基于YOLOv5的行人检测系统研究
2025-02-21焦天田秀云



摘 要:针对计算量冗余和精度低的问题,提出一种改进的YOLOv5行人检测模型。系统采用Ghost卷积结合Transformer自注意力机制,结合双向金字塔结构以及EIoU损失函数,将INRIA行人检测数据集按照7∶2∶1的比例分配训练集、验证集和测试集,采用SGD优化器对模型进行300个Epochs的训练,并利用训练好的权重模型对测试集进行检测,结果表明:改进模型检测的平均精度值增加了1.5%,且计算量显著降低。
关键词:行人检测;YOLOv5模型;Ghost卷积;双向金字塔结构
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)02-0033-06
Research on Pedestrian Detection System Based on YOLOv5
JIAO Tianwen, TIAN Xiuyun
(School of Electronics and Information Engineering, Guangdong Ocean University, Zhanjiang 524088, China)
Abstract: Aiming at problems of the amount of calculation with redundancy and low accuracy, an improved YOLOv5 pedestrian detection model is proposed. This system uses Ghost convolution to combine with the Transformer Self-Attention Mechanism, then combines with the BiFPN structure and EIoU loss function. The INRIA pedestrian detection data set is divided into the training set, the validation set, and the test set according to the ratio of 7∶2∶1. The SGD optimizer is used to train the model for 300 Epochs, and the trained weight model is used to test the test set. The results show that the average accuracy of the improved model detection is increased by 1.5%, and the amount of calculation is significantly reduced.
Keywords: pedestrian detection; YOLOv5 model; Ghost convolution; BiFPN
DOI:10.19850/j.cnki.2096-4706.2025.02.006
收稿日期:2024-06-11
基金项目:2022年广东海洋大学校级课程-数学物理方法(010301112202)
0 引 言
近些年来,在计算机视觉研究领域中人体运动分析处于研究的热点,其研究应用范围可涵盖人机互动、视频监控、智慧交通等热点问题。该领域内技术研究给这些热点问题提供了极大的帮助。例如通过人脸识别和人体行为预测等方式,可判断目标的运动过程以及是否对安全造成威胁,其可以运用至银行、机场等环境复杂,对安全性需求较高且较为敏感的场合,对于监测目标的不良举措可以提前预知识别并通报。行人检测[1]属于计算机视觉领域内人体运动分析的分支的一部分,又或者说,可以称为人体运动分析系统的预处理的部分。早期研究并未受到大量关注,然而随着行人检测过程中出现的背景模糊化,人体姿态多样化以及重叠、小目标检测等问题的浮现,使得该研究领域的难度逐渐升高且对于行人检测目标的需求逐渐升级,这使得行人检测这一话题在研究中越来越受到广泛关注。此外,对于当代智慧城市、辅助驾驶等热门研究应用场景的出现,使得行人检测的实用性增强,可以极大地简化生活中所遇到的问题。
目前,行人检测算法可分为传统行人检测算法以及基于深度学习的行人检测算法,前者主要有HOG+SVM算法[2]、AdaBoost算法等,如AdaBoost算法[3]是由Viola等人利用Haar特征和级联分类器结合实现的行人检测系统,可应用于智能监控中进行实时监测。后者是近些年随着深度学习不断发展后与其结合的产物,并在市场上占据主流。基于深度学习的行人检测算法如R-CNN、Fast-CNN、SSD、YOLO算法等都是现阶段较为流行的行人检测算法。其中,YOLO算法为该类型算法中的一种单阶段算法,其主要思想是对边界框进行分类与回归,采用卷积神经网络实现端到端的目标检测功能,并确定被测目标分类概率和位置信息的算法。
1 YOLOv5结构
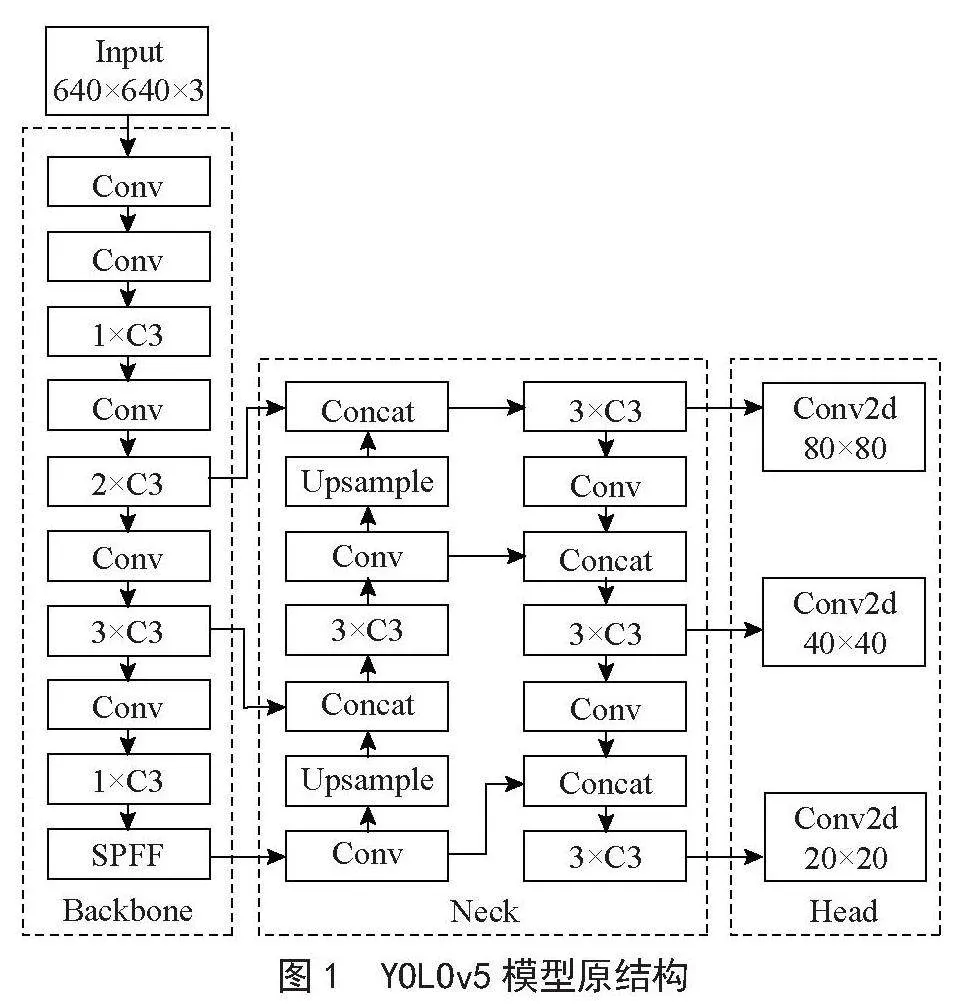
YOLOv5行人检测算法[4]是YOLO系列算法的第五代版本,对比上一代其融合一些改进思路,并考虑到网络结构的宽度与深度的不同需求,提供了5种不同尺度的模型,即n、s、l、m、x这5个模型,兼顾模型检测精度和检测速率需求,本文选取YOLOv5s模型作为行人检测算法,如图1所示。
由图1可知,YOLOv5网络结构可分为输入端(Input)、主干网络(Backbone)、颈部网络(Neck)和输出端(Head)4个部分。输入端主要完成图像预处理的工作,其中完成的主要工作有Mosaic数据增强、自适应锚框计算和自适应图片缩放。主干网络主要由Conv、C3和SPPF这3个模块组成,其中,Conv模块主要由常规卷积模块、正则化模块和激活函数组成,激活函数采用Sigmond加权线性组合函数,即SiLU激活函数。C3模块借鉴了ResNet的残差结构,通过分支卷积后选择性堆叠在进行叠加实现特征融合的方式,实现有限度的容量下提高检测效率。SPPF即为原模块SPP[5](Spatial Pyramid Pooling)的改进版本,借鉴空间金字塔的思想,实现局部特征与全局特征融合,此外采用多个池化核级联方法提升特征图表达能力和运行速度。颈部网络所完成的工作为特征融合,采用FPN(Feature Pyramid Networks)+PAN(Path Aggregation Networks)的结构,前者完成将深层特征图的语义信息传递至浅层特征图,后者将浅层特征图的位置信息传递给深层特征图,即完成自上而下和自下而上的特征交互交融的操作。实现多尺度融合以及特征表达的丰富程度提高的目的。输出端由3个不同尺度的检测层组成,对融合特征进行分类与预测,并采用CIoU损失函数和非极大值抑制操作获取最优目标检测框,即完成目标检测的末尾工作。
2 改进YOLOv5算法
为了提高检测精度以及达到模型轻量化目的,在原模型基础上做了部分改进。主干网络结构采用Ghost卷积层替代原有卷积层,并对模型中ResNet的网络结构结合Transformer结构,即实现模型轻量化高效和提高特征捕捉效果的功能。颈部网络结构结合双向加权金字塔结构,通过改变堆叠方式提高特征融合效率。对于检测端将原CIoU损失函数替换成EIoU以避免目标框回归时存在的不精确的问题。
2.1 主干网络改进
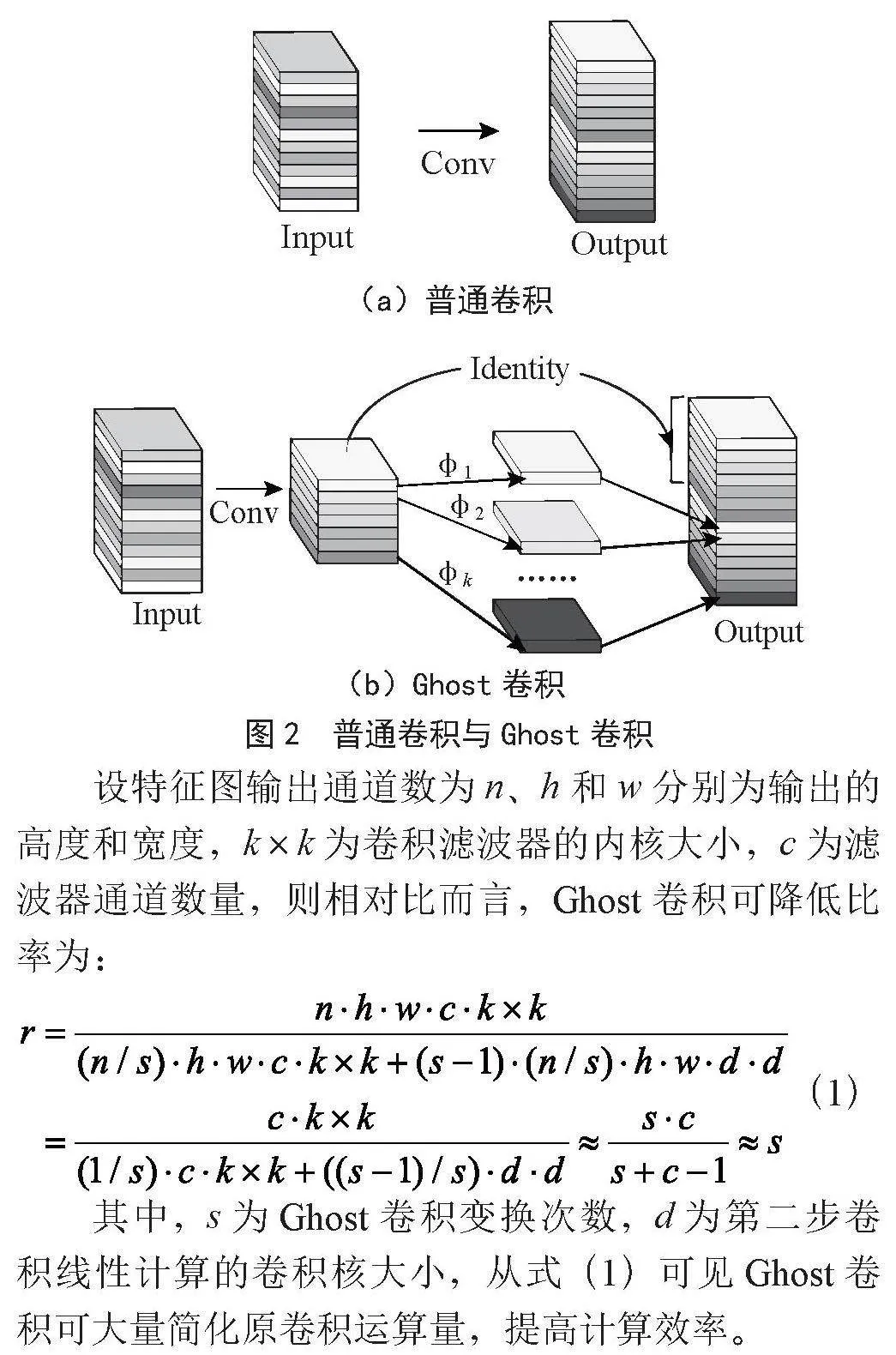
深度卷积神经网络结构一般都是由大量的卷积组成,其所造成的问题则是计算成本的增加,一般的卷积过程中由于滤波器和通道数量较为庞大,导致运算量极大,这是使得模型冗余的一大要素。相比之下,Ghost卷积模块减少了不必要的计算冗余。
如图2所示,Ghost卷积[6]采用分步卷积,并采用减少通道数并降低和深度分离卷积的方式降低运算量。
设特征图输出通道数为n、h和w分别为输出的高度和宽度,k×k为卷积滤波器的内核大小,c为滤波器通道数量,则相对比而言,Ghost卷积可降低比率为:
(1)
其中,s为Ghost卷积变换次数,d为第二步卷积线性计算的卷积核大小,从式(1)可见Ghost卷积可大量简化原卷积运算量,提高计算效率。
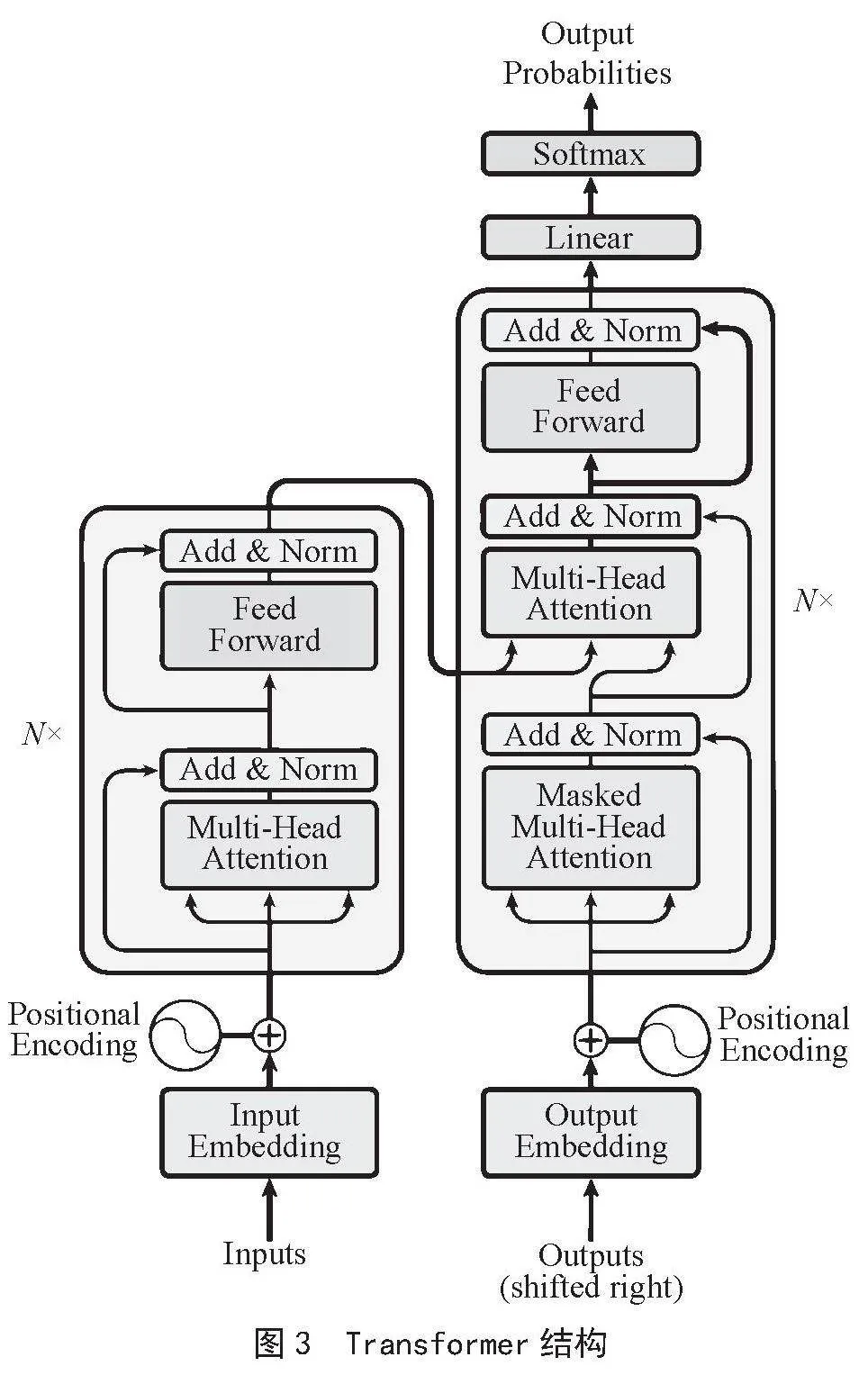
Transformer模型[7]最早运用于自然语言处理,直至2020年,ViT模型首次将其引入计算机视觉领域才使得该模型同卷积结构结合,由于其模型的高解释性和长距离学习等优点使其在计算机视觉领域占据一席之地,并具有大量的可研究空间。本文对于主干网络C3模块采用Transformer结构与其结合。
如图3所示,Transformer结构对于原结构下做部分改进,对于C3模块所采用的将模块中间卷积层替换成多注意力机制体,而其他部分保持不变,可使模型完成多组输入数据的汇入,结合自注意力机制体提高原模型深入挖掘特征的能力,即实现远特征获取,使原模型特征丰富。
2.2 颈部网络改进
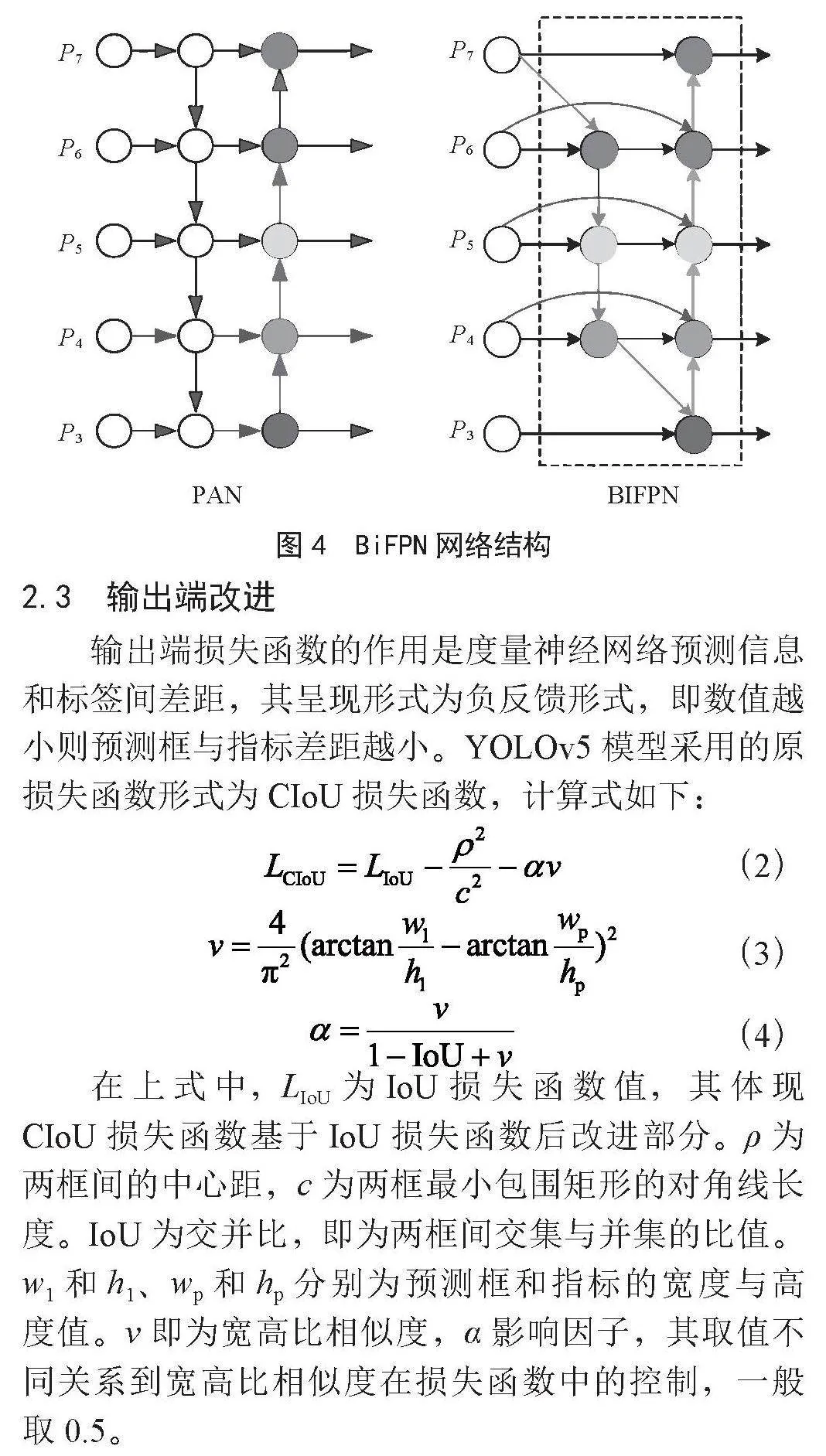
颈部网络主要结构为FPN+PAN结构,采用上下间交互传递特征并促进其融合的方式完成特征融合的工作。然而,对于这种结构体仍存在一些问题需要解决,首先,FPN信息流传递时通常是单向传输,因为其由下至上的方式导致粗糙特征图内必然存在细节信息的丢失。此外,PAN结构较为简单且缺少原始学习信息,这样会使得训练学习发生偏差。
如图4所示,BiFPN结构[8-9]在原FPN+PAN结构下做了些许改动,去掉了只有一个输入和输出汇入的结点,并增加额外一条路径直接与PAN部分,这样使得PAN可直接获得原始学习特征,进而降低特征融合偏差。而对于粗特征的丢失这一部分,BiFPN网络采用双向连接解决这个问题,采用双向连接,允许不同尺度间特征传递,这样使得特征尽可能利用最大化。
2.3 输出端改进
输出端损失函数的作用是度量神经网络预测信息和标签间差距,其呈现形式为负反馈形式,即数值越小则预测框与指标差距越小。YOLOv5模型采用的原损失函数形式为CIoU损失函数,计算式如下:
(2)
(3)
(4)
在上式中,LIoU为IoU损失函数值,其体现CIoU损失函数基于IoU损失函数后改进部分。ρ为两框间的中心距,c为两框最小包围矩形的对角线长度。IoU为交并比,即为两框间交集与并集的比值。w1和h1、wp和hp分别为预测框和指标的宽度与高度值。v即为宽高比相似度,α影响因子,其取值不同关系到宽高比相似度在损失函数中的控制,一般取0.5。
增加了宽高比这一参考量的涉入使其回归速度加快,然而宽高比反映纵横比差异,并不能宽高位置和置信度间的真实关系,进而导致收敛缓慢和回归不精确的问题。对于上述情况,需要重新考虑损失函数的合适选择,且能正确反应损失函数与宽高比间问题。因此,后期选择EIoU损失函数替代原损失函数。EIoU损失函数[10]在原损失函数基础上将纵横比拆开分别计算,其考虑了宽度和高度间真实的差异。该损失函数将损失值分解为交并比损失、宽高损失和距离损失。计算式公式如下:
(5)
式中,LIoU、Ldis、Lasp分别为不同损失函数考虑范畴的变量,即交并比损失、宽高损失和距离损失。ρ2(b,bgt)为预测框与标签框内中心点间欧几里得距离。ρ2(w,w gt)和ρ2(h,hgt)则为预测框和指标的宽高比例值,Cw和Ch分别为预测框和标签间最小外接矩形的宽和高。即EIoU损失函数直接对宽和高分开求出损失值,避免宽高之间相互制衡的问题发生,也可保证预测框的回归精确并加快收敛速度的目的。
3 实验结果与分析
3.1 实验环境
实验环境操作系统为Windows 11,64位系统,显卡为GPU NVIDIA GeForce RTX 3050 Ti,CPU为AMD Ryzen 5 5600H with Radeon Graphics CPU@3.30 GHz处理器,编程环境为Python 3.12,深度学习框架为PyCharm,在PyTorch 2.2.0、CUDA 12.2、CUDNN 8.9.4上训练。
3.2 实验数据集
使用的数据集为INRIA行人检测数据集,涉及场景较为广泛,图像间行人数量不等,数据集内含902张含行人目标的图像。按照7∶2∶1的比例分配训练集、验证集和测试集,即训练集照片632张,验证集照片180张,测试集照片90张。为弥补训练原始数据量的不足,在图像预处理部分采用Mosaic数据增强方式,即4张照片剪裁后拼接组成。这样丰富训练数据集多样性,也提高模型的泛化能力。
实验图像尺寸为640×640,迭代次数为300次,训练批次设置个数为8。初始学习率设置为0.01,学习率动量设置为0.937,采用SGD优化器对模型进行训练。
3.3 实验评价指标
使用参数量(Parameters)、召回率(Recall)、平均精度值(mean Average Precision)和浮点计算量(giga floating-point operations)来衡量模型性能指标,其计算公式如下:
(6)
(7)
(8)
其中,TP(True Positive)为算法和标注中均标记出的物体,FP(False Positive)为算法未能识别出但标注中已标记的物体,FN(False Negative)为算法和标注中均没有标记的物体,P为精度,R为召回率,AP为平均精度。
3.4 实验结果分析
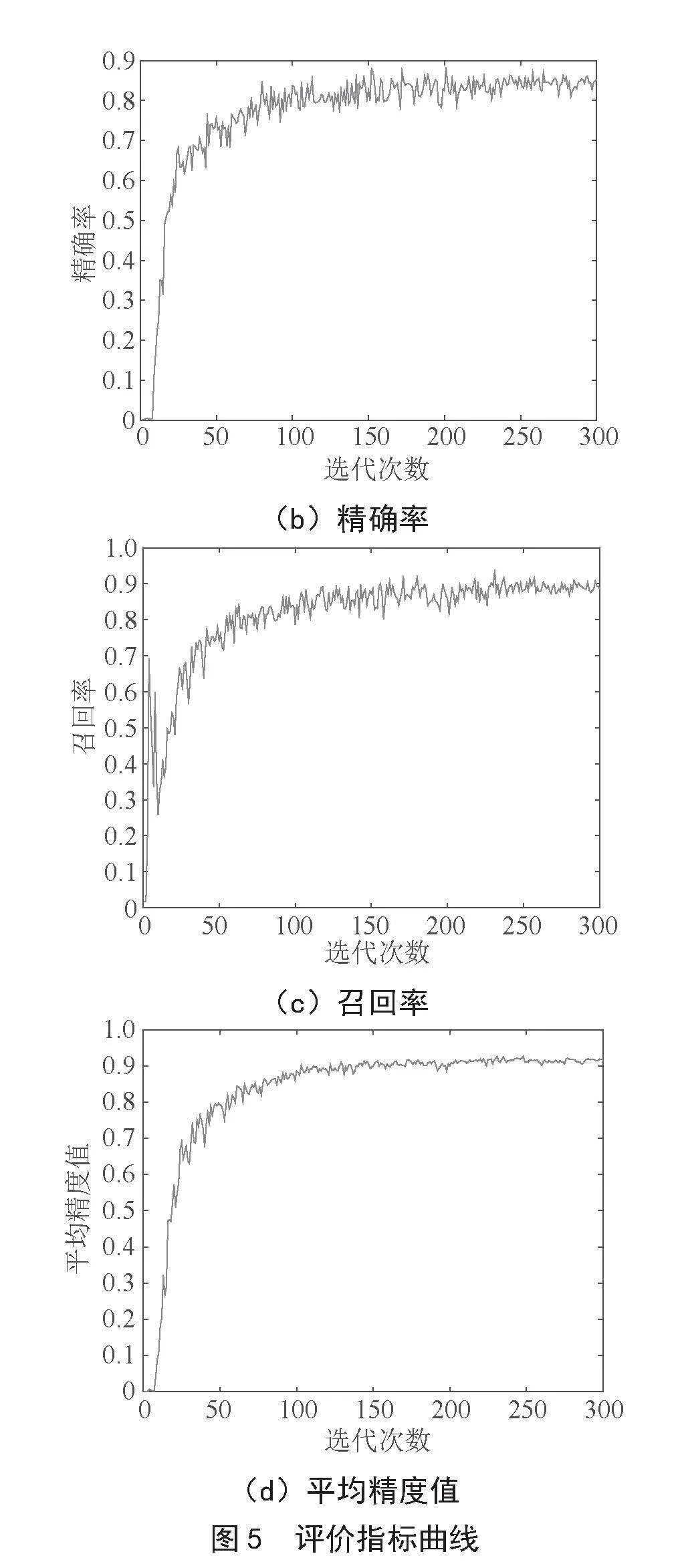
为分析YOLOv5原模型的改进点对模型性能的影响差异,本次使用控制变量法,保证数据集和实验环境不变,实验结果如表1所示。
从表1可以看出,相对于原模型,改进模型召回率保持不变,且平均精度值增加了1.5%。且浮点计算量大幅度减少,虽然模型性能仍然存在些不足,但大体上看出一定量的优越性,这符合改进模型的预期目标。
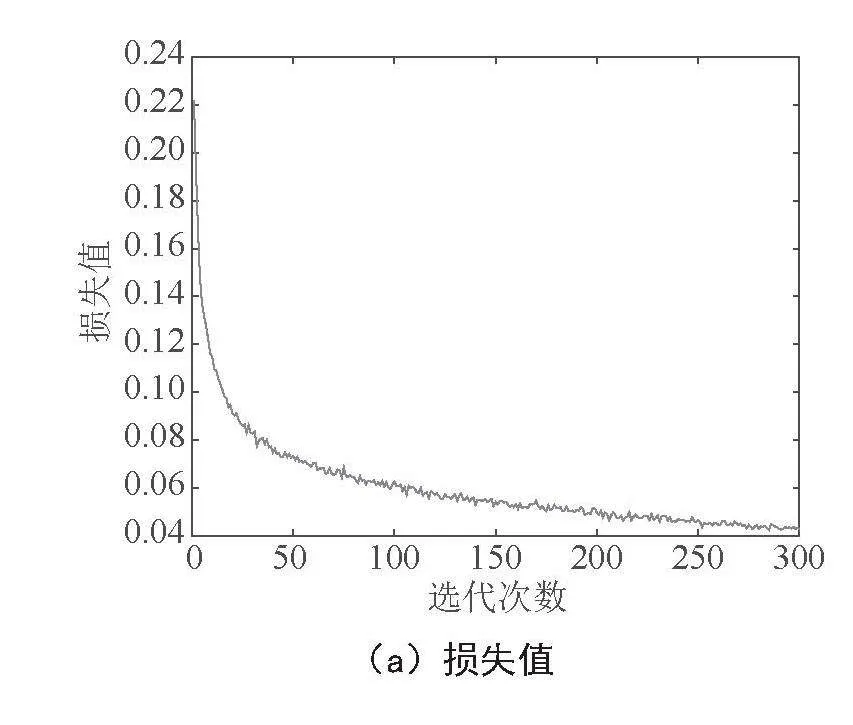
图5为实验过程中评价指标随训练迭代次数变化的趋势,可以看出改良算法具有较高的优越性。
3.5 结果展示
检测结果如图6所示。
4 结 论
本文介绍了基于YOLOv5的行人检测方法,较于原模型达到提高精度和轻量化模型的目的,做出了相对应的改进措施,主干网络采用Ghost卷积和Transformer结构融合,颈部网络采用BiFPN结构替代原FPN+PAN结构,输出端损失函数选择用EIoU损失函数替代CIoU损失函数。并采用INRIA行人检测数据集进行实验。结果表明,改进后模型较于原模型精确度提升1.5%,且模型呈现明显轻量化结果。后续工作将会尝试增加模型鲁棒性和抗干扰能力,能够将其适应多种环境检测,此外,尝试解决小目标检测问题使模型检测范围扩大。
参考文献:
[1] 苏松志,李绍滋,陈淑媛,等.行人检测技术综述 [J].电子学报,2012,40(4):814-820.
[2] DALAL N,TRIGGS B. Histograms of Oriented Gradients for Human Detection [C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05).San Diego:IEEE,2005,1:886-893.
[3] VIOLA P,JONES M. Rapid Object Detection Using a Boosted Cascade of Simple Features [C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001).Kauai:IEEE,2001:I-I.
[4] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779-788.
[5] HE K M,ZHANG X Y,REN S Q,et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[6] HAN K,WANG Y H,TIAN Q,et al. GhostNet: More Features From Cheap Operations [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020,1577-1586.
[7] 彭斌,白静,李文静,等.面向图像分类的视觉Transformer研究进展 [J].计算机科学与探索,2024,18(2):320-344.
[8] TAN M X,PANG R,LE Q V. EfficientDet: Scalable and Efficient Object Detection [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:10778-10787.
[9] YU C S,SHIN Y.SAR Ship Detection Based On Improved YOLOv5 and BiFPN [J].ICT Express,2024,10(1):28-33.
[10] ZHANG Y F,REN W Q,ZHANG Z,et al. Focal and Efficient IOU Loss for Accurate Bounding Box Regression [J].Neurocomputing,2022,506:146-157.
作者简介:焦天文(2001—),男,汉族,广东珠海人,本科,研究方向:嵌入式、AI算法;通信作者:田秀云(1974—),女,汉族,广东湛江人,讲师,硕士,研究方向:软件算法、光电检测。
