基于时间跨度的汉语教学常用词表统计研究①
2010-01-11王治敏
王治敏
(北京语言大学汉语学院,北京 100083)
基于时间跨度的汉语教学常用词表统计研究①
王治敏
(北京语言大学汉语学院,北京 100083)
统计特征;教材编写;统计词表
本文利用语料的频次信息和时间跨度,通过设计不同的统计时点,建立了两个可以反映词语历时变化的汉语名词常用词语统计词表。两个统计词表不仅为《汉语水平词汇与汉字等级大纲》新词的收取和历史词的过滤提供了有价值的数据,也为人工选取教学词汇提供了有益的参考。为验证统计词表的可靠性,本文又进行了统计词表与教材高频词的对比研究,结果表明《人民日报》虽然是新闻语料,但是基本包含了汉语作为第二语言教材中的常用词汇。
1.前言
汉语常用词表的研制历史由来已久,学者们经过多次实践,研制出多个面向不同需求的常用词词表,例如:1986年北京语言学院研制的《现代汉语频率词典》;1989年北京航空航天大学的《现代汉语常用词词频词典》;北京师范大学的《中小学汉语教学词表》;1990山东大学的《现代汉语常用词库》以及 1992年国家汉语水平考试委员会办公室考试中心研制的《汉语水平词汇与汉字等级大纲》(简称 HSK词汇大纲)。其中 HSK词汇大纲的影响最大,大纲中词汇的筛选不仅集成了上述各类词表的资源成果,同时还邀请了 33位对外汉语教学专家进行人工干预。词汇大纲曾经作为我国对外汉语总体设计、教材编写、课堂教学、教学测试的重要依据,在学界发挥了重要的作用,但是由于词汇大纲所用的统计语料全部来自上个世纪 80年代,多年来未曾更新,有些词汇已经不再使用。
长期以来,学者们对于词汇大纲的修订提出过种种建议。赵金铭 (2003)提出在大型语料库进行精词频和义频统计之后重新进行词语筛选和分级。姜德梧 (2004)从词汇的发展变化、收词标准、词性标注、同形词和一词多义的处理、轻声和儿化等多个方面提出了解决这些问题的原则和方法。李红印 (2005)提出把大于词的短语、结构、成语和习用语归入新增的 “语汇大纲”,与已有的 “汉字等级大纲”、“词汇等级大纲”相照应。刘长征 (2008)提出利用语言监测的相关结果,实现对外汉语教学用词表定期更新的设想。如何继承原有大纲的成果,研制新的大纲是亟待解决的问题。
因此,本文尝试利用大规模语料的统计结果,自动提取和发现汉语常用词语,建立名词常用词语统计词表,为词汇大纲的词条收取和更新提供科学可靠的依据,也为制定基于统计特征的汉语教学本科词汇大纲提供思路。
2.常用词语统计词表的设计方法
常用词的界定往往要和基本词汇联系在一起,常用词就是当代社会中常用的词,它可以是基本词汇的词,也可以是一般词汇的词,常用词的确定完全根据词在最流行的书刊中的频次 (刘叔新,1964)。一个词语是否常用,往往是凭借经验和直觉的判断,但是这种直觉判断往往带有主观的个人因素,不同的专业背景可能有不同的结果,因此,制定一个词语收取的客观标准非常重要。
国家语言监测与研究中心在《中国语言生活状况报告》中发布了针对中国内地报纸、广播电视和网络的用字用词的调查结果。该调查基于超大规模语料,考虑了平面媒体、有声媒体、教材媒体等多方面的因素,而且发布了年度流行语的监测。由于时间只有一年的跨度,上述调查还无法判断词语的持续性,无法作为判定常用词的标准。
因此,本文给出了一个量化的定义,衡量一个词语是否常用,最重要的应该看该词是否能够在特定的时间段中持续流行,这就是说,一个词语的常用程度不能只通过一个点的频次记录来衡量,而应该把该词语放在历史大背景下,通过考察词语在多个统计时点的变化来确定其常用程度。如果一个词在特定历史时段中的统计时点上出现数量很多且分布很均匀,根据出现的频繁和稳定程度可以认为该词为常用词汇。如果一个词语在某一个特定历史时段的多个统计时点上出现很少或者不出现,我们就认为该词的使用情况复杂,有待于观察,不能作为常用词汇。为了验证这一假设,本文以《人民日报》作为基本语料,考察《人民日报》(1999~2003)这一历史时段词语的发展变化。选择《人民日报》主要是考虑到语言的规范、发行量、影响力等多方面的因素。
在 5年的《人民日报》中如何确定统计时点是首先要考虑的问题。本文设计了两种统计方案,第一种以 5年《人民日报》中 20个季节时点作为统计对象,第二种选择以 5年《人民日报》中的第一个季度 (5个季度)作为统计对象,期望通过两种统计的对比分析,确定最合理的常用词语提取方法。语料加工如下:
首先,利用北京大学计算语言学研究所自主研制的分词软件对 5年的《人民日表》进行切分标注,然后把经过分词标注后的语料按照季度分成 20个子集 S1、S2……S20。先后提取词语在 20个子集和第一季度 5个子集的词频统计数据,建立两个可以反映词语变化曲线的《人民日报》统计词表。这两个统计词表记录了在 5年时间词语在季度上的统计数据。
其次,常用词语必须满足在 20个季度或者5个季度的统计词表中均有出现,通过这样的筛选,在任意一个季度不出现,都会被过滤掉。最后两个统计词表所收的名词如表1所示:

表1:汉语名词统计词表收词情况统计
两个统计词表的统计时点不同,得到的常用词语集合也有所差别,统计的时点越多,限定条件越严格,得到的名词条数越少。20个季度统计词表中的名词词条只有 8607条,而 5个季度统计词表得到的名词要高得多,名词总数达到 11175条。两个词表词条总数不同,词语分布是否也存在差异?笔者对此进行了调查,调查结果表明,当名词的平均频次大于 10次、50次、100次时,词表的名词个数变化曲线基本重合。当名词的平均频次小于 10次时,两个词表的个数出现了明显的分化,两个统计词表的名词数分别为 2562条和 5297条。数量上有了明显差距,这说明两个词表最重要的收词差异在于低频词的收取方面,具体分布如图 1所示:

图1:统计词表词语分布与对比分析
词语在两个词表的季度节点上的平均频次纪录较高,往往很常用。例如:“经济、企业、公司”是现代生活中的高频词,它们在两个词表的平均频次全部超过了 2000次以上。因此未来新词的收取主要考虑平均频次靠前的词语。
有一些词语在统计词表上虽然有记录,但是频次非常低,说明其常用程度不高。例如:“大哥大”现在已经不用,只是语料中还有零星纪录,不过这样的词语相对于频次高的词语,它的变化曲线也几乎为零。例如:

图2:“大学、信息、大哥大”的词语变化图示
还有一些词语,在 20个季度中分布不稳定。例如:“小鬼”在 20个季度的平均频次为2.15次,在 2000年和 2003年第四季度的频次为 0,与之相比,“火柴”的频次相比高一些,平均频次为 4.95,但是其分别在 2001年第一季度、2002年第二季度和 2003年的第四季度分别出现了 0纪录。“火柴”这个词语反映了人们社会生活的变化,原来人们使用火柴点火做饭,现在出现了电子打火,城市里居民几乎不再使用火柴。“火柴”的频次出现了明显变化。因此“小鬼、火柴”被排除在统计词表之外。
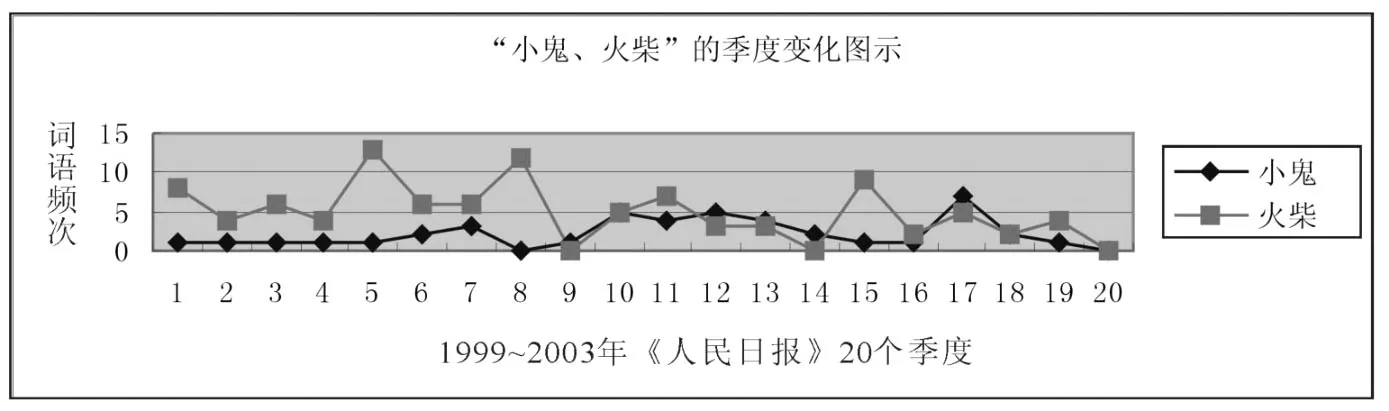
图3:“小鬼、火柴”的词语变化图示
汉语中有很多词语可能会在这一时段出现,但不能保证在所有的统计时点中出现,大量的低频、分布不均匀的词语都会被本文设计的统计词表自动排除。
统计词表中还有一些词语,受突发事件的影响,在个别季度中出现急剧增加。以“肺炎、疫情、传染病”为例:
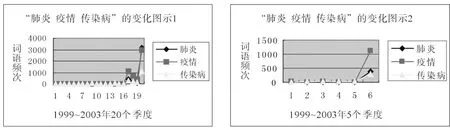
图4:两个统计词表中“肺炎、疫情、传染病”的变化图示
这 3个词语在 2003年的使用频次猛增,致使这 3个词语的季度平均频次不能反应它们的真实使用程度,因此词语的收取不能光考虑平均频次,还需要考虑它的稳定程度。
3.统计词表的稳定参数设计
王治敏 (2009)提出一个衡量词语稳定程度的U作为选取常用词语的依据,该模型反映了词语在语料中出现的平均频次及词汇波动性等因素。因此本文采用该模型来计算。

式 (1)中,f表示词语出现的平均频次,其计算公式如式 (2)所示;stdev(f)表示词语出现频次的标准差,其计算公式如式 (3)所示。

式 (2)、式 (3)中,n为词语统计频次f的个数。从公式 (1)可以看出,参数与词语在语料库中出现的平均频次成正比,与词语出现频次的标准差成反比。词语的季度平均值反映了使用该词语的频繁程度,一个词语使用得越频繁,其在语料中的季度平均值越高。标准差stdev(f)反映了该词语出现频次的波动程度,一个词语在季度中的分布越不稳定,其标准偏差的值越大,U的值就越小。比如和年度突发事件的词语标准偏差很大,参数U就会把这些词语排除在外。
按照评价参数U,排名越靠前,词语稳定性和季度出现频繁程度就越高。我们按照两个统计词表中的U值排列顺序统计发现,排名靠前的词语中有大量名词可以作为未来 HSK词汇大纲的备选新词语。不过,两个统计词表在备选词语提取方面存在明显的差异,具体如图 5所示:
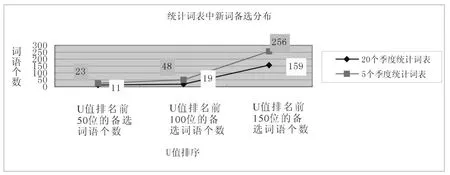
图5:统计词表中新词备选分布图示
在U排名前 500条词语中,5个季度的统计词表中在新词备选远远高于 20个季度的统计词表,备选词语有 258条,已经占总数的 51.6%。而 20个季度的统计词表前 500位中只包含备选词语 156条,占总数的 31.20%。这说明 5个季度的统计词表在新词提取方面具有明显的优势。因此,未来 HSK词汇大纲的新词收取应主要参考 5个季度统计词表的数据。
4.HSK词汇大纲中名词的更新
汉语名词统计词表记录了词语的各种统计特征,为汉语词汇大纲的所有词语提供了在大规模语料中的历时分布,也为滤掉陈旧词汇提供了可能。笔者分别用两个统计词表对 HSK词汇大纲的名词进行了筛选和人工统计,结果如下:
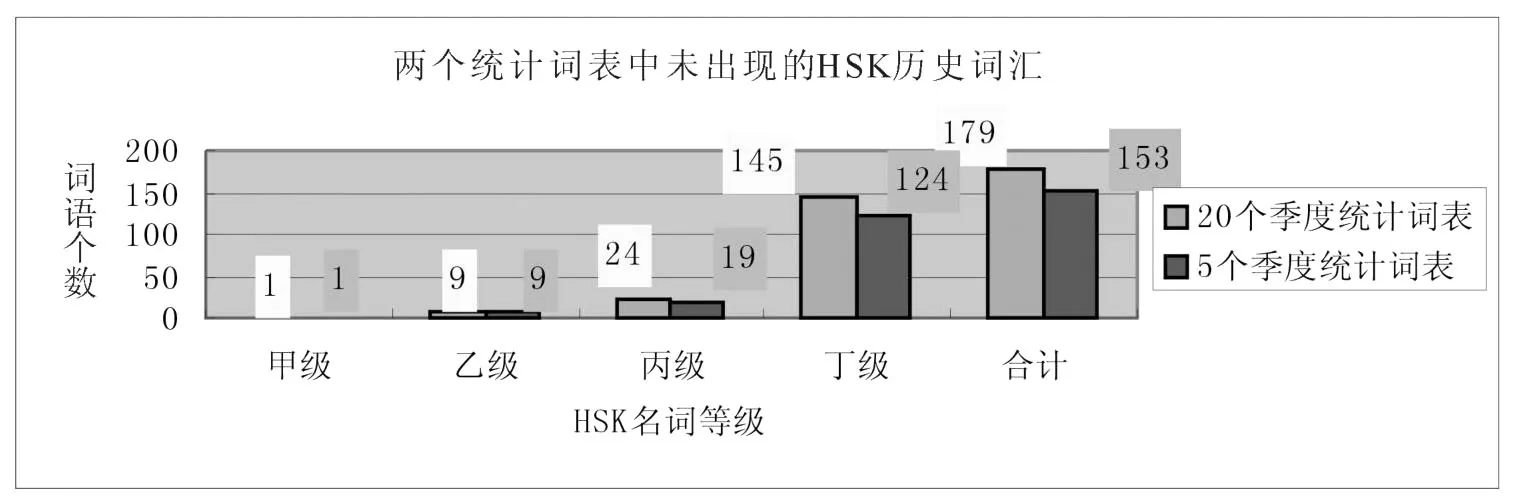
图6:两个统计词表中未出现的 HSK历史词汇
两个统计词表分别滤掉 HSK名词 179条和153条,从上面的统计可以看出,丁级词汇比例最高,两个词表分别为 145条、124条,相比较而言,20个季度的统计词表的过滤能力比 5个季度的过滤能力稍强,这可能与两个统计词表的词语限定条件有关。两个词表的交叉部分为138条。具体分布如表2所示:

表2:两个统计词表共同过滤掉的 HSK历史词汇
丁级词汇的交叉部分为 112条,占绝大部分。甲级词汇最少,只有一例 “汽水”。 “汽水”原来是人们生活中常用词,但由于生活水平的提高,出现了种类繁多的饮品,人们常常统称为“饮料”,可以考虑用 “饮料”替换掉“汽水”。上述词语绝大多数都是不常用的词汇,例如“火柴、冰棍儿、校徽、尼龙、的确良”等词语所指的事物已经在人们生活中基本消失,应该考虑剔除。除此之外,还有与农业生产、战争相关的词语,对留学生的汉语教学作用不大,也可以征求专家意见后考虑有选择地剔除。
5.教材高频词和统计词表的对比研究
2006年中国语言生活状况报告中发布了汉语作为第二语言教材用词调查结果,并给出了汉语作为第二语言教材中具有代表性的 1500条高频词 (苏新春,2006)。这 1500条高频词语由 12套教材统计得到,最低频次为 33次,覆盖了总语料的 77%,这样高的比例足以说明学者们在编写教材时对这些词语的认同。为此笔者对这些高频词作了进一步的统计,考察发现二字词最多,占到全部词语的 59.60%,一字词位居第二,占全部词语的 37.73%,三字词 38个,占全部词语的 2.53%。名词在 1500高频词中共计 479条,基本占全部高频词语的 1/3。在这些名词中,一字名词 99条,二字名词 359条,三字名词 20条,没有四字名词。

图7:1500高频名词字数分布
从上面的统计可以看出,二字名词的比例非常高,已经占全部名词的 72.23%。因此二字名词将是研究的重点。除此之外,高频名词中没有四字词语,这说明对外汉语教材中四字成语使用非常少,这可能和 HSK词汇大纲的收词有关,在 HSK词汇大纲中成语不在考虑范围内,今后也要加强这方面的研究。
教材中的高频名词大多是我们生活中的基础词汇,它们在《人民日报》中分布如何?在本文设计的统计词表中有多大比例?笔者对此做了详细考察,发现 479高频名词中有 466个词语都包含在 20个季度统计词表中,占全部词语的 97.29%。这足以说明,《人民日报》虽然是新闻语料,语体方面很正式,但是基本涵盖了人们日常的生活词汇。因此,选择《人民日报》语料作为实验语料完全可行。
不在《人民日报》加工出来的统计词表的词语共计 12个,它们是 “婶、太祖母、少爷、掌柜、一年、每年、每天、年轻人、期中、民族、英语、大声”。其中 “婶、太祖母、少爷、掌柜”并不是常用的称呼用语,特别是 “少爷、掌柜”现在已经基本不用。“一年、每年、每天”没有出现在《人民日报》统计词表中主要是由于切分问题,在语料中,“一年、每年、每天、年轻人”不是以一个词语的形式出现,分别被切分成两个词。“民族”在语料中以 “民族之林 /n、民族主义 /n、少数民族 /n”出现。统计词表中虽然没有 “英语、汉语”,但是 “中文、英文”都在统计词表中,这可能和《人民日报》的语体有关。
6.结语
本文以名词为例,利用语料的时间跨度和频次信息设计了两个汉语名词常用词语统计词表,并利用该词表自动过滤 HSK词汇大纲中过时的词汇,实现了词汇大纲的半自动更新,常用词语统计词表为词汇大纲中的所有词汇绘制了一个历时的词语变化图谱,为人工选取教学词汇提供有益的参考。两个统计词表在新词收取和历史词汇更新方面具有各自的优势,因此未来词汇大纲的收词应该综合利用两个统计词表的统计数据。上述方法同样也可用于其他词类的常用词语提取研究。
另外,统计词表和教材高频词的对比研究也表明,《人民日报》虽然是新闻语料,但是基本包含了汉语作为第二语言教材中的常用词汇,这为利用新闻语料开展常用词语的统计研究提供了有价值的证据。
北京语言学院语言教学研究所 1986 《现代汉语频率词典》,北京语言学院出版社。
国家汉语水平考试委员会办公室考试中心 2001 《汉语水平词汇与汉字等级大纲》 (修订本),经济科学出版社。
国家语言资源监测与研究中心 2006 《中国语言生活状况报告 2005》(下编),商务印书馆。
国家语言资源监测与研究中心 2007 《中国语言生活状况报告 2006》(下编),商务印书馆。
姜德梧 2004 《关于〈汉语水平词汇与汉字等级大纲〉的思考》,《世界汉语教学》第 1期。
李红印 2005 《〈汉语水平词汇与汉字等级大纲〉收“语”分析》,《语言文字应用》第 4期。
刘长征 2008 《对外汉语教学用词表的多元化与动态更新》,《语言文字应用》第 2期。
刘叔新 1964 《论词汇体系问题》,《中国语文》第3期。
苏新春 2006 《对外汉语词汇大纲与两种教材词汇状况的对比研究》,《语言文字应用》第 2期。
王治敏 2009 《汉语常用名词的自动提取研究——兼论“汉语水平词汇与汉字等级大纲”的词语更新问题》,《全国第十届计算语言学学术会议论文集》(CNCCL):52-58。
赵金铭 张 博 程 娟 2003 《关于修订 <汉语水平词汇等级大纲 >的若干意见》,《世界汉语教学》第 3期。
The Statistical Research on Diachron ic Changes of the Common Wordlist for Chinese Teaching
WANG Zhi-min
(College of Chinese Studies,Beijing Language and Culture University,Beijing100083,China)
statistical characteristics;textbook compilation;statistical database
Frequency and time span of corpus are used to establish two statistical databases for common nouns,which can reflect the diachronic changes of Chinese nouns by designing different time points.The databases not only provide the valuable data for collecting the new words and filtering the historical words for Syllabus ofGraded W ords and Characters for Chinese Proficiency,but also provide the beneficial reference for artificial selection of the teaching vocabulary. In order to verify its reliabilty,we make a contrast analysis of the statistical database and high frequencywords of textbook.The results show that thePeople'sDaily,as a news corpus,contains the basic common nouns for Chinese as a second language teachingmaterials.
H195
A
1674-8174(2010)04-0049-07
2010-06-18
王治敏 (1972-),女,北京语言大学副教授,博士,硕士生导师,主要从事对外汉语教学、自然语言处理研究。
教育部人文社科研究项目 (09YJC740010);国家语言资源中心平面媒体分中心课题
①本文曾在国家语言资源监测与研究中心暨平面媒体分中心成立五周年学术会议上宣读,陆俭明教授、冯志伟教授、杨尔弘教授提出了诸多宝贵意见,特此致谢。
【责任编辑 蔡 丽】
