XBRL层次结构与财务信息数据挖掘
2009-02-05姚靠华洪昀
姚靠华 洪 昀
【摘 要】 XBRL是XML在商业报告领域的规范化,发展步伐迅猛。XBRL吸收了XML的结构层次特点,并有其独特的地方。它通过分层机制,有利于把握商业事实内在语义,便于计算机理解,促进了财务信息数据挖掘。
【关键词】 XBRL; XML; 层次结构; 数据挖掘
XBRL(eXtensible Business Reporting Language,可扩展商业报告语言)是用于企业财务数据电子交流的语言,是一种基于XML语言的实现(准确的说是规范化)。上世纪90年代末美国首先提出XBRL理论,很快为实务界所采纳,短短几年之内,XBRL得到超乎寻常的发展。在XBRL国际组织(xbrl.org)的推动下,目前XBRL在全球范围内已经被大多数会计师事务所、贸易机构、软件开发商、金融机构、投资者以及政府机构采用。
现在对XBRL的研究普遍存在仅从技术上理解的倾向,但其实际情况并非如此。XBRL的广泛传播并不是仅仅是由于技术规范的成熟和标准的整齐划一,更重要的是因为它对于现实生活中商业行为的深刻理解和语义层面的把握,才使得不同语法形式下(外在表现为异质平台)信息共享成为可能,极大地促进了财务信息数据挖掘的进行,满足了决策者对有用信息和知识的需求。本文将探讨XBRL的层次结构特点,以说明为何它能有效地把握语义信息及由此而产生的数据挖掘问题。
一、XML层次结构与计算机理解
XBRL是XML在商业报告领域的应用。XML是一种面向计算机的使用元数据标识信息的标准化结构;XBRL则给出了元数据的一个规范化,并简单定义了财务报告文档信息标记的语义关系。
XBRL,或者说XML之所以要采用层次结构的方式,是因为人和计算机对事物的理解,都是分层的。
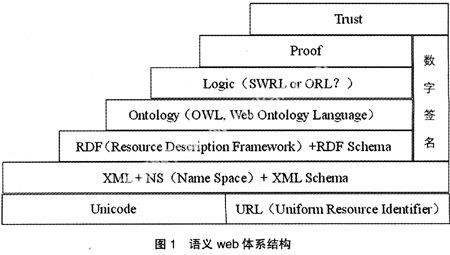
笔者采用自然语言描述这样一个事实——“红星股份有限公司2006年年报总资产是1 000万元”,我们理解这一语句的过程大致分为这么几步:分析语句语法结构为“<主语名词词组>(<‘是><数量词宾语>=”,此语法结构对应的语义解释规则为“(等值于)(个体—>属性,数量值)”,据此语句解释为“(等值于)(红星股份有限公司—>总资产,1 000万元)”;至此解释并没有完成,而只是把对象语言的自然语言形式转化为了元语言的逻辑函数形式,对对象语言的理解也转化为了对逻辑函数的理解。要理解这一逻辑函数项,需要解释等值关系、年报总资产等语义要素的含义,对这些要素的理解又需要诉诸于更上一层的元语言。由此每一层次的语言都需要在更上一层的元语言中实现语义解释。当然,如此反复将导致无限循环,可能存在语义解释系统都以一定的假设(尤其是对某些形而上命题的假设,亦即本体论)为起点。以W3C总监Tim Berners-Lee在XML2000年会上提出的语义Web为例,其意义解释层次结构如图1所示。
这一层次结构中,只有XML层、RDF层、Ontology层、Logic层是为语言解释而设计的,这四个层次本身还可以进一步划分。XML文档描述的是信息内容,NS定义了信息内容的访问地址标识,XML Schema则规定了文档的语法格式;RDF提供了标准的元数据语义描述规范;而本体论(ontology)在RDFs基础上定义了领域共享概念的形式化显式说明,Ontology一般分为顶层本体、领域本体、任务本体、应用本体;逻辑层则(Logic)提供了基于本体进行逻辑推理的规则,它目前有SWRL(Semantic Web Rule Language)与ORL(OWL Rule Language)两个提案,未形成标准。
相比HTML及PDF的会计信息表述形式,XML的优势在于可标识信息的语义项,这种标识是对计算机而言的。以“投资收益1 000万元”为例,PDF与HTML等方式只是通过网络传递人类能通过视觉系统将其中的信息项“投资收益”与值项“1 000”相对应起来的、显示在屏幕上或打印到纸上的“电子图纸”;而在XML里,我们可以通过标签来唯一地标识信息项,如
XML的思想精髓在于分层,实现“信息显示与信息内容相分离”、“信息内容与信息语法格式相分离”、“语法格式与语义规则相分离”、“语义规则与本体论相分离”。分层机制将语义解释转化为了对树形结构文档的解读问题,这使得计算机能够使用一个相似的递归算法来实现,大大降低了工程实践的难度,也从实践的角度佐证了语义解释亦是递归计算。不过不能因此而认为树形结构的XML文件就完整地表示了信息语义关系,XML不过是信息的语法形式,尽管语义解释的元语言语句也可以是XML(事实上Schema、RDF、OWL都采用树形文档结构),但逻辑上两者处于不同层次上。
狭义地讲,计算机对XML的理解是根据Schema文档定义的语法要素(element)及要素之间的组合关系(complexType)识别出XML实例文档中语法要素,并据此建立语法要素与信息内容之间的关联。但如果没有RDF、OWL、Logic层次的支持,计算机理解只可能是限定于特定语言层次上的形式化理解。从广义上看,XML是一个包含了RDF、OWL、Logic的完整体系结构,计算机理解实质上是借助于递归算法,对各层次的关系完整把握。
二、XBRL的层次结构
作为XML的一个应用模式,XBRL的层次结构也有其特点。可以将现有的XBRL分为三层:技术规格(specification)、分类标准(Taxonomy)和实例文档(Instance Documents)。
技术规格,或称说明、规范,主要用于定义XBRL的各种专门术语,描述了XBRL文件的结构,详细规定了XBRL分类的标准和XBRL实例文档的语法和语义。虽然有XML元素和属性的语义上的表述,但XBRL规格是一项侧重技术的文件,目的在于定义一项符合规范的XBRL文档。
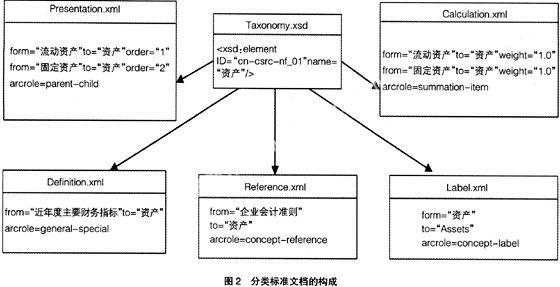
分类标准是财务报告发布的语法格式,也部分定义了各会计报表要素的“语义关系”。如“资产=负债+所有者权益”、“主营业务收入是利润表的要素”、“Assets表达资产的概念”等等。分类标准由名为Taxonomy.xsd的XML Schema文档与相关联的五个XML链接库文件(Definition.xml,Calculation.xml, Presentation.xml,Label.xml,Reference.xml)组成,Taxonomy定义的是报表的语法形式,链接库文件定义的是报表语法要素的语义关系,其结构如图2所示。
XML链接库文件是使用链接语言(XLink)定义的,并不局限于外在形式上标签之间的链接(HTML链接则是外在形式上的链接),而是主要用来描述信息内容标签(元数据)之间的联系。XBRL的五个链接库文件定义的是XBRL Schema文档中各标签之间的联系,属于XBRL Schema的元语言范畴。显然,XBRL并未遵循语义Web的体系结构,其语义表达功能较为简单。
Definition链接库描述Schema文件中元素概念之间的关系,这些关系可取general-special、similar-tuples、essence
-alias、requires-element等四种值,分别表示一般与特殊的种属关系、不同XML视图中的元组间的定义等价关系、概念间的相似关系、跟随出现关系。Calculation链接库定义了元素间的线性运算关系,具体关系式为“TO=FROM1*WEIGHT1+FROM2*WEIGHT2 +……+FROM-n*WEIGHT-n”。Label链接库定义了Schema文档中的元素与XML中标记的对应关系,实现一个元素与多个标记相关联。Presentation链接库规定了元素展现的父子关系与兄弟元素的展现次序。Reference链接库建立了元素到元素涵义解释的权威参考文献链接。Label与Presentation定义的都是XBRL实例文档的展示问题,而Reference显然是为便于人类阅读者索取各元素权威解释而设计的,它们都不涉及信息项的语义关系定义;定义Schema元素语义关系的只有Definition与Calculation。
实例文档是一个企业根据XBRL规范和XBRL分类标准做成的财务报表,它必须要同时满足分类标准的定义和规范的限制。实例文档封装了具体的商业事实(fact),根据信息的汇集程度分为条目(item)、元组(tuple)、组(groups)三个不同层次。其中,条目通常与一个数字型的事实对应;元组是事实的联合体,等同于关系数据库里的一条记录,组是实例文档的根结点,由相关联的数据项的集合构成。在不知道分类标准的情况下,实例文档没有任何意义。用户需要借助与分类标准和相应的软件才能从XBRL实例中提取所需要的数据并加以分析。
可以看到,XBRL并没有完全遵循语义Web的规范,试图通过Definition链接库和Calculation链接库来把握财务对象的语义,这必将是不充分的。技术规格虽然也有一些专门术语语义层次上的表述,但总的来看,与XML存在的缺陷一样,XBRL缺乏本体层概念关系定义和逻辑层的计算规则定义。
W3C也试图致力于弥补这一缺陷。2004年提出标准化的本体语言OWL就代表了这方面的努力。OWL由OWL Lite、OWL DL(Description Logics)、OWL Full三个并列的子集构成,OWL Lite用于表示只需一个分类层次和简单约束关系的形式语义关系;OWL DL用于表示需要最强表达力且需要保持计算的完备性(即所有结论可计算)与可判定性(所有计算能够在有限时间内完成)的形式语义关系;OWL Full用于需要最强表达力且无法提供计算完备性与可判定性保证的形式语义关系。其中,OWL DL也提供了完备的实例、类、属性、关系等元语言对象的表示工具。也就是说,OWL层提供了充分定义XBRL范畴概念关系的形式工具。
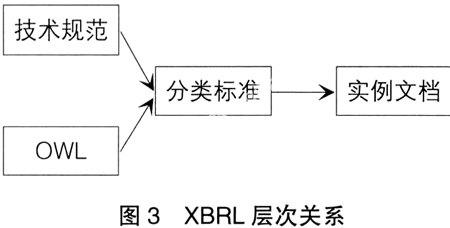
若OWL能够得到充分的完善,必将为XBRL提供有力支持,弥补技术规范语义表达方面的不足。可以设想,较为理想的XBRL层次关系如图3所示。
三、XBRL层次结构引致的财务数据挖掘
数据挖掘(Data Mining,DM)是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的,但又是潜在的有用信息和知识的过程。相对于传统的数据分析,数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。
因为信息具有强烈的时效性,一旦为所有人所知晓,信息的价值就荡然无存。在当今瞬息万变的商业环境中,竞争的主要方式是信息的竞争,传统的事后分析型的数据分析方法将被事前探索型的数据挖掘所取代。而与此同时,信息提供者之间也存在着激烈的竞争,如财务信息与非财务信息之间的竞争也日益激烈。XBRL的提出不但为财务信息提供者增加了竞争的筹码,也直接推动了财务数据挖掘的开展。
XBRL的优势在其清晰的层次关系和语义表达能力。XBRL的层次结构在财务数据挖掘的优势表现在:
(一)跨平台使用
由于采用了XML的架构体系,在不同的操作系统下,如Windows、Unix和Linux等,XBRL文件无需修改就可以直接使用。在不同的应用软件中,即使所用的数据库不同,只要转换成XBRL格式,也可以实现数据的交换。跨平台使用的关键在于XBRL实现了语法格式与语义规则分层,在图3中表现为技术规范和分类标准的分层,从而使得XBRL在不同的技术实现之间没有障碍。
(二)数据跟踪
XBRL可以在不同的信息之间建立连接,跟踪相关的信息线索,自顶向下地考察数据源直到底层的数据,方便了对企业报告的阅读和数据分析。XBRL的技术结构使其具有良好的动态分析功能,计算机可以读懂XBRL标记的含义,而且操作员也可以很容易地从文档中获取有价值的信息。当搜索引擎找到所需的信息时,它能进一步追踪下去找到数据的最初来源及其它与该信息有关的资料。同时,完善的定义与唯一的XBRL要素使信息减少了模糊性。数据跟踪的关键则在于OWL与分类标准的分层结构,通过对OWL的深入挖掘可发现分类标准中各元素之间的内在联系,在图3中表现为OWL与分类标准的分层。
(三)搜索快速、准确
XBRL使用标签描述数据的含义。在进行数据搜索时,不是像HTML那样根据字面内容进行搜索,而是根据标签的语义进行定位,这样搜索引擎就能够快速、准确地找到用户所需的特定信息。同时,由于XBRL采用标签来标记数据,可以通过应用程序对搜索结果中的数据进行汇总。其效率远远高于目前互联网上的PDF、WORD和HTML等文件格式。而实现这一目标的要点在于图3中分类标准与实例文档的分层,清晰的分类有利于满足丰富实例中信息的挖掘。
XBRL清晰的层次结构关系不但支持了数据收集和数据预处理过程,也为各种适用于不同范围与层次的数据挖掘工具提供了良好的材料。如在数据的预处理过程中,为对XBRL文档进行存储和校验,可以借助于IPEDO XML智能处理平台,利用其Schema Manager和XML Rule模块在OWL和分类标准层次上搜集相关信息,然后对XBRL实例文档进行校验。
总之,XBRL的层次结构特点为财务数据的挖掘提供了极大的方便,这是XBRL得到广泛推崇的原动力之一。
四、结论
XBRL承继了XML分层的机构特征,有利于计算机对语义信息的把握和数据挖掘工具的使用,这是XBRL在短短几年的时间里得到迅猛发展的重要原因。但是,XBRL作为XML在财务方面的实现,也存在同样的缺陷,缺乏本体层次上的有力支撑。相信随着对其研究的深入开展和各领域本体构建的完善,能够弥补这方面的缺陷。●
【主要参考文献】
[1] 李雄飞,李军.数据挖掘与知识发现[M].北京:高等教育出版社,2003.
[2] Bryan Bergeron. XBRL语言21世纪的财务报告[M]. 北京:中国人民大学出版社,2004.
[3] Tim Berners-Lee. Semantic Web - XML2000. http:∥www.w3.org/2000/Talks/ 1206-xml2k-tbl,2000-12-06.
[4] XBRL International. Extensible Business Reporting Language (XBRL)2.1 Specification. Http://www.xbrl.rog,2003-12-31.
