基于神经网络的车牌识别系统
2009-01-06吕品品
吕品品
[摘 要]本文提出了一种基于单片机的车牌识别自动装置的设计思路,给出了系统的设计方案,并详细介绍了它的工作原理及其软硬件设计,提出了一种字符分割的新方法,利用BP神经网络原理对车牌中的汉字、字母及数字进行了分类识别,识别后由单片机控制将数据填入相应的信息管理系统。
[关键词]单片机 车牌识别 BP算法
[中图分类号]U47[文献标识码]A[文章编号]1007-9416(2009)11-0003-02
为了解决年审人工登记车牌号速度慢、效率低的问题,特开发此基于单片机的车牌自动识别系统,该系统通过扫描正在审查车辆的车牌,经过处理后可以直接把车牌号数据上传到车辆管理信息系统中。采用该系统,可以加快车辆的审查速度。基于单片机的车牌自动识别系统其关键技术是对车牌号码的读入和识别。为了节约成本和减小体积,该系统用单片机来控制实现。本文将详细介绍如何用单片机来控制读入车牌号码图像和识别读入图像以及如何把识别出的字符传给计算机。
1 系统工作原理
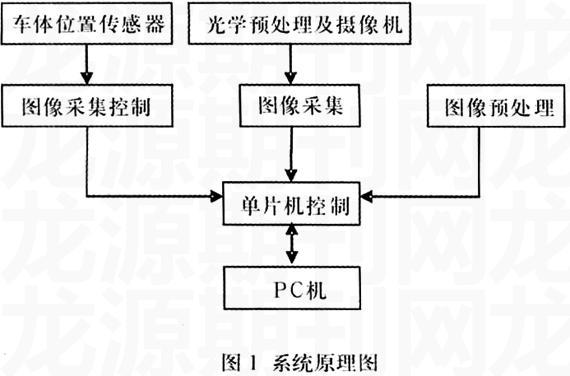
车牌号码自动识别系统的原理框图如图1所示。一个典型的车牌识别系统主要包括车牌图像采集、图像预处理、特征提取、特征匹配和数据库5个模块。在本系统中,还加入了单片机控制部分。
系统主要工作过程如下:
当汽车通过检测站时车体位置传感器发出一个信号给图像采集控制部分,它的控制摄像机采集一幅汽车图像送入单片机进行预处理,然后将处理后的图像传给主机,由主机的图像处理模块从输入的图像中找到牌照的位置,对牌照进行字符切分,得到各个字符的点阵数据;再由字符识别模块利用这些数据进行识别,然后把识别出的字符通过串口传给单片机进行进一步的处理,最后由单片机控制写入相应的信息管理系统。该系统的技术难点主要是在主机中如何实现牌照的定位、切分以及牌照字符的识别,还有单片机如何实现控制等。
2 系统主要构成
2.1 图像采集控制以及图像采集
将车体位置传感器固定于某一位置,当有汽车经过时它就会发出一个信号给图像采集控制部分,这时图像采集控制系统发送一个控制信号给图像采集模块,则摄像机开始工作,采集一幅含有汽车牌照的图像。
2.2 图像预处理
为了加快系统的处理速度,有必要将部分图像预处理过程做成硬件方式。就本系统而言,从汽车图像中找出牌照位置是减少后级处理数据量的关键步骤,因而在系统中将牌照定位的部分做成硬件处理,主要利用数字图像输入板实现。数字图像输入板采用专用的多媒体芯片实现。这套芯片功能较强,可编程性好,使用方便,性能稳定,适于恶劣环境的视频输入。
视频信号经过A/D转换,数字解码和彩色空间转换后,成为24bits的RGB三分量数据流,然后发送到主机。对于RGB三分量数据流可以采用基于直方图指数平滑的阈值分割法进行二值化,转化为一幅二值化的黑白图像,存入缓冲区中,并将转化后的数据传给PC机。
2.3 牌照定位
根据现在牌照的特点:我国汽车牌照的长度为45厘米,宽度为15厘米,共有8个字符(包括一个点符号)。通过上面操作过程,我们在PC机上可获得一幅二值化的黑白图像的数据。本文采用逐行扫描的办法,由于车牌位于汽车的下部,且为避免汽车上的广告和标语等的干扰,采用从上往下的逐行扫描策略,根据车牌上的文字笔划变化的频率,从左向右逐个象素扫描,当某行笔划变化频率在某特定宽度达到预先设置α时,记下该行号和该笔划变化区域的起点和终点,再根据车牌的长宽比例特征预计车牌区域,当该区域具有相似特征的行达到设定范围β时,则表示该区域即是车牌的所在区域。其中α和β需根据获取的车牌图像质量及车牌在图像中的比例大小进行设置。
2.4 字符分割
在准确找到车牌的位置后,下一步就是把车牌上的字符串分割成一个个标准大小的字符块。字符分割并不是真的把所要的字符块从原图像块中分割下来,仅仅是把所要识别的字符的准确位置找到。对于该系统,共有8个字符,汽车牌照上出现的字符有3类,汉字字符只包括部队,公安系统和全国各省省名的简称,另外还有26个英语字母和10个数字字符。一般民用牌照第一个字符是汉字,且是各省市的简称,如“京”、“津”、“沪”、“苏”等,第二个字符是大写英文字母,如“A”、“B”、“C”等,接着是一个点“·”,第四个字符可能是英文字母,也可能是阿拉伯数字,第五至第八个字符均为阿拉伯数字。如“鲁C·12345”就是最典型的车牌号码。对汉字我们把它分成18×9的块,把字母和数字都分成5×5的方块。具体方法是在第一步搜索中找到了字符块左上角的起点(sx,sy),对固定的目标来说每个字符对起点都有固定的偏移量,其偏移量P[8]={0,18,23,24,29,34,39,44};这样就可以把字符块分成8块。如第4个字符的起点坐标为(sx,sy+24)长宽为5×5。
2.5 字符识别
在对字符进行分割的时候我们已经把字符划分成方块,所以可以采用神经网络的方法来对字符进行识别。对于并行识别的BP网络,可以让汉字、字母或数字分别送到各自的网络分别识别,由于BP网络的容错能力强,对于文字的某些笔划出现断线或笔划少了一部分,仍然能正确识别,这样既提高了识别率,识别速度也有所改善。
2.5.1 BP算法简介
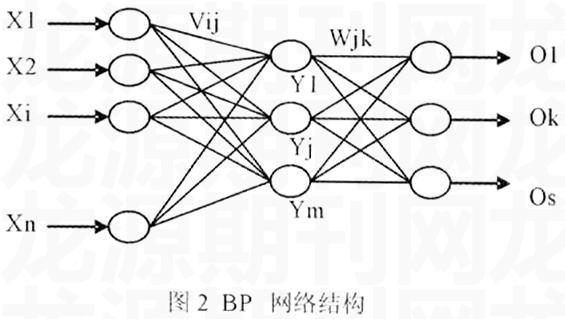
典型的三层BP网络结构如图2所示,它包含输入层、隐含层和输出层,相邻层节点全互连,同层节点之间不相连。BP算法的学习过程由正向传播和反向传播组成。正向传播过程中,输入模式从输入层经过隐含层逐层处理,并传向输出层,每一层神经元的状态仅影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入反向传播,将误差信号沿原来的连接通路返回,通过修改连接权与各神经元的阈值,使得误差信号最小。
2.5.2 BP算法用于字符识别
经过车牌定位,分隔等操作已经将车牌中的汉字、字母和数字形成了灰度图像且已经被提取出来,对于汉字采用18×9的网格,字符(字母或数字)是5×5的网格,其中黑色的网格用1表示,白色的网格用0表示。通过分割操作将字符输入值确定后,就可以利用BP网络进行训练,从而得出识别的字符。
2.5.3 结果分析
经过大量实验证明,网络训练目标误差为0.01,学习率u取0.6,连接权的初始值在[0,0.2]之间随机取值时网络的判别精度较高。
对字符识别时,如果取输入层节点25个,隐含层为15个,输出层节点6个,则该BP网络的学习速率与误差限的关系是:当误差限确定时,学习速率越大,学习次数越少,同时,网络的训练精度也随之降低。
在学习速率给定的条件下,隐含层节点越多,所需学习的次数越少,BP网络的记忆能力越强,但是,隐含层节点过多,会造成网络因为振荡而失去判别能力。
在本系统中,图像采集控制和图像采集部分通过单片机控制,然后对采集的图像进行预处理;由于单片机的资源有限,且处理速度慢,因此牌照定位、字符分割、字符识别由PC机通过软件实现。
2.6 通信模块
此模块主要实现单片机与PC机之间的通信。对已经通过上位机识别出的字符通过串口(RS-232)先发送给下位机,然后由下位机控制再传入车辆信息管理系统,该系统可通过VC++编程实现。
3 结语
本文给出了基于单片机的车牌自动识别的设计方案,利用单片机控制对含有车牌的图像进行一系列的操作,如读入图像、车牌定位及分割和车牌识别等,最后由单片机控制实现与主机的通信,从而实现了将识别出的信息自动填入信息系统的功能,既节约了成本又减小了该装置的体积,使用方便灵活。采用该装置登记车牌号方便快捷,而且该系统成本不高,具有一定实用价值。
[参考文献]
[1] 吴捷.汽车号牌自动识别系统[J]. 贵州科学,1999.3.
[2] 周翟和,刘建业.纸币号码读入识别系统的单片机实现[J].工业控制计算机,2002
[3] 万国红,王敏,王心汉等。基于神经网络的汽车牌照自动识别技术研究[J]. 计算机工程与应用,2002
[4] 韩力群.人工神经网络理论、设计及应用[M].北京:化学工业出版社,2002.
