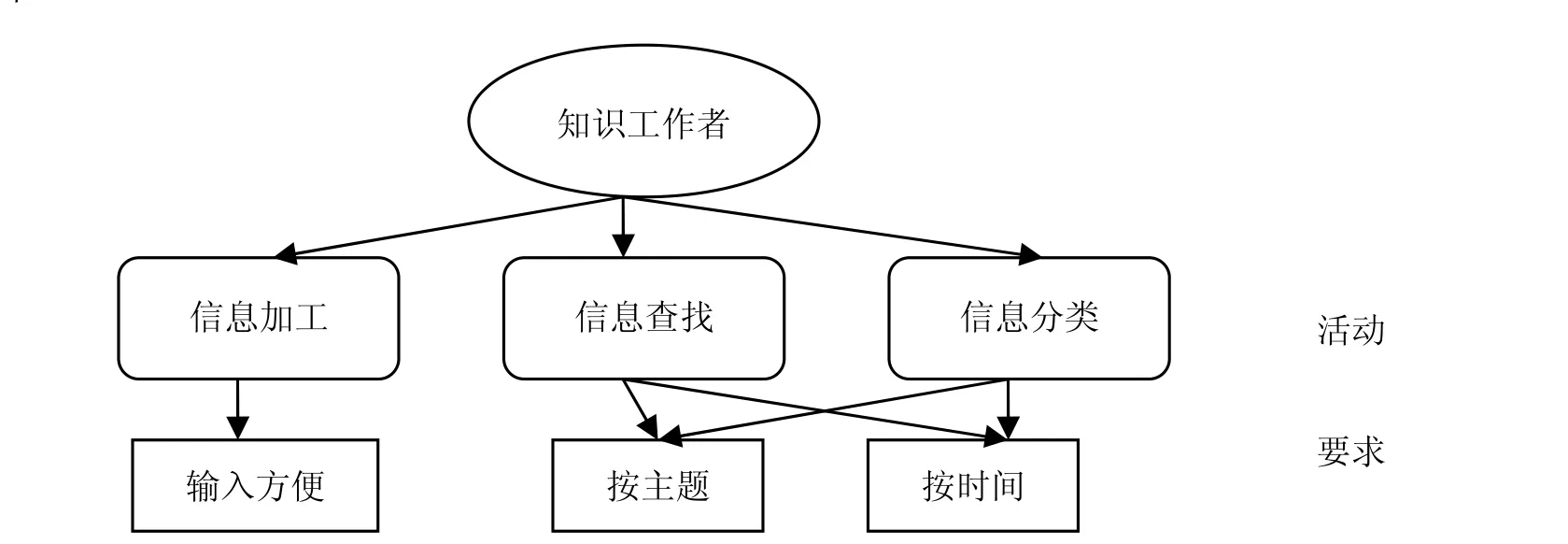
图1 知识工作者活动模型
信息加工包括了知识工作者创造知识,整理知识。要求输入自然方便。
信息查找是指用户对创造过的知识进行查找,要求按照时间或者要获取的知识来查找。
信息分类是指用户把近期使用过的文档进行piling似的松散分类,从时间看是近期使用的,从主题看,反映相似知识的文档往往被分为一类。
以上是对知识工作者活动特点的描述,从中可以分析得出支持知识工作者的信息管理系统有以下几个特征:
从底层数据组织来看,用户需要自然灵活的信息组织方式。由于知识工作者工作中产生的文档,如草图等,他们之间的相互关系很难用层次化结构来描述,而用户需要松散的灵活分类,这就需要一个能提供灵活分类的非层次化信息管理系统。
从对数据的管理来看,用户需要很好的历史管理机制。由于知识工作者总围绕一个中心问题进行思考,工作特点具有时间上的连续性,需要有很好的机制记录用户的交互历史。
因为知识工作者是信息驱动的,他们往往因为思考一个主题,使用过的文档具有很强的主题相关性,所以找到这种相关性并向用户提醒和推荐,是面向知识工作者的个人信息管理系统应具备的功能。
从用户界面角度来看,用户需要丰富的可视化形式,以方便自然地与系统进行交互。
根据以上分析,面向知识工作者的个人信息管理系统需要具备以下功能特征:系统包含的主要功能模块应该有信息组织模块、可视化表现、历史管理、知识管理。其中的信息组织模块主要负责以灵活的方式组织用户的数据;可视化表现部分主要以时间流界面为主,用于支持知识工作者工作的时间连续性;历史管理模块记录用户使用系统的历史;知识管理主要结合历史管理模块,对用户的行为进行智能分析,提取关于用户行为特点的知识。如图2所示。

图2 支持知识工作者的系统功能性特征
3 面向知识工作者的 PIM 模型描述
根据上面对知识工作者工作需求的分析可以看出,知识工作者的个人信息管理模型需要方便自然的信息组织方式、强大的历史管理、丰富的可视化表现和智能化的提醒推荐功能,传统的层次化文件管理方式显然不能满足用户的需要。为此,我们设计了基于标签的管理模型,以标签来组织数据,为用户提供了灵活的文档分类方法和充足的文档使用历史记录,同时加入了智能处理模块分析用户的交互历史,适时对用户进行提醒和推荐,全面支持知识工作者的创造性活动。
3.1 模型框架
作者分析了知识工作者的工作模型特点,并考虑到个人信息管理是在用户空间和数据空间之间建立映射关系,由此设计了面向知识工作者的三层个人信息管理模型。模型分为3个层次:数据层、任务层、交互层,如图3所示。
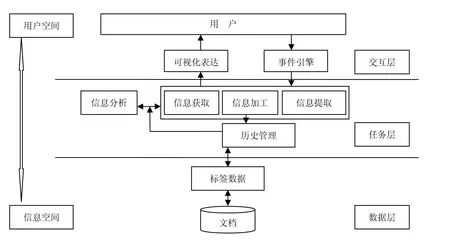
图3 面向知识工作者的个人信息管理模型
其中数据层存储了文档和标签的数据,以及他们之间的相互关系:一个文档可以有若干个标签来描述,一个标签也可以描述若干个文档。数据层仅仅存储这些信息,而不对信息进行解释和加工。任务层负责对这些数据进行处理。包含信息获取、信息加工、信息提取、历史管理、信息分析等模块。任务层接受交互层的具体任务指令,根据不同的指令调用不同的处理模块。交互层描述了用户的输入输出行为,事件引擎解析用户命令,向任务层发出交互指令,并从任务层得到可视化的效果,通过可视化模块反映给用户。下面详细阐述模型的每一个层次。
3.1.1 面向知识工作者的模型数据层分析
数据层存储了个人的所有信息,包括管理对象本身,即用户的文档,和辅助管理的数据即标签,还有两者间的映射关系。
(1) 标签的概念和使用
当前的大多数系统使用树状结构的层次化管理方法,如图4所示。
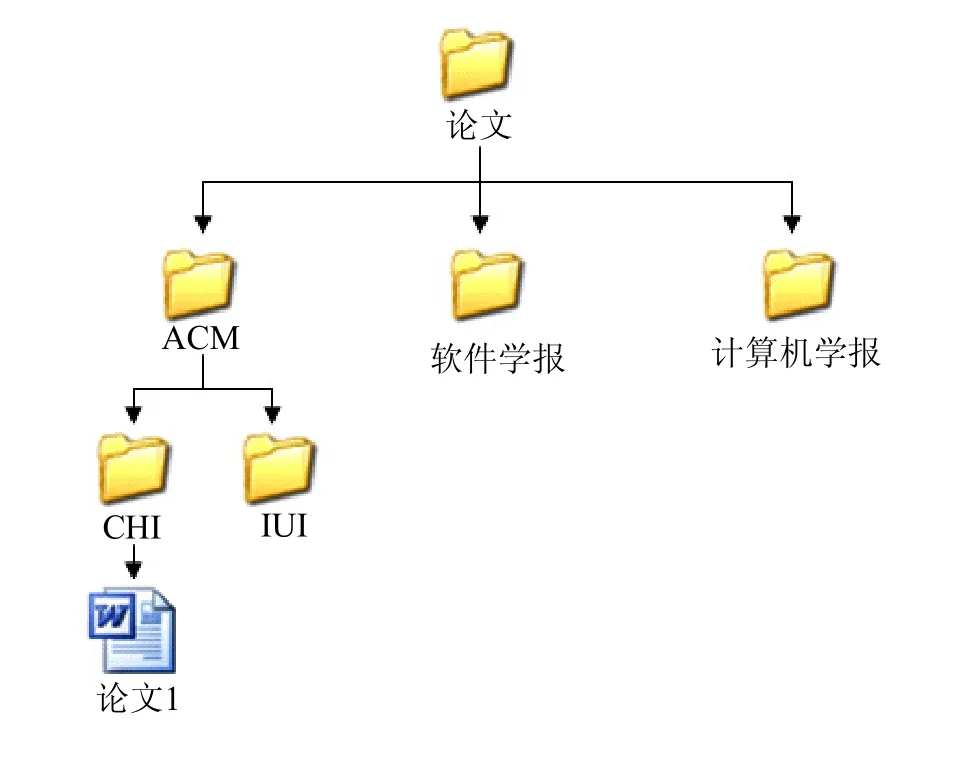
图4 层次化管理模型示意图
论文1的位置描述为:论文->ACM->CHI->论文1。对于具有确定所属关系的文档,这样的描述方式是合适的。然而现实生活中,很多文档的分类虽然具备所属关系,但关系不确定;很多文档的分类则无法用所属关系来描述。例如一份菜单,从口味上分,可以分为粤菜、川菜、杭帮菜等;从荤素上分,可以分为荤菜、素菜;从价格上又可以分为高中低档,每一种分法都不能确定属于另一种分法,因此用层次化的管理方式来分类是不科学的,一些情况下用户无法接受。
贴标签是现实生活中描述事物的常用方法,原因在于事物本身有多个特点,看待这些特点是从多个角度出发的,用多个标签能最大程度反应事物本质。即可以把标签定义为:反映事物属性的描述。如图5所示,看待一篇论文,从类型上看,是pdf格式,从名称上看是论文,从论文描述的方向看,是人机交互方面的文章,标签同时告诉人们它至少与ACM会议和张老师与李老师两人有关。
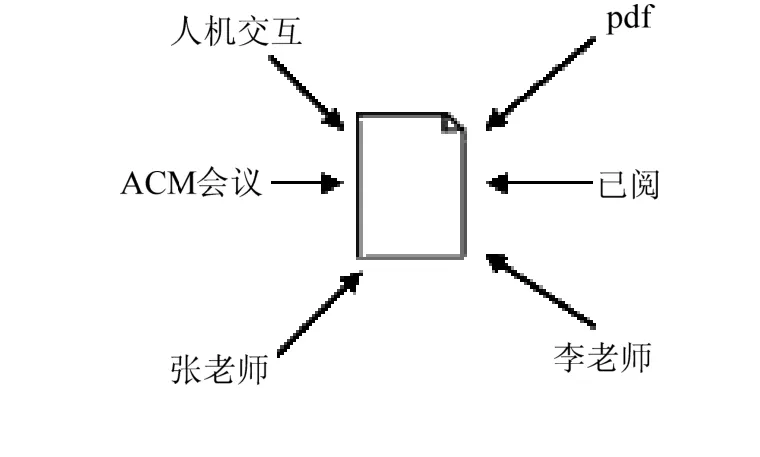
图5 文档标签示意图
对于标签的使用可以分为两种,一种是基于标签的浏览,即浏览该标签标注的所有文档,另一种是基于标签的查询,即输入标签关键词,系统查找到相应的文档。
(2) 基于标签的数据组织
在计算机系统中,根据标签的生产者,把标签分为两类:显性标签和隐性标签,显性标签由用户主动输入,隐性标签由系统生成,显性标签又按照数据的类型分为文本标签和ink标签。隐性标签由文档使用时间标签组成。在本系统中,同样是对文档的描述,标签与Paul提出的文档属性[13]的不同点在于,Paul的属性是“Name=Value”的形式,即每个属性要有属性的名称,有的需要用户自定义。而本文提出的标签概念中,属性名称是系统已知的,即对文档时间这样的隐性标签,属性名称为 time_prop;对于用户自己输入的显性标签,属性名称为discribe_prop,两种情况下,用户都只需要输入属性值描述,而不需要输入属性名称,从用户交互角度看,显然与Paul的系统有不同,为与之区别,作者把它们统一叫做标签。之所以不要用户定义属性名称,是因为对于名称的定义就需要分类,然而分类对用户来讲往往是困难的[10]。
对一个文档的描述,可以使用若干个标签:
<document>:=<ID,Name,Path,Type,ID: 文档的全局唯一标识符,唯一标识文档的身份;Name:文本形式定义的文档的名称,可以由用户指定;Type:以文本形式定义的文档的类型;Path:当前操作系统的文件系统里,文档的具体位置;Tag:描述文档特征的若干标签,可以是3个标签中的任意形式。
对一个文本标签的描述,可以这样表示:
<Tag_Text>:=<ID,discription>
ID:文本标签的全局唯一标识符;description:以文本形式对标签的描述。
对一个ink标签,可以用如下表示:

ID:ink标签的全局唯一标识符;StrokeNumber:ink标签里,笔划的个数;Stroke:ink标签里的每个笔划;PtNumber:笔划里点的个数;Pt:笔划里的每个点;X:点的横坐标;Y:点的纵坐标。
对文档使用时间标签的描述如下:
<Tag_Time>:=<ID,Time>
ID:时间标签的全局唯一标识符;Time:系统记录的文档使用时间。
显然,标签来组织数据的本质在于标签与文档间多对多的映射关系,而传统的树状结构父结点和子结点是一对多的关系,这正是基于标签组织数据的灵活性所在。
3.1.2 面向知识工作者的模型任务层分析
作者分析了知识工作者的活动,总结了知识工作者在使用信息管理系统时主要完成的操作,如表1所示。
作者把这些操作根据操作对象的不同以及对底层数据的影响,抽象成3个任务:信息获取、信息加工、信息抽取。这3个任务连同为智能化提供服务的历史管理模块和信息分析模块一起,构成了任务模型的5个主要部分。
信息获取负责接受用户的输入,输入分为文本形式和ink形式,前者是用户以文本形式对文档所做的描述,即文本标签,后者既包括用户以ink形式对文档做的描述,即ink标签,也包括用户以ink形式勾画的草图。

表1 知识工作者对信息管理系统的主要操作
信息加工对新来数据进行加工,并维护已有数据。对新数据的加工体现在:① 建立新文档;② 建立新标签;③ 建立新文档与已有标签的关联;④ 建立新标签与已有文档的关联。对已有数据的维护体现在:① 删除指定文档;② 删除指定标签;③ 删除指定文档和标签间的关系;④更改已有文档;⑤ 更改已有标签;⑥ 建立已有文档与已有标签间的关系。
信息提取根据用户的查询条件,对文档进行查询,查询方式根据标签不同分为:基于标签的浏览、基于关键词的查找、基于时间的查找。前者查询到指定标签下的所有文档;中者根据用户输入的关键词到数据空间进行查找,关键词可以是文本形式,也可以是ink形式;后者根据文档使用时间查找。
历史管理负责记录用户和系统交互的历史,为智能化的信息分析模块提供服务。
信息分析负责对已有数据进行分析,已有数据包括文本标签、ink标签和文档使用时间标签。分析任务包括:① 根据文档使用的时间,分析文档的使用周期;② 根据文档使用的时间,分析与该文档具有时间相关性的其他文档有哪些;③ 根据文档间标签的重叠性,对文档进行聚类。对3个分析策略的描述在后面详细展开。任务模型如图6所示。
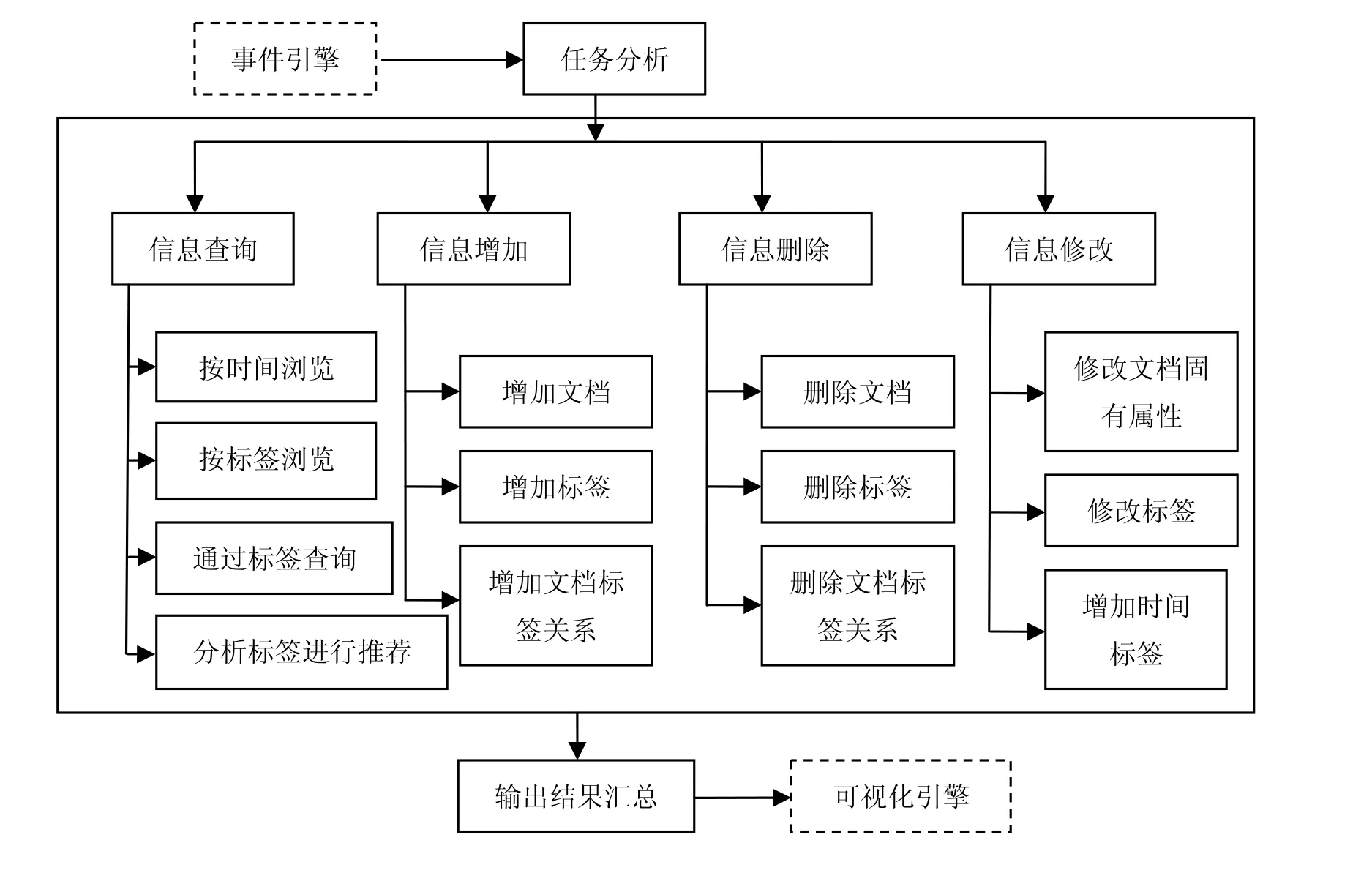
图6 任务分析图
3.1.3 面向知识工作者的模型交互层分析
交互层里主要包括事件引擎和可视化表达。
用户对计算机的操作,连同交互历史一起,通过事件引擎的解析,形成系统可以执行的若干操作指令,发送给任务层进行任务的执行。执行后的结果,交给可视化模块反映给用户。
可视化模块负责显示管理层提交的可视化结果,根据不同的结果选择不同的可视化策略。主界面是基于时间流隐喻的时间线界面,它的好处在于支持知识工作者工作的时间连续性特点,由于时间线隐喻属性单一,本系统还增加了对文档基于标签的查询。根据上图输出结果,可视化部分选择不同的可视化策略,如图7所示。如果 ∂t i ≤ ∂Tmax ,∂ T max是系统定义的最大周期偏差,即可以认为文档在最近的N次使用中,存在周期性,并定义t为平均间隔时间
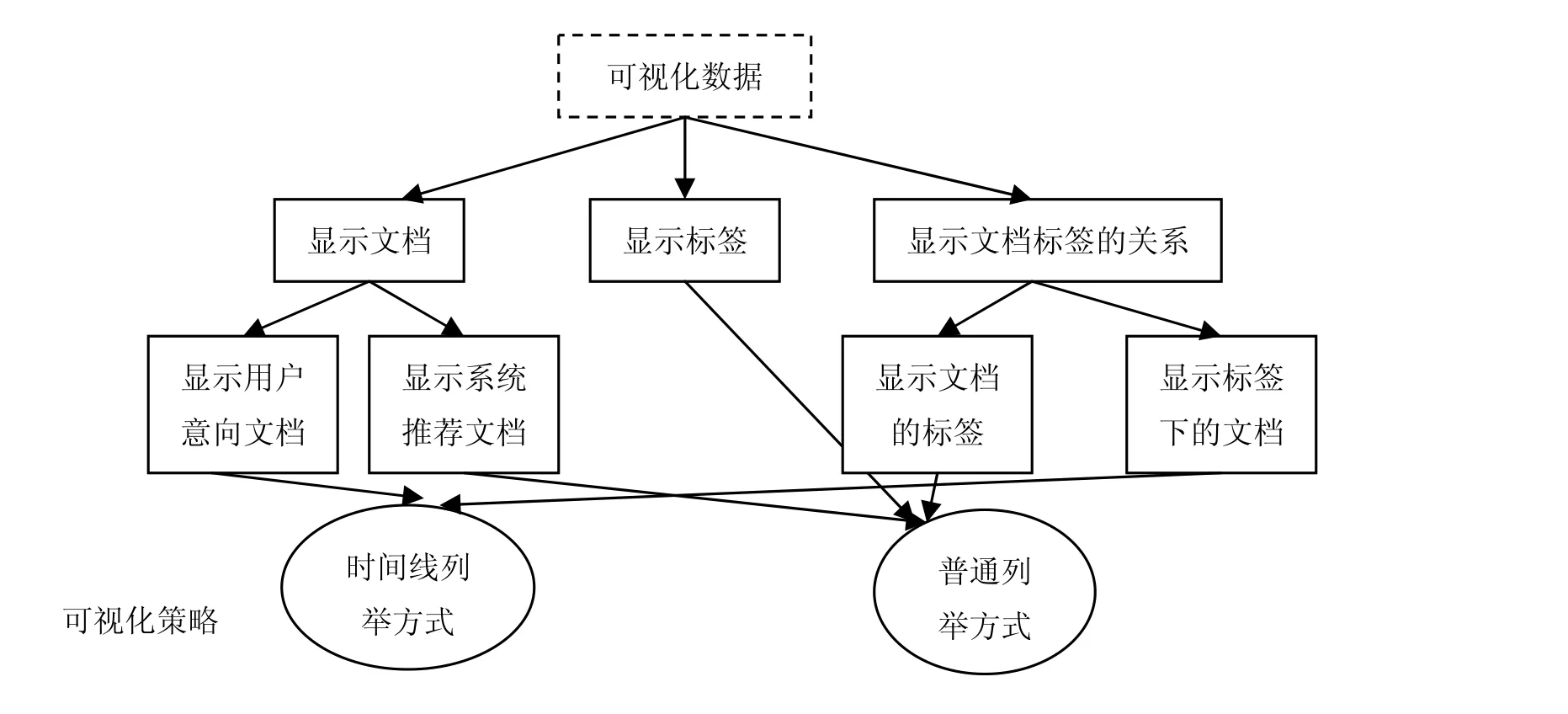
图7 可视化策略
3.2 面向知识工作者的PIM模型的管理策略
由于知识工作者工作中具有创造性特点,他们在思考问题是信息为驱动的发散性思维,这就要求个人信息管理系统能够充分分析用户交互历史的数据,从中提取到用户的思维特点。作者用标签来全面描述了文档,对标签进行分析,从中发现用户行为的特点。
3.2.1 文档时间关联分析
(1) 文档周期性分析
文档的周期性分析目的是找到文档使用时间是否存在规律性,如果存在,则找到规律并且预测文档下一次的使用时间,届时进行文档推荐。周期性分析使用了文档使用时间标签。系统在文档每一次使用的时候,记录下使用的时间。
将文档的使用时间序列用t来表示,定义N为用来进行分析的最近时间个数,比如,N=5即表示分析最近5次文档使用时间。定义Nmax为文档使用时间序列的个数。如果 N >Nmax,则不进行分析;如果N≤Nmax,则按时间从远到近,对N个时间进行排序:t0…tN-1,计算N-1个时间间隔:Δt0…ΔtN-2,其中Δti=ti+1-ti(i=0…N-2),对这 N-1个值,计算相邻两者的差的绝对值:在文档最近使用时间的间隔后,进行系统推荐。如图8所示。
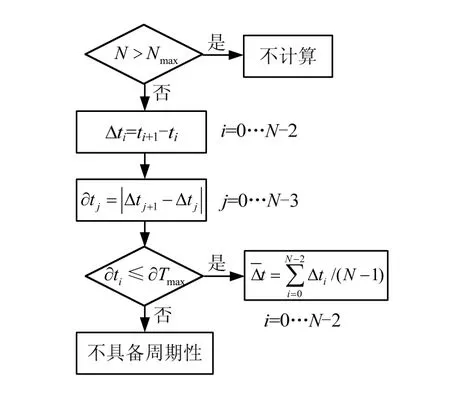
图8 文档周期性分析流程图
(2) 文档间时间关联分析
文档间时间关联分析目的是找到所有与给定文档有时间相关性的文档。在给定文档被激活时,系统找到与给定文档具有时间相关性的文档,进行推荐。时间管理性分析利用了文档使用时间标签。
作者将给定文档的使用时间用t0来表示,定义N为用来进行分析的最近时间个数,比如,N=5即表示分析最近 5次给定文档使用时间。定义Nmax为文档使用时间序列的个数。如果N >Nmax则不进行分析;如果N≤Nmax,则按时间从远到近,对N个时间进行排序:t0…tN-1。对于每个ti(0≤i≤N-1),计算ti附近的两个时间ti1和ti2,其中ti1= ti-Δt,ti2= ti+Δt,Δt是系统给定的时间范围正参数,并向文档搜索引擎查询使用时间为ti≤t≤t2的文档集合Ci(0≤i≤N-1)。求文档集合Ci(0≤i≤N-1)的交集则集合C即是与给定文档具有相关性的文档集合,如图9所示。
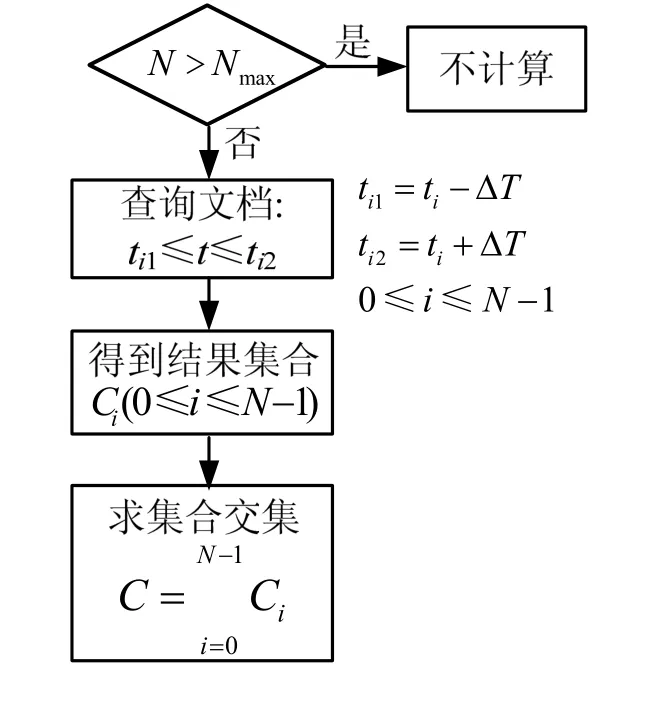
图9 文档间关联分析流程图
3.2.2 文档聚类分析
文档聚类分析目的是找出与给定文档具有标签相关性的文档集合,在用户激活给定文档时,系统找到该集合,并进行推荐。文档聚类分析使用了文档的文本标签和ink标签。
作者将给定文档的文本标签和ink标签统一用G表示。定义N为给定文档的标签个数,比如N=5即表示该文档有5个标签有待分析。对于每一个标签通过标签查询引擎,查询到拥有标签 Gi的文档集合 Ci,对于出现在 Ci中的每一个文档 Dj,记录下他出现次数tj,如果 tj≥Tmin(Tmin系统定义的文档出现最小次数)即可以认为文档Dj与给定文档存在着标签相关性,并且根据标签 Gi,可以建立起以Gi为中心的相关集合。
4 原型系统和评估
系统主界面如图10所示,共有8个区域。
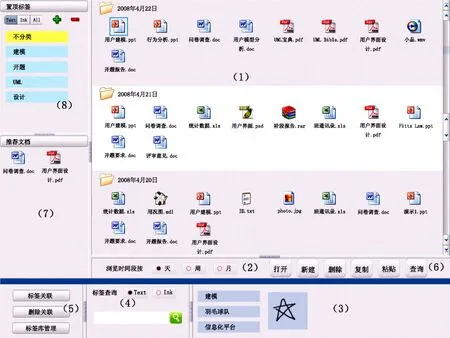
图10 系统主界面
(1) 为时间线界面 按时间由近及远显示出用户用过的文档。这里也按时间显示查询出的文档。
(2) 对时间线界面的浏览方式 可以按天、周、月为时间段进行浏览。图 10中例子是按天进行浏览。
(3) 显示文档所标注的标签 当选中一个文档时,显示该文档所标注的标签。图 10中选中了“用户建模.ppt”文档,与它关联的标签显示在这里,有3个文本标签和一个ink标签。用户可以在(5)中进行文档和标签的关联操作。
(4) 对文档进行基于标签的查询 可以按两种情况进行文档查询:文本标签和ink标签,查询后的结果按最后使用时间显示在时间线界面(1)中。该区域进行一个标签的查询,在(6)区域中,可以有多个标签的复杂查询。
(5) 对标签的操作 对标签的操作包括:建立标签与文档的关联,删除标签与文档的关联,标签库的管理。
(6) 用户对文档的主要操作 对文档主要操作包括:打开、新建、删除、复制、粘贴、查询。其中,查询部分可以弹出新界面,对文档进行多个标签的复杂查询。
(7) 系统对用户进行的文档推荐 系统分析用户所选的文档,找到与该文档具有时间相关性或标签相关性的文档,在这里进行提醒和推荐。
(8) 用户自定义的置顶标签 用户感兴趣的标签和最近工作常用到的标签,都可以由用户放在该区域。当用户选择一个标签时,(1)界面将按时间显示具有该标签的所有文档。
综上所述,原型系统反应了模型的诸多特点:支持知识工作者工作中时间连续性特点;支持知识工作者对文档进行灵活分类;分析知识工作者使用过文档的特点,对他们进行文档推荐。
为了评估本原型系统设计,作者进行了定性的用户研究。在实验室范围内以自愿报名的方式选择了8名被试(包括3名女性,5名男性,均有5年以上计算机使用经验)。每名被试用时40分钟,其中包括3分钟的简单介绍和10分钟的自由探索,在进一步讲解用户在自由探索阶段未发现的功能之后,要求被试完成两组共 12个任务,包括:① 基本操作,如新建,删除,复制,粘贴等;② 高级操作,如编辑标签,查询等。实验完成之后,每名被试被要求完成一份5分量度的主观满意度调查问卷,问题范围包括易学性、使用愉悦性、趣味性、能否完成任务以及使用效率。在试用本系统进行日常工作一周后,每名被试完成第二份调查问卷,第二份调查问卷除涵盖第一份问卷中关于愉悦性,趣味性,效率3项内容之外,还包括两个针对特定功能的问题:① 标签策略对查询是否有较好的辅助作用?②系统的文档推荐是否准确?
问卷结果分析显示:本原型系统易于学习(4.5/5),用户能够完成指定的任务(4.5/5),用户认为使用过程较为愉悦,交互过程也比较有趣(4/5 4.1/5),使用效率可以接受(3.9/5),经过一周的试用后,用户的使用效率有明显提高(4.4/5),愉悦度也有一定提高(4.3/5)。另外,用户普遍认为标签策略对查询有较好的辅助作用(4.1/5),系统的文档推荐较为准确(4/5)。
5 结 束 语
本文分析了知识工作者的活动模型,提出了面向知识工作者的个人信息管理系统应具备的功能特点,建立了适合知识工作者的个人信息管理模型,在3个层次进行了阐述。建立的原型系统取得了不错的效果。随着普适计算技术的不断发展,知识工作者为了更大地激活创造力,对计算机必定有更高的要求,希望为创造力的发挥有更好的支持,同时他们在使用日益完善的计算服务时,工作也必将具有新的特点。如何发现这些特点,如何针对这些特点满足他们的需要,如何设计更好的智能化服务为用户提供智能支持,将是今后的主要研究方向。
[1] William Jones, Harry Bruce. A report on the NSF sponsord, workshop on personal information management [EB/OL]. http://pim.ischool.washington. edu/final PIM report.pdf. 2005.
[2] Vannevar Bush. As we may think [J]. ACM Interactions Magazine, 1996, 3(2): 35-46.
[3] Alison Kidd. The marks are on the knowledge worker[C]//Proc. CHI 1994, ACM Press, 1994: 186-191.
[4] Eyal Oren. An overview of information management and knowledge work studies: Lessons for the semantic desktop[C]//Semantic Desktop Workshop at ISWC 2006, Athens, Georgia, 2006: 3-11.
[5] Jones W, Phuwanartnurak A J, Gill R, et al. Don’t take my folders away! organizing personal information to get things done[C]//Proc. CHI 2005, ACM press, 2005: 1505-1508.
[6] Fertig S, Freeman E, Gelernter D. Lifestreams: an alternative to the desktop metaphor[C]//Proc. CHI 1996, ACM Press, 1996: 410-411.
[7] Scott Fertig, Eric Freeman, David Gelernter. “Finding and reminding”reconsidered[C]//The SIGCHI Bulletin 1996, ACM Press, 1996: 66-69.
[8] Catherine Plaisant, Brett Milash, Anne Rose, et al. LifeLines: visualizing personal histories[C]//Proc. CHI, 1996: 221-227.
[9] Jim Gemmell, Gordon Bell, Roger Lueder, et al. MyLifeBits: fulfilling the memex vision[C]//Proc. of the tenth ACM International Conference on Multimedia, ACM Press, 2002: 235-238.
[10] Malone T W. How do people organize their desks:implications for the design of office information-systems [J]. ACM Transactions on Information Systems, 1983, 1(1): 99-112.
[11] Richard Mander, Gitta Salomon, Yin Yin Wong. A‘Pile’ metaphor for supporting casual organization of information[C]//Proc. CHI 1992, ACM Press, 1992: 627-634.
[12] Anand Agarawala, Ravin Balakrishnan. Keepin’ it real: pushing the desktop metaphor with physics, piles and the pen[C]// Proc. CHI 2006, ACM Press, 2006: 1283-1292.
[13] Paul Dourish, W. Keith Edwards, Anthony LaMarca, et al. Presto: an experimental architecture for fluid interactive document spaces[C]//ACM TOCHI, 1999: 133-161.
[14] Paul Dourish, W. Keith Edwards, Anthony LaMarca, et al. Using properties for uniform interaction in the presto document system[C]//Proc. of the 12th Annual ACM Symposium on User Interface Software and Technology, ACM Press, 1999: 55-64.
[15] Wisam Dakka, Panagiotis G Ipeirotis, Kenneth R Wood. Automatic construction of multifaceted browsing interfaces[C]//Proc. of the 14th ACM CIKM, ACM Press, 2005: 768-775.
[16] Ofer Bergman, Ruth Beyth-Marom, Rafi Nachmias. The project fragmentation problem in personal information management[C]//Proc. CHI 2006, ACM Press, 2006: 271-274.
[17] Boardman R, Sasse M A. "Stuff goes into the computer and doesn't come out" A cross-tool study of personal information management[C]//ACM SIGCHI Conference on Human Factors in Computing Systems (CHI 2004), 2004: 583-590.
[18] Edward Cutrell, Daniel C Robbins, Susan T Dumais, et al. Fast, flexible filtering with phlat[C]//Personal Search and Organization Made Easy, ACM CHI, 2006: 261-270.
[19] David K Gifford, Pierre Jouvelot, Mark A Sheldon, et al. Semantic file systems[C]//Proceedings of 13th ACM Symposium on Operating Systems Principles, Association for Computing Machinery SIGOPS, 1991: 16-25.
[20] Sarah Henderson. How do people organize their desktops?[C]//Proc. CHI 2004, ACM Press, 2004: 1047-1048.
[21] Jones W. et al. “It’s about the information stupid!”: why we need a separate field of human-information interaction[C]//Proc. CHI 2006, ACM Press, 2006: 65-68.
[22] Kaptelinin V UMEA. Translating interaction histories into project contexts[C]//Proc. CHI 2003, ACM Press, 2003: 353-360.
[23] Joseph Kaye, et al. To have and to hold: exploring the personal archive[C]//Proc. CHI 2006, ACM Press, 2006: 275-284.
[24] Nardi B, Barreau D. "Finding and reminding" revisited : appropriate metaphors for file organization at the desktop [J]. ACM SIGCHI Bulletin, 1997, 29(1): 76-78.
[25] Robertson G, Van Dantzich M, Czerwinski M, et al. The task gallery: a 3D window manager [C]//Turner T, Szwillus G. Proceedings of the CHI 2000 Conference on Human Factors in Computing Systems. New York, ACM Press, 2000: 494-501.
[26] Daniel E Rose, Richard Mander, Tim Oren, et al. Content awareness in a file system interface: implementing the “pile” metaphor for organizing information[C]//Proc. IR1993, ACM Press, 1993: 260-269.
Knowledge Worker Oriented Personal Information Management Model
CHEN Ming-xuan, ZHOU Ming-jun, TIAN Feng, DAI Guo-zhong
( Intelligence Engineering Lab, Institute of Software Chinese Academy of Sciences, Beijing 100190, China )
In order to allow knowledge workers to manage their personal information flexibly, sequentially and intelligently, a model for managing personal information model is proposed. First, the features of the knowledge workers for managing personal information are analyzed. Next, the architecture of the model is provided and the structure of it is described. Some tag-based, personal-information recommendation methods are introduced later. Finally, the evaluation results of the overall system show that the model could meet the knowledge workers’requirements for managing personal information.
computer application; personal information management model; tag; knowledge worker
TP 391
A
1003-0158(2010)03-0176-11
2008-08-16
国家自然科学基金资助项目(60503054);(U0735004);国家“863”高技术研究发展计划项目基金(2007AA01Z158)
陈明炫(1982-),男,内蒙古包头人,博士研究生,主要研究方向为人机交互,笔式计算,个人信息管理。
