第五讲:如何报告临床诊断准确性研究
——国际报告规范STARD解读
2010-01-23严卫丽
严卫丽
诊断准确性研究是用来评估某试验方法,正确地将一组研究对象区分为具有或不具有某种状况能力的研究。在诊断准确性研究中,将同一组可能具有某种健康状况(疾病)的研究对象,接受一项或多项检查的结果,与金标准方法检验结果进行比较,从而对被评价检验方法的真实性、可靠性和收益进行评估。医学领域的各种新检查方法发展迅速,现有的各种检验方法的技术也在不断改进。如果诊断准确性研究设计存在缺陷,或者是结果报告欠准确,均可导致被评价试验的价值被夸大或者导致偏倚,从而导致临床医生过早地下结论或者导致错误的治疗决定。本文特别强调诊断准确性研究在论文报告阶段采用STARD (standards for reporting of diagnostic accuracy)写作清单作为参考十分必要,不仅有助于向读者提供客观、准确的诊断试验研究的信息,防止研究信息误导临床实践,同时也有助于减少临床上不必要的检查,从而达到节约卫生资源和医疗花费的目的。
STARD第一稿产生于2000年9月,目的是为了改进诊断准确性研究报告质量,通过建立一个科学、规范和循证的报告标准,使读者能通过完整、准确的报告评价研究结果的内部有效性和外部有效性,为指导临床实践和临床决策奠定基础。
STARD推荐了一个包含25条条目的写作清单(表1 )和一张反映研究设计的诊断准确性研究的纳入和排除流程图(图1)。《中华流行病学杂志》于2006年第10期发表了詹思延教授对STARD的介绍及解读[1],第一次向中国读者介绍了诊断准确性研究的国际报告规范,对提高中国医学领域诊断准确性研究的设计和报告水平起到了重要的作用。经过10年的实践,证明STARD写作清单被越来越多的学术界和研究者所认可,截至2008年4月,超过 200本生物医学杂志在稿约中鼓励作者使用 STARD写作清单。本文再次强调STARD写作清单在儿科临床诊断准确性研究中的作用,并就相关条目作出解读,供儿科领域研究者参考。本文未做解读的条目可参考詹思延教授精辟的介绍和解读。
1 基本概念
诊断准确性研究中被评价试验方法(index test),可以包括所有从病史、体格检查、实验室检查、影像学检查、功能检查和组织学检查等所获得的患者信息。而金标准试验是指目前可行的、最好的判断疾病状态的方法,可以是一项单独的检查,也可以是几项检查的组合;可以是实验室、影像学和病理学检查,也可以是经过随访后获得的结果。诊断方法的准确性(accuracy)指从被评价试验中获得的疾病状态信息和由金标准试验获得相应信息的吻合程度。常用的判断准确性的评价指标包括灵敏度(sensitivity)、特异度(specificity)、似然比(likelihood ratios),诊断OR值(diagnostic odds ratio),以及受试者工作特征曲线下面积(area under receiver operator characteristic curve)。
2 START写作清单部分条目的解读[2]
条目1 在文章的结构式摘要的目的中,应当清晰地标明研究的性质。如一项研究的目的是“以结肠镜检查为金标准,确定CT成像诊断结肠息肉和结肠癌的灵敏度和特异度”[3]。一项研究显示,检索Medline数据库1992至1995年发表的文章,仅用“灵敏度和特异度”这两个主题词,只有51%诊断准确性研究被正确检出,还有一些非诊断准确性研究也被错误的检出[4]。为了提高数据库检索的正确性和效率,建议作者在题目、摘要中使用“诊断准确性”一词。
条目2 清晰、准确地界定研究目的,有助于读者判断作者是否采用了最为恰当的研究设计和统计分析方法。如果只是泛泛地用“诊断价值”或者“临床用途”,读者则无从判断以上信息。
条目3 研究方法部分应当分别详细交代病例的募集、被评价试验和金标准试验实施的场所。此外,详细描述研究对象的纳入和排除标准的非常重要。某些研究对象所具有的一些特殊状况可能影响诊断性试验的结果,应当考虑在排除标准中加以限定。例如,研究运动后ECG改变时,是否排除了使用β受体阻滞剂的研究对象。
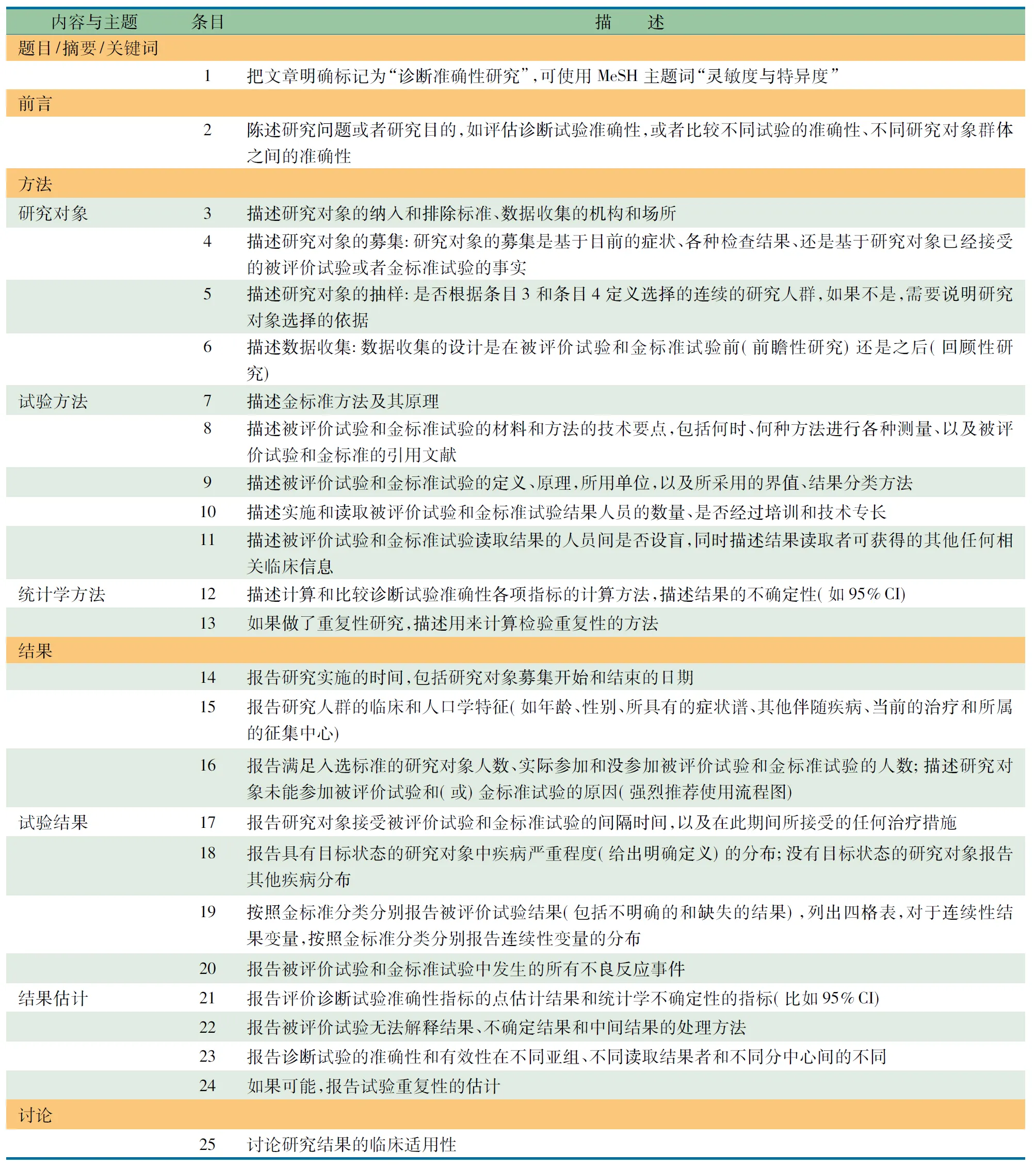
表1 STARD写作清单
条目5 研究对象可以是由目标人群中所有满足纳入标准而未被排除标准排除的个体组成的,也可以是其中一部分个体组成,需要详细介绍研究样本是如何抽取的,如果是随机抽取的,需要说明随机抽样的方法,如随机数字表法。这样做有助于读者判断研究结果的外推性。
条目6 数据收集。前瞻性和回顾性的数据收集各有优缺点。如果研究设计在先进行前瞻性研究,数据收集可以集中于入选的研究对象,数据的收集更有计划性,如运用特殊的病案记录表格和特别设计的数据录入表格,缺失数据或者难以解释的数据较少,数据的质量较好,具有一定的优越性。如果回顾性地从病案记录中收集被评价试验和金标准试验的结果数据,其结果更能反映临床实践,缺点是很难发现所有符合条件的患者,数据的质量也不如前瞻性研究。
条目7 例如,ApoE基因的e4基因型与阿尔茨海默病的关联性已被很多研究证实。要研究基因诊断(e4)对阿尔茨海默病的诊断准确性,以病理学诊断为金标准,某学者比较了3种诊断方法,即临床诊断、ApoE基因型诊断和临床诊断+ApoE基因型诊断的灵敏度和特异度[5]。 诊断准确性研究中,金标准是用来区分有病的患者和无病的研究对象。依据具体的研究目的,金标准方法可以是结合一组临床信息定义的,如临床相关性、病理诊断、临床处理方案或者是预后。例如,采用怀孕早期(3个月内)胎儿颈项透明层的B超检查筛查唐氏综合征的研究,阳性结果可通过染色体核型检查来证实,然而阴性结果只能等到分娩后才能证实。那些在胎儿颈项透明层的B超检查提示阳性下进行染色体核型检查的研究明显高估了胎儿颈项透明层B超检查的灵敏度和特异度[6]。
条目11 如果事先知晓金标准诊断结果,将会对研究者判断被评价试验结果产生很大的影响,反之亦然,这样会使被评价试验和金标准试验的结果更加趋于一致,造成对诊断准确性评价指标的高估,这两种情况分别导致了试验评价偏倚(test review bias)、诊断评价偏倚(diagnostic review bias)。读取结果者事先了解了更多的临床信息则可以导致临床评价偏倚(clinical review bias)。因此对于试验结果判断者采取盲法至关重要。例如,某项研究描述:“所有的影像结果分析在计算机分析平台由2名放射科医生独立完成,之后进行合议最终得到诊断结论。放射科医生对于患者的病史、包括患者是否进入筛查范围、是否具有目标症状,以及金标准结肠镜和组织学检查的结果等相关信息完全不知晓”[3]。作者甚至提供了2名放射科医生的名字缩写。
条目12 评价诊断试验准确性的指标不止一种。作者应当详细地报告所采用的指标、计算方法和估计值,同时报告统计学的不确定性(如95%CI)。有的统计学方法可以检验其他假设,比如一种检验方法是否优于另一种,或者某一种检验的诊断准确性是否超过预期。
条目13 无论是被评价试验还是金标准试验其重复性都受到以下因素的影响,如观察者对于同一张影像片的观察结果存在的变异,根据检验结果对研究对象进行分类时,统一机器的不同操作者之间存在的变异,不同操作系统间的变异,分析方法学的变异,以及分析性噪音等。对于定量研究,应报告测量值在临近临床决策日的不同日的重复测量结果的变异系数,如果所有研究对象在同一批进行测定,应报告测量值的批内变异系数。例如,表述“计算kappa值及其95%CI来分析对磁共振血管造影和传统血管造影结果判读的观察者间变异”。
条目14 技术的进步使许多试验方法的诊断准确性发生了变化。诊断准确性研究实施与论文发表有相当长的间隔时间。因此应当清晰地报告研究实施的时间。
条目15 提供足够的研究对象的人口学特征和相关临床特征有助于读者判断一项研究的结果在其他人群中的适用性。通常可用表格的形式陈列研究对象的人口学和临床特征。
条目16 STARD写作清单强烈建议使用诊断准确性性研究流程图(图1),即清晰地标出研究的每一个阶段研究对象的数目,帮助判断患者样本与目标人群的相似程度,获得计算各种率和比的分母。 说明未能参加被评价试验和(或)金标准试验的人数。如果被评价试验的结果影响该研究对象是否接受金标准试验,被评价试验的诊断准确性会因此受到影响。

图1 诊断准确性研究的纳入和排除流程图
条目17 从流行病学角度讲,诊断准确性评价是属于横断面研究。同一组研究对象最好同时接受被评价试验和金标准试验的检测,同时获得结果。如果两个试验的间隔时间过长,研究对象的情况可能发生变化,可导致主要和次要观察指标恶化或者改善。如果在被评价试验之后、金标准试验之前患者接受了某种治疗,也会给诊断准确性的测量增加难度。
条目18 研究对象的人口学特征和临床特征可能对诊断准确性的评估带来影响,这种影响被称作疾病谱偏倚(spectrum bias),包括所研究的疾病或者健康状况的严重程度、人口学特征以及其他伴随疾病。其中以不同疾病严重程度对被评价试验诊断准确性的影响最为常见。如果研究样本中病情较严重的研究对象所占的比例较大,则被评价试验的灵敏度通常被高估。另一方面,如果并发疾病较多,则假阳性和假阴性结果也常可能发生。因此,描述研究对象的疾病严重程度和所并发疾病的分布十分必要。
条目20 并非所有的诊断试验都是安全的。真实地报告诊断准确性研究中各种不良事件有助于全面地了解被评价试验的临床意义。
条目21 诊断准确性研究最终目的是评估被评价试验判断研究对象有无疾病 (与金标准试验对比)的准确性。通过一个研究样本获得的是诊断准确性指标的点估计值,受各种因素的影响,如果在同一个研究人群中进行重复抽样研究,该值会有波动,因此报告估计值的波动范围,如95%CI更为科学。研究发现,1996至1997年在BMJ杂志发表的诊断准确性研究中只有50%报告了诊断准确性指标的点估计值的置信区间[7]。
条目22 无法解释的结果、不确定结果和中间结果 (介于阳性和阴性结果之间)是评估被评价试验诊断准确性的常见问题。这类结果出现的频率是该诊断试验总体用途的一个评价指标。如果这类结果在患者和非患者中出现的频率不同,则会给诊断试验的准确性评估带来偏倚。出现无法解释、不确定和中间结果的原因有多种,技术原因、样本量不足(如肿瘤组织的针刺活检未能获得肿瘤细胞)所导致的无法解释的结果,或者是因为研究对象患病情况的沾染,或者是治疗情况的沾染而获得不确定的结果,如在研究运动试验对心率的影响时,混入了使用β受体阻滞剂的患者。不同试验出现这类难解释结果的频率存在差异,可导致不同的临床决策。因此应对这类结果的原因加以重视。
条目23 由于研究设计、患者选择和操作的不同可导致不同诊断试验的特征也不相同,从某一特定诊断试验得到的结论可能不适用于读者的具体决策问题[8]。因此报告中除了讨论潜在的方法学的不足以及对当前获得结果的一般性解释外,STARD写作清单推荐作者要指出该研究的结论在推广至其他机构和患者群体时应该有所不同。
3 总结
诊断准确性研究并不是唯一的评价诊断试验的方法(如还包括随机化临床试验)。诊断准确性研究的设计和实施方法学仍在不断完善。随着对各种变异和偏倚认识的不断深入,STARD写作清单将定期更新。STARD写作清单不适合用于诊断准确性研究的质量评估。对于诊断准确性研究的质量评价,可参考QUADAS 清单[9]。在国际范围内,研究者们对STARD写作清单的认识和使用仍然有待提高。2006年发表了一篇研究报告,对2本产科学国际重要杂志1999至2004年发表的诊断准确性研究的文献进行分析发现, 在STARD写作清单发表后的5年间,STARD写作清单中25条条目在论文中的平均报告率仅从12.1%增至12.4%,STARD写作清单条目的使用率和报告率仍然很低。因此,积极鼓励中国儿科研究者在诊断准确性研究的论文写作中使用STARD写作清单。
[1]Wang B(王波), Zhan SY. 如何撰写高质量的流行病学论文 第三讲.诊断试验转确性研究的报告规范——STARD介绍. Chin J Epidemiol(中华流行病学杂志), 2006, 27(10):909-912
[2]Bossuyt PM, Reitsma JB, Bruns DE, et al. The STARD statement for reporting studies of diagnostic accuracy: explanation and elaboration. Clin Chem, 2003, 49(1):7-18
[3]Yee J, Akerkar GA, Hung RK, et al. Colorectal neoplasia: performance characteristics of CT colonography for detection in 300 patients. Radiology, 2001, 219(3):685-692
[4]Deville WL, Bezemer PD, Bouter LM. Publications on diagnostic test evaluation in family medicine journals: an optimal search strategy. J Clin Epidemiol, 2000, 53(1):65-69
[5]Mayeux R, Saunders AM, Shea S, et al. Utility of the apolipoprotein E genotype in the diagnosis of Alzheimer′s disease. Alzheimer′s Disease Centers Consortium on Apolipoprotein E and Alzheimer′s Disease. N Engl J Med, 1998, 338(8):506-511
[6]Mol BW, Lijmer JG, van der Meulen J, et al. Effect of study design on the association between nuchal translucency measurement and Down syndrome. Obstet Gynecol, 1999, 94(5 Pt 2):864-869
[7]Harper R, Reeves B. Reporting of precision of estimates for diagnostic accuracy: a review. BMJ, 1999, 318(7194):1322-1323
[8]Irwig L, Bossuyt P, Glasziou P, et al. Designing studies to ensure that estimates of test accuracy are transferable. BMJ, 2002, 324(7338):669-671
[9]Whiting P, Rutjes AW, Reitsma JB, et al. The development of QUADAS: a tool for the quality assessment of studies of diagnostic accuracy included in systematic reviews. BMC Med Res Methodol, 2003, 3:25
