H.264运动估计硬件加速器的设计
2010-03-14李本斋吴从中陈家银
李本斋,吴从中,陈家银
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
1 引言
H.264标准的编码效率与之前的视频压缩标准相比有了明显提高,但这是以运算复杂度的增加为代价的。其中,可变块大小的全搜索运动估计的运算量在整个编码运算量中占约60%~80%。因此,如何提高运动估计的效率成为实时编码的关键。块匹配是运动估计最流行的方法[1],其基本思想是将图像序列的每一帧分成许多互不重叠的宏块,并认为宏块内所有像素的位移量都相同,然后对每个宏块到参考帧某一给定特定搜索范围内,根据一定的匹配准则找出与当前块最相似的块,即匹配块。匹配块与当前块的相对位移即为运动矢量。视频压缩时,只需保存运动矢量和残差数据就可以完全恢复出当前块。它被广泛应用于各种视频编码标准中,但算法复杂度和庞大的运算量一直是视频编码实时实现的瓶颈。因此,算法研究人员研究利用快速算法降低计算的复杂度,而硬件设计人员致力于利用并行流水线技术开发有效的硬件加速器。笔者对运动估计算法进行优化,提出了两种适合于硬件实现的运动估计算法,设计出合理的硬件结构和加速器,构建基于PowerPC的验证平台,并验证该加速器数据处理能力的正确性。
2 H.264运动估计算法优化
在H.264标准的搜索算法中[2],图像序列的当前帧被划分成互不重叠的16×16大小的子块,而每个子块又可划分成更小的子块,当前子块按一定的块匹配准则在参考帧中对应位置的一定搜索范围内寻找最佳匹配块,由此得到运动矢量和匹配误差。运动估计的估计精度和运算复杂度取决于搜索策略和块匹配准则,常用的匹配准则是MAD,因为它没有乘除操作,不需要做乘法运算,实现简单方便。通常使用求和绝对误差(SAD)代替MAD,(i,j)点的绝对误差值定义如下
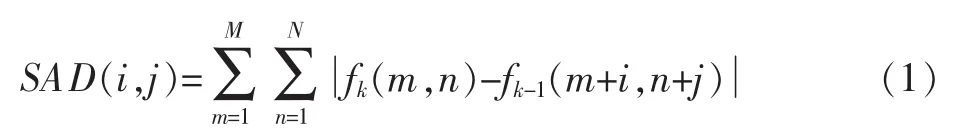
式中:(i,j)为运动矢量(MV)的坐标,fk和 fk-1分别为当前帧和上一帧图像的相应像素。将对应最小的SADmin的块用于预测。运动矢量定义为
为提高运动估计的效率,出现了很多快速搜索算法,如三步法、砖石搜索法、对数搜索和等级搜索等,这些算法减少了搜索点数,降低了运算量,但数据流的不规则性和估计运算时间的不确定性使它们很难在硬件中实现。目前,硬件设计人员多采用全搜索的方法[3],即搜索前一帧搜索范围内的所有可能搜索点,给出最佳匹配点和运动矢量,它具有规则的数据流,有很好的搜索效果,但庞大的运算量需要很多硬件资源,降低了处理速度。如编码 1 920×1 250@50 f/s(帧/秒)的图像,搜索窗为16×16 时,计算量约为:3×1 024×1 920×1 250×50=3 686.4×108次/秒(每秒3 686.4亿次的运算)。为减少计算量,现对运动估计算法进行优化,提出以下两种适合硬件实现的方法:
方法1:在搜索窗口内以步长2进行抽样搜索,即每隔1个像素点选1个候选宏块,根据匹配准则得到最佳匹配块和运动矢量,如图1所示。这种方法有规整的数据流,易于硬件实现,搜索精度会有所降低,但可减少一半的计算量。

图1 每隔1个像素抽样搜索
方法2:采用两步搜索:1)在搜索窗口内以步长4进行初定位,即每隔3个像素点选1个候选宏块,根据匹配准则得到初定位点。2)在初定位点相邻的4×4区域上进行全搜索,得到最佳匹配块和运动矢量,如图2所示,这种方法与全搜索相比约减少1-(1/4+1/16)=11/16的计算量。
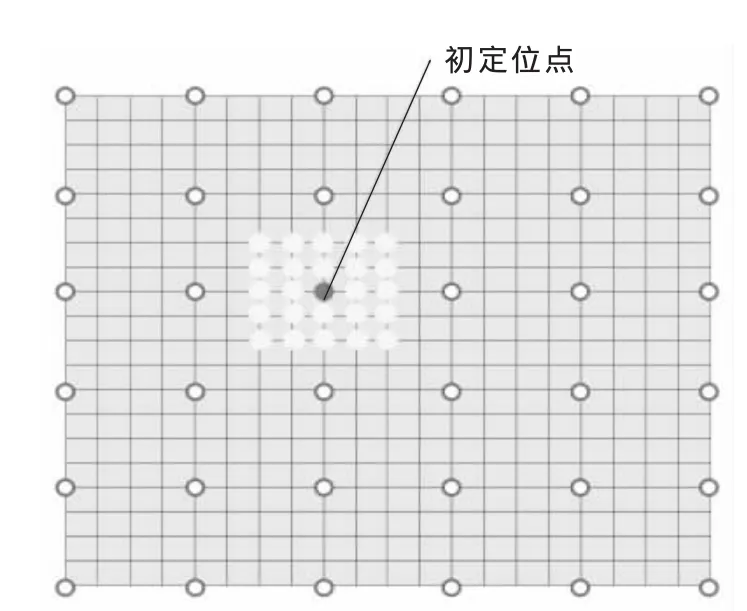
图2 初定位方式抽样搜索
3 块匹配运动估计结构及加速器设计
3.1 PE结构
图3为PE(Processing Element)的内部结构。PE处理单元[4]的设计通常是先对C(当前块)和S(参考块)进行差值绝对值运算,然后再将得到的结果直接与上次的SAD值累加。该PE结构主要由1个运算模块、1个SAD值的锁存器(Latch)、1个累加单元(ALU)和1个输出寄存器(REG)组成。运算单元主要完成C和S的绝对差值计算,将得到的SAD值锁存在Latch中,同时将当前存于Latch中的SAD值送入累加单元进行累加。当编码宏块数据被扫描完一次后,累加单元中的SAD值将被送入其他单元做进一步处理,并置累加器为0,进行下一次块匹配运算。

图3 PE结构
3.2 速度优先的硬件结构
在FPGA设计中,速度和资源是一对对立统一的矛盾体,要求一个系统同时具有较少的资源消耗和较高的运行频率是不现实的。速度和资源的互换常常在FPGA设计中被用到。图4中的速度优先的硬件结构[5]是以资源的牺牲为代价换取高的运行速度,同时数据带宽相应增加。该结构利用16个PA(PE Array)来并行完成1个匹配点的计算,每个PA由4×4 PE组成,这样就能同时产生16×16个当前块数据和搜索区数据的SAD计算,对于1个16×16搜索范围,256个搜索点采用全搜索需要256个周期完成,采用方法1需要128个周期,方法2只需要80个周期,有较快的运行速度。
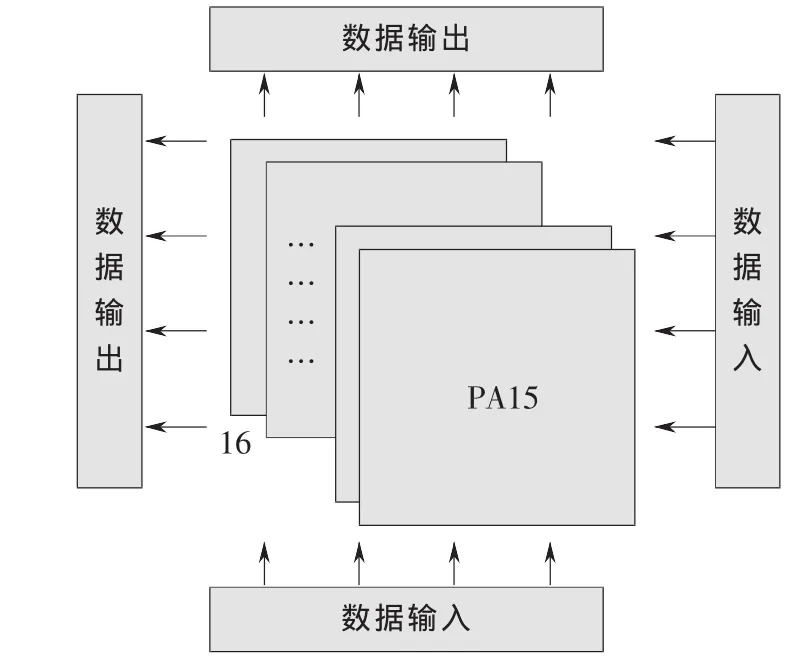
图4 速度优先的硬件结构
3.3 资源优先的硬件结构
图5中的资源优先的硬件结构是二维的脉动阵列结构[6],相比于前一种结构具有低硬件资源开销、存储带宽小的优点。利用4×4 PE阵列分时计算完1个16×16宏块的16个4×4子块,计算时,搜索区数据以总线方式输入到PE的缓存中,当前块数据由寄存器装入,16个PE输出的绝对差值,被一起送入并行加法器中得到1个4×4块的SAD。4×4 PE阵列每个周期计算1个4×4块的SAD,在16个周期内完成16个SAD值计算,累加得到16×16宏块的SAD值。对于1个16×16搜索范围,256个搜索点采用全搜索需要4 096个周期完成,而采用方法1需要2 048个周期,方法2仅需要1 280个周期。运行速度变慢,但所需资源和数据带宽都相应减少。
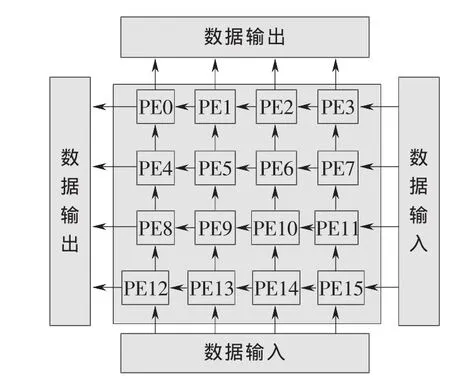
图5 资源优先的硬件结构
3.4 加速器总体设计
加速器[7]的总体结构如图6所示,包括存储模块、地址产生模块、PE阵列、控制单元和输出比较模块。存储模块用于缓存当前块和参考帧数据;地址产生模块产生读取所需数据的相应地址;PE阵列完成宏块的SAD值计算;控制单元完成整个处理过程的控制和调度。MVbest为搜索到的最佳运动矢量,SADmin是对应的最小SAD值。

图6 加速器总体结构
4 运动估计硬件加速器验证平台
笔者在Xilinx Virtex-II PRO开发板上对设计的硬件加速器进行验证,验证平台结构[8]如图7所示。其中,PowerPC405是1个32位的定点硬核,负责总线的调度和各个模块的协调工作;JTAG是调试接口,用于对程序的调试,系统有32 Mbyte的在片RAM和可扩展的DDR存储控制器,有PLB总线和OPB总线,可以通过总线桥进行数据交互。
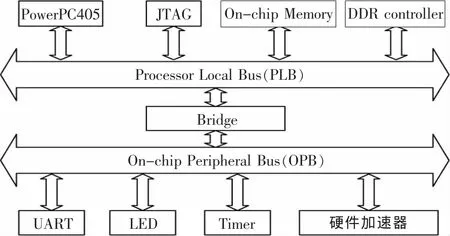
图7 验证平台系统框图
验证时,首先使用EDK10.2构建PowerPC的最小系统,然后将硬件加速器集成到该系统中,编译通过后由USB口下载到目标板,系统开始运行后通过RS-232从上位机下载待编码的图像数据,下载的数据保存在目标板上的256 Mbyte DDR SDRAM中。数据下载完毕后程序将待编码数据依次写入加速器并启动,并将处理完的数据再写入DDR SDRAM,待全部数据处理完毕,Power-PC将处理结果一起发送给上位机。上位机将结果与本机C代码执行结果相比较,最终确认硬件加速器的数据处理能力是否正确。
5 实验结果分析
将文中所提到的两种优化算法用foreman,football,news序列在AVC下与全搜索进行了对比,结果见表1。可见,方法1仅有平均0.45 dB的PSNR下降却减少了50%的计算量,方法2有平均0.67 dB的PSNR下降,减少了约68.7%的计算量。
当块尺寸为 16,搜索范围[-8,7],CIF@30 Hz时,对两种硬件结构的处理速度和资源消耗等性能进行了对比,结果见表2。

表1 优化算法与全搜索性能对比

表2 两种结构性能对比
本文对H.264运动估计算法进行优化,提出两种适合硬件实现的搜索方法,表1的实验数据表明,在不损失图像质量的同时,明显减少了运算量,提高了速度。同时与硬件相结合,给出速度优先和资源优先的两种结构,两种结构在速度和资源方面各有优势,设计出运动估计的硬件加速器,在Xilinx XUP Virtex-II PRO开发板中做了验证,结果表明该加速器能正确完成H.264运动估计的数据处理功能。
[1]毕厚杰.新一代视频压缩编码标准——H.264/AVC[M].北京:人民邮电出版社,2005.
[2]YANG KM,SUNM T,WU L.A family of VLSIdesigns for themotion compensation block-matching algorithm[J].IEEE Trans.Circuits and Systems,1989,36(10):1317-1325.
[3]CHENCY,HUANGCT,CHENYH,etal.LevelC+data reuse scheme formotion estimation with corresponding coding orders[J].IEEE Trans.Circuits and Systems for Video Technology,2006,16(4):553-558.
[4]王睿,林涛,林争辉,等.一种H.264运动估计器的VLSI设计[J].微电子学与计算机,2004(11):153-157.
[5]黄卫锋,桑红石,郑兆青,等.用于H.264的高性能整像素运动估计 VLSI的设计[J].微电子学,2007(4):260-264.
[6]CHENTC,HUANGYW,CHENLG.Analysisand design ofmacroblock pipelining for H.264/AVC VLSIarchitecture[EB/OL].[2009-12-20].http://ieeexplore.ieee.org/Xplore/login.jsp?url=http%3A%2F%2Fieeexplore.ieee.org%2Fiel5%2F9255%2F29377%2F01329261.pdf%3Farnumber%3D1329261&authDecision=-203.
[7]HSU Meiyun,CHANG Haochieh,WANG Yichu,et al.Scalable module-based architecture for MPEG-4 BMA motion estimation[EB/OL].[2009-12-20].http://ntur.lib.ntu.edu.tw/bitstream/246246/2007041910021255/1/00921053.pdf.
[8]石磊,林涛,焦孟草.H.264/AVC硬件解码器设计及其验证策略[J].微电子学,2006(2):16-19.
