基于HMM的中文姓名识别方法研究此
2009-03-30杨霞黄陈英
杨 霞 黄陈英
[摘要]以2000年1月-12月《人民日报》大约80万汉字语料为基础,利用基于隐马尔可夫模型并结合统计来评价在真实文本中构成中文姓名的能力,实现中文姓名的自动识别。实验测试表明;准确率达91.5%,召回率为89.5%。
[关键词]中文姓名识别隐马尔可夫模型中文信息处理
中图分类号:TP3文献标识码:A文章编号:1671-7597(2009)0210064-01
一、引言
在汉语的书面表现形式中,词与词之间是没有自然界限的,自动分词就成了中文信息处理的基础工程[1],而未登录词(人名、地名、机构名、新词和专业术语)的识别是汉语自动分词的难题之一,其识别率和识别速度的高低将直接影响分词的效果。中文姓名在未登录词中占很大比例,统计显示:中文姓名占未登录词的15%[2],可见,中文姓名的自动识别对未登录词识别是极其重要的。传统的姓名识别方式主要包括:基于统计[3-4]、基于语料库[5]、结合决策树等。
姓名识别也是一种分类问题,每一个字或者是或者不是姓名的一部分。近年来,隐马尔可夫模型(HMM,Hidden Markov Models)在文字分类尤其是标注中取得了很大的成功。本文以《人民日报》2000年的语料为基础,基于HMM建立了中文姓名的识别模型,开发了中文姓名自动识别实验系统,经测试准确率达91.5%,召回率为89.5%。
二、基于HMM的中文姓名识别
(一)隐马尔可夫的基本概念
隐马尔可夫模型(Hidden Markov Model,HMM)是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有响应概率密度分布的状态序列产生。所以,隐马尔可夫模型是一个双重随机过程具有一定状态数的隐马尔可夫链和显示随机函数集。HMM创立于20世纪70年代。80年代得到了传播和发展,成为信号处理的一个重要方向,现已成功地用于语音识别,行为识别,文字识别以及故障诊断等领域。
HMM有5个组成部分,记为一个五元组(N,M,π,A,B),其中:N是模型状态集的状态数目;M是每个状态可能的观察值数目;π是初始状态空间的概率分布;A是与时间无关的状态转移概率矩阵;B是给定状态下,观察值概率分布。
(二)模型框架
首先定义文字的属性,在上下文中每一个词只能有一个属性,要么是姓名的一部分,要么就是非姓名。相应地,在隐马尔可夫模型的状态中,对中文姓名的识别其实只包含两种类型:中文姓名(Person-Name)与非姓名(Non-Person-Name)。另外,还有两个特殊的状态,分别是句子起始状态(start-0f-Sentence)和句子结束状态(End-0f-Sentence)。我们使用一个二元统计语言模型来计算词在每个区域内(name-class)的似然值。
本系统中所用的模型包括三个部分:(1)模型选择Name-class;(2)模型产生Name-class内部的第一个词;(3)模型产生Name-class内部的所有其它词。
相应的公式分别是:
其中Nc表示当前的Name-class,NC-I表示前一个Name-class,w-I表示前一个类中最后一个字或者词,wfirst表示当前类中的第一个字或者词。
Name-class内部产生所有非第一个词的模型:
还有一个特殊的词“+end+”,在Name-class内部如下公式计算最后一个词的概率:
其中,c()表示事件在训练数据中出现的次数。当然统计的时候需要用某种平滑方法例如Good-Turning来解决数据稀疏的问题。
(三)识别
中文姓名识别的任务可归结为:给定一个句子W=wlw2…Wn2,要求找出NC=NCINC2…NCn使得P(Nclw)最大,其中NCi是词,它的状态有两种:中文姓名PN或NPN。
由贝叶斯法则,P(Nc|w)=P(NC,W)/P(w),对于给定的句子,P(W)是固定的,所以只需要考虑P(NC,w),展开即如公式(1)-(4)所示。这样,姓名的提取可以看成特殊的分词过程,系统在解码或识别过程中采用Viterbi束搜索算法。
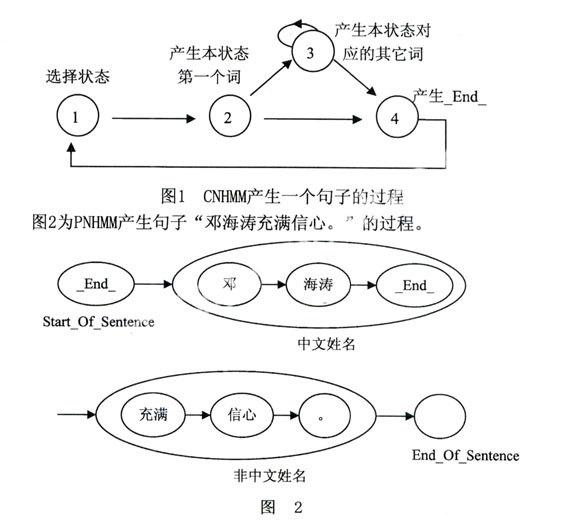
用一个各态遍历HMM作为产生句子的模型,称为PNHMM。该模型有四种状态,PN,NPN,Start-Of-Sentence和End-0f-Sentence。使P(Nc,w)最大化可转化为P(Path,W)最大化,Path=S1S2…Sn是状态转移路径。
PNHMM产生一个句子的过程如图1所示。
三、实验结果及讨论
分词采用的也是Viterbi束搜索算法,用来训练的语料为2000年《人民日报》约80万字;从中文网站上下载50篇文章作为测试系统性能的测试数据,总共有2000句话,大约有5万字。其中含有中文姓名304个。统计结果,共识别出中文姓名272个,未识别出的中文姓名32个,召回率89.5%。识别为中文姓名的共有297处,误报为19个,准确率91.5%。
识别错误的例句:
1.候选人为何齐鲁。(漏识别)
2、受聘于张氏律师事务所。(错召回)
基于HMM的各态遍历过程对中文姓名进行识别,可以提高识别的精度,但仍存在一些需要解决的问题:(1)构造模型的语料有限,中文姓名在真实文本中的覆盖率不完全,对识别产生很大影响;(2)对于那些小概率稀疏事件没有较好考虑,造成识别错误;(3)外国人名和中文姓名有些具有相似的语言特征,在识别中容易引起错误。
