结合注意力机制和特征加权融合的高效跌倒检测模型
2025-02-21牟雪楠余洁镱王胤胡文军




摘 要:跌倒已成为公共安全最大的风险之一,及时发现跌倒是开展有效救助的首要前提。基于计算机视觉的目标检测是当前跌倒检测的主流方法,但真实场景中的复杂因素导致现有模型仍面临准确率不高、鲁棒性不强和部署困难等问题,在EfficientDet基础上提出轻量级跌倒检测模型FD-EfficientDet,该模型首先将EMA注意力机制引入主干网络来增强对输入数据的理解和表示能力,提升检测准确率;其次,设计EMA-Fused-MBConv模块用于主干网络,加快模型训练和防止模型退化;最后,提出SKIPS-BiFPN结构并用其构建Neck层,实现主干网络不同阶段特征的加权融合,进而增强模型鲁棒性。实验结果表明,FD-EfficientDet模型相比EfficientDet模型mAP提升17.65%,鲁棒性、轻量化等方面具有较好优势。
关键词:跌倒检测;EfficientDet;轻量级;鲁棒性;准确性
中图分类号:TP183;TP391.4 文献标识码:A 文章编号:2096-4706(2025)02-0038-08
Efficient Fall Detection Model Combining Attention Mechanism and Feature Weighted Fusion
MU Xuenan1, YU Jieyi1, WANG Yin1,4, HU Wenjun1,2,3
(1.School of Information Engineering, Huzhou University, Huzhou 313000, China; 2.Huzhou Key Laboratory of Aquatic Robot Technology, Huzhou University, Huzhou 313000, China; 3.Zhejiang Province Key Laboratory of Smart Management and Application of Modern Agricultural Resources, Huzhou 313000, China; 4.Zhejiang Xingjian Medical Union Technology Co., Ltd., Huzhou 313399, China)
Abstract: Fall has become one of the greatest risks to public safety, and timely detection of fall is the primary prerequisite for performing effective rescue. Object Detection based on Computer Vision is currently the mainstream method for fall detection. However, due to the complex factors in the real scenes, the existing models still face problems such as low accuracy, weak robustness, difficult deployment, and so on. The lightweight fall detection model FD-EfficientDet is proposed based on EfficientDet. Firstly, the model introduces the EMA Attention Mechanism into the backbone network to enhance the understanding and representation abilities of input data, improving detection accuracy. Secondly, the EMA-Fused-MBConv module is designed for the backbone network, to accelerate model training and prevent model degradation. Finally, the SKIPS-BiFPN structure is proposed and used to construct the Neck layer, to realize feature weighted fusion from different stages of the backbone network, thereby enhancing the robustness of the model. The experimental results show that the FD-EfficientDet model improves the mAP by 17.65% compared with the EfficientDet model, and it has good advantages in robustness, lightweight, and other aspects.
Keywords: fall detection; EfficientDet; lightweight; robustness; accuracy
DOI:10.19850/j.cnki.2096-4706.2025.02.007
0 引 言
世界卫生组织指出,每年因跌倒导致的死亡人数占公共安全导致死亡人数的近6%,跌倒已成为公共安全最大的风险之一[1]。并且随着老龄化社会的到来加重,跌倒的风险和后果变得更加严重。因此,研究和开发高效、准确的跌倒检测方法具有重要的现实意义,不仅能够及时提供帮助,减少伤害,还能显著减轻医疗系统的负担。
目前,跌倒检测方法主要包括基于环境设备的检测方法[2-4]、基于穿戴式传感器的检测方法[5-8]和基于计算机视觉的检测方法[9]。基于环境设备的检测方法存在误报率较高,鲁棒性较差等缺点,尤其是在复杂的家庭环境中,容易受到家具和其他障碍物的干扰。而基于穿戴式传感器的检测方法则易受温湿度等环境因素的干扰,并且依赖用户的主动佩戴,存在忘记佩戴或佩戴不当的缺点。随着手机、摄像头等移动端设备的广泛使用,基于计算机视觉的检测方法已成为当前跌倒检测的主流方法。该方法通过分析视频或图像数据,旨在给定的场景帧中快速检测并对目标进行精准定位,具有适用性广、实时性强等优势。此外,基于计算机视觉的方法能够利用深度学习技术,不断提高检测准确率和鲁棒性,并且可以集成到智能家居系统中,实现全天候的监控和保护,极大地提高了跌倒检测的效率和可靠性。
近年来,多种基于计算机视觉的跌倒检测方法被提出,例如Min等人[9]使用Faster-RCNN方法分析人体和家具的空间关系并实现了对目标活动特征的检测,获得了较好的跌倒检测准确率,但其实验场景较为理想,并无外界干扰因素,鲁棒性无法保证。针对场景中外界因素干扰的情形,Zhao等人[10]提出在Faster-RCNN模型的基础上使用多分支特征金字塔网(Multi-Scale Feature Pyramid Network, M-FPN)和注意力区域建议网络(Squeeze-and-Excitation Region Proposal Network, SE-RPN),通过融合不同尺度特征图和增强模型对关键信息的捕捉能力来减小环境干扰影响。Xu等人[11]将深度SORT算法中的级联匹配及IoU匹配引入到YOLOv3结构,将不同时间帧中的目标进行关联,进而实现了外界干扰的处理。谢辉等人[12]通过数据增强和引入注意力机制子网络,增强模型特征选择能力以及实现对输入图像不同特征进行动态权重分配,进而提升了YOLOv3对外界干扰的处理能力。Chen等人[13]提出一种在复杂背景下使用Mask-CNN和注意力引导的双向LSTM模型(Long Short-Term Memory Model, LSTM),通过同时关注空间和时间方面的信息来处理外界干扰问题。本质上,上述方法是通过投入更多的计算资源来换取更好的性能,而且这些方法的网络结构较为复杂、计算量较大,这些因素限制了这些方法在移动终端上的应用。同时,上述方法需要训练大量的数据集来确保检测精度,需要消耗大量时间和人力来收集数据,这些因素都进一步影响了上述方法在实际跌倒检测领域的应用。
为了更好地解决上述问题,在EfficientDet基础上设计轻量级跌倒检测模型FD-EfficientDet。具体地,首先使用EMA注意力机制(Efficient Multi-scale Attention, EMA)替换主干网络中原SE注意力机制(Squeeze-and-Excitation Attention, SE),目的是通过增强主干网络对输入数据的理解和表示能力,以提高模型检测的准确性;其次,提出EMA-Fused-MBConv模块并用其替换主干网络第2-4阶段的MBConv模块,以减小主干网络层数和合理分配计算资源,进而防止模型退化和加快模型训练速度;最后,基于BiFPN结构提出了SKIPS-BiFPN结构,并用其构建Neck层,通过新增跨层数据流充分融合主干网络不同阶段的输出特征和,以增强模型鲁棒性。
1 相关工作
1.1 双阶段检测模型
典型的双阶段检测模型有Faster-RCNN[14]模型和Mask-RCNN[15]模型等,这里仅对Faster-RCNN进行回顾,Faster-RCNN模型结构包括Backbone、Region Proposal Network(RPN)和Classification and Regression三部分。
在Faster-RCNN模型中,其主干网络Backbone包含图像压缩和特征提取两个步骤,前者的作用是压缩输入图像以便降低后续的计算成本,而后者则是从压缩后的图像中获取特征图(Feature Map)。Region Proposal Network是候选区域生成模块,此模块首先通过滑动窗口机制在特征图的每个像素点上生成多个预定义大小的锚框来捕捉所有可能出现的目标,之后,将这些锚框输入到Class Prediction和Box Prediction分支中,前者的作用是预测锚框中是否有目标,后者是通过回归调整锚框的大小和位置以生成候选区域,并最终输出预测得分较高的候选区域(Proposal)。Classification and Regression是目标分类及边界回归模块,此模块通过ROI Pooling将不同维度的Proposal池化到固定维度并输入到Class Prediction和Box Predicition中,以输出每个Proposal的类别概率分布及检测框的预测坐标。
Faster R-CNN通过RPN模块,使模型检测拥有较高的准确率,但也因此导致其检测速度较慢。另外,Faster-RCNN模型结构相对复杂,参数量较大,训练Faster-RCNN模型需要大量的计算资源和时间成本。
1.2 单阶段检测模型
1.2.1 EfficientDet模型
该模型于2020年由Tan等人[16]提出,其结构包括Backbone、Neck和Class/Box Prediction三部分。在EfficientDet模型中,其主干网络Backbone为EfficientNet主干网络,它由3×3标准卷积和MBConv两种卷积模块构成,分8个阶段的输出特征。Neck部分是特征融合模块,它由多个双向特征金字塔BiFPN重复堆叠组成,此结构通过双向特征传播机制实现了浅层结构上的位置信息与深层结构上的语义信息之间的交互传递,并最终在最后一个BiFPN上融合输出两路特征。Class/Box Prediction是类/框预测模块,该模块包含Class Prediction和Box Prediction两条分支,分别接收Neck的输出进行卷积处理,以生成每个位置对应的边界框坐标预测和类别概率分布。
与传统目标检测模型相比,EfficientDet在保持准确率的同时大幅减少了参数量和计算量,适合在移动端进行部署。但EfficientDet因在主干网络中使用MBConv模块,使得大部分显存资源投入非计算操作以及SE注意力机制参数更新抖动较大,导致了其训练速度较慢和产生过拟合现象。另外,对于EfficientDet中的双向特征金字塔BiFPN,一方面缺乏对高分辨率特征图的重复使用,另一方面BiFPN在垂直方向因特征流交互较少而面临特征融合不充分问题,在检测任务的角度该模型的鲁棒性不强。
1.2.2 YOLOv3模型
该模型由Redmon等人[17]提出,其结构包括Backbone、Neck和YOLO Head三部分。在YOLOv3模型中,其主干网络Backbone采用DarkNet-53主体结构,由3×3标准卷积和Residual模块组成,前者的作用是初步特征提取和空间信息捕捉,以确保输入图像的特征可以被后续模块有效提取,后者的作用是更深层次提取特征,并且其通过残差连接来缓解梯度消失,提高计算效率。Neck为多尺度特征融合模块,由Conv Set模块和1×1标准卷积等结构组成,Conv Set用于融合和细化特征图以提供高质量的特征表示,1×1标准卷积用于调整通道数来降低计算成本。YOLO Head为检测模块,由1×1标准卷积和3×3标准卷积组成,用于输出预测目标的边界框位置坐标和类别概率分布。
YOLOv3模型相对与EfficientDet和Faster-RCNN来说,其检测速度更快,更适合用于视频分析和实时监控等应用,同时通过引入多尺度检测策略,可以更好地检测不同尺寸的目标。但是,YOLOv3对输入图像的质量和背景要求较高,在复杂背景情况下,检测任务会受到较大影响,鲁棒性不强。
2 FD-EfficientDet模型
2.1 FD-EfficientDet模型框架
如上所述,EfficientDet具有参数量小和检测速度快的优势,但其准确率、训练速度及鲁棒性方面有明显不足。导致不足的原因有:1)主干网络中SE注意力机制对特征的局部细节处理能力不强;2)MBConv模块中深度可分离卷积增加了主干网络层数和将大部分GPU资源投入非计算操作;3)BiFPN对特征流交互不充分和缺少对高分辨率特征图的使用。为此,本文将EMA注意力机制引入主干网络,通过增强主干网络对输入数据的理解和表示,以提高检测准确率;其次,设计EMA-Fused-MBConv模块并将其用到主干网络浅层,通过减少主干网络层数和合理分配GPU资源来防止模型退化和加快模型训练速度;最后,提出SKIPS-BiFPN结构并用其构建Neck模块,一方面充分融合特征流,另一方面充分利用高分辨率特征图和增强模型鲁棒性。提出的FD-EfficientDet跌倒检测模型结构如图1所示。
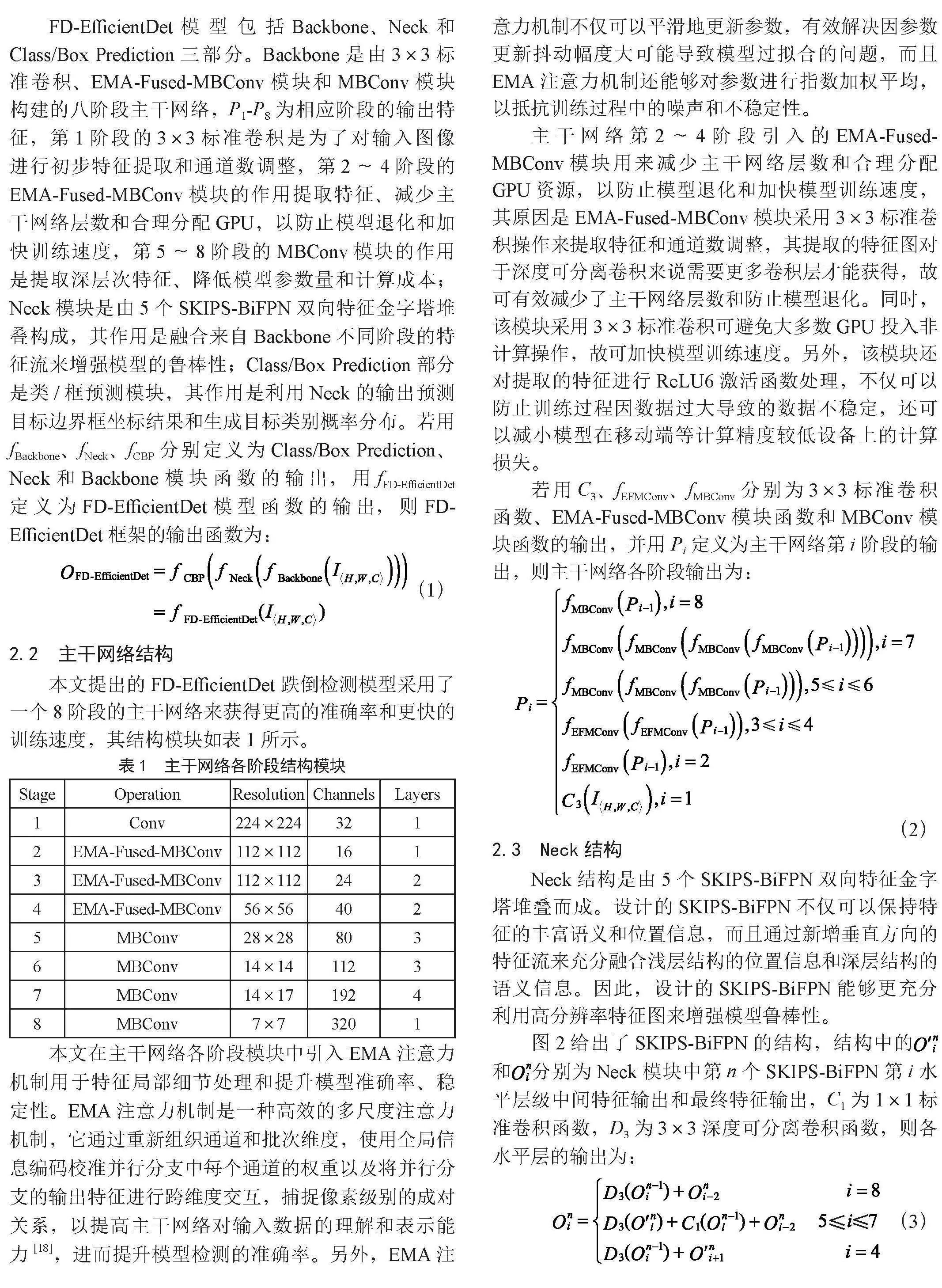
FD-EfficientDet模型包括Backbone、Neck和Class/Box Prediction三部分。Backbone是由3×3标准卷积、EMA-Fused-MBConv模块和MBConv模块构建的八阶段主干网络,P1-P8为相应阶段的输出特征,第1阶段的3×3标准卷积是为了对输入图像进行初步特征提取和通道数调整,第2~4阶段的EMA-Fused-MBConv模块的作用提取特征、减少主干网络层数和合理分配GPU,以防止模型退化和加快训练速度,第5~8阶段的MBConv模块的作用是提取深层次特征、降低模型参数量和计算成本;Neck模块是由5个SKIPS-BiFPN双向特征金字塔堆叠构成,其作用是融合来自Backbone不同阶段的特征流来增强模型的鲁棒性;Class/Box Prediction部分是类/框预测模块,其作用是利用Neck的输出预测目标边界框坐标结果和生成目标类别概率分布。若用fBackbone、fNeck、fCBP分别定义为Class/Box Prediction、Neck和Backbone模块函数的输出,用fFD-EfficientDet定义为FD-EfficientDet模型函数的输出,则FD-EfficientDet框架的输出函数为:
(1)
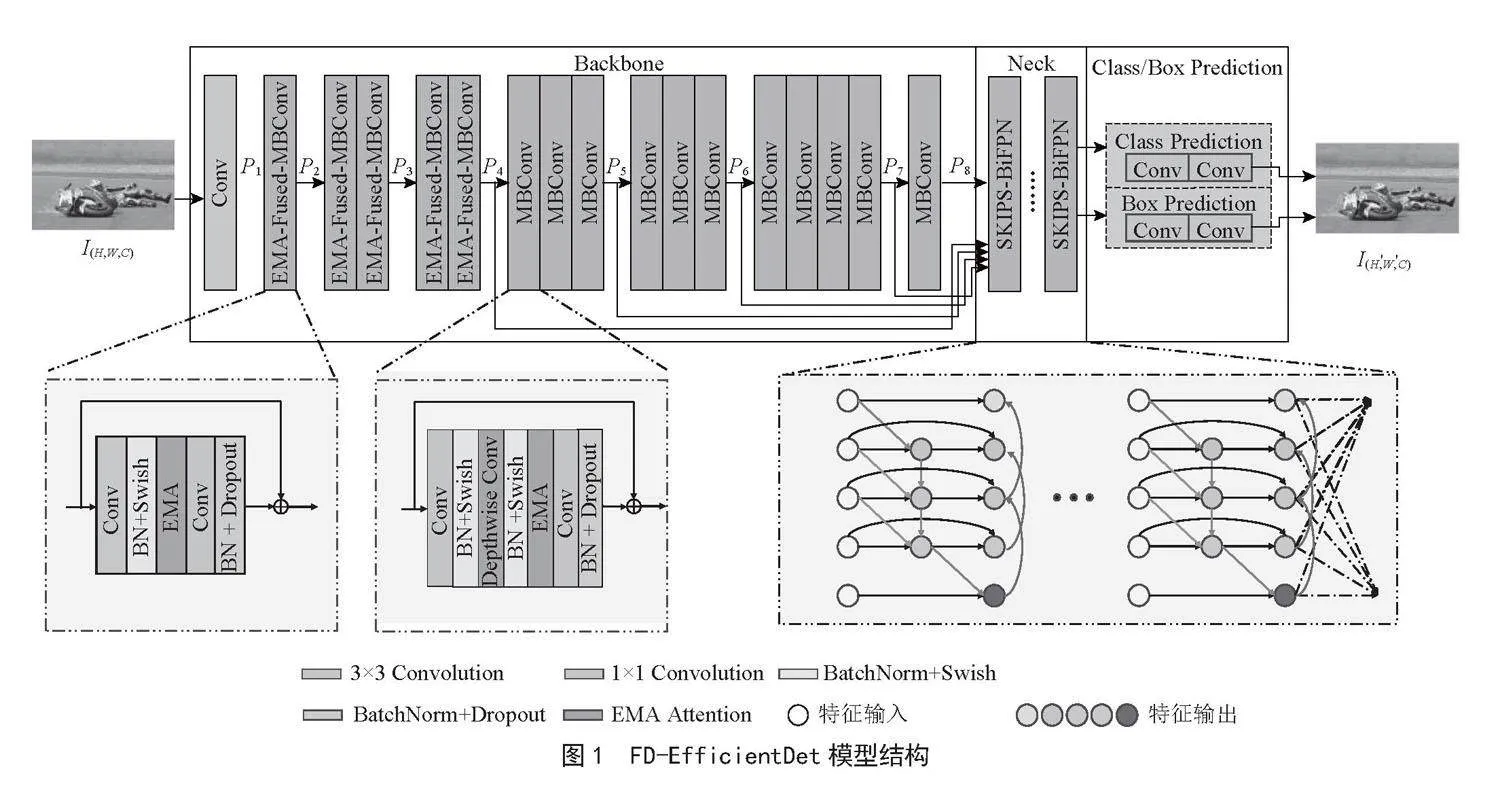
2.2 主干网络结构
本文提出的FD-EfficientDet跌倒检测模型采用了一个8阶段的主干网络来获得更高的准确率和更快的训练速度,其结构模块如表1所示。
本文在主干网络各阶段模块中引入EMA注意力机制用于特征局部细节处理和提升模型准确率、稳定性。EMA注意力机制是一种高效的多尺度注意力机制,它通过重新组织通道和批次维度,使用全局信息编码校准并行分支中每个通道的权重以及将并行分支的输出特征进行跨维度交互,捕捉像素级别的成对关系,以提高主干网络对输入数据的理解和表示能力[18],进而提升模型检测的准确率。另外,EMA注意力机制不仅可以平滑地更新参数,有效解决因参数更新抖动幅度大可能导致模型过拟合的问题,而且EMA注意力机制还能够对参数进行指数加权平均,以抵抗训练过程中的噪声和不稳定性。
主干网络第2~4阶段引入的EMA-Fused-MBConv模块用来减少主干网络层数和合理分配GPU资源,以防止模型退化和加快模型训练速度,其原因是EMA-Fused-MBConv模块采用3×3标准卷积操作来提取特征和通道数调整,其提取的特征图对于深度可分离卷积来说需要更多卷积层才能获得,故可有效减少了主干网络层数和防止模型退化。同时,该模块采用3×3标准卷积可避免大多数GPU投入非计算操作,故可加快模型训练速度。另外,该模块还对提取的特征进行ReLU6激活函数处理,不仅可以防止训练过程因数据过大导致的数据不稳定,还可以减小模型在移动端等计算精度较低设备上的计算损失。
若用C3、fEFMConv、fMBConv分别为3×3标准卷积函数、EMA-Fused-MBConv模块函数和MBConv模块函数的输出,并用Pi定义为主干网络第i阶段的输出,则主干网络各阶段输出为:
(2)
2.3 Neck结构
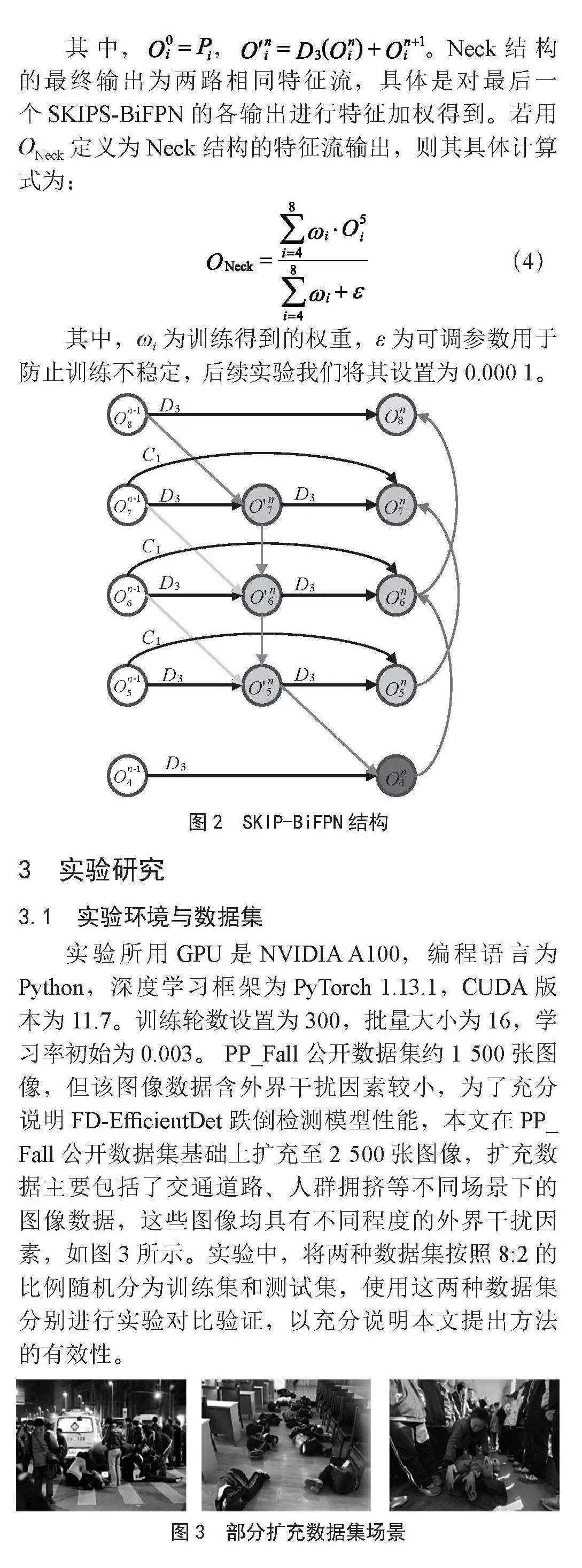
Neck结构是由5个SKIPS-BiFPN双向特征金字塔堆叠而成。设计的SKIPS-BiFPN不仅可以保持特征的丰富语义和位置信息,而且通过新增垂直方向的特征流来充分融合浅层结构的位置信息和深层结构的语义信息。因此,设计的SKIPS-BiFPN能够更充分利用高分辨率特征图来增强模型鲁棒性。
图2给出了SKIPS-BiFPN的结构,结构中的和分别为Neck模块中第n个SKIPS-BiFPN第i水平层级中间特征输出和最终特征输出,C1为1×1标准卷积函数,D3为3×3深度可分离卷积函数,则各水平层的输出为:
(3)
其中,,。Neck结构的最终输出为两路相同特征流,具体是对最后一个SKIPS-BiFPN的各输出进行特征加权得到。若用ONeck定义为Neck结构的特征流输出,则其具体计算式为:
(4)
其中,ωi为训练得到的权重,ε为可调参数用于防止训练不稳定,后续实验我们将其设置为0.000 1。
3 实验研究
3.1 实验环境与数据集
实验所用GPU是NVIDIA A100,编程语言为Python,深度学习框架为PyTorch 1.13.1,CUDA版本为11.7。训练轮数设置为300,批量大小为16,学习率初始为0.003。 PP_Fall公开数据集约1 500张图像,但该图像数据含外界干扰因素较小,为了充分说明FD-EfficientDet跌倒检测模型性能,本文在PP_Fall公开数据集基础上扩充至2 500张图像,扩充数据主要包括了交通道路、人群拥挤等不同场景下的图像数据,这些图像均具有不同程度的外界干扰因素,如图3所示。实验中,将两种数据集按照8:2的比例随机分为训练集和测试集,使用这两种数据集分别进行实验对比验证,以充分说明本文提出方法的有效性。
3.2 评价指标
本文为了对FD-EfficientDet模型进行性能评估,采用Precision(P)、Recall(R)、mAP和F1分数(F)分别来衡量模型正确检测正类别样本的能力,正确检测真实目标的能力,在不同类别上检测平均表现,及全面性,具体如下所示:
(5)
其中,TP为模型正确地将正类样本分为正类的个数。FP为模型错误地将负类样本分为正类的个数。
(6)
其中,FN为模型错误地将正类样本分为负类的个数。
(7)
其中,N为类别数量,APi为第i个类别的平均准确率即Precision-Recall曲线下的面积。
(8)
3.3 实验结果与分析
3.3.1 EMA注意力机制对比实验
为获得更好的准确率,将EMA注意力机制入主干网络。经验证,引入EMA注意力机制后模型准确率明显提升,具体实验结果如图4所示。
3.3.2 EMA-Fused-MBConv模块对比实验
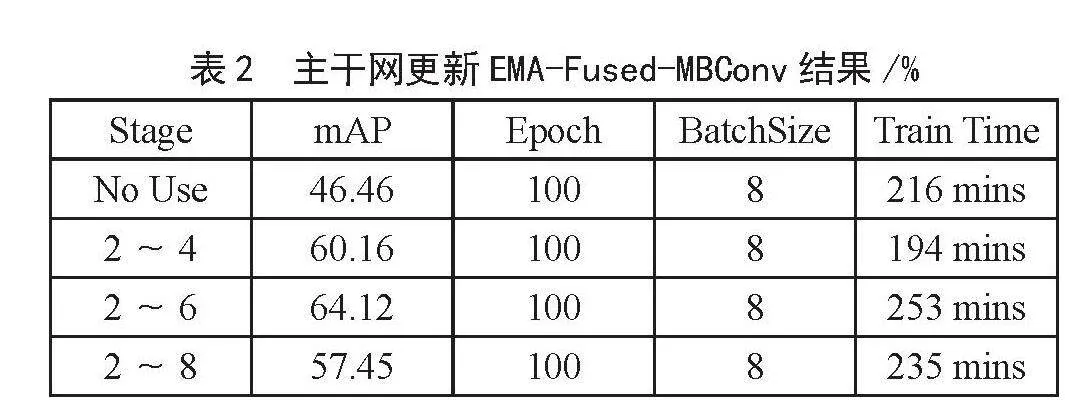
为了加快模型训练速度和防止模型退化,本文提出了EMA-Fused-MBConv模块,并将其引入到主干网络的浅层,该结构避免了将大部分GPU资源用于数据读取而不计算以及SE注意力机制参数抖动的问题,与此同时还提高了主干网络对特征的表达能力。然而,在实际应用中,直接确定要替换的MBConv模块数量是不切实际的。因此,本文通过多次实验对比,找到了最佳替换方案。具体实验结果如表2所示。
由表2可见,将主干网络第2~4阶段的MBConv模块替换为EMA-Fused-MBConv模块后,100个Epoch的训练时间从216 mins缩短为194 mins,节省了近10%的训练时间,并且mAP增长13.7%。而将第2~6阶段的MBConv模块替换为EMA-Fused-MBConv模块后,虽然模型的mAP相较于替换第2~4阶段的MBConv模块多增长3.96%,但训练时间从216 mins增加到253 mins,增加近17%。而将第2~8阶段的MBConv模块替换为EMA-Fused MBConv模块后,mAP和训练时间均表现不佳。故本文认为将主干网络第2~4阶段的MBConv模块替换为EMA-Fused-MBConv模块,FD-EfficientDet跌倒检测模型综合性能最佳。实验结果表明,使用EMA-Fused-MBConv模块可以显著提升模型的训练速度和稳定性,同时保持较高的检测性能。
3.3.3 Neck模块对比实验
为了增强模型鲁棒性,提出SKIPS-BiFPN模块,并用其构建Neck层,其一方面对特征流更充分地整合深层结构上的语义信息和浅层结构上的位置信息,另一方面更充分使用高分辨特征图,从而实现增强模型鲁棒性。经实验验证,FD-EfficientDet综合性能明显改善,具体实验结果如表3所示。
由表3可见,使用SKIPS-BiFPN模块构建Neck模块,FD-EfficientDet跌倒检测模型的mAP增长了5.91%,且其余各项评价指标也均有明显提升。除此之外,该结构未明显增加模型参数。
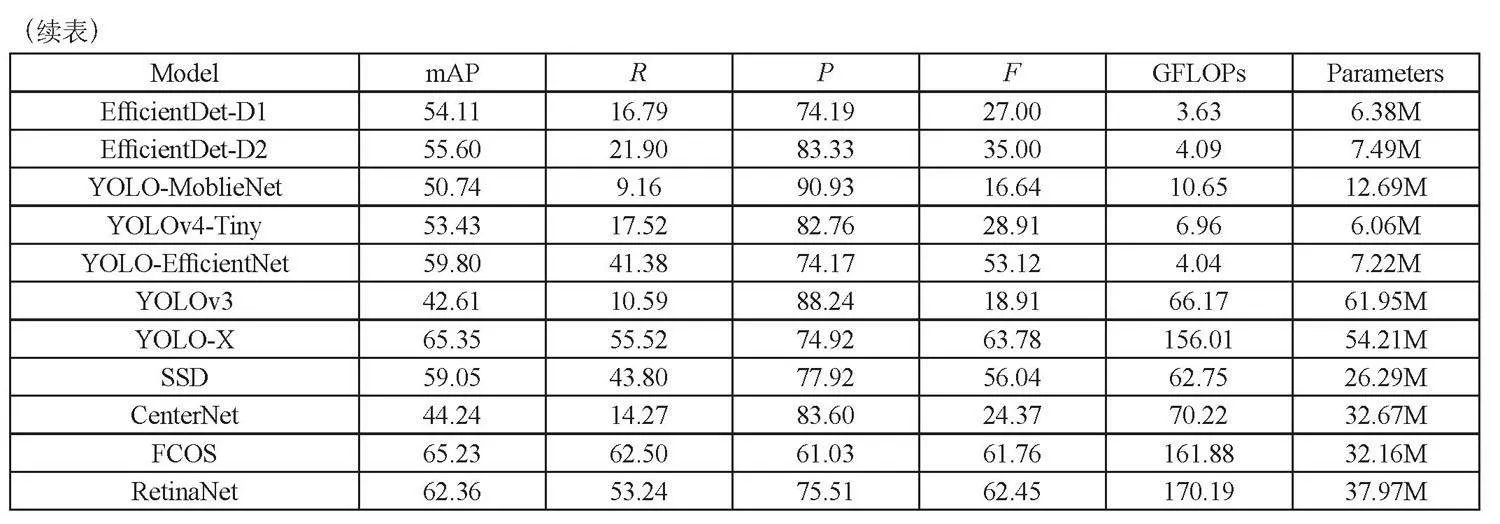
3.3.4 FD-EfficientDet综合对比实验
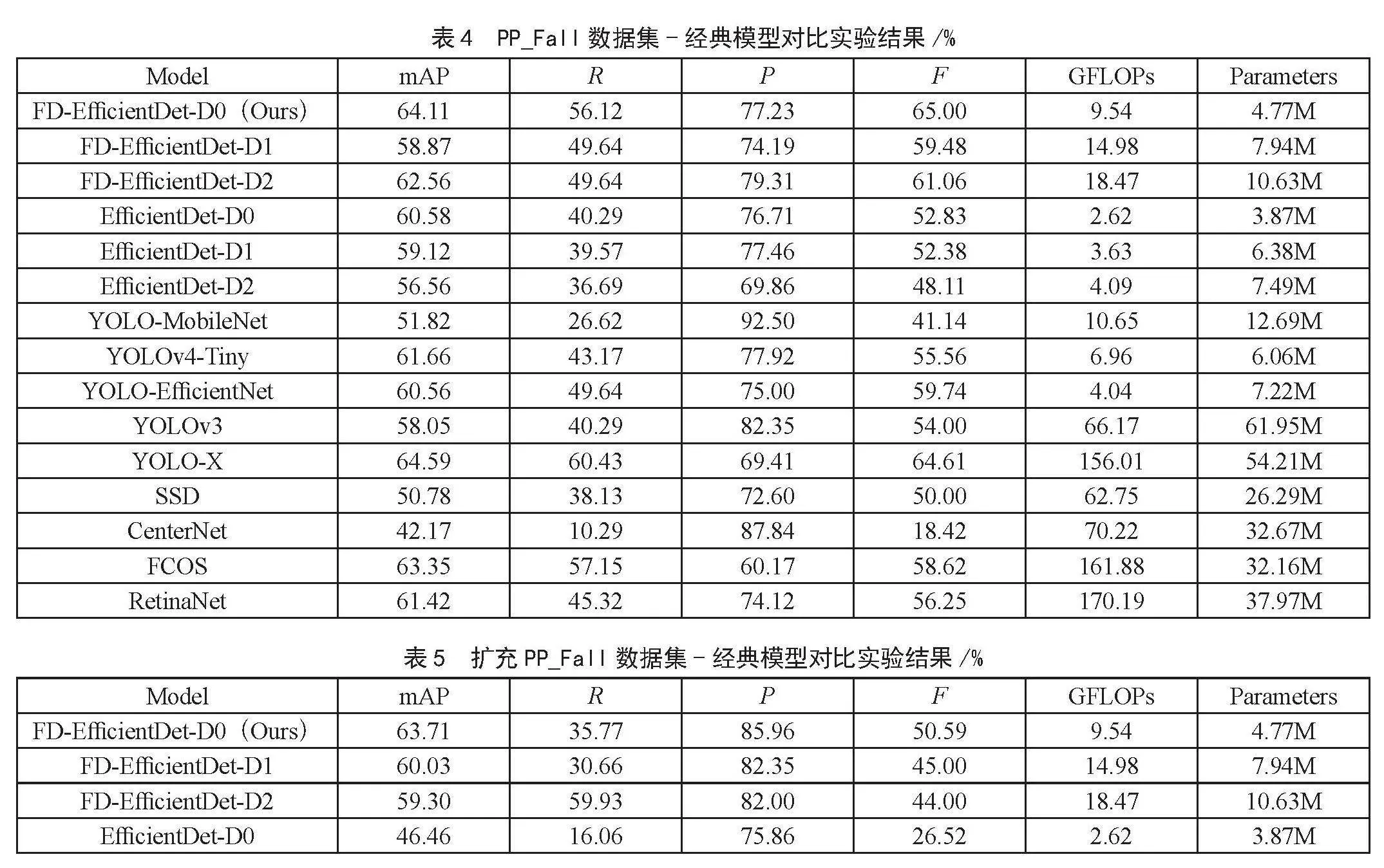
为了充分说明FD-EfficientDet跌倒检测模型的有效性,本文分别准备了PaddlePaddle发布的PP_Fall公开跌倒数据集和对PP_Fall进行适当扩充的数据集,并分别在两个数据集上与其他经典模型进行实验对比,具体实验结果如表4和表5所示。此外,为了评估FD-EfficientDet跌倒检测模型的性能,本文在不同场景下与EfficientDet模型进行了对比实验。实验结果如图5、图6和图7所示,位于实验结果图左侧的为EfficientDet检测结果图,右侧为FD-EfficientDet检测结果图。从图中可以明显看出,FD-EfficientDet的检测准确率(P)、鲁棒性都有明显提升。
3.3.5 消融实验
消融实验旨在验证所提出的每个模块对模型性能均有所提升,模块更新顺序为EMA注意力机制、EMA-Fused-MBConv模块和SKIPS-BiFPN模块,实验结果如表6所示。由表5可见,EMA注意力机制使模型的mAP提高4.59%。EMA-Fused-MBConv模块使模型的mAP提高9.11%,SKIPS-BiFPN模块使模型的mAP提高3.55%。
4 结 论
本文针对目前基于计算机视觉的跌倒检测方法所面临的问题,提出FD-EfficientDet跌倒检测模型。通过对比实验验证,相较EfficientDet模型,FD-EfficientDet在准确率上实现了显著提升,具体增幅达17.65%,训练时间缩短10%,鲁棒性也明显改善。FD-EfficientDet模型在处理目标遮挡问题时展现出优越的性能。但该模型网络层数较多,训练时占用显存过多。因此,我们计划未来聚焦实现网络结构的轻量级优化,进一步提升算法性能,以期在跌倒检测领域取得更为显著的突破。
参考文献:
[1] 王澜,孙博,隆昌宇,等.一种基于共线特征点的线阵相机内参标定方法 [J].红外与激光工程,2015,44(6):1878-1883.
[2] GUO R H, LI H,HAN D L,et al. Feasibility Analysis of Using Channel State Information (CSI) Acquired from Wi-Fi Routers for Construction Worker Fall Detection [J].International Journal of Environmental Research and Public Health,2023,20(6):4998-4998.
[3] PENNONE J,AGUERO F N,MARTINI M D,et al. Fall prediction in a quiet standing balance test via machine learning: Is it possible? [J].PloS one,2024,19(4):e0296355-e0296355.
[4] LI Y,HO K C,POPESCU M. A microphone array system for automatic fall detection [J].IEEE Transactions on Biomedical Engineering,2012,59(5):1291-1301.
[5] VINEETH C,ANUDEEP J,KOWSHIK G,et al. An enhanced, efficient and affordable wearable elderly monitoring system with fall detection and indoor localization [J].International Journal of Medical Engineering and Informatics,2021,13(3):254-268.
[6] DEDABRISHVILI M,MAMAIASHVILI N,MATIASHVILI I. Fall Detection System based on iOS Smartphone Sensors [J].Journal of Technical Science and Technologies,2024,8(1):35-44.
[7] KUMAR V S,ACHARYA K G,SANDEEP B,et al. Wearable Sensor-BASed Human Fall Detection Wireless system [C]//Wireless Communication Networks and Internet of Things:Select Proceedings of ICNETS2,Volume VI.Singapore:Springer,2019:217-234.
[8] MEHMOOD A,NADEEM A,ASHRAF M,et al. A Novel Fall Detection Algorithm for Elderly Using SHIMMER Wearable Sensors [J].Health and Technology,2019,9(4):631-646.
[9] MIN W D,CUI H,RAO H,et al. Detection of Human Falls on Furniture Using Scene Analysis Based on Deep Learning and Activity Characteristics [J].IEEE Access,2018:9324-9335.
[10] ZHAO Z Y,MA J W,MA C,et al. An Improved Faster R-CNN Algorithm for Pedestrian Detection [C]//2021 11th international conference on information technology in medicine and education (ITME).Wuyishan:IEEE,2021:76-80.
[11] XU T,CHEN J,LI Z Y. Fall Detection Based on Person Detection and Multi-Target Tracking [C]//2021 11th International Conference on Information Technology in Medicine and Education (ITME).Wuyishan:IEEE,2021:60-65.
[12] 谢辉,师后勤,齐宇霄,等.基于注意力机制子网络的时空跌倒检测算法 [J].计算机与现代化,2022(3):70-75+81.
[13] CHEN Y,LI W T,WANG LU,et al. Vision-Based Fall Event Detection in Complex Background Using Attention Guided Bi-Directional LSTM [J].IEEE Access,2020:161337-161348.
[14] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards real-time object detection with region proposal networks [J].IEEE transactions on pattern analysis and machine intelligence,2017,39(6):1137-1149.
[15] HE K M,GKIOXARI G,DOLLAR P,et al. Mask R-CNN [EB/OL].[2024-07-08].https://openaccess.thecvf.com/content_iccv_2017/html/He_Mask_R-CNN_ICCV_2017_paper.html.
[16] TAN M X,PANG R M,LE Q V. Efficientdet: Scalable and Efficient Object Detection [C]//2020 IEEE/CVF conference on computer vision and pattern recognition.Seattle:IEEE,2020:10778-10787.
[17] REDMON J,FARHADI A. Yolov3: An Incremental Improvement [J].arXiv:1804.02767 [cs.CV].[2024-07-08].https://arxiv.org/abs/1804.02767.
[18] OUYANG D,HE S,ZHANG G Z,et al. Efficient Multi-Scale Attention Module with Cross-Spatial Learning [C]//ICASSP 2023-2023 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Rhodes Island:IEEE,2023:1-5.
作者简介:牟雪楠(1998—),男,汉族,安徽蚌埠人,硕士,研究方向:目标检测;余洁镱(1997—),女,汉族,广东中山人,硕士,研究方向:分类预测;王胤(1982—),男,汉族,河南周口人,讲师,博士,研究方向:数字医疗;胡文军(1977—),男,汉族,安徽宣城人,教授,博士,研究方向:机器学习。
收稿日期:2024-08-01
