数字图书馆读者信息挖掘系统构架的建设
2010-02-09张智刚郭淑艳
张智刚,郭淑艳
(吉林大学农学部图书馆,吉林长春 130062)
随着信息技术的不断发展和普及,图书馆作为一个信息情报资源中心,积累了大量的数据。以一个中小型图书馆为例,其馆藏图书量大约是50万册,电子书刊可能接近5~10T,信息数量可以达到几千万条。由于数据库技术的日臻成熟,在如此海量的数据库中查找读者所需的资料已经不是什么问题。可我们的数据库是在不断更新的,每天都会有大量的图书和电子期刊到馆入库。怎么才能让读者及时地了解到图书馆的最新资料?如何判断这些新资料会不会成为某些读者的需要?我们研究的目的是:建立一条读者与海量资源的桥梁,满足不同读者的不同需求,实现信息利用的通畅和最大化。
数据挖掘技术为我们指明了解决这一问题的方向。自从1989年第11届国际联合人工智能学术会议上首次提出K DD这一概念以来,信息挖掘技术日益受到人们的关注,并己经成为当前计算机领域的一大热点,其研究的重点也逐渐从发现方法转移到系统应用,并且注意多种发现策略和技术的集成以及多学科之间的相互渗透。现今,数据挖掘的应用领域越来越广泛,从早期的商业应用,发展到科学研究、电子商务、产品控制、金融行业、教育教学等多个领域。我们可以利用数据挖掘相关方法和理论,对读者信息进行分析和处理,对读者需求作出一个量化的定义。根据这一定义去搜索图书馆的海量资源,将符合读者需求的资源提取出来推送给读者,实现上述我们的理想目标。
1 读者信息域的设想及组织形式
根据设想,我们从读者信息着手分析。在传统的图书馆中,读者信息比较简单直白,包括姓名、性别、年龄、单位、联系方式等信息。这些信息只能反映出读者的自然情况以及读者和图书之间的借还关系。为了更好地表达出读者的需求和特点,在这里我们引入读者信息域的概念。其定义为:能够表述读者特征的主题词的多维集合。
首先,信息域是一个集合,只要是能体现读者特点的主题词均可加入该集合,包括读者的自然情况属性。世界上的信息纷繁复杂,数量极其庞大,我们不可能将所有的信息点均用于表达读者的特点,而应将庞大的信息群按照某种规则进行分类,提取每个类或者其子类的主题词。根据主题词出现的频度和类目的深度,有计划地将主题词填充到信息域中,用以表达读者的特征状态。
其次,集合中存在多维结构,每一维体现出读者的一个特点。一个读者的兴趣特点可能是多方面的,我们不可能将表达读者兴趣的关键词一律添加到信息域中去,而应将关键词以某种形式组织起来添加到集合中去,以免引起集合中的关键词的混乱。这里我们设计了一种放射性的树形多维组织形式,如图1所示:
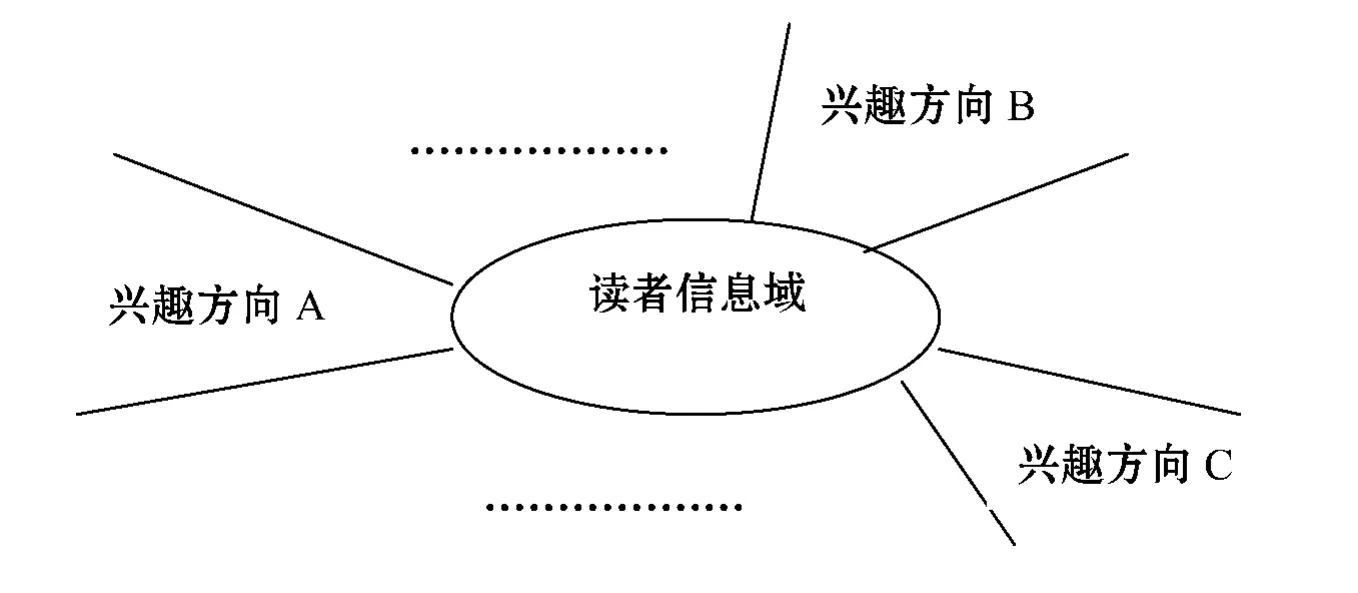
图1 信息域结构
每个特征兴趣方向均可以看作是一“维”,它是由一棵关键词树组成的,表达读者对该方向的详细兴趣点。
最后,“维”与“维”之间不存在交叉,“维”具有权重属性。信息域中每个关键词存在唯一性和代表性。为了不产生歧义和提高效率,我们不能将重复或意义相近的关键词添加进来。可见“维”与“维”之间一定是不存在交叉的。一个人的兴趣是多方面的,而每个兴趣的浓厚程度显然不是完全一样的。我们为每一个维设定一个权重值,用来表示读者对该特征兴趣方向的重视程度。体现出读者对哪些方面的内容更感兴趣。
信息域可以看成是主题词表的子集。既然是集合的一种,我们可以对信息域进行逻辑运算。“与”表示取两个读者的共同特点,“或”表示取两个读者的所有特点,“非”表示读者不感兴趣的信息。可以通过设定“维”的限制关系,来对读者进行分类、筛选等更为复杂的逻辑运算。如:可以设定“心理学兴趣方向”为限制条件,通过查询会很容易将兴趣相近的读者统计出来。图书馆工作者可以组织读者联谊活动,为兴趣爱好相同或相似的读者提供交流促进的机会,也可以统计出读者群兴趣度列表,根据兴趣度的高低,来指导图书馆资源的摆放顺序、新资源采购的侧重点。
2 读者信息处理及挖掘设想
读者信息这里主要指读者行为记录。作为一个数字图书馆,其管理系统应对读者行为进行详实的记录。如:读者出入馆时间、借阅记录、期刊查阅记录、论文下载阅读记录等。显然,这些记录是海量的,从某种角度说是杂乱无章的。我们的目的就是从这些海量的看似杂乱无章的数据中提取出读者的兴趣特点,把这些特点填充到读者的信息域当中去。
从海量记录中提取读者特征的过程就是数据挖掘的过程,或者说是发现知识的过程。借鉴数据挖掘的相关理论方法,我们可以按照以下步骤进行:
首先,进行“数据清洗”。读者行为记录中难免有些错误或冗余的记录,这些记录进入挖掘流程势必会影响结果的准确度。如:借还间隔只有几分钟,说明读者可能拿错了书;几分钟内下载了多次相同的文献,显然这会产生多条冗余的行为记录。针对上述的错误数据、冗余数据,我们应当编写一种“清洗”算法将他们过滤掉。
其次,进行数据格式上的统一调整,生成数据仓库。由于各类读者行为记录格式不尽相同,借还记录可能只有图书编号、读者编号、借还时间等,下载记录可能会有下载编号、读者编号、时间等。为了适应统一的挖掘算法,必须将原数据进行格式上的调整,生成标准的数据格式,存储于数据仓库中。
最后,设计挖掘算法,进行挖掘计算,得到读者特征值并填写到读者信息域中。挖掘算法是系统的关键。国内外对文本信息的挖掘算法很多,我们可以选取其中比较成熟的算法作为核心算法,后面适当调整输出知识的形式,填写到信息域中。
通过以上信息处理和挖掘过程,读者信息域建立完毕。下面我们来讨论读者信息域的开发利用及修正。
3 读者信息域的利用与修正
为了建立读者和海量资源的快速通道,现在读者的特征已经数字化,而某条信息资源也有自己的关键词集合。我们拿读者域和关键词集合进行基于关联规则的运算,就能得到一个反映相关度的数值I。根据I的大小判定该读者对这条信息资源的兴趣程度。我们可以把I的值域划分成若干等级,不同等级采取不同的服务方式。若I值非常大,我们可以采用即时通信的办法将该信息资源立即推送给读者;若值比较大,我们可以发送邮件等方法将资源推送给读者。这样图书馆的服务模式就发生了质的转变,从原来的被动等待读者寻找资源,转变为资源主动寻找读者,实现了资源利用的最大化。
读者信息域不是一成不变的,它应该根据读者兴趣的转移而发生相应的变化。这就必须设定一套信息域的修正方案。最简单的办法是,以权值W作为衡量读者对某个兴趣方向的重视程度。影响数值大小的因素应该包括:读者访问次数、近期访问频度、读者自定义等。读者访问某类资源的次数越多,证明对该资源的感兴趣程度越浓。近期访问量也是衡量读者兴趣变化方向的重要指标。虽然总的访问量可以证明读者的兴趣浓厚,但也许是该位读者几年前的兴趣所在。这就要求我们还应该统计近期读者的访问情况,适当修改W数值,体现出读者兴趣的最新变化情况。
为了系统的优化考虑,信息域必须具有“减肥”能力。任凭信息域集合的不断壮大和发展,势必产生过时的数据。当某个“维”在某个时间范围内读者都没有访问过,我们就可以认定读者已经失去对该方向的兴趣,可以作出删除处理。通过修正方案的定期执行,我们就能基本上跟踪掌握读者的最新动态,从而为读者服务提供更强大的支持。
4 结束语
读者和数字图书馆资源是一对矛盾。图书馆人应当从读者角度考虑问题,创造性地开展新业务、新服务,解决好这一矛盾。本文从规范化、标准化的角度考虑读者服务模型,力求建立一套数字图书馆读者信息挖掘平台。目前针对读者信息挖掘的方法、算法很多,但各类系统互不兼容。希望统一格式的读者信息表达模块——信息域能够起到相互联络、共享信息的作用,以利于各系统的互补,提高读者服务能力和图书馆建设水平。
[1]雷刚.个性化数字图书馆研究[D].成都:四川大学,2008.
[2]刘璇.数字图书馆的个性化知识服务研究[D].大连:辽宁师范大学,2008.
[3]王创新.关联规则提取中对Apriori算法的一种改进[J].计算机工程与应用,2004(34).
[4]李康顺,李元香,滕冲.遗传算法在数据挖掘中的应用[J].计算机工程与应用,2005(9).
