第三讲:如何报告观察性流行病学研究
——国际报告规范STROBE解读
2010-01-25詹思延
詹思延
观察性研究是相对于实验性研究而言的,指研究者不对被观察者的暴露情况加以限制,通过现场调查分析的方法,客观地记录某些现象的现状及相关特征,进行流行病学研究,主要用途是描述疾病或健康状况在人群中的分布,探索和检验疾病与暴露之间的因果关联。与RCT相比,观察性研究中研究对象所具有的各种特征是客观存在的,研究者不能随机分配研究因素予观察对象,只能靠全面、客观的描述或精心设计的方案对人群现象进行分析、比较、归纳和判断,以揭示事物之间的联系。这类研究设计通常容易实施,医学伦理学问题较少,但研究中可能存在多种偏倚,影响结果的真实性。因此,在评价任何一个观察性流行病学研究结果时,主要的问题是判断观察到的暴露与疾病之间的关联是否由偏倚、随机误差或混杂所造成。毫无疑问,清晰透明的研究报告有助于读者的阅读和评价,但近年来国内外的研究都发现,此类报告普遍存在不完整和不规范的问题[1,2]。加强观察性流行病学研究报告的质量(strengthening the reporting of observational studies in epidemiology,STROBE)是由一个国际性合作小组共同起草,主要目的是为观察性流行病学研究论文提供报告规范,从而改进这类研究报告的质量。目前STROBE已被百余种杂志的稿约所推荐,受到了学术界的广泛关注,本文对STROBE进行解读。
1 观察性流行病学研究的内容
观察性研究中按事先有无专门设计的对照组又可以分为描述性研究与分析性研究。描述性研究主要用于描述疾病或某种特征在不同时间、地点、人群中的分布(三间分布)以及发生、发展的规律,如横断面研究、病例报告和病例系列等。由于没有事先专门设计的对照组,所以此类方法不能确定暴露与效应之间的联系,只能提出病因假说。分析性研究是在描述性研究的基础上,分析疾病和健康状态与可能的致病因素之间的关系,从而进行致病因素的筛选并形成和检验病因假说。与描述性研究不同,分析性研究最重要的特点是在研究设计中设立了可供对比分析的两个组,或者按疾病的有无进行分组,如病例对照研究,或者按是否暴露于某因素或具备某特征进行分组,如队列研究。
临床工作者不仅需要有关治疗和干预效果的证据,也需要疾病频率、危险因素、诊断及预后等信息。虽然RCT是评价药物疗效的金标准,但伦理和实践的考虑常常限制了RCT的广泛使用,严格的纳入和排除标准也限制了结果的外推。为了寻找药物安全性的新信息,观察性研究如果不是唯一的也是最好的选择[3]。事实上,许多临床和公共卫生知识都来自观察性研究,并且约90%发表在医学专业杂志上的论文为观察性研究[4]。因此,规范观察性流行病学研究报告具有重要的意义。
2 STROBE的制定过程
STROBE的制定始于2004年,以同年9月在英国Bristol大学召开的为期2 d的国际会议为标志。与会者包括流行病学家、方法学家、统计学家、7家著名杂志的编辑以及少数医生,会议的主要内容是对之前文献汇总形成的STROBE清单草稿中的每个条目进行讨论进而达成共识,并在会后公布了STROBE清单第1版的内容。随后,通过定期会面和电话会议等方式查漏补缺,一个由方法学家、研究者和编辑组成的STROBE工作小组连续制定并公布了STROBE清单第2版(2005年4月)、第3版(2005年9月)和第4版(2007年10月)[5,6]。
由于观察性流行病学研究常包含数种研究设计和诸多的主题,因此制定小组把STROBE建议限定在3种研究设计(队列研究、病例对照研究和横断面研究),并制定成一种通用的格式。以后可以进一步扩展到其他的研究设计和专门的主题领域,如遗传和分子流行病学。同时,STROBE的制定还是一个不断更新的过程,工作小组会根据评论、评价和新证据而定期推出更新的建议版本。
3 STROBE清单第4版内容
与既往3版清单相同,STROBE清单第4版内容(表1)覆盖观察性流行病学的3种主要研究设计——队列研究、病例对照研究和横断面研究,包括22个条目,即文章的题目和摘要(条目1),前言(条目2和3),方法(条目4~12),结果(条目13~17),讨论(条目18~21)及其他信息(关于赞助资金的条目22)。其中,18个条目对3种研究设计是共用的,4个条目(条目6,12,14,15)根据研究设计而异,对整个条目或其部分内容有不同的表述,STROBE工作小组还同时给出了3种研究设计各自的清单。另外,用角注的条目(条目8,条目13~15)要求分别给出病例对照研究中病例和对照的信息,或者队列研究和横断面研究中暴露组和非暴露组的信息[6]。
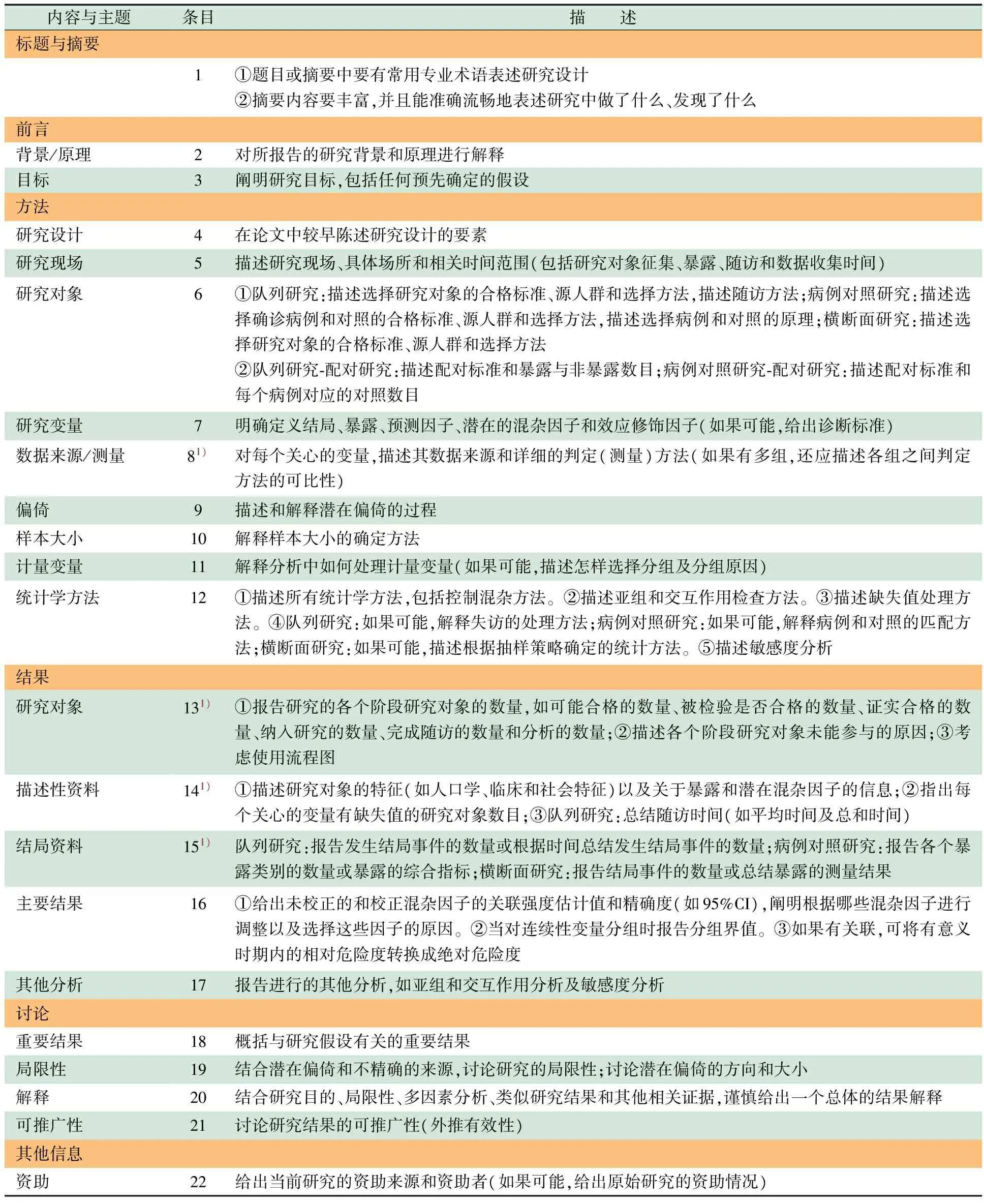
表1 STROBE声明——观察性研究必需项目清单(第4版)
注 1)在病例对照研究中分别给出病例和对照的信息;如果可能,在队列研究和横断面研究里给出暴露组和未暴露组的信息
4 STROBE清单第4版解读
STROBE工作小组还发表了一篇与声明配套使用的解读文章[4],更详细,不仅说明清单中每个条目的选取原因、给出方法学背景,而且在每个条目的解释前都给出他们认为是高质量报告的例文或例表,这些举例反映了其所属条目的良好报告规范。另外,该文还附带一个流程图的举例及8个相关概念(如混杂和遗失数据等)的简单介绍。结合此文能更好地理解和使用STROBE清单。
条目1 题目和摘要。①题目或摘要中要用专业术语(如宜用“队列研究”而不用“随访研究”或“纵向研究”)表述研究设计,使读者从中很容易识别研究设计类型,也有助于在电子数据库中准确索引到文章。②摘要内容要丰富,并且能准确流畅地表述研究中做了什么,发现了什么。摘要应包括关键信息(且只能是出现在文章中的关键信息),使读者了解研究并决定是否继续阅读这篇文章。典型的内容是所研究的问题、研究方法、研究结果及结论。重要结果用数字表示:研究对象数目,关联的估计值及其变异性和不确定性的正确计算(如OR的置信区间)。
条目2 对所报告研究的背景和原理进行解释,从而为读者提供研究脉络,定位研究在整个学科中所处的阶段,并描述研究的中心所在。还能总结对所研究主题目前已经知道的和空白的点是什么。背景资料应注明目前相关的研究及系统综述。
条目3 阐明研究目标,包括任何预先确定的假设。这是研究的具体目的,描述较好的目的会详细指明人群、暴露和结局、将要估计的参数,可以表述成具体的假说或者以问题的形式出现。如在早期调查阶段,目的可能不是很明确,但是报告还应能清楚地表达研究者的意图。如果某些不是最初目的的亚组分析或多因素分析在数据分析阶段出现,那么也应该做出相应的描述。
条目4 研究设计。在方法学的前期(或者在前言末尾)写明研究设计要素,使读者能理解整个研究的基础。例如,当作者报告队列研究时,应用专门的术语“队列研究”说明研究的性质,描述组成队列的人群和他们的暴露状况。类似地,如果是病例对照设计,应描述病例和对照及其源人群。如果是横断面调查,应描述人群和重要时间点。当研究是3种主要设计的衍生类型(如病例交叉设计)时,还需注明额外的相关内容。也可在研究的方法部分首先写明该研究是否为某个系列研究之一。
条目5 研究现场。描述研究现场、具体场所和相关时间范围(包括研究对象征集、暴露、随访和数据收集时间)。读者需要研究现场和具体场所的信息来评价一个研究结果的背景和可推广性。因为环境和治疗等暴露因素会随时间而变化,同样地,研究方法也会随时间更新,所以知道了研究开展的时间、研究对象征集时间和随访时间就知道了研究的历史背景,这对理解结果非常重要。研究现场的信息包括研究对象征集地或来源(如选民名册,门诊登记,癌症登记,或三级医疗中心)。研究具体场所涉及到国家、城镇及医院等调查发生地。要写明具体时间而不仅仅描述持续时期。
条目6 研究对象。描述选择研究对象的合格标准(即纳入和排除标准)、源人群和选择方法,队列研究还需描述随访方法,病例对照研究还需描述选择病例和对照的原理。希望作者报告所有的合格标准(如医院和人口学等特征),也应描述选取研究对象的人群组(如一个国家或地区的一般人群)和研究对象征集方法(如志愿者)。如果应用了匹配设计,那么应描述选择匹配变量的原理和方法细节,如匹配的队列研究描述配对标准和暴露与非暴露数目,匹配的病例对照研究描述配对标准、方式(频数匹配或个体匹配)和每个病例对应的对照数目。
条目7 研究变量。明确定义结局、暴露、预测因子、潜在的混杂因子和效应修饰因子(如果可能,给出诊断标准)。不要用“自变量”或“原因变量”描述暴露和混杂变量,因为它不能从混杂因子中区分暴露。如果在研究早期阶段的探索性分析中使用了很多变量,就要在附录中,附表中或独立发表的文章中对每个变量列一个细节清单。建议作者阐明统计分析的“备选变量”,而不是仅选择性报告包含在最终模型中的变量。
条目8 数据来源和测量。对每个关心的变量,描述其数据来源和详细的判定(测量)方法(如果有多组,还应描述各组之间判定方法的可比性)。暴露、混杂因子和结局的测量方法可影响研究的效度和信度。测量误差和暴露或结局的错误分类使得出因果效度关系更困难,也可能产生虚假联系。潜在混杂因子的测量误差增加残余混杂的危险。因此,建议作者报告研究的信度或效度的评价或测量结果,包括参考标准的细节问题,这可用来校正测量误差或对测量误差进行敏感度分析。另外,比较组间数据收集方法是否有差别也很重要。
条目9 描述和解释潜在偏倚的过程。偏倚产生偏离真值的系统误差。研究者最好在设计阶段就认真思考偏倚的可能来源。在报告阶段,建议作者估计相关偏倚的似然比,特别应讨论偏倚的方向和大小,如果可能则计算出偏倚的值。如果使用适当的方法来减少偏倚,作者应提供更多处理偏倚的细节,描述质量控制计划(如数据收集质量控制计划,调查员的培训),保证变量变异最小。
条目10 样本大小。观察性研究样本量的计算依赖于研究背景。如果采用适用于其他研究目的的数据进行某种分析,主要的问题之一是样本量可能不合适。一般在研究计划早期计算样本量,这种计算的不确定性高于用常规的计算方法估计样本量,但是仍鼓励研究者正式恰当地报告样本量的计算。其他情况下,作者应该指明样本大小的确定方法。如果观察性研究在找到有统计学意义的结果时就停止了,应该告诉读者,不要让读者在事后证实样本量或者思考计算功效。
条目11 计量变量。解释分析中如何处理计量变量(如果可能,描述怎样选择分组及分组原因)。研究者选择收集和分析暴露,效应修饰因子和混杂因子等定量数据的方法,可以对一个持续暴露变量进行分组而产生一个分组变量。分组对数据分析有重要意义,建议作者解释分组的原因和意义,包括分成几组,分组数值和组均数或中位数。若用表格报告数据,不应只报告效应估计值和模型结果,还应报告每组的病例数、对照数、高危人数和高危人时数等。研究者在选择分组的时候应该考虑暴露和结局关系的本质(可能偏离线性关系,有多种方法校正暴露和结局的非线性关系,如对数变换)。如果给出暴露变量的连续性数据分析和分组数据分析将提供更多的信息。
条目12 统计学方法。①描述所有统计学方法,包括控制混杂的方法。研究者常根据最初的研究目的确定分析方法,但是没有哪一种统计分析方法是绝对正确的,在数据分析过程中常需要增加某些分析方法或者用其他分析方法代替,这因数据而异。研究报告中,作者应告诉读者使用每种分析方法的原因。②描述亚组和交互作用检查方法。读者需要知道哪个亚组分析是事先计划好的,哪些是根据数据特点进行分析的。用来区分不同组间的效果或关联是否相同的方法也很重要,应说明。交互作用越来越受到重视,我们关心暴露的交互作用在何种程度上改变了其独立效应,是相加关系还是相乘关系。③描述缺失值的处理方法。在分析的每一步应报告每个关心的变量(暴露、结局和混杂因子)的缺失值个数。如果可能,作者应报告数据缺失的原因,并描述有多少研究对象因为缺失值问题而被排除。作者应描述分析缺失值的方法(如多重差补)和所采用的假设(如缺失是随机的)。④队列研究中报告失访患者数和对待截尾数据的策略;病例对照研究包括Mantel-Haenszel分层分析和个体匹配研究中的条件Logistic回归(如果匹配后对估计值的作用较小,作者也可以选择不匹配的分析);横断面研究描述根据抽样策略确定的统计学方法,复杂抽样(其关联的估计值可能比一个简单随机样本的估计值稍大)应用设计效率(deff)来校正诸如标准误或置信区间等精度的估计值。⑤描述敏感度分析,检验主要结果是否与其他分析策略或假设条件下的结果一致。
条目13 研究对象。①报告研究各个阶段中研究对象的数量,如可能合格的数量、被检验是否合格的数量、证实合格的数量、纳入研究的数量、完成随访的数量和分析的数量。报告要尽量详细,这是因为进入研究的人常不同于研究结果适用的目标人群,可能导致患病率或发病率的估计值不能反映目标人群的水平。例如,母亲生育年龄小和后代患白血病之间的关联,部分原因是有健康孩子的年轻母亲会比有不健康孩子的年轻母亲更少参加这种调查研究。②描述各阶段研究对象未能参与的原因,帮助读者判断研究人群是否代表目标人群,是否会产生偏倚。例如横断面调查中,所选对象由于与健康无关的原因而不参加研究(例如征集信函由于错误的地址而没有邮寄到)会影响估计的精度,但却可能不会产生偏倚。③考虑使用流程图。
条目14 描述性资料。①描述研究对象的特征(如人口学、临床和社会特征)以及关于暴露和潜在混杂因子的信息。连续性变量描述均数和标准差(当数据不对称时则用中位数和百分位数间距);分类数少的有序变量(如疾病的Ⅰ~Ⅳ级)不能当作连续性变量,需给出每类的数目和比例;组间比较应分组给出描述性特征及其数目;不用标准误和置信区间描述变量特征,描述性表格中不应出现显著性检验;P值在分析中不是用来选择应校正哪个混杂因子的标准,对研究结局作用较大的混杂因子,其统计学差异再小也同样重要;队列研究中报告暴露与其他特征和潜在混杂因子的相关性。②指出每个关心的变量有缺失值的研究对象数目,暴露、潜在混杂因子和患者的其他重要特征,不同程度和原因的失访。可用表格和图列举缺失数据的数量。③队列研究总结随访时间,报告随访期限的最大值和最小值或总体分布的百分位数,总随访人年,所获得潜在数据的一些比例指标。
条目15 结局资料。报告发生结局事件(队列研究、横断面研究)或暴露类别(病例对照研究)的数量,或者根据时间总结发生结局事件的数量。在描述暴露(危险因素)和结局之间可能的关联之前应先介绍相关描述性数据。队列研究可报告每随访人年结局事件的发生率(如果事件的发生率在随访期内改变,那么就以合适的随访间隔报告事件的发生数和发生率,或者用Kaplan-Meier寿命表法描述),用表格或图适当介绍测量数据,对病例对照研究,以频数或定量的形式报告病例和对照各自的暴露情况。
条目16 主要结果。①给出未校正的和校正混杂因子的关联强度估计值、精确度(如95%CI)。阐明根据哪些混杂因子进行调整以及选择这些因子的原因。建议给出未校正分析结果的同时给出主要数据,例如暴露或不暴露的病例和对照数目。对校正的分析结果,因为缺失值会使关联强度在不同的协变量间有差别,所以要报告分析中的人数。谨慎解释校正的结果、考虑到的所有潜在混杂因子以及筛选统计模型中变量的标准(如果选择某变量的原因是估计值有所变化,就要报告这种变化是什么)。②当对连续性变量分组时报告分组界值,如用百分位数分类,BMI等常规界值分类。细化分类的目的是与其他研究做比较和Meta分析,作者至少应该报告类间距,若报告数据范围与类内均数或中位数则更好。③如果有关联,可将有意义时期内的相对危险度转换成绝对危险度。一般来说,暴露的绝对危险度比相对危险度更受偏爱,计算出归因危险度或人群归因危险度还有助于估计如果消除暴露而被预防疾病的比例,描述计算归因危险度的方法,最好给出计算公式。
条目17 报告进行的其他分析,如亚组和交互作用分析、灵敏度分析。第一,描述亚组间特定关联或效果测量在亚组之间的变化,分辨几个恰当分类的亚组分别分析的关联与总体关联是否一致。第二,介绍在数据分析过程中出现的感兴趣的亚组。建议作者报告计划中准备进行哪些分析,没有准备的哪些分析。第三,评价危险因素间联合作用和交互作用、或者分析是否可用最优的统计学模型确定危险因素间的某种关系时,应同时报告每种暴露各自的效果和他们之间的联合作用及置信区间(如果可能的话用表格表示),不可用某个因子在亚组间的P值来判断它是否为效应修饰因子,若置信区间重叠则判断交互作用为零也是不对的。最后,灵敏度分析有助于估计统计分析中所选方法的影响、或者估计在缺失数据或可能的偏倚下得到的研究结果是否可靠,有时只报告已经进行的、并且分析结果与报告中的主要结果一致的敏感度分析就足够了,如果所分析的问题受到很大的关注,或者效应估计值变化很大时更需要详细说明。
条目18 概括与研究假设有关的重要结果。通过简短的总结告知读者主要的研究结果,以帮助读者评价研究结果是否支持作者在讨论中的解释和说明。
条目19 局限性。结合潜在偏倚和不精确的来源,讨论研究的局限性、潜在偏倚的方向和大小。识别和讨论研究的局限性是正规报告的必要部分。作者不仅要描述能影响研究结果的偏倚和混杂,还要讨论不同类型偏倚的相对重要性,包括任何可能偏倚的方向和大小;也应讨论研究结果的不精确性及其来源(如样本大小,暴露、混杂因子和结局的测量);研究者还可通过比较自己的研究与其他研究的效度、可推广性和精确度来讨论局限性。
条目20 解释。结合研究目的、局限性、多因素分析、类似研究的结果和其他相关证据,谨慎给出一个总体的结果解释。讨论部分的核心是解释研究结果。制定小组专家认为大家更容易在谨慎方面犯错误[7],原因有二:第一,科学进展很少在单次研究中发生,而是需要累积和几项研究的同时解释;第二,流行病学有时受到批评的原因之一是对研究结果过度解释或夸大其推广性。为了避免过度解释这一普遍现象,解释结果的时候,作者应该从连续验证的结果和潜在偏倚来源(包括失访和不参加)考虑研究的性质,应给予混杂、相关敏感度分析结果、多因素分析与亚组分析问题足够的重视。作者也应考虑因未测量的变量和没有精确测量的混杂因子产生的残余混杂。
条目21 讨论研究结果的可推广性(外推有效性)。可推广性也称为外部效度或可适用性,是研究结果可被用在其他情形下的程度。研究结果是否有外部效度的问题常是从研究现场、研究对象特点、暴露特点和结局特点来判断的。因此,作者告诉读者以下内容的足够信息非常必要:研究地点和场所、研究对象的合格标准、暴露及其测量、研究对象征集和随访时间、不参与的程度、未暴露但是产生研究结局者的比例、暴露的绝对危险和暴露率。
条目22 其他信息。给出当前研究的资助来源和资助者(如果可能,给出原始研究的资助情况)。许多研究者都认为资助情况和研究结论关系密切。资助者在研究的哪个部分起到了直接作用(如研究设计、数据收集、数据分析、撰写论文或决定发表)。作者本身当然不会描述资助者的影响不合理,但是,一句符合事实的说明如“资助者收集、处理和分析数据”会很大程度上帮助读者评价研究或发表的结果是否受到资助者的影响[7]。
5 结语
虽然STROBE有助于显示出研究的优缺点,但是制定者提醒不要用清单去判断研究的质量,也希望作者不要用清单去修饰他们的研究报告,这也是STROBE声明中一再强调的。另外,他们还强调STROBE只是为如何更好地报告观察性研究提供指导(研究报告中要包含清单中所有条目,但并无严格的顺序要求,这些内容的顺序和格式应根据作者的意图,杂志风格和研究领域的传统确定,不应STROBE化),清单内容不是研究设计和实施流程,也不是评价观察性研究报告清晰度的量表。尽管如此,我们相信随着STROBE的不断改进与广泛应用,不仅观察性流行病学研究的报告会不断完善,也有助于改善观察性研究实施的质量和结果评价,最终导致更科学的临床和预防实践。
[1]Pocock SJ,Collier TJ,Dandreo KJ,et al. Issues in the reporting of epidemiological studies: a survey of recent practice. BMJ,2004,329(7471):883-889
[2]Zhang T(张婷),Liang RY,Lv J, et al.近年来《中华流行病学杂志》上发表的横断面研究报告完整性评价. Chin J Epidemiol(中华流行病学杂志),2009,30(1):85-86
[3]Morabia A, Costanza MC. Everybody′s talkin′ ′bout a new way of reportin′ observational studies. Prev Med, 2007, 45(4): 245-246
[4]Vandenbroucke JP, von Elm E, Altman DG,et al.Strengthening the Reporting of Observational Studies in Epidemiology (STROBE): explanation and elaboration.Ann Intern Med,2007,147(8):163-194
[5]Wang B(王波), Zhan SY. 如何撰写高质量的流行病学研究论文 第一讲. 观察性流行病学研究报告规范——STROBE介绍.Chin J Epidemiol(中华流行病学杂志),2006,27(6):547-549
[6]von Elm E, Altman DG, Egger M, et al. STROBE Initiative. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE)statement: guidelines for reporting observational studies. Lancet,2007,370(9596):1453-1457
[7]The Epidemiology Monitor. Exclusive interview with developers of STROBE guidelines for reporting of epidemiologic studies - checklist called a "life-jacket not a straight-jacket" by developers.Epimonitor, 2007, 28(1): 1-5
