一种支持H.264与AVS的高效环路滤波器设计
2011-03-15林衡芝张文军高志勇陈颖琪
林衡芝 ,张文军 ,高志勇,陈颖琪 ,毛 韧
(1.上海交通大学 电子工程系 图像通信与信息处理研究所,上海 200240;2.上海市数字媒体处理与传输重点实验室,上海 200240)
0 引言
H.264[1]和AVS[2]标准编解码环路中都引入了去块效应环路滤波模块,用于平滑由于运动补偿、变换及量化产生的虚假边界,从而提高图像质量。H.264的环路滤波基于4×4块边界滤波,先从左到右对垂直边界滤波,再从上到下对水平边界滤波。为适应高清视频应用,H.264采用了宏块级帧场自适应(MBAFF)、8×8变换编码等新技术以提高编码质量,但同时也增加了视频编解码实现的难度[3]。当采用MBAFF技术时,环路滤波以宏块对为单位,对当前宏块对滤波时,需要用到其左侧宏块对和上邻宏块对作为参考数据,并且当前宏块对与参考宏块对的编码方式可能不同。这不仅极大地增加了数据组织安排的难度,而且当上邻宏块对为场编码而当前宏块对为帧编码时,当前宏块对顶宏块的水平宏块边界需要滤波2次。当宏块采用8×8变换编码时,只对宏块内的8×8块边界滤波。AVS采用和H.264相同的滤波顺序对宏块内8×8块边界滤波。
近年来,关于环路滤波器硬件实现的研究很多。文献[4]采用2个较大的SRAM存储参考数据和中间数据,并按标准规定的滤波顺序实现AVS的环路滤波。文献[5-7]实现了H.264 BP的环路滤波。文献[5]采用二维的改进滤波顺序以减少片上缓存,提高滤波速度。文献[6]采用混合的滤波顺序和宏块分割等策略,以提高滤波中间数据重用率,减小片上缓存。文献[7]采用GoP(Group of Pixel)的数据组织策略,以避免数据的转置操作。文献[8]使用4个LoP(Line of Pixel)的一维滤波器并行处理,以逻辑资源换取滤波速度。文献[9-10]采用有效的Buffer管理机制,并将8×8块边界分割为2个4×4边界处理,从而实现对MBAFF技术和8×8变换技术的支持。文献[9]实现了H.264 BP/MP/HP的环路滤波,而文献[10]支持AVS,H.264,VC-1的环路滤波。
本文通过调整宏块滤波边界和合理地组织数据,实现了AVS与H.264环路滤波的复用;并通过优化滤波顺序和宏块分割等策略提高中间数据重用率,减少片上缓存;使用并行和流水处理技术提高滤波速度和最高工作频率。
1 滤波算法
1.1 宏块规整
H.264与AVS都以宏块为单位作环路滤波,但在不同情况下,宏块需要滤波的边界不尽相同。为实现滤波结构和滤波顺序的复用,对宏块的滤波边界作了规整。
对于AVS标准,所有的图像边界和条带边界不滤波;而对于H.264标准,所有图像边界和滤波禁用标志等于2时的条带边界不需要滤波。置图像边界和不需要滤波的条带边界对应的滤波强度Bs=0,采用相同的滤波结构和滤波顺序处理包含图像边界或条带边界的宏块。
对于采用8×8变换的宏块,H.264和AVS的环路滤波都仅对宏块内的8×8块边界滤波。把8×8块边界分割成2条4×4块边界处理,并置8×8块内部的4×4块边界的Bs=0,采用相同的滤波结构和滤波顺序处理8×8变换编码的宏块。
1.2 滤波顺序
定义当前宏块为帧编码而其上邻宏块为场编码的宏块为特殊宏块;除特殊宏块之外的所有宏块为标准宏块。则通过宏块规整后,每个标准宏块有48条4×4边界需要滤波,其中包括32条亮度边界和16条色度边界;而每个特殊宏块有56条4×4边界需要滤波,其中包括36条亮度边界和20条色度边界。
H.264和AVS采用相同的滤波顺序。对每个宏块,先从左到右对垂直边界滤波,再从上到下对水平边界滤波。结合本设计的特点,本文提出了一种新颖的混合滤波顺序。图1给出了标准宏块的滤波顺序,图2给出了特殊宏块的滤波顺序。采用这种滤波顺序,能够有效地简化设计,提高滤波中间数据的重用率,提高滤波效率。

1.3 宏块分割
为了减少片上缓存同时简化设计,本文将一个宏块分割为3个16×8块处理。如图3所示,将亮度块分割为2个16×8块,并将2个色度块合并为1个16×8块来处理。
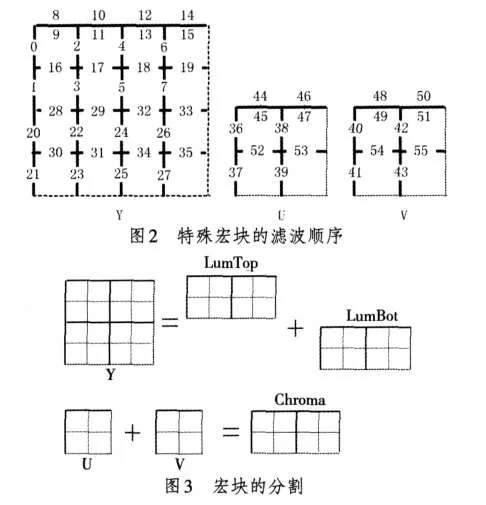
经过宏块分割后,标准宏块的LumTop,LumBot,Chroma以及特殊宏块的LumBot这4个16×8块的滤波顺序一样,滤波方法也类似,而且其中2个LumBot的滤波完全相同;特殊宏块的LumTop和Chroma这2个16×8块的滤波顺序和滤波方法也很相似。采用宏块分割策略后,可将环路滤波分为宏块级、16×8块级和边界级3个级别实现分级控制,整体结构清晰,易于设计与维护。
2 滤波结构
2.1 框架结构
本文提出的去块效应环路滤波器的总体结构如图4所示,图中主要描述了滤波的数据通路。
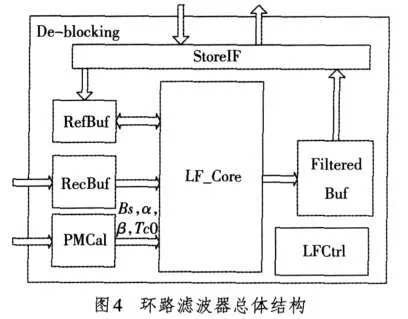
整个去块效应环路滤波器主要由以下7个子模块组成:
1)环路滤波主控(LFCtrl)
LFCtrl是整个环路滤波的主控系统,它实现宏块级和16×8块级的数据控制,并协调各个模块间的工作。
2)参数计算(PMCal)
PMCal计算滤波强度Bs、滤波裁减阈值α和β、滤波裁减参数Tc0。
3)滤波运算(LF_Core)
LF_Core是整个环路滤波器的核心模块,它从RecBuf模块、RefBuf模块和PMCal模块分别获得待滤波数据、参考数据和滤波参数,经环路滤波运算模块滤波后,将滤波后的数据存储到FilteredBuf模块以便回写到帧存储器中。滤波运算模块的内部结构如图5所示,它由数据流控制器DataFlowCtrl、一维滤波器OneDFilter、临时存储器TempBuffer、复用选通MuxP和MuxQ、转置直通TransDirP和TransDirQ、输出接口OutputIF等8个子模块构成。

DataFlowCtrl是滤波运算模块的数据流控制器,实现边界级的数据控制。OneDFilter是滤波处理的运算单元。它由2个LoP(Line of Pixels)的一维滤波器组成,并行处理2行像素的滤波;而每个LoP滤波器采用AVS标准滤波、AVS强滤波、H.264标准滤波、H.264强滤波和不滤波5种滤波模式的并行结构,并使用4节拍的流水处理。TempBuffer使用2个8×64 bit的双口RAM以存储16×8块的滤波中间数据,并设置了输入输出数据转接口以实现数据的帧场格式转换功能。MuxP和MuxQ用于OneDFilter的P端口和Q端口数据选通。TransDirP和TransDirQ依据滤波的需要对滤波后的数据作转置或直通到下一子模块处理。OutputIF是滤波运算模块与其他模块的输出接口,实现数据格式转换的功能。
4)重建参数缓存(RecBuf)
RecBuf采用乒乓Buffer的形式存储从重建模块接收的待滤波数据,并在主控LFCtrl控制下将待滤波数据送往LF_Core模块滤波。环路滤波基于宏块进行,同时考虑到模块间的流水,重建参数缓存RecBuf的大小为2×48×64 bit。
5)参考数据缓存(RefBuf)
RefBuf存储左侧宏块(对)和上邻宏块(对)的参考数据,并在主控LFCtrl控制下将参考数据送往LF_Core模块参与滤波。
对于AVS和H.264的非MBAFF情况,左侧参考数据为左侧宏块右侧的8个4×4小块(包括4个亮度块和4个色度块);对于H.264的MBAFF情况,滤波基于宏块对进行,左侧参考数据为左侧宏块对右侧的16个4×4小块。当前宏块(对)作为下一宏块(对)参考数据部分,在滤波后直接存储于左侧参考数据缓存中。由于当前宏块对和左侧宏块对的编码方式可能不同,为方便数据读取采用128 bit的宽度存储数据,另外,为实现流水处理采用乒乓Buffer,故左侧参考数据缓存大小为32×128 bit。
对于AVS和H.264的非MBAFF情况,上邻参考数据为上邻宏块底部的8个4×4小块(包括4个亮度块和4个色度块);对于H.264的MBAFF模式,滤波以宏块对为单位,上邻参考数据与上邻宏块对和当前宏块对的编码方式有关,图6给出了field/field,field/frame,frame/field和frame/frame这4种不同情况下的上邻参考数据。因此,上邻参考数据需要存储上邻宏块对的16个4×4小块。上邻参考数据由滤波模块向帧存储器申请获得,或者为当前宏块对的顶宏块滤波后数据。由于本文滤波按16×8块进行,上邻参考数据缓存同时也作为部分数据的中间数据存储器。为实现流水处理,同样采用乒乓Buffer实现,上邻参考数据缓存大小为2×16×128 bit。

6)滤波后数据缓存(FilteredBuf)
FilteredBuf用于存储滤波后的数据,包括当前宏块(对)和上邻参考数据。
7)数据回写接口(StoreIF)
StoreIF为滤波模块和帧存储器的接口模块。
2.2 滤波过程
本文将系统分为宏块级、16×8块级和边界级3个不同级别,使用LFCtrl和DataFlowCtrl控制器实现三级控制,其中LFCtrl实现宏块级和16×8块级的控制,而LF_Core中DataFlowCtrl实现每个16×8块的边界级控制。在宏块级,将滤波过程分为数据准备、参数计算与滤波运算、数据回写3个部分并行流水处理;在16×8块级,环路滤波将每个宏块分为3个16×8块来处理,标准宏块通过实现LumTopNor,LumBot和ChromaNor这3个16×8块完成滤波,特殊宏块通过实现LumTopSpe,LumBot和ChromaSpe这3个16×8块完成滤波;LF_Core完成对每个16×8块的滤波,边界级的控制由其中的DataFlowCtrl子模块实现。
下面主要以LumTopSpe为例介绍滤波的过程。通过算法分析,对于特殊宏块的水平宏块边界需要滤波2次。按照图2的滤波顺序对LumTopSpe块滤波,首先对垂直边界0~7滤波,边界0~1的左侧参考数据从RefBuf中取得,而边界2~7的左侧参考数据为边界0~5右侧数据滤波后的中间数据;边界右侧数据为从RecBuf中获得的待滤波数据。垂直边界滤波后,左侧参考数据输出到FilteredBuf中,而待滤波数据经TransDir转置后暂存至TempBuffer。当垂直边界滤波完成后,开始对水平宏块边界8~15滤波,水平宏块边界的上邻参考数据从Ref-Buf读取,而其下邻待滤波数据为转置后的场格式4×4小块。转置由TransDir模块实现,数据的帧场格式互换由TempBuffer中的输入输出数据转接口控制实现,由于待滤波数据在垂直边界滤波完成后为帧格式,而水平宏块边界用到的待滤波数据为场格式,因此在这里使用了帧到场的格式变换。水平宏块边界滤波完成后,上邻参考数据经转置后输出,而当前宏块的滤波中间数据再次存储于TempBuffer中。最后,对宏块内部的水平边界16~19滤波,边界两边数据均从TempBuffer中读取。Temp-Buffer中的数据为场格式,而宏块内部水平边界使用的数据为帧格式,因此待滤波数据读取的同时作了场格式到帧格式的转换。滤波完成后,将作为下一宏块左侧参考数据和下一个16×8块的上邻参考数据部分存储到RefBuf中,其余部分输出到FilteredBuf。
3 仿真结果与分析
使用Verilog语言实现RTL级的设计;使用Synopsys Design Compier工具,用65 nm CMOS工艺库,在200 MHz的工作频率下进行综合,电路规模大约为43 k门,片上缓存为1 152 byte。
采用64 bit的带宽,待滤波数据的读入需要48个时钟周期,参考数据的申请需要32个时钟周期,宏块对及其上邻参考数据的回写需要128个时钟周期。而1个标准宏块的滤波时间为131个时钟周期,其中有效滤波为96个时钟周期;1个特殊宏块的滤波时间为147个时钟周期,其中有效滤波为112个时钟周期。Bs的计算用了35个时钟周期。本设计采用了并行流水策略,故完成1个标准宏块的滤波需要166个时钟周期,完成1个特殊宏块的滤波需要182个时钟周期。最坏情况下,每4个宏块有1个宏块为特殊宏块,其他3个宏块为标准宏块,此时1个宏块平均滤波时间为170个时钟周期。当工作在200 MHz时,本文的结构能够支持2路H.264或AVS的1 080p@60 f/s的实时解码。
将本设计与参考文献中的几种滤波器的性能进行了对比,数据见表1。文献[4-9]仅能支持一个标准的滤波,而本设计能够同时支持AVS标准和H.264标准的滤波;与文献[10]支持多标准的滤波器相比,本设计在系统资源增加不多的情况下,极大地提高了滤波的速度,具有更大的数据吞吐量。注意:滤波面积不包含输入缓存、输出缓存、Bs计算以及片上缓存面积;片上缓存不包含输入缓存和输出缓存;N为一宏块行的行块数。
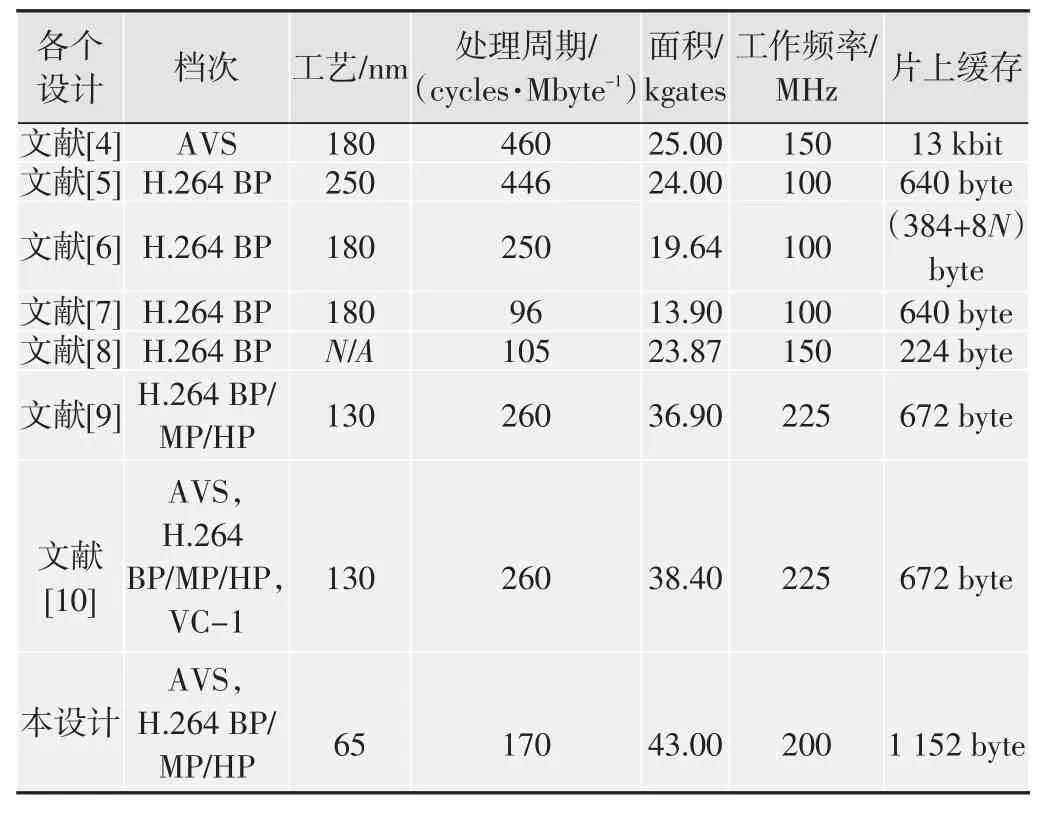
表1 几种滤波器的性能对比
4 结论
本文提出了一种支持H.264 BP/MP/HP和AVS的高效去块效应环路滤波器的硬件实现结构。通过调整宏块滤波边界和合理地组织数据,实现了H.264 BP/MP/HP和AVS的环路滤波结构的复用,并通过优化滤波顺序、宏块分割、并行流水处理等技术减小片上缓存,提高了滤波效率。
[1]International Telecommunication Union.ITU-T recommendation H.264:advanced video coding for generic audiovisual services[S].2005.
[2]GB/T 20090.2——2006.信息技术先进音视频编码第2部分:视频[S].2006.
[3]于小燕,赵不贿,郑博,等.基于FPGA的H.264帧内预测算法研究[J].电视技术,2010,34(5):40-43.
[4]SHENG B,GAO W,WU D.A platform-based architecture of loop filter for AVS[EB/OL].[2010-08-20].http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=1452726.
[5]SHENG B,GAO W,WU D.An implemented architecture of de-blocking filter for H.264/AVC[EB/OL].[2010-08-20].http://www.jdl.ac.cn/doc/2004/An%20Implemented%20Architecture%20of%20Deblocking%20Filter.pdf.
[6]LIU T,LEE W,LIN T,et al.A memory-efficient deblocking filter for H.264/AVC video coding[J].IEEE International Symposium on Circuits and Systems,2005,3:2140-2143.
[7]LIN H,YANG J,LIU B,et al.Efficient deblocking filter architecture for H.264 video coders[EB/OL].[2010-08-20].http://www.arnetminer.org/viewpub.do?pid=430041.
[8]LOUKIL H,BEN ATITALLAH A,MASMOUDI N.Hardware architecture for H.264/AVC deblocking filter algorithm[EB/OL].[2010-08-20].http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=4956713.
[9]CHIEN C,CHANG H,GUO J.A high throughput in-loop de-blocking filter supporting H.264/AVC BP/MP/HP video coding[C]//Proc.IEEE APCCAS.Macao,China:IEEE Press,2008:312-315.
[10]CHIEN C,CHANG H,GUO J.A high throughput de-blocking filter design supporting multiple video coding standards[C]//Proc.2009 IEEE International Symposium on Circuits and Systems.[S.l.]:IEEE Press,2009:2377-2380.
