The Research on How to Detect Plagiarism in the Theses Based on Automatic Abstraction
2010-04-16ZhaoJunjieWangLiWangPingshui
Zhao JunjieWang Li Wang Pingshui
(Anhui University of Finance&Economics,Bengbu 233061,Anhui)
Automatic abstraction can automatically extract the brief and coherent essays reflecting the main contents of the text completely and accurately from the text or text collection,using the computer to meet the general or particular users’requirements.First,this paper refers to the definition,function and classification of automatic abstraction,and then gives a kind of automatic abstraction technology based on keywords retrieval.It also puts forward a method of detecting plagiarism in the theses based on automatic abstraction and analyzes the results of the experiment.Finally,the author introduces the further work in brief.
automatic abstraction;keywords;extraction;retrieval;plagiarism detection
Author introduction:Zhao Junjie,male,Suzhou Anhui,master degree,lecturer,research direction:data mining and the information retrieval.
Fund of social sciences research project:the project(07JC870006)youth fund,Anhui University of Finance and Economics research projects(ACJYZD200914).
赵俊杰,男,安徽宿州人,硕士,讲师,研究方向:数据挖掘与情报检索。
教育部社科研究基金青年项目,项目编号:07JC870006,安徽财经大学教研重点项目,项目编号:ACJYZD200914。
1.Introduction
So-called automatic abstraction is to automatically extract abstracts from the original literature using the computer[1].Automatic abstraction quickly condenses and extracts a large of electronic texts,which is an accurate and efficient way to accelerate the reading and obtain information resources.So-called abstract is a brief and coherent passage to reflect the central content of a document accurately,mainly including the following three types:instruction,information and comment[2].This paper mainly studies on information abstract,a kind of concentrated expression for the details of the content.It can help users to grasp the core content of the original paper only through reading the abstract,and greatly save the time and improve the efficiency of reading.The main purpose of this study is to design a kind of automatic abstraction techniques based on keywords retrieval and apply it to the rapid detection of paper copy.
2.Overview of Automatic Abstraction Technology
Automatic abstraction consists of three steps:text analysis,information selection and generalization,and generating abstracts.Text analysis finds the most representative components of original contents.Conversion process compresses text through summary.The last step is to recombine the original content and generate abstracts[3].
Automatic abstraction includes four main methods:automatic extraction,automatic abstraction based on understanding,information extraction and automatic abstraction based on structure[4].
2.1 Automatic Extraction
Automatic extraction regards text as a linear sequence sentences and the sentence as a linear sequence of words.It usually works by four steps:(1)calculating the right value of words;(2)calculating the right value of sentences;(3)descending the order of all the original sentences from the highest value to the lowest,and the highest one is selected as abstract words;(4)outputting all abstract words according to their order in the original text.In automatic extraction,the calculation of word value and sentence value and the selection of abstract words are all on the basis of the six kinds of text form:word-frequency,title,position,syntax structure,clue words and demonstrative expressions.These six features are the basis of automatic extraction and they indicate the theme of the text from different angles.
2.2 Automatic Abstraction Based on Understanding
The obvious difference between this mat hod and automatic abstraction lies in the use of knowledge.It not only obtains language structure by using the knowledge of linguistics,but also gets the significance of abstract by using the knowledge of this field.Finally it produces the abstract from the significance.
2.3 Information Extraction
Information extraction means to automatically identify the information such as referring to an entity,relationship,and event from a given set of texts and store or manage all the information.The method of using information extraction to carry out automatic summarization should firstly identify the themes of text,then choose the framework of abstracts,analyze the useful fragments of information extraction deeply and use relevant phrases or sentences to fill the abstract framework.Lastly,we will make use of the abstract model to convert the content in the framework into the abstract and output it.
2.4 Automatic Abstraction Based on Structure
The abstract words are usually regarded as top sentences which are related to many sentences in a network composed of sentences.The relationship between sentences can be judged by that of words or conjunctions.To a long article,it also can be regarded as a network of paragraphs.We can give each paragraph a feature vector,and take the inner product of these two paragraphs eigenvector as the connection strength of them.If the connection strength is beyond the given threshold,the two paragraphs have semantic links.Lastly,the central groups with the link to many segments are extracted to form an abstract of an article.
3.A Technique of Automatic Abstraction Based on Keyword Retrieval
3.1 Keyword Extraction
The algorithm model of keyword extraction puts the following into a full framework,such as word segmentation and part-of-speech tagging,text pretreatment,linear weighting algorithm,the formation and filtration of combined words,merging keywords,etc.And the two important data structures are the word information table the compound word information table.The generated combined words are not regarded as exceptions,but to give them value with the scientific method and take part in the competition with other words(the words made by the algorithm of linear weighting).Then we merge the two tables and get the ultimate keywords[5].
We first deal with text pretreatment,and the system of word segmentation and part-of-speech tagging,then use the algorithm of linear weighting.Through analyzing the frequency of the Chinese text,part of speech and the position of phrases,we quantize the weighting factor and calculate the value of each word.Then the candidate keys are extracted according to the size of value,and take them as the basis of final keywords.Based on the method of getting combined words by using linear weighted algorithm,we can get the second candidate keywords list.Finally the repeated items in these two tables are taken away,and the keywords are produced according to the right order of the size of value.Meanwhile,the number of keywords can be specified by users.
3.2 Algorithm of Automatic Abstraction
The algorithm of automatic abstraction first does the text segmentation by using segmentation tools[6];then it extracts the keywords,on the one hand,it stores the keywords according to the unit of paragraphs;each keyword is given different weights by the order of extraction(1.0,0.9,0.8),and the weight of each statement in every paragraph is calculated according to the value of keywords.Title,position and the length of sentences are also taken as the important factors of choosing abstracts besides word frequency.According to statistics,the chance of abstract words appearing on the title is around 95%,85%in the beginning of the paragraph,and 7%in the end of the paragraph.Therefore,the titles with keywords are directly seen as abstract words.The other statements are sorted by the order of weight,and the 5 sentences with the maximum weight in each paragraph are picked up as candidate key sentences.Then we select the abstract words considering the position and length of statements.Eventually the abstract of the whole thesis is formed.Specific processes are shown below:
4.Detection of Thesis Copying Based on Automatic Abstraction
4.1 Basic Thought
Because most papers take up the large space,it is time-consuming to compare them.Therefore,we first compare their abstracts and again compare whole text if they have a high similarity to find the contents suspected of plagiarism.But some authors offer too simple abstracts,no more than 200words;or the abstract is not too accurate.And to sum the full content of text is a good way to stress the key point.So here this paper deals with the themes with automatic abstraction and compare the abstracts so that the accuracy is improved.
4.2 Concrete Steps
Step 1:to segment the paper to be detected and the original one;
Step 2:to extract the keywords of the paper to be detected and the original one respectively and store them;
Step 3:to calculate and sort the weight of sentences in the paper to be detected and the original one respectively,and gen-erate automatic abstracts;
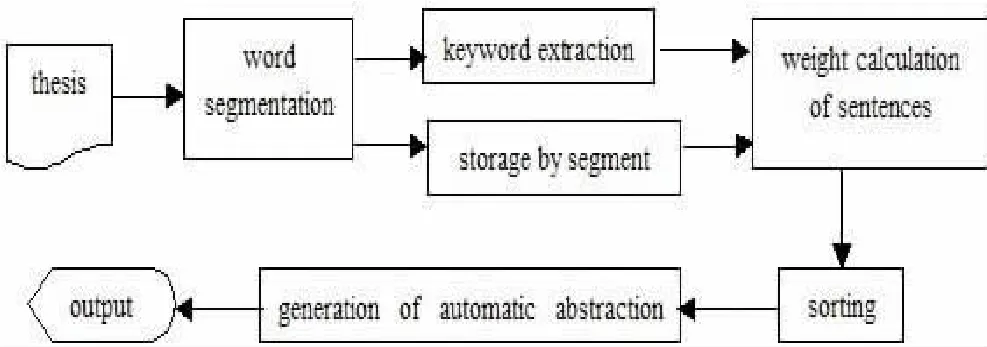
Figure1 Automatic Abstraction Based on Keyword Retrieval
Step 4:to compare the abstracts of the paper to be detected and the original one,calculate the similarity;to calculate the similarity of the abstract provided by the author and the automatic abstract;
Step 5:to suspect that it is a copy if the similarity is beyond 10%,make a further comparison between the whole text of the paper to be detected and the original one,output the copied contents.Otherwise,it is not thought as a copy.
4.3 Experimental Result
This paper designs the three copying files D1,D2,and D3 to act as the test samples.The proportions of plagiarism are about 20%,30%and 50%respectively.And the main purpose is to test that different proportions of plagiarism have an influence on the result of the comparison.The paper calculates the similarity by using word-frequency statistics,that is,to get the proportion of similar words out of the total words[7].Figure 2 is an interface of automatic abstraction system.Table 1 contains not only three copying files D1,D2 and their corresponding abstracts,but also the result of similarity between them and the original text,abstract and automatic abstracts.

Figure 2 Automatic Abstract for a Certain Document
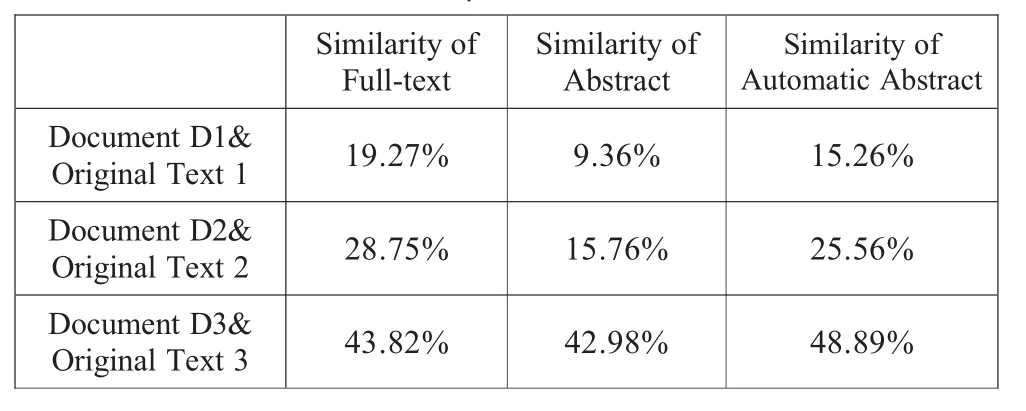
Table 1 Experimental Result
4.4 Basic Summary
From the experiment result we can see that the similarity of the whole text and automatic abstract is very close to the proportion of copying.But the abstract provided by the writer sometimes makes some errors due to the accuracy and the words of the abstract.The abstract generated by the automatic abstraction based on keyword retrieval can roughly summarize the text,replace text to be detected.Of course it's only a preliminary inspection;detailed text detection still needs to be done.
In addition,the keywords given by some authors are less and not very accurate.This system usually extracts 5-8 keywords,and they can reflect the theme of the text,so that the automatic abstract which is based on keywords retrieval is more accurate.
5.Conclusion
The a bstract with good quality can replace the retrieval position of the original text to a certain extent and act as an alternative to the retrieval,so that it can reduce the time spent on the information retrieval.The experts at home and abroad are always exploring an accurate and efficient algorithm of automatic abstraction.There is still something to be improved in this paper.Generally,the abstract is about 700 words in a paper with 7000 words.The more the words or paragraphs of the text are,the more the words of abstract are.Therefore,it is necessary to reduce the number of words,that is,within 500 words.We can combine a few paragraphs in the practice or pick up the key sentences for the unit of subtitle,not for the unit of paragraph.
[1]柴晓丽,自动文摘技术的研究与应用[D].硕士学位论文.长春理工大学,2006.
[2]黄丽琼,中文自动文摘及评价方法的研究[D].硕士学位论文.重庆大学,2007.
[3]郭燕慧,钟义信等,自动文摘综述,情报学报[J].2002,21(5):582~591.
[4]刘挺,王开铸,自动文摘的四种主要方法,情报学报[J].1999,18(1):10~19.
[5]张红鹰,基于模糊处理的中文文本关键词提取算法[J].现代图书情报技术,2009,(5):39~43.
[6]李荣陆,文本分类及其相关技术研究[D].博士学位论文.复旦大学,2005.
[7]赵俊杰,一种基于段落词频统计的论文抄袭判定算法[J].计算机技术与发展,2009,19(4):231~233,238.
