一种处理混合型属性的聚类算法在计算机取证中的应用
2010-02-25陈德礼陈俊杰
黄 斌, 史 亮, 陈德礼, 陈俊杰, 周 超
(1.莆田学院电子信息工程系, 福建 莆田 351100;2.厦门大学软件学院, 福建 厦门 361005)
0 引言
计算机动态取证是将取证技术结合到防火墙、人侵检测中,对所有可能的计算机犯罪行为进行实时数据获取和分析,智能分析人侵者的企图,采取措施切断链接或诱敌深人,在确保系统安全的情况下获取最大量的证据,并将证据鉴定、保全、提交的过程[1,2].
数据挖掘是一种特定应用的数据分析过程,可以从包含大量冗余信息的数据中提取出尽可能多的隐藏知识,从而为做出正确判断提供基础.因为具有高度自动化的特点,数据挖掘技术已经被频繁应用于与计算机取证领域相近的入侵检测领域的研究中,用于对海量的安全审计数据进行智能化处理,目的是抽象出利于进行判断和比较的特征模型.
K-Means算法作为一种数据挖掘中常用的聚类算法,在大数据集处理上具有较好的可伸缩、高效性和良好的扩张性,因此可以考虑将其应用于计算机取证中,但K-means算法无法处理符号类型的数据,而在计算机取证领域中,所要处理的数据往往混合型.通常的解决方法是转换符号类型数据为数值,例如直接数值映射方法:protocol_type属性里有一般有icmp、tcp、udp等多种可能的取值,直接映射方法是将protocol_type属性的取值直接映射为一个自然数的集合,icmp取值为1,tcp取值为2,udp取值为3,…,以此类推.这种方法简单易行,但存在着一定的问题:容易对算法造成误导,错误地认为该类型特征之间存在着大小关系.
针对基于聚类的计算机取证技术中所存在的不足,本文采取对符号类型特征进行数值域的映射,并使用主成分分析对数值映射后增加的维数进行降维.其基本思想是对于有m种不同取值的符号特性,用m比特对其进行编码,当且仅当特征取值为第i种值时,其码字中的第i比特为1,其余比特为0.编码映射实际上是将原始的具有多种取值的符号类型特征转换为多个具有布尔取值的新特征,通过编码映射将重要的符号型属性转化为数值型,再利用主成分分析进行降维,从而克服单纯使用聚类分析数据集中数值型属性的不足,提高取证效果.
1 基于聚类的计算机取证技术
聚类是数据挖掘中重要的一类方法,聚类分析的方法是指将物理的或抽象的对象分成几个群体,在每个群体内部,对象之间具有较高的相似性,而在不同的群体之间相似性则比较低.一般一个群体也就是一个类,但与数据分类不同的是聚类结果主要是基于当前所处理的数据,我们事先并不知道类的结构及每个对象所属的类别,可以不依赖预先定义的类和带类标号的训练实例来完成数据集的划分,因此基于聚类分析的计算机取证技术可以通过对未标识数据进行训练来检测异常数据,并能够自适应地确定算法参数.该方法不需要手工或其它的分类,也不需要进行训练,因此能发现新型的和未知的异常行为.
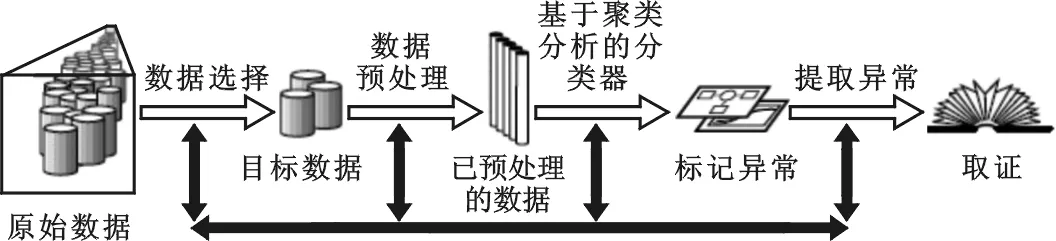
图1 基于聚类分析的计算机取证过程
一般的网络环境下正常数据规模是远远大于入侵行为数目的,由此可以假设正常行为的类的数据的数量远远大于各种体现攻击行为的类的数据的数量,同时,我们认为同一个类的实例都是具有相同类别的实例,聚类算法所得到的划分就能够区分正常与异常行为.计算每个聚类的实例个数占训练集实例个数的比例,将比例最大的聚类标记为正常,而将其它的聚类标记为异常,从而进行计算机取证.
2 混合型属性处理方案
计算机取证中数据是混合型数据集,包含了数值型和符号型的数据.在聚类前的数据预处理过程中,我们对符号型的属性进行编码映射,将原始的具有多种取值的符号类型特征转换为多个具有布尔取值的新特征,编码映射保留了符号类型特征不同取值之间的本质特征,编码映射后会增加数据集的维数.为了解决这个问题,我们在编码映射的基础上引入主成分分析从而达到降维的效果.而对于数据集中的数值型属性特征,由于一些度量单位的不同,造成属性值之间差异很大,所以在进行聚类分析之前我们必须采用标准化与正规化处理.
2.1 符号型数据的转化
符号类型特征虽然与离散类型特征比较相似,但又与之不同.离散特征之间具有大小的关系,而符号类型特征之间却没有.例如:对于“协议类型(protocol_type)”特征,一般有icmp、tcp、udp等多种可能的取值.各种取值之间只有相同或者不同的关系而没有大小的区别.对于它们的处理,显然应该与离散类型特征有所区别.
为了便于聚类算法的处理,在预处理阶段需要对符号类型特征进行数值域的映射,本文采用下面编码映射方法.其做法是:对于有m种不同取值的符号特性,用m比特对其进行编码,当且仅当特征取值为第i种值时,其码字中的第i比特为1,其余比特为0.例如对特征service,如果其取值仅为http、telnet、ftp、imap4、finger、netstat、gopher这7种,而特征protocol_type只有icmp、tcp、udp这3种取值,则对每个取值可以做如表1所示的编码.

表1 对符号特征的编码映射
编码映射与直接数值映射法相比,编码映射保留了符号类型特征不同取值之间的本质特征,不会对学习算法造成误导,但同时如果针对一些取值很多符号类型,要完成编码需要的比特位数也会很长,如此会造成维度大幅度增加的结果.本文用主成分分析来处理编码映射后增维的问题,从而达到了降维的目的.
2.2 主成分分析
主成分分析(PCA)是一种熟知的特征抽取方法[3,4].通过计算样本协方差矩阵的本征矢量,PCA线性地将输入空间映射为低维的特征空间,且新的特征互不相关.PCA的主要思想是降低数据集的维度,并尽可能保持数据集的信息.
我们对编码映射后生成的矢量进行PCA主成分分析,将能充分表征原来映射后生成的矢量主成分与计算机取证数据中的数值型数据一起进行聚类分析.
我们设计的基于PCA技术的符号型数据编码映射生成数据集的特征提取方法的实现算法如下:
步骤1: 设1行m列的矩阵νi1,νi2,…,νimOi表示1条计算机取证原始数据中所选的符号属性经过编码映射后的生成值.计算机取证数据集中共有k条数据,i=1,2,…,k.根据原始矩阵Oi求出相关矩阵Xi,其中Xi为m阶方阵.初始化,设i=1.
步骤2: 求出xi的m个特征值(按由大到小的顺序)以及相应的正交标准化特征向量νi1,νi2,…,νim,其中νi1,νi2,…,νim均为n行列向量.
步骤3: 以νi1的各个分量作为系数,求出各变量的线型组合,得到第一主成分.以νi2的各个分量作为系数,求出各变量的线型组合,得到第二主成分.以此类推,通过νim得到第m个主成分.
步骤4: 设i=i+1,重复步骤1、步骤2、步骤3,当i=k时,算法终止.
通常取前3个主成分就基本能包含或者代表了原有数据集的全部信息,所以我们基于此对原数据进行缩减.通过主成分分析,可以得到数据集中较大权重值所对应的变量项,找出在权值上发生较大变化的变量项,作为主成分分析后新生成的数据集的主干变量项,在考虑其余变量项的实际意义的基础上,适当去掉影响较小的变量项,从而得到一个全新的数据集,起到降维作用.
3 实验结果
在本文中,我们采用的数据集来自于KDD Cup 1999[5],该数据集包含了4大类入侵类型,即PROBE、R2L、U2R和DoS.首先对KDD CUP 99数据集进行抽样,按照一定概率随机抽取5个抽样数据集,其中前4个子集中各含一类攻击,第5个子集中的入侵为混合型.各数据集的样本数接近10 000条.
表2详细地列出了各种类型数据的抽样概率和抽取的样本数,以及异常攻击数据所占的百分比.本文的抽样方法是对每一条数据生成一个随机概率,如果该随机概率小于我们所设置的抽样概率比例,就抽取这条数据,否则不抽取.因此,在多次抽样的过程中,虽然某些具体攻击类型赋予了确定的抽样概率比例,但是仍然可能每次抽取的样本数目不一样,甚至可能没有抽到数据,如表2,DOS攻击类型中的pod攻击,虽然抽取概率是0.03%,但是仍然没有抽取到样本.

表2 抽样KDD-CUP-99的各种类型攻击数据集
从表2可以看出,DOS、Probing和R2L攻击的异常数据百分比在1%到1.5%之间,但是U2R攻击的异常数据百分比小于1%,且都是以100%的概率抽样,这是由于U2R攻击类型的数据在KDD CUP 99数据集中较少的缘故,尽管以全概率进行抽样,但是U2R异常攻击的百分比比例还是较小.
数据集中不是每个属性都对取证的结果有贡献,Srinivas Mukkamala等人利用支持向量机方法通过实验指出在KDD Cup 1999数据集中有13个属性最为重要[6],因此我们选取这13个属性,并对符号型属性service和protocol_type进行编码映射(见表1),再对其进行主成分分析,最后使用K-Means算法对新的数据集进行聚类,同时我们也做了只对11个数值属性进行聚类分析的仿真实验,两者结果如表3所示:
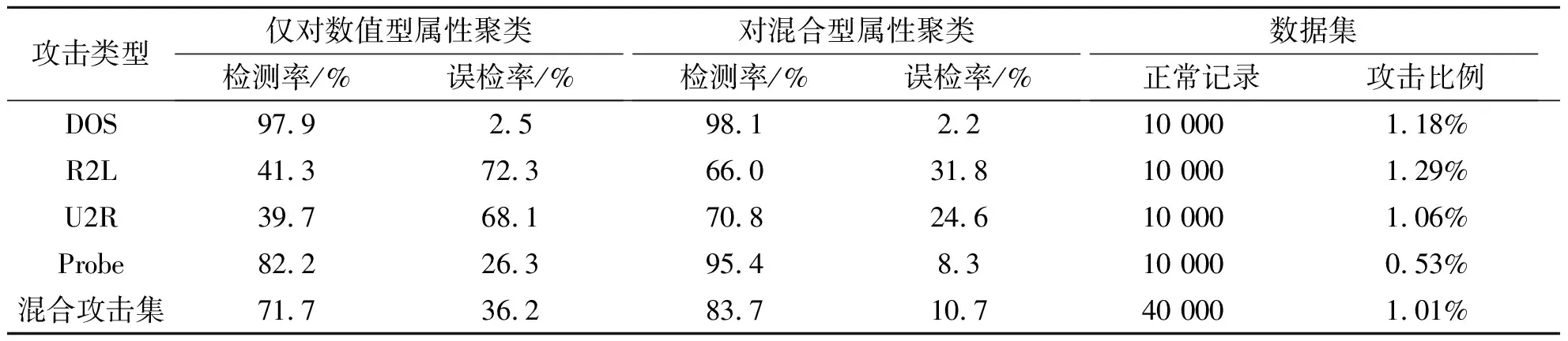
表3 实验结果比较
从实验结果我们可以看到,在计算机取证中对网络连接记录中的符号型属性采用编码映射与主成分分析结合的方法,无论在4类攻击类型还是混合攻击类型上的检测率都要比单纯对数值型属性聚类进行异常检测的高,而且在误检率上也有大幅度降低.
4 结束语
本文分析了聚类在计算机取证中的应用,针对目前基于K-Means算法的计算机取证技术所存在的对符号类型数据处理能力欠缺的问题提出了一种处理混合型属性的聚类算法的计算机取证技术,采用编码映射处理符号型数据,并利用主成分分析来实现降维,最后在KDD99实验数据集通过聚类分析进行了仿真实验,实验结果证明采用这种方法能够取得较高的检测率与较低的误检率.下一步工作是改进方法提高R2L和U2R这2类攻击的检测率.
参考文献
[1] 张 俊,麦永浩,龚德忠. 计算机取证的时间分析方法[J]. 湖北警官学院学报, 2009,(2):67-70.
[2]米 佳, 何 平, 汪晓峰. 基于广义数据挖掘的计算机取证技术[J]. 中国人民公安大学学报(自然科学版), 2008,(3):52-55.
[3] Jian Yang, David Zhang, Alejandro F Frangi,etal. Two-dimensional PCA: a new approach to appearance-based face representation and recognition .IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26 (1):131-137.
[4]R. B. W. Wang. Identifying Intrusions in computer networks with principal component Analysis[C].Proceedings of the First International Conference on Availability, Reliability and Security,2006.
[5]KDD99 Cup dataset, http://kdd.ics.uci.edu/ databases/kd- dcup99/kddcup99.html.[DB/OL].
[6]黄 斌,史 亮,陈德礼.一种基于聚类和关联规则修正的入侵检测技术[J].莆田学院学报,2009,(2):41-44.
