Web挖掘研究
2009-10-26谢海艇
摘要:随着网络的飞速发展,Web挖掘技术已成为一个研究热点。本文就Web挖掘与相关研究进行了对比,介绍了Web挖掘的概念、分类及步骤,最后给出了Web挖掘的研究方向。
关键词:Web挖掘;数据挖掘;信息检索
随着数字化信息时代的到来,网络日渐成为人们获得信息的重要途径。然而网络中信息量巨大且分散无序,Web用户经常发现难以找到其所需的信息,造成“信息过载,知识匮乏”[1]的现状。通用搜索引擎给人们提供了进行信息检索的方法,但也存在查准率不高、查全率不能保证等问题。Web挖掘技术正是应这一需求而出现的一项新技术。人们运用Web挖掘技术,寻找网络中有趣的、潜在的、有用的模式或隐藏的信息,并利用这些信息加快用户检索的效率,从而使网络资源更好的为人们服务。
1 Web挖掘定义与相关研究
1.1 Web挖掘的定义
Web挖掘[2]就是从Web页面和Web用户访问活动中发现、抽取有用模式和隐藏的信息。它是以从Web上挖掘有用知识为目标,以数据挖掘、文本挖掘、多媒体挖掘为基础,并综合运用计算机网络、数据库与数据仓储、人工智能、信息检索等技术,将传统的数据挖掘技术与Web结合起来的一门新兴学科。
1.2 Web挖掘与数据挖掘
数据挖掘[3]是从数据库的大量数据中揭示出隐含的、潜在有用信息的频繁过程。从广义观点来说,数据挖掘就是从存放在数据库、数据仓库或其它信息库中的大量数据中挖掘有趣知识的过程。
Web 挖掘从数据挖掘发展而来,在研究方法上有很多相似之处。但是,Web 挖掘与数据挖掘相比有许多独特之处。首先,Web 挖掘的对象是大量、异质、分布的 Web 文档。其次,Web 在逻辑上是一个由文档节点和超链接构成的图,因此 Web 挖掘所得到的模式可能是关于 Web 内容的,也可能是关于Web 结构的。
1.3 Web挖掘与信息检索
信息检索[4]是自动获取相关文档的同时尽可能少的获取不相关文档,其主要的目标是索引文本,寻找有用的文档。
Web挖掘与信息检索在一些方面有所不同。首先,信息检索是目标驱动的,用户需要明确提出查询要求,其目的在于帮助用户发现资源;Web 挖掘是机会主义的,其结果独立于用户的信息需求,揭示文档中隐含的知识是它的目标;第二,信息检索使用精度和查全率来评价其性能;而 Web挖掘采用受益度、置信度、简洁性等来衡量所发现知识的有效性、可用性和可理解性。
2 Web挖掘的分类
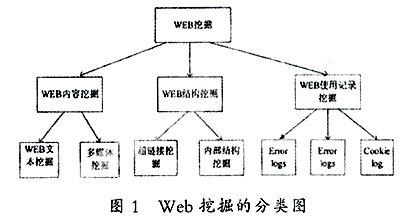
Web挖掘大致分为三类:Web内容挖掘(Web content mining)、Web结构挖掘(Web structure mining)、Web使用记录挖掘(Web usage mining).下图为Web挖掘的分类图:
xieht01.tif
2.1 Web内容挖掘
Web内容挖掘是指从 Web上的网页内容及其描述信息中获取潜在的、有价值的知识模式,以实现Web资源的自动检索,提高Web数据利用率的过程。Web内容挖掘根据不同的标准,有多种不同的分类方法。按挖掘对象来划分包括对文本文档的挖掘和多媒体文档的挖掘 ;按方法来划分有信息查询观点的挖掘和数据库观点的挖掘;按内容又可分为对Web 文档的挖掘和对搜索结果的挖掘。
2.2 Web结构挖掘
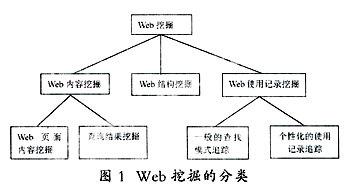
Web结构挖掘的基本思想是将Web看作一个有向图,它的顶点是Web页面,页面间的超链接就是有向图的边。然后利用图论对 Web的拓扑结构进行分析。这种思想源于引文分析,即通过分析一个网页链接和被链接数量以及对象来建立Web自身的链接结构模式。在Web结构挖掘领域最著名的两个算法是:PageRank算法和HITS算法。它们的共同点是使用一定方法计算Web页面之间的超链接质量,从而得到页面的权重。
2.3 Web使用记录挖掘
Web使用记录挖掘又称为Web日志挖掘,主要目标是从Web的访问记录中发现感兴趣的模式;分析不同Web站点的访问日志可以帮助人们理解用户的行为和Web结构,从而改进站点的结构,或为用户提供个性化的服务。Web使用挖掘的基本流程包括四个阶段:数据预处理、挖掘算法实施、模式分析、可视化。
3 Web挖掘的过程
Web挖掘的处理流程[5]包括如下四个步骤:资源发现、信息选择和预处理、模式发现、模式分析。
1)资源发现
网络爬虫在线收集Web文档、网站的日志等数据,并从中得到有用的数据。
2)信息选择和预处理
剔除Web资源中无用信息并将信息进行必要的整理,如Web文档中自动去除广告连接、去除多余格式标记、英文单词的词干提取、高额低频词的过滤、汉语词的切分等。
3)模式发现
自动进行模式发现。可以在同一个站点内部或多个站点之间进行,以自动发现Web站点的共有模式。
4)模式分析
验证、解释上一步骤产生的模式,并进行可视化。
4 Web挖掘研究方向
Web挖掘的应用非常广阔,不但涉及页面信息的提取、站点的分析和设计,而且在基于Internet 的电子商务方面也有很好的应用前景。
今后几年Web挖掘研究的主要方向有:(1)Web知识库的动态维护、更新,各种知识和模式的融合、提升,以及知识的评价综合方法;(2)基于Web挖掘和信息检索的、高效的、具有自动导航功能的智能搜索引擎相关技术的研究;(3)研究和开发基于Web的多层数据体系结构和智能集成系统,提供相应的查询语言,优化和维护机制;(4)现有的数据挖掘方法与技术的改进及其向Web数据的扩展,挖掘算法的适应性和时效性的研究;(5)Web挖掘的相关技术在电子商务领域的应用研究等。
5 总结
随着网络的飞速发展,Web挖掘技术已成为一个研究热点。本文就Web挖掘与相关研究进行了对比,介绍了Web挖掘的概念、分类及步骤,最后给出了Web挖掘的研究方向。
参考文献:
[1]Raymond Kosala,and Hendrik Blockeel.Web Mining Research: A Survey[J]. SKGKDD Explorations,July 2000.
[2] 韩家炜,孟小峰,王静,等.Web挖掘研究[J].计算机研究与发展,2001,38(4):405-410.
[3] Jiawei Han,Micheline Kamber 。范明译。数据挖掘概念与技术[M]。北京,机械工业出版社,2000.
[4] 王继成,萧嵘,孙正兴,等.Web信息检索研究进展[J].计算机研究与发展,2001(2).
[5]Yuefeng Lia,Ning Zhong.Web mining mobel and its applications for information gathering[J].Knowledge-Based Systems,2004(17):207-217.
收稿日期:2009-04-28
作者简介: 谢海艇(1982-),男,山东淄博人。研究方向:信息检索、数据挖掘等。
