神经网络思想切入数据库查询优化的应用研究
2009-09-29吴树荣
吴树荣
摘要:神经网络是一门新兴的技术,由于人工神经网络由大量的单元组成非线性大规模自适应系统,其自组织及学习和联想记忆能力可以很好的逼近许多非线形映射关系。这一特性在数据库查询优化的许多过程可以得到极大的利用。本文将对神经网络思想切入数据库查询优化的实际应用进行探讨。
关键词:神经网络 数据库 查询优化 应用
1 神经网络简介
神经网络是大脑的一个组成部分,人工神经网络模型是基于生物学中的神经网络的基本原理建立的。它是以大脑作为研究基础的,其目的在于模拟大脑的某些方面的机理,实现大脑某些方面的功能,因此,进行神经网络实现技术研究的目的,也即进行神经计算机研究的目的不是寻求一种传统计算机的替代物,而是要开垦那些人类“唾手可得”,而传统计算方式却“举步维艰”的领域。
从数学的角度可以归纳为以下几个基础属性:
1.1.1 非线性:人工神经元可以表述为激活和抑制两种基本状态,这就是一种非线性关系。
1.1.2 非局域性:人工神经网络系统是以人工神经元之间的相互作用表现信息的处理和存储能人。系统的整体行为不仅取决于单个神经元的状态,而且取决于它们之间的相互作用,用此来模拟大脑的非局域性。
1.1.3 非凸性:非凸性是指人工神经网络的演化过程在满足一定条件下取决于某特定函数,而且该函数具有多个稳定点,这将导致在不同边界条件下得到不同的结果,这就是系统演变的多样性。
1.1.4 非定常性:表现在人工神经网络具有自组织、自适应和自学习能力。
数据库系统,特别是大型数据库系统,完全可以看作是分布式系统。
在分布系统论中假定了分布系统中的大量处理单元都是自律要素,并且通过自律要素间的相互作用体现整体性能相信息处理能力。自律要素的处理能力可以是非常复杂,也可能异常简单。相对而言,在人工神经网络模型中,一般假设神经元是一个非常简单的处理单元.每个单元向其它单元发送兴奋性或抑制性信号。单元表示可能存在的假设,单元之间的相互作用则表示单元之间存在的约束。这些单元的稳定激活模式就是问题的解。
我的观点是,在数据库查询优化领域,作为模拟大脑的神经计算方式具有如下的重要特点:①在短时间内寻找好的,但不一定是最好的解答。②由大量的简单的处理单元协同处理问题。③在模糊、不完整或冗余,甚至矛盾的数据基础上进行问题求解。④容错能力强。
关于以上特点中的第一点,其实这是启发式算法的共同特点之一。启发式算法是这样定义的:一个基于直观或经验构造的算法,在可接受的花费下给出带解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度不一定事先可以预计。
在某些情况下,特别是实际问题中,最优算法的计算时间使人无法忍受或因问题的难度使其计算时间随问题规模的增加以指数级速度增加,此时只能通过启发式算法求得问题的一个可行解。
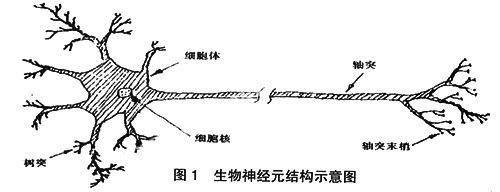
神经网络方法是模拟大脑的,所以其输入就是晶枝,处理单元就是神经元,可以进行“抑制”和“兴奋”两类处理,最后通过突触传送给其他的神经元。以下是自然神经网络图(见图1):
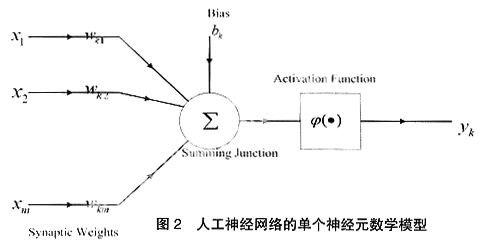
以及神经元的数学模型:
2神经网络在数据库查询优化中的具体应用
查询是数据库使用者进行的主要操作之一。在这方面,最初的查询优化方法是试用那些没有坏的影响的方法。大部分的变化,比如增加索引、改变模式或者修改事务的长度都对全局有影响,有时是有害的负面影响。而重写查询使之以更高的速度运行则只有有利的影响。
在查询事务处理中,锁查询优化是一个重要内容,下面结合神经网络思想进行分析。
关于锁查询优化,下面是一些建议:①使用特殊的系统程序来处理长的读操作。②消除不必要的封锁。③根据事务的内容将事务切分成较小的事务。④在应用程序允许的情况下,适当降低隔离级别。⑤选择适当的封锁粒度。⑥只有在数据库很少被访问时才修改有关数据定义的数据。⑦考虑划分。⑧减少访问热点。⑨死锁监测周期的查询优化。
每个建议都可以独立于其他建议来运用,但是仔细的分析会发现,要很好的处理这些建议,神经网络算法的特点似乎很合适。
比如说,在谨慎降低隔离级别的过程中,可以使用简单的单层前向神经网络思想。
低隔离级别是有益的,但也是由风险的,在这个过程中可串行化的价值也在体现当中。
为了确定隔离级别,可以进行相应的试验,可以不断的重复执行一个对所有帐户的余额求和的查询事务以及若干个转帐事务。试验的参数是执行这些转账事务的线程数。
初步试验可以在数据库使用前模拟进行,目的是获得理想的结果参数,包括可串行化的影响,死锁可能性,阻塞可能性,隔离级别等等。
然后构建一个如下的单层前向神经网络:
在单层神经网络中,只有输入层和输出层,输出层主要通过对输入层的输入数据和同理想输出结果的比较,确定其权数,最后,用确定了权数的神经网络应用到实际问题中。
也就是说,实质上经历了三个阶段,先确定理想结果参数,然后确定权数,最后投入应用。
另外,在减少热点的应用中,有时插入数据的事务都会将每个新的数据项同一个惟一的表示练习起来。当多个插入事务并发执行时,他们必须协调工作以避免将同一个标识联系到不同的数据项上。
一般的,可以通过给数据库建立一个计数器来实现。每个插入事务首先对计数器加1,接着完成它的插入操作和其他操作,最后提交。问题是这个计数器很可能会成为瓶颈,因为根据两阶段封锁机制,事务只有提交时才可以释放它在计数器上的锁。
在这里可以用一个采用非线性激活函数的前向神经网络。比如将激活函数设定为符号函数,阀值为0,这样一个系统是可以识别XOR问题的,他的分类识别问题很强,而且简单,完全可以应用在协调上述工作上。
从以上例子可以看出,神经网络和数据库优化的主要切入点在于学习和识别,在查询优化过程中遇到识别问题的地方,都可以试试神经网络算法。而学习的能力,则完全可以应用于一些繁琐的维护,是系统尽可能的拥有自维护能力。

参考文献:
[1]高红云,王丽颖,汪再秋.分布式数据库查询优化分析及实例[J].软件导刊.2008.(02).
[2]周园春.科学数据网格分布式查询框架及其关键技术研究[D].中国科学院研究生院(计算技术研究所).2006.
