基于时间序列相似性匹配算法的地震预测研究
2010-01-06邱剑锋蒋阿芳
郑 华,李 炜,邱剑锋,林 晨,蒋阿芳
(安徽大学计算机科学与技术学院,安徽合肥 230039)
基于时间序列相似性匹配算法的地震预测研究
郑 华,李 炜,邱剑锋,林 晨,蒋阿芳
(安徽大学计算机科学与技术学院,安徽合肥 230039)
把匹配抽象时间序列相似性的方法引入到地震预报的应用中,结合大量地震历史源数据,地震领域的专家经验知识和相关成果基础上,提出了一种简化的抽象时间序列匹配模型。该模型在对海量数据进行预处理筛选的基础上再进行时间相似性匹配,增加了横向和纵向多方位地区和多方位时间段的匹配,不同时间差和阈值的匹配,并通过大量实验对该模型进行了反复验证,同时对我国地震频繁地区近几十年的地震历史数据进行了相似性匹配实验分析,取得了可信度较高的实验结果,实验结果验证了所给时间序列相似性匹配控制策略的有效性、实用性以及算法的优越性。
时间序列;序列匹配;地震预测;算法;地震相关地区
引言
时间序列(Time series)泛指那些随时间或空间有序变化的数据集合,这些数据记录集合往往采用等时间或空间间隔进行度量。如何有效的管理和利用海量数据序列,有效的发现和理解这些数据序列背后隐含的规律和知识,已受到越来越多数据挖掘研究者广泛关注[1]。在其相应的数据挖掘系统中,时间序列的相似性查询是分析时间序列变化规律的一种重要方法[2]。对于时间序列的分类、预测及知识发现都具有重要的现实意义。比如在我们熟悉的股票,期货,具有相似性销售的产品,恒星的光谱曲线中相似性度量都具有不可替代的作用[3]。
地震序列是一维时间序列,却蕴藏着动态演化中其它变量的痕迹和信息,因此对地震序列的研究具有重要意义[4]。时间序列相似度序列匹配是在时间、震级数据库中找出与给定时间、震级序列模型相似的序列,对相似性度量的建立求解过程,是数据挖掘中一类重要问题,具体表现在大量数据中具有时间和另一性质的二维相关性[5]。在地震预报科学中,经过大量的研究和积累,专家们发现在一定的区域中地震活动具有同步涨落的现在。也就是说在一定的区域范围中的两个地区,特定震级以上的有明显震感的地震相伴发生的现象称为地震的相关现象,也称地震的区域相关性。
地震的相关性反映了地球的自转、向心力相似、地质构造的相似、板块运动等对地震发生的规律性的影响。所以寻找地震相关区域,进而预报相关的地震,是人们最常用的预报地震的方法之一。鉴于传统方法费时费力,预报不精确等特点[6]。本文把数据挖掘技术引入地震预报科学中,通过不同地区地震数目的不同,首先进行粗相似匹配,即对原始地震数据中相差一定地震数目条数以下的地震区域将其转化为粗相似格式,其次对粗相似区域中的数据项转化为时间序列,对粗相似的区域进行时间相似度匹配来发现地震相关区域,从而进行地震预报。本文首先结合地震领域的相关知识,定义了序列的相似度量模型,提出了一种基于相似度序列匹配的算法,利用相关的地震相似度全面的对时间、经纬度和震级等地震相关信息进行处理,从而快速、全面的找出地震的相关区域[7]。
1 地震相关地区的序列相似性定义及度量模型
地震相关地区相似度匹配研究可以分为以下几个部分:相似性的定义,度量模型的建立和相似度匹配算法的实现。
相似性定义和度量模型一般根据不同的需求进行定义,进而转化为一些抽象的数学模型来解决问题。传统的相似性定义是根据时间序列数据的上升或下降的趋势和需解决的问题相结合来定义[8]。比较典型的有 ARMA(auto regression moving average)模型,采用的是随机时间序列分析技术;DFT (discrete fourier transform)模型,采用的是把时间序列转化为空间中的点,对这些点进行分析处理。这些模型中都用了欧几里德距离作为序列间的相似性评价函数,也就是当两个序列间的欧氏距离小于一定的阈值时,就认为此序列相似。但在实际应用中,由于序列长度不一,采样率不同,数据多少相差较大等问题,使得欧氏距离很难直接用于解决问题。
由于地震数据记录的每一次地震发生的时间、经度、纬度、震级以及地震事件序列等其具非线性特点,传统的时间序列相似性度量模型和匹配很难使用于地震数据。
对此,本文根据地震相关领域知识,通过适当的数据预处理,将其转化为一定震级,一定时间,一定空间范围内的地震事件序列集。构成不同的地震时间序列。下面给出地震序列及相似性定义及地震序列相似性的模型。
定义1:(地震事件)把预处理过的地震数据目录中的每一条地震记录定义为一次事件。按照不同的空间属性划分为不同的地震事件集。在地震事件集上t时刻发生的地震事件记为F(t)。
定义2:(地震事件序列)在一定的区域中发生在一定的时间范围H内的地震事件集Ft={F(t)|t∈H}在时间轴上的一个排列。
定义3:(地震序列)对预处理过的地震数据目录里的地震数据提取其时间和震级,抽象为地震序列。
定义4:(完整地震序列)在某些地震区域中,对于地震序列S,在没有发生地震事件的时间上用空元素给予填充的地震序列S′。
定义5:(地震相似性)设x,y分别是两个地震序列,用函数ω(x,y),θ(x,y)来表示其相似性。令ω(x, y)=1,若|x(t)-y(t)|≤Mthreshold1;

x(m),y(m)表示x,y的震级数,x(m)-y(m)表示震级差。
Mthreshold1为年份误差的阈值,Mthreshold2为震级误差的阈值。Mthreshold1越小时间相差越小,Mthreshold2越小震级相差越小。所以x,y可以对应不同的时间点, Mthreshold1和Mthreshold2为用户给定。
定义6:(地震序列相似性模型)设X和Y为两个不同的地震序列,则X和Y的序列相似性可以用这两个序列中对应每一组数据的相似进行统计,记为相似性加权累计和来度量。两个地震序列的相似性度量模型定义为

(1)X’和Y’分别是指定范围内X和Y的完整地震序列。且序列长度相同。
(2)W(x,y)是权重函数,定义为震级大比震级小的相似对实际产生意思的系数。
相似性匹配算法可以分为两个部分:一是粗相似匹配,即在查询地震源目录时找出地震条数差值在一定的阈值margin下的地震区域,简单的说,在一个时间段内,一个地区发生了一条地震项目,另一个地区发生了几万条地震项目,那么这两个地区有相似性的可能性就极小了。二是相似性匹配,在粗相似的基础上,查询的地震序列与地震数据仓库中的地震序列记录进行比较,找出具有较高相似度的地震序列。当具备较高的相似度时,必然会反映出两个地区的地震发生具有一定规律上的先后关系。对此我们给合了地震区域的相关知识,定义了地震的相似度定义和度量模型的基础上,提出了一种基于给定阈值支持数的序列相似性匹配算法。下面给出算法的形式化描述。
输入:粗相似的差值margin;地震源目录M;经度范围latitude_r;纬度范围longitude_r。
输出:地震相似目录FreSubSeries M;


Step4;Output the result;//Num(EQS)将地震目录按空间划分区域的总数,在此为按地理位置分块后的总块数。
算法说明:
步骤:1:对中国地区按给定的经纬跨度latitude_ r,longitude_r分块。
2:统计中国地区的总块数。
3:对地震源目录M按,进行处理,若两个块中对应的地震数目总数差值在margin值之间,定义为粗相似,对粗相似的目录进行时间相似度序列匹配处理FindFreSubSeries M。
4:对结果进行收集处理,用于后续处理。

过程算法说明:
从粗相似的两块记录中,依次对每块记录中的每条记录,进行统计。若对应的年份差值统计总数count year大于Mthreshold Year且对应的震级差值统计总数count degree大于Mthreshold Degree,认为是相似区域。
在此算法中对两个地震区域序列进行匹配时,需要逐条记录进行对比,本算法在设计对地震源目录进行粗相似匹配,在利用粗相似匹配的结果进行相似性匹配,对非粗相似的区域不再进行处理,极大的提高了算法的效率。
2 实验及讨论分析
2.1 实验数据预处理
本文所采用的地震资料来源于安徽省滁州市地震局,包括1965年1月1日到2008年5月13日发生在中国境内的地震信息,地震目录共有记录349572条次地震。由于一定震级以上的地震做出预报才具有意义,所以本文选择3级以上的记录,共63165条记录。进行数据预处理的目的是为了使数据适应时间序列的相似性匹配算法,本文分别对空间窗口、时间窗口和震级进行预处理,如表1所示:

表1 部分预处理后的地震目录数据
(1)按照地震时间序列的空间窗口、震级标准(选取一定震级以上的地震)。
(2)由于地震目录数据的条数是相当的大,在存储过程中难免会出现数据不一致的现象,例如数据日期不符合现实生活中的日期,所以要将类似于这样的无效数据去掉,从而提高数据的质量,有利于数据挖掘的质量。
2.2 实验结果分析
地震的时间序列相似性是指在一定时间空间范围内,两个地区发生的地震在时间、震级方面具有相似性。比如某区域A在1995,1997,1999,2003,2004…有一定震级以上的地震,而在区域B在 1997, 1999,2001,2005,2006…也发生了地震,则A和B两个区域在时间序列相似度上具有很大的相似性,本文针对这一特点,设计了3组实验,在进行粗相似的基础上分别从不同的时间差、时空差、粗细力度差等方面进行相似性序列分布分析。
实验1:固定时间差为30天的粗粒度序列相似性分析
本实验采用4.5级以上的地震序列,时间跨度为1987-2007年范围内,对全国的相关区域进行分析研究,发现有些区域有着相似性,结果如表2所示。

表2 固定时间差为30天的部分区域同台湾地区相关次数表

图1 台湾和藏南地区固定时间差为30天的M-T图
由表2可以看出四川和台湾地区以及藏南和台湾地区的相似度最高,本文针对这两组区域时间差在30天以内的地震相关项目进行研究,发现四川和台湾地区有41次地震具有相关性,藏南和台湾地区有36次相匹配的地震项目,而且地震震级相似性也很高,具有相同的趋势和震匹配性。图1给出四川地区(经度100-105,纬度25-30)和台湾地区(经度120 -125,纬度20-25)相关地震的M-T图。图2给出了藏南地区(经度95-100,纬度25-30)和台湾地区(经度100-105,纬度25-30)相关地震的MT图。

图2 台湾和四川地区固定时间差为30天的M-T图
实验2:固定时间差为1年的粗粒度相似性分析

图3 藏中和四川-云南地区固定时间差为一年的M-T图
在实验1的基础上,我们把实验的时间阈值由30天放大到1年,部分震级有所调整的情况下(由于四川和台湾地区数据较多,震级提高到5级以上),实验结果发现多了一些区域具有相似性,其中相似度提高最明显的是四川和台湾地区以及藏中和四川-云南交界地区。图3表示了四川-云南交界地区(经度90-100,纬度25-30)和藏中地区(经度85-90,纬度30-35)的M-T图,相匹配的地震条数由16次增加到23次。图4表示了四川地区(经度100-105,纬度25-30)和台湾地区(经度120-125,纬度20-25)的M-T图,相匹配的项目由28上升到41。

图4 台湾和四川地区固定时间差为一年的M-T图
实验3:固定时间差为10天的细粒度相似性分析
在实验1和2的基础上,针对四川台湾地区和四川-云南,藏中两组地区将时间阈值缩小到10天,震级阈值缩小到5级,进行相似度更为精确的相似匹配。得到实验结果如图5和图6所示。匹配项目分别为32和10条。
3 结论
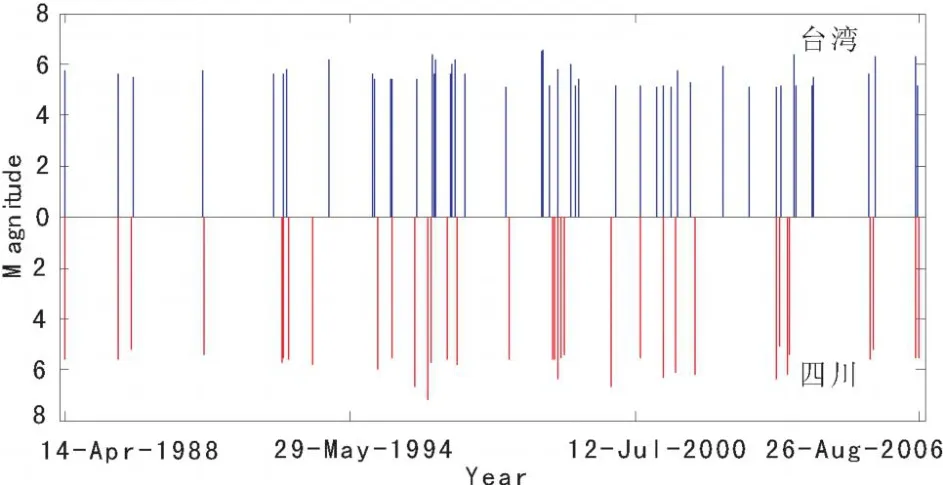
图5 台湾和四川地区固定时间差为10天的M-T图

图6 藏中和四川-云南地区固定时间差为10天的M-T图
本文对地震源数据依次进行预处理,粗相似匹配,相似性匹配。提出了相似度量模型和时间震级相似性匹配算法。可全面、高效的找到地震相似性区域。实验表明部分地震相关区域,与专家经验相比较,证实算法合理有效。为地震预报研究提供较好的平台。
[1]张保健,何华灿.时态数据挖掘研究进展[J].计算机科学, 2002,29(2):124-126.
[2]欧阳为民,蔡庆生.数据库中的时态数据挖掘研究[J].计算机科学,1998,25(4):60-63.
[3]刘念祖.时态数据挖掘的探讨[J].上海第二工业大学学报,2001,(2):27-31.
[4]张保健.时间序列数据挖掘[D].西安:西北工业大学(博士学位论文),2003.
[5]欧阳为民,蔡庆生.在数据库中自动发现广义序贯模式[J].软件学报,1997,8(11):864-870.
[6]王炜,刘悦,李国正,等.中国大陆强震时间序列预测的支持向量机方法[J].地震,2005,(4):26-32.
[7]王炜,谢端,宋先月,等.使用人工神经网络进行我国大陆强震时间序列预测[J].西北地震学报,2002,24(4):315 -319.
[8]崔万照,朱长纯,保文星,等.混沌时间序列的支持向量机预测[J].物理学报,2004,53(10):3303-3309.
The Earthquake Prediction Research Based on Time Series Similarity Matching Algorithm
ZHENG Hua,LI Wei,QIU Jian-feng,ZHU Li-jin,JIANG A-fang
(School of Computer Science and Engineering,Anhui University,Hefei230039,China)
On the basis of analyzing the newly time sequence research achievement nowadays,several definitions on seismological zone relativity are put forward in this paper for integrating the large amount of history earthquake source data and the experimental expert know ledge in seismological field.At the same time,the time sequence similarity-matching model of the relevant seismological zone is presented,and then it is implemented through several correlative experimental simulations.Based on the sequence similarity-matching model,a sequence-matching algorithm is given with seismological similarity.Furthermore,by discovering the history earthquake database in recent several years,some experiments are provided to analyze longitudinal thick-granularity sequential similarity and thin-granularity sequential similarity.Finally,the experimental result has found its satisfactory way out by using the proposed algorithm to support earthquake prediction.
time series;sequence match;seismological prediction;algorithm;seismological relevant zones
TP391
A
1009-9735(2010)02-0022-05
2009-10-11
安徽省自然科学基金(090412063),安徽省滁州市科技计划项目(200852)。
郑华(1984-),女,安徽黄山人,安徽大计算机科学与技术学院硕士生,研究方向:计算机;李炜(1969-),女,安徽蚌埠人,硕导,博士,研究方向:计算机;邱剑锋(1980-),男,安徽合肥人,博士,研究方向:计算机;林晨(1985-),男,安徽马鞍山人,硕士,研究方向:计算机 ;蒋阿芳(1985-),女,安徽淮北人,硕士,研究方向:计算机。
