基于Web的数据挖掘在电子商务中的应用
2010-01-15周贤善谢婷婷
周贤善,谢婷婷
(1.长江大学计算机科学学院,湖北荆州434023;2.北京电子科技学院计算机科学与技术系,北京100070)
基于Web的数据挖掘在电子商务中的应用
周贤善1,谢婷婷2
(1.长江大学计算机科学学院,湖北荆州434023;2.北京电子科技学院计算机科学与技术系,北京100070)
Web数据挖掘应用于电子商务系统,已成为数据挖掘热点研究。Web服务器日志中保存了大量的用户访问电子商务系统的记录,运用数据挖掘技术对数据进行处理和分析,构造频繁访问路径挖掘算法,获取用户的购物特性和习惯,达到向每个用户推荐产品的目的,进一步指导电子商务网站建设。
Web;数据挖掘;电子商务;频繁访问路径
面对大量的电子商务信息,找出用户感兴趣的信息加以组织利用,加强客户关系的管理,提高客户满意度,从而改变Web站点的设计、改善企业与客户的关系成为电子商务必须解决的问题。通过对电子商务网站服务器日志文件进行分析挖掘,可以找出用户行为模式,利于向用户推荐产品,提出针对性商务计划或者对网站进行改进。
1 电子商务中的Web挖掘
1.1 Web数据挖掘的资源
Web数据挖掘的资源[1]主要包括Web上各种形式的文档和用户访问信息两大类。在Internet电子商务中,客户的浏览信息被Web服务器自动搜集,并保存在日志文件中。Web服务器文件的记录格式如表1所示。
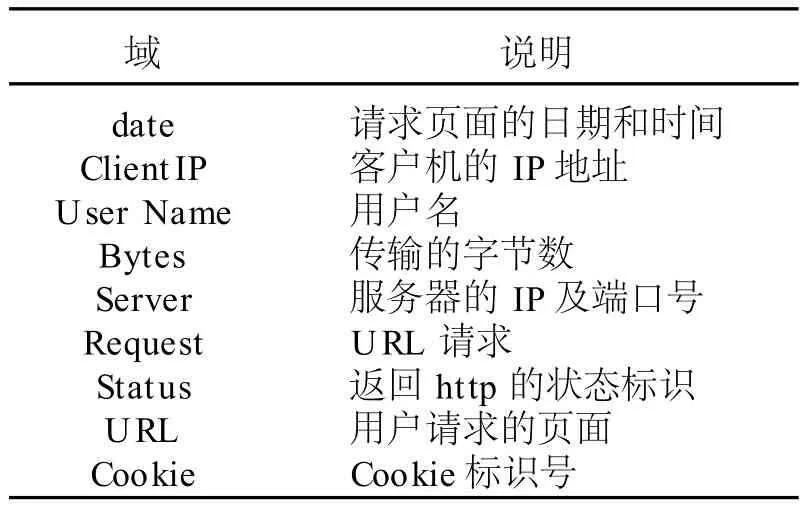
表1 Web服务器文件的记录格式
1.2 Web日志挖掘的过程
Web日志挖掘是对原始的日志文件进行预处理转变成适合挖掘的数据形式,再利用模式识别中的数据挖掘算法进行挖掘,最终汇总挖掘结果应用到实际中去。通过对日志数据信息进行分析加工,可以发现用户访问站点的浏览模式,得到商家用于向特定消费群体或个体进行定向营销的决策信息,可揭示其中的关联关系、时序关系、页面类属关系、客户类属关系以及频繁访问路径与页面等,从而为优化Web站点拓扑结构,为企业更有效地确认市场目标、改进决策提供帮助[2]。
1.3 用户识别、会话识别
用户识别[3],是分析有多少不同的用户访问。一般的方法是采用启发式规则,以用户IP和代理来唯一确定用户。即用户IP地址和代理同时相同的为同一个用户;IP地址相同而代理不同,则可以标记为不同的用户。结合访问信息、引用日志和站点拓扑,就能列出用户浏览的众多路径,若请求的页面与用户已浏览的页面不存在链接关系,则认为存在IP地址相同的多个用户。
会话是指用户在一次访问网站期间所进行的活动,会话识别的任务就是把属于同一用户的同一次访问请求识别出来。不同的用户访问属于不同的会话,同一用户相邻两次访问时间跨度较大时,可以认为该用户开启过两次不同会话。一般时间戳Timeout设定为30分钟。扫描日志文件中按照用户分类的日志记录,可完成对所有用户的会话识别,进而完成整个日志文件的会话识别。会话识别是Web日志挖掘的基础和关键,只有识别出高质量的会话,才能有效地实现模式识别和模式分析,从而为应用提供有意义的数据支持。
2 频繁访问路径的挖掘
用户频繁访问路径[4]是用户在一个时间段中多次浏览的连续网站页面序列。在求得M FP的基础上,逐次扫描每个用户会话的所有M FP,迭代产生长度为len的候选子路径,通过计算候选路径的频繁访问支持度从而产生频繁访问路径。
2.1 相关定义和概念
定义1用户会话S是一个二元组<Uid,p>,其中Uid为用户标识,p为用户在一个时间段内访问的页面的集合,它由用户访问的页面Pi和用户访问一个页面所停留的时间L(访问时间长度)构成,即:S= <Uid,{(P1,L 1),(P2,L 2)…(Pn,Ln)}> 。
定义2最大向前路径M FP(maxim um fo rw ard path)是指用户会话中的首个网站页面至回退的前一个网站页面所组成的路径。如:一个用户会话页面顺序是P1-P2-P1-P3-P4-P3,则对应的M FP为 P1-P2和 P1-P3-P4。
定义3设P={x1,x2,…,xn}为用户顺序访问的页面集合,Fmin为最小支持度,若,则称路径P为频繁访问路径。频繁访问路径就是M FP中满足一定支持度的连续页面序列,频繁访问路径的长度为其包含的页面数。
定义4包含频繁访问路径的用户会话数目称为支持度。用FPlen表示长度为len的频繁访问路径的集合,则最频繁的 K个访问路径的集合为FPlen_k={Plen_1,…Plen_k}。
定义5若两个连续的len-1长的子路径{xj,…xj+len-2}和{xj+1,…xj+len-1}都是 FPlen-1的元素,即它们的支持度都不小于Plen-1_k的支持度,则称{xj,…xj+len-1}为FKlen的候选路径。
2.2 频繁访问路径挖掘算法
要挖掘长度为len的频繁访问路径,实际上就是要构造出 FPlen。从M FP中找出长度为len的候选路径{xj,…xj+len-1},计算它在用户所有会话中的支持度。支持度最大的 K个路径的集合就是 FKlen_k。
FPk的构造算法如下:
input:备选M FP集合,最小支持度 Fmin;
output:长度为len的频繁路径集合FPlen(len>1)。
for每个用户会话s{
for s中的每个M FP{x1,x2,…,xk}{
if(len≤k){
for(j=l;j<k-len+l;j++){
if{xj,…xj+len-1}已经在 FPlen中
{xj,…xj+len-1}的支持度加1
else if{xj,…xj+len-2}的支持度 ≥Fminand{xj+l,…xj+len-1}的支持度≥Fmin
把{xj,…xj+len-1}插入 FPlen;
}
}
}
}
通过该算法对用户会话进行分析,构造出每个用户频繁访问路径表(用户标识,频繁访问路径),反映出用户的浏览兴趣,同时为用户提供个性化服务提供依据。
3 结束语
在电子商务中,客户浏览信息被Web服务器自动收集并保存在访问日志、引用日志和代理日志中。通过对Web服务器日志文件的数据进行处理和分析,在挖掘出最大向前路径的基础上做进一步的挖掘工作,得到用户的频繁访问路径,找出用户的购物特性和习惯,达到向用户推荐产品的目的,同时为企业更有效地确认目标市场,改进决策获得竞争优势提供帮助。
[1] 赵东东.电子商务中的Web数据挖掘系统的设计[J].微计算机信息,2007,23(10-3):168-169.
[2] 周丽利,李耀辉,董颢霞,等.基于 Web的数据挖掘在电子商务中的应用[J].微计算机信息,2006,22(7-3):162-164.
[3] 周贤善,王松林,王海林,等.Web日志挖掘及应用[J].长江大学学报:自然科学版,2009,6(2):258-260.
[4] 蔡俊,宋顺林.基于Web日志的频繁偏爱路径挖掘算法[J].计算机工程与设计,2009,30(24):5615-5617.
The Application of Web-based Data Mining in E-business
Zhou Xianshan1,Xie Tingting2
(1.School of Computer Science,Yangtze University,Jingzhou,Hubei 434023,China;2.Department of Computer Science and Technology,Beijing Electronic Science and Technology Institute,Beijing 100070,China)
Application of Web-based data mining in e-businesses has become a ho t topic in the research on data mining.Web server logs have saved the records on the access of large numbers of users to ecommerce system s.The use of data mining techniques help s to process and analyze data,work out the algorithm for frequent access paths,obtain the user’s shopping features and habits and achieve the purpose of recommending products for each user.This can serve as a guidance to furthering the construction of e-commerce sites.
Web;data mining;e-business;frequent access path
TP393.092
A
1671-2544(2010)03-0071-03
2010-01-26
周贤善(1963— ),男,湖北黄石人,长江大学计算机科学学院副教授,硕士。谢婷婷(1980— ),女,湖北荆州人,北京电子科技学院计算机科学与技术系讲师,硕士。
(责任编辑:陈锦华)
