火焰和烟雾检测中YOLOv8的应用和改进
2025-02-21韩伟娟平翼杨奥林远京辉崔二强董新捷


摘 要:火灾事件严重威胁着人民生命财产安全,因此火灾检测是极其必要的。基于YOLOv8算法进行烟雾和火焰检测,并对模型结构进行改进以提高准确度。改进包括3个方面,一是引入DBB模块,二是使用动态卷积,三是优化损失函数。实验表明,三种改进算法均在一定程度上提高了检测准确度,而同时使用三种改进的YOLOv8n模型,相比原来的YOLOv8n,mAP50提升了3.03%,mAP50-95提升了3.37%,相比于Faster R-CNN等其他模型,mAP50、mAP50-95等各项性能指标也获得了大幅提升,火灾检测准确度也有所提高。
关键词:YOLOv8;网络结构;卷积;损失函数;mAP;准确度
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)02-0001-06
Application and Improvement of YOLOv8 in Flame and Smoke Detection
HAN Weijuan1, PING Yi2, YANG Aolin3, YUAN Jinghui2, CUI Erqiang2, DONG Xinjie2
(1.School of Electro-mechanical Engineering, Zhongyuan Institute of Science and Technology, Zhengzhou 450000, China; 2.Department of Information and Communication, Department of Public Security of Henan Province, Zhengzhou 450003, China; 3.School of Public Administration, Henan University of Economics and Law, Zhengzhou 450046, China)
Abstract: The fire incidents seriously threaten the safety of people's lives and property, so the fire detection is extremely essential. Based on the YOLOv8 algorithm, this paper carries out the smoke and flame detection, and improves the model structure to raise accuracy. The improvements include 3 aspects of introducing the DBB module, using the Dynamic Convolution, and optimizing the loss function. The experiments demonstrate that the three kinds of improved algorithms all have a specific rise in detection accuracy, and the YOLOv8n model which uses three improvements at the same time has increased mAP50 by 3.03% and mAP50-95 by 3.37% compared to the original YOLOv8n. Compared to Faster R-CNN and other models, various performance indicators such as mAP50 and mAP50-95 have notable enhancements, and the precision of fire detection is also improved.
Keywords: YOLOv8; network structure; convolution; loss function; mAP; accuracy
DOI:10.19850/j.cnki.2096-4706.2025.02.001
0 引 言
火灾是严重影响人民生命安全的危险因素,因此对有关区域进行火焰和烟雾检测是十分必要的,近年随着视频摄像头的广泛使用,基于视频和图像的火灾检测技术得到不断发展。目标检测主要分为两阶段算法如Faster R-CNN[1]系列和一阶段算法如SSD[2]、YOLO[3]系列。两阶段算法需要先用特征提取器生成一系列可能包含待检物体的预选框,之后对预选框进行筛选,最后在预选框上面进行的物体类别分类,检测和分类速度较慢。一阶段算法会直接在网络中提取特征来预测物体分类以及位置,提高了检测速度,是目前的主流方向。YOLO[4]自2016年提出以来,研究者们已经对YOLO进行了多次更新迭代,截至目前已存在YOLOv1到YOLOv10共10个版本。本文将基于YOLOv8对火焰和烟雾进行检测,并探索进一步提高检测准确率。
1 相关工作
火焰和烟雾检测也是目标检测的研究热点之一,谢康康[5]等人基于YOLOv7提出了改进的火焰和烟雾目标检测算法,在骨干网中引入GhostNetV2长距离注意力机制,降低参数量的同时,增加模型检测的准确度,在包括公开数据集的自建数据集上测试,相比原YOLOv7,参数量下降了约3.4 MB,mAP50上升了2.4%,达到70.3%。王一旭[6]等人提出一种基于YOLOv5s的小目标烟雾火焰检测算法,添加注意力机制SimAM,修改网络中的Neck结构,结合了加权双向特征金字塔网络结构,增强了特征融合过程,提高小目标的检测能力,在自建数据集上mAP50达到了78.9%。宋华伟[7]等人基于YOLOv5s提出一种改进的火焰烟雾检测算法,将YOLOv5s颈部原有模块替换为双向交叉多尺度融合模块,在头部添加协调注意力的推理层,使用K-means聚类算法获取数据集先验锚框,在自建数据集上与原YOLOv5s相比,mAP50提升了3.2%,达到了84.1%。以上算法通过网络结构改进等方法,提升了模型识别准确度,但准确度值仍有改进空间,本文将基于YOLOv8进行火焰和烟雾检测并改进算法,进一步提高检测准确度。
2 YOLOv8结构
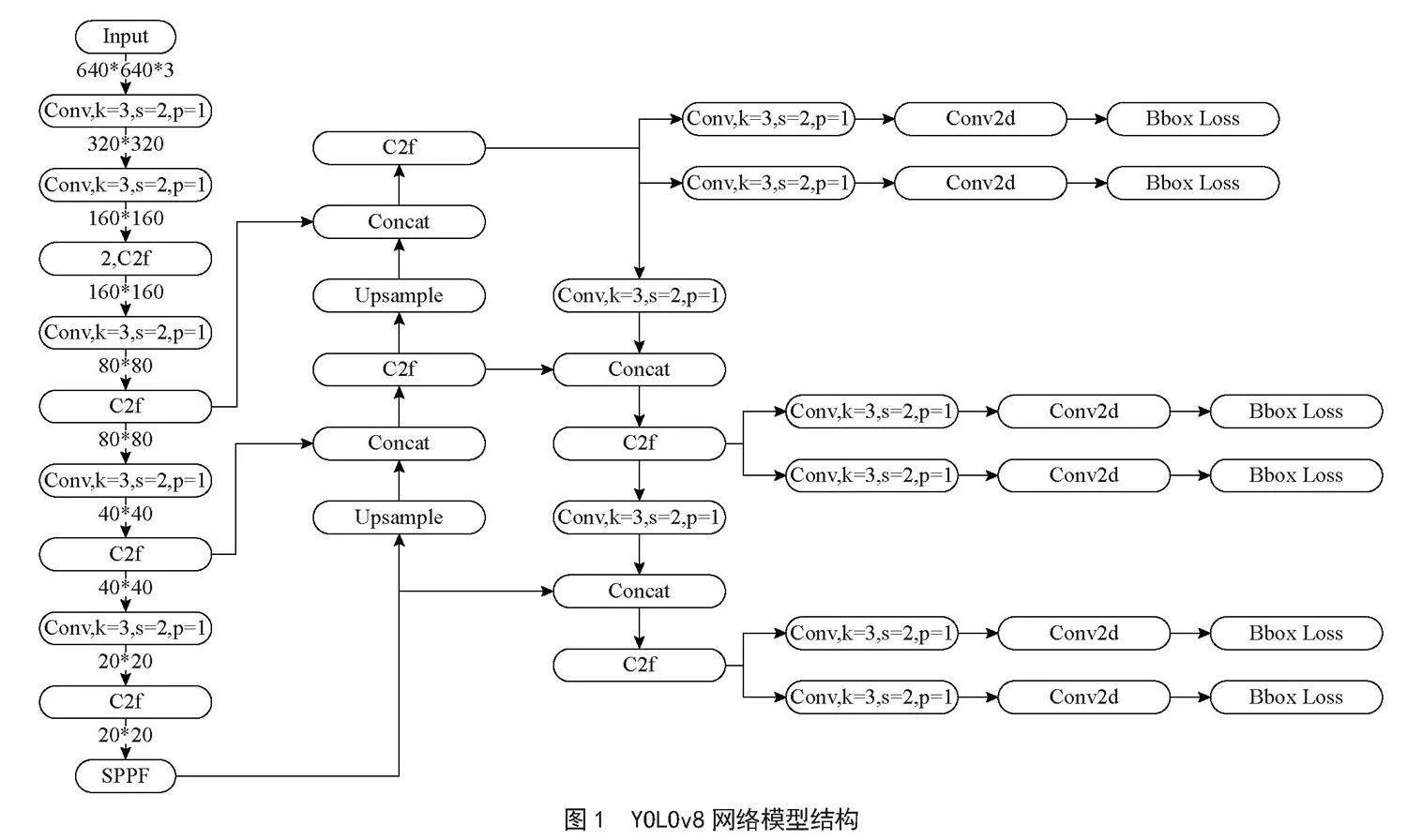
YOLOv8n网络结构[8-9]如图1所示,共包括Conv、C2f、SPPF等共21个模块225层,参数量3.01 MB,计算量8.2GFLOPs,总体上可分为特征提取骨干网络(backbone)和头部检测(head)部分,骨干网中的Conv、C2f、SPPF均为特征提取模块。Conv为普通卷积,使用Silu激活函数,YOLOv8将YOLOv5中的C3模块被替换成了C2f模块,使用了更多的特征融合和残差连接,SPPF采用空间池化结构,在不同尺度上进行特征提取,并将这些特征通过Concat操作进行融合。整体结构采用PAN-FPN特征金字塔结构,FPN是自顶向下卷积,将高层的语义特征传递下来,PAN是一个自底向上的卷积金字塔,通过路径聚合,将浅层特征和深层特征进行聚合。总体结构先进行下采样,然后进行上采样,上采样和下采样之间跨层融合连接,得到3个检测头分支。
检测头分支使用了主流的解耦结构,将分类和检测分离,锚框不需要预设,从原有的Anchor-Based转换为Anchor-Free,正负样本分配上YOLOv8使用动态分配策略TaskAlignedAssigner,根据分类与回归的分数加权选择正样本,分类损失使用VFL,定位损失使用了DFL和CIoU。使用YOLOv8对火灾进行目标检测取得了良好效果,本文将在3个方面探索进一步改进YOLOv8模型。
3 改进点
3.1 融合DBB模块
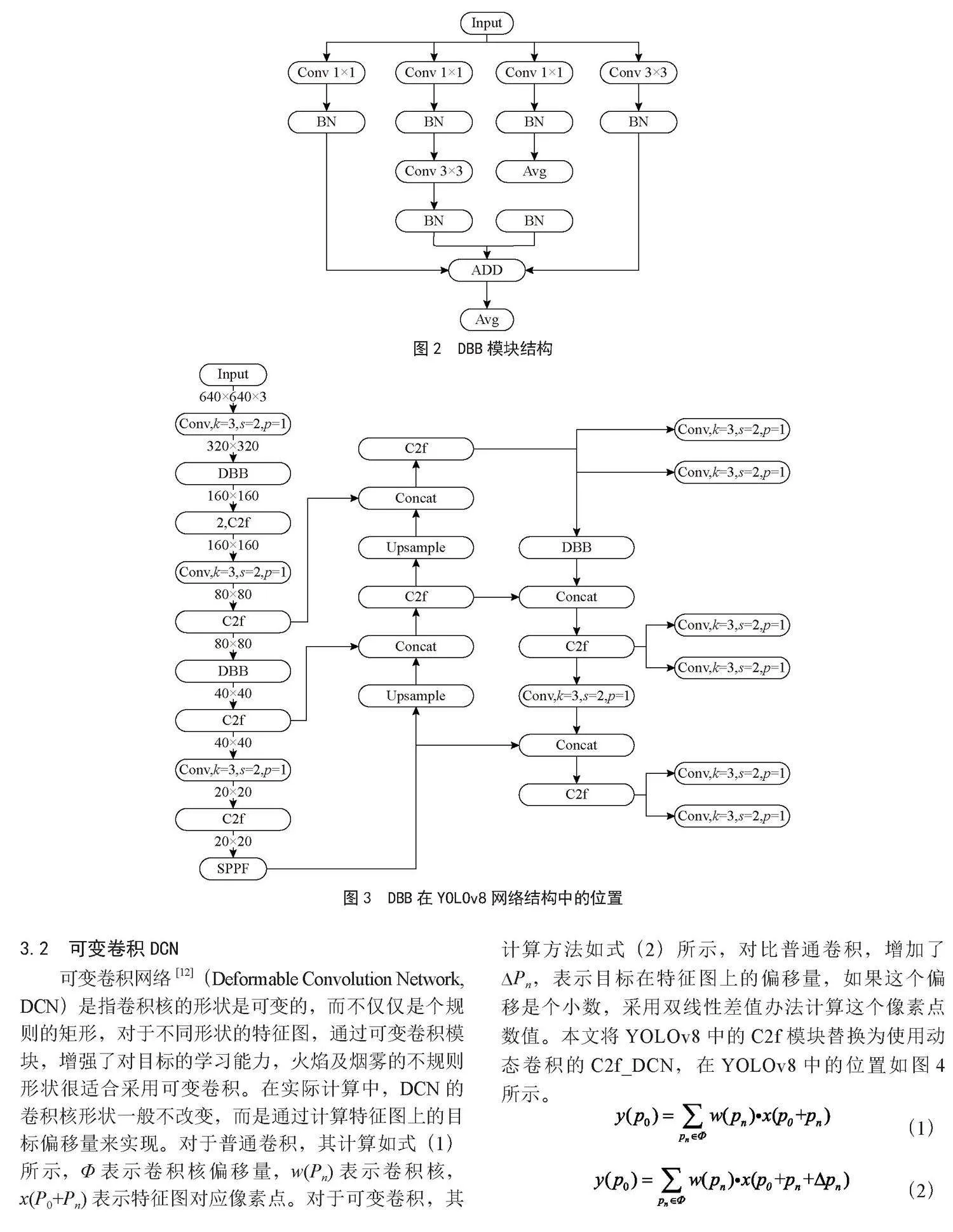
DBB[10]是Diverse Branch Block的简称,是一种类似Inception[11]的结构,如图2所示,使用并行的卷积核卷积后进行拼接,不同大小的卷积核增强了网络对不同尺寸特征图的适应性,本文将采用DBB以提高火焰和烟雾检测正确率。DBB对于输入的特征图,用4个分支分别处理,第1个分支为1×1卷积和BN层,第2个分支依次为1×1卷积、BN层、3×3卷积、BN层,第3个分支依次为1×1卷积、BN层、AVG平均池化层、BN层,第4个分支为3×3卷积、BN层,所有分支结果经过累加后作为模型输出。本文对模型进行改进,包括在累加操作后增加一个平均池化层,取消了Pad层。DBB在YOLOv8模型结构中位置如图3所示。
3.2 可变卷积DCN
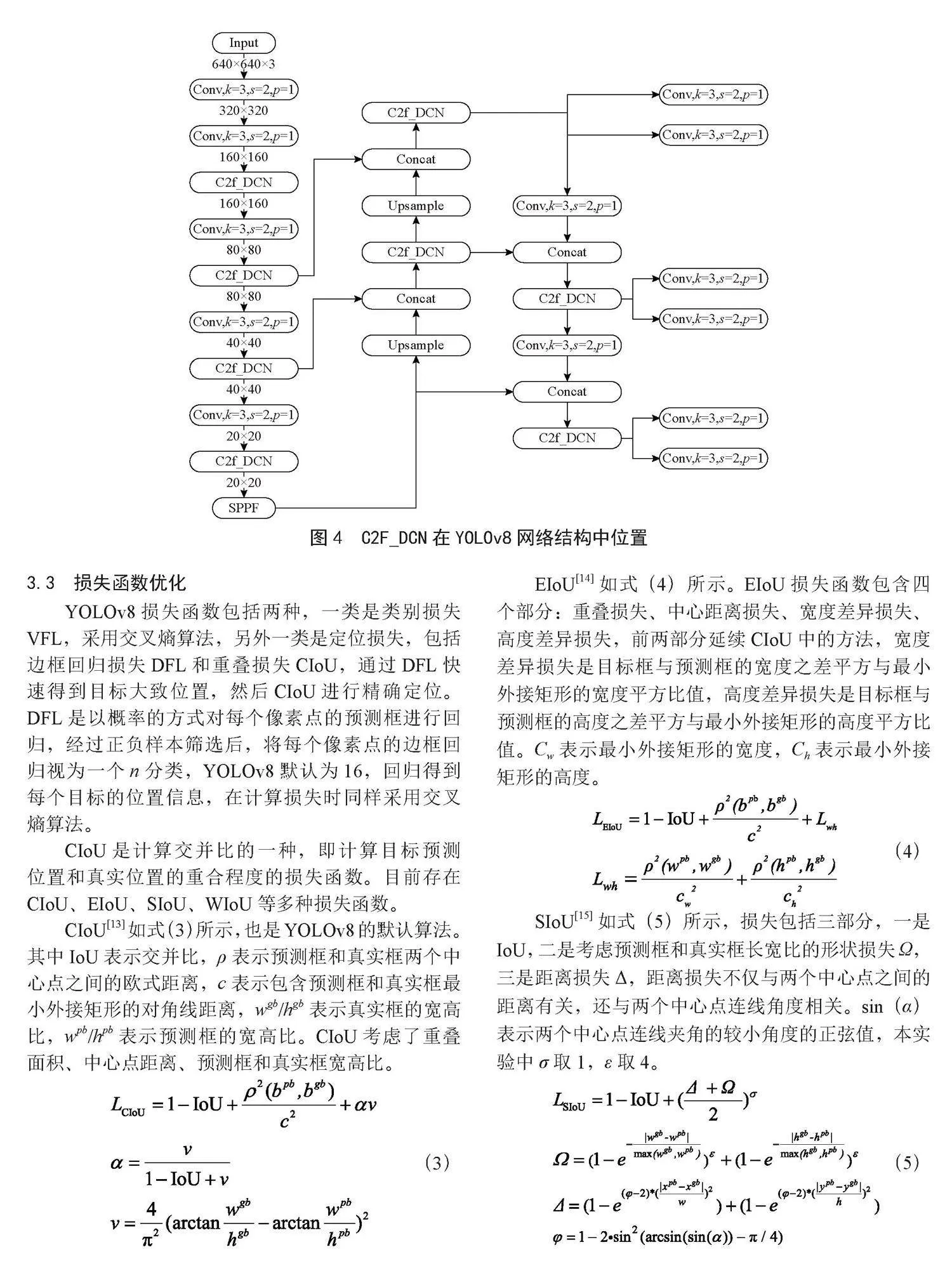
可变卷积网络[12](Deformable Convolution Network, DCN)是指卷积核的形状是可变的,而不仅仅是个规则的矩形,对于不同形状的特征图,通过可变卷积模块,增强了对目标的学习能力,火焰及烟雾的不规则形状很适合采用可变卷积。在实际计算中,DCN的卷积核形状一般不改变,而是通过计算特征图上的目标偏移量来实现。对于普通卷积,其计算如式(1)所示,Φ表示卷积核偏移量,w(Pn)表示卷积核,x(P0+Pn)表示特征图对应像素点。对于可变卷积,其计算方法如式(2)所示,对比普通卷积,增加了∆Pn,表示目标在特征图上的偏移量,如果这个偏移是个小数,采用双线性差值办法计算这个像素点数值。本文将YOLOv8中的C2f模块替换为使用动态卷积的C2f_DCN,在YOLOv8中的位置如图4所示。
(1)
(2)
3.3 损失函数优化
YOLOv8损失函数包括两种,一类是类别损失VFL,采用交叉熵算法,另外一类是定位损失,包括边框回归损失DFL和重叠损失CIoU,通过DFL快速得到目标大致位置,然后CIoU进行精确定位。DFL是以概率的方式对每个像素点的预测框进行回归,经过正负样本筛选后,将每个像素点的边框回归视为一个n分类,YOLOv8默认为16,回归得到每个目标的位置信息,在计算损失时同样采用交叉熵算法。
CIoU是计算交并比的一种,即计算目标预测位置和真实位置的重合程度的损失函数。目前存在CIoU、EIoU、SIoU、WIoU等多种损失函数。
CIoU[13]如式(3)所示,也是YOLOv8的默认算法。其中IoU表示交并比,ρ表示预测框和真实框两个中心点之间的欧式距离,c表示包含预测框和真实框最小外接矩形的对角线距离,wgb/hgb表示真实框的宽高比,wpb/hpb表示预测框的宽高比。CIoU考虑了重叠面积、中心点距离、预测框和真实框宽高比。
(3)
EIoU[14]如式(4)所示。EIoU损失函数包含四个部分:重叠损失、中心距离损失、宽度差异损失、高度差异损失,前两部分延续CIoU中的方法,宽度差异损失是目标框与预测框的宽度之差平方与最小外接矩形的宽度平方比值,高度差异损失是目标框与预测框的高度之差平方与最小外接矩形的高度平方比值。Cw表示最小外接矩形的宽度,Ch表示最小外接矩形的高度。
(4)
SIoU[15]如式(5)所示,损失包括三部分,一是IoU,二是考虑预测框和真实框长宽比的形状损失Ω,三是距离损失Δ,距离损失不仅与两个中心点之间的距离有关,还与两个中心点连线角度相关。sin(α)表示两个中心点连线夹角的较小角度的正弦值,本实验中σ取1,ε取4。
(5)
MPDIoU[16]主要计算预测框和真实框左上点之间和右下点之间的距离作为损失。如式(6)所示,(x1pb,y1pb)和(x2pb,y2pb)分别表示预测框左上点和右下点坐标,(x1gb,y1gb)和(x2gb,y2gb)分别表示真实框左上点和右下点坐标。w和h分别表示输入图像的宽度和高度。
(6)
WIoU[17]如式(7)所示。核心思想是降低质量差的锚框系数以减少有害梯度,提高质量高的锚框系数以加快收敛。通过一个和IoU相关的系数调整因子γ,低质量锚框的损失系数被相对放大,高质量锚框的损失系数被相对缩小,快速放弃低质量备选锚框,选择高质量备选锚框,从而快速收敛并提高模型的定位性能。本文实验中α取1.9,δ取3,η取0.002 6。
(7)
4 实验环境
目前公认的大批量火焰烟雾数据集较少,本文搜集互联网数据,共标注训练及测试集6 000张(8比2划分训练集和测试集),随机选择9张图片如图5所示,并进行了预处理。本文YOLOv8选择SGD优化器,初始学习率设为0.01,动量设为 0.937,batch为16。GPU为GeForce RTX 4060Ti,操作系统为Windows 11,PyTorch版本为 1.10.1,Cuda版本11.3,Python版本3.7,所有实验均训练200个批次。
5 实验结果
实验指标包括模型参数量parameters,数值越大代表模型越大,浮点运算数GFLOPs,数值越大代表计算复杂度越高,平均准确度mAP50,表示IoU值为0.5时的平均准确度,mAP50-95表示IoU值为0.5到0.95间隔为0.05的平均准确度,本实验为火焰和烟雾两类。
5.1 优化损失函数结果
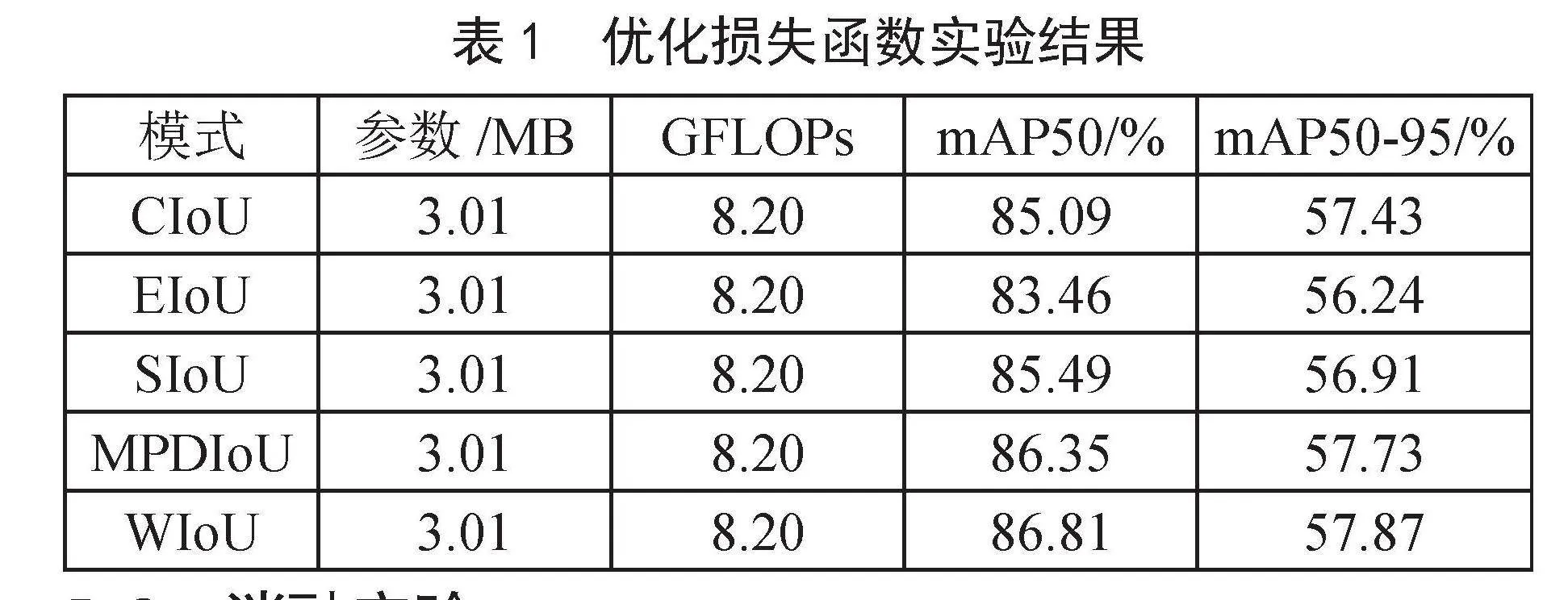
优化损失函数实验如表1所示,结果显示YOLOv8n使用WIoU时获得最佳效果,对比使用默认算法CIoU的YOLOv8n,mAP50提升1.72%,mAP50-95提升了0.44%。
5.2 消融实验
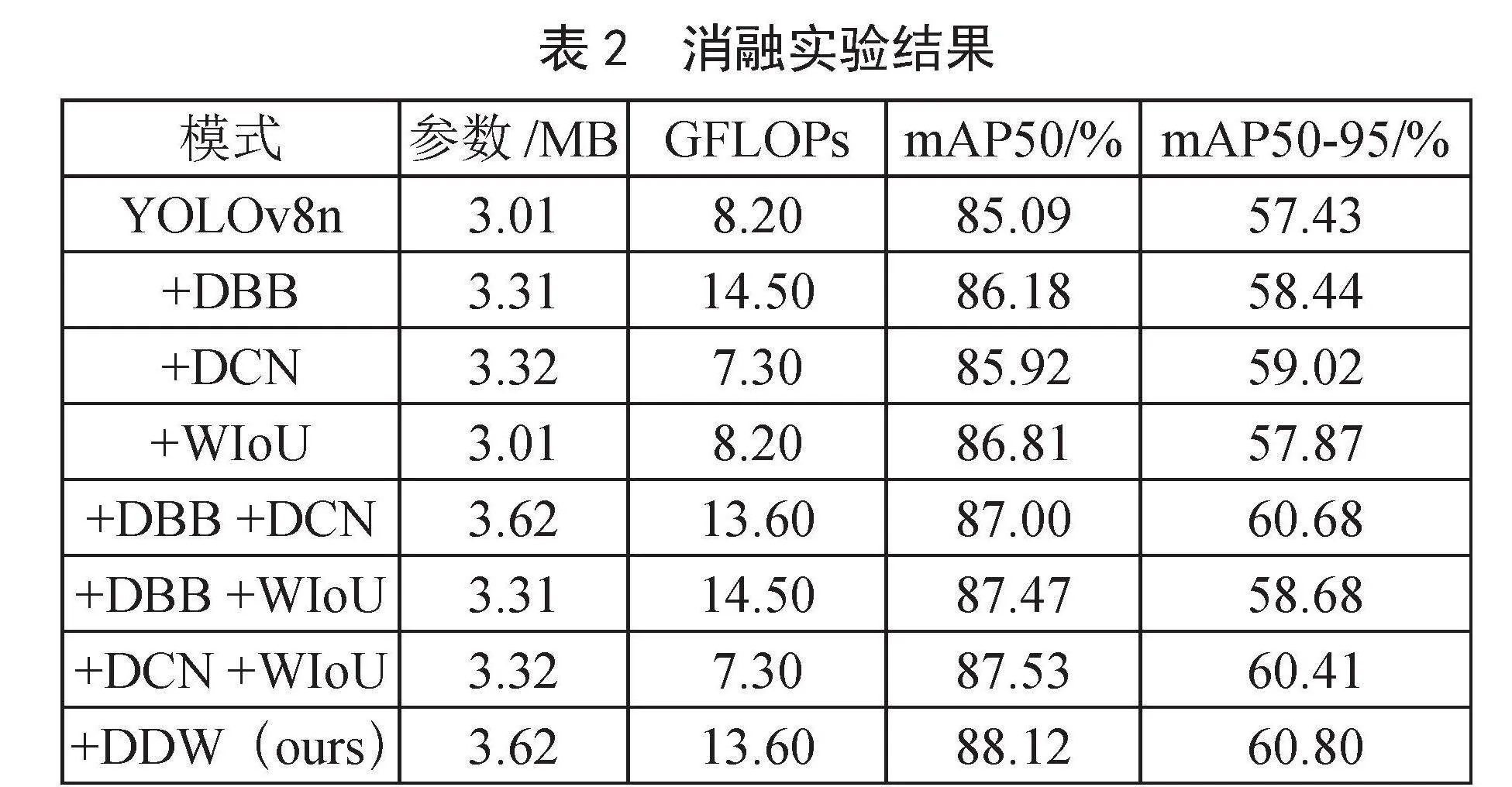
YOLOv8n整合DBB模块、采用DCN可变卷积、使用WIoU损失函数三种改进,以及相关消融实验结果,如表2所示,其中DDW指使用全部三种改进的模型。从实验中看出,DDW取得最好效果,比起YOLOv8n,mAP50提升3.03%,mAP50-95提升了3.37%。
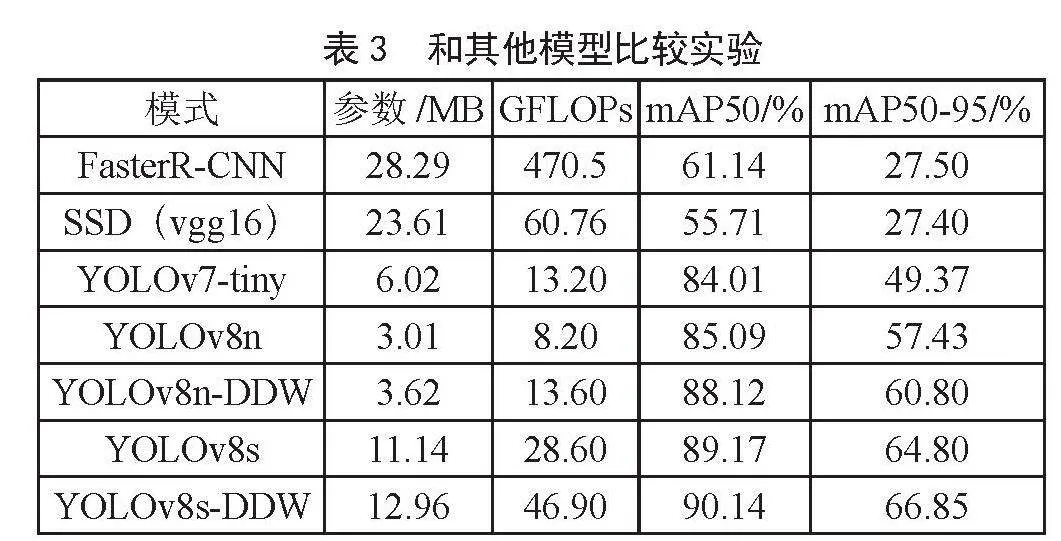
5.3 和其他模型对比结果
与其他模型Faster R-CNN、SSD、YOLOv7等对比结果如表3所示。相比Faster R-CNN和SSD,YOLOv8n-DDW在参数量和计算量大幅降低的情况下,mAP50和mAP50-95指标获得了大幅提升;相比YOLOv7-tiny,YOLOv8n-DDW参数量下降39.87%和计算量微升3.03%的情况下,mAP50提高4.11%,mAP50-95提高11.43%;使用三种改进的YOLOv8系列其他模型,如YOLOv8s-DDW对于YOLOv8s,mAP50微升0.97%,mAP50-95提高了2.01%。
各算法实验视觉效果图如图6所示,从图中可以看出Faster R-CNN识别和定位也很好,但存在多余的可以合并的识别框,SSD识别点存在着一定的遗漏,从图中的实际效果看,YOLOv8n-DDW相对YOLOv8n,不仅正确识别率高,定位也更加准确。
6 结 论
本文基于YOLOv8进行火焰和烟雾检测,并对模型结构进行改进以提高准确度,改进包括YOLOv8n骨干网引入DBB模块、使用DCN可变卷积、使用WIoU损失函数三个方面。通过消融实验,YOLOv8n-DDW对比YOLOv8n,mAP50提升3.03%,mAP50-95提升了3.37%,相比Faster R-CNN、SSD、YOLOv7等其他模型,各项性能指标也获得了大幅提升,提升了火灾检测准确度。
参考文献:
[1] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(16):1137-1149.
[2] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot Multibox Detector [C]//Computer Vision-ECCV 2016.Amsterdam:Springer International Publishing,2016:21-37.
[3] JIANG P Y,ERGU D,LIU F Y,et al. A Review of YOLO Algorithm Developments [J].Procedia Computer Science,2022,199:1066-1073.
[4] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-time Object Detection [C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016:779-788.
[5] 谢康康,朱文忠,谢林森,等.基于改进YOLOv7的火焰烟雾检测算法 [J].国外电子测量技术,2023,42(7):41-49.
[6] 王一旭,肖小玲,王鹏飞,等.改进YOLOv5s的小目标烟雾火焰检测算法 [J].计算机工程与应用,2023,59(1):72-81.
[7] 宋华伟,屈晓娟,杨欣,等.基于改进YOLOv5的火焰烟雾检测 [J].计算机工程,2023,49(6):250-256.
[8] ZHOU Y J,ZHU W G,HE Y H,et al. Yolov8-based Spatial Target Part Recognition [C]//2023 IEEE 3rd International Conference on Information Technology,Big Data and Artificial Intelligence(ICIBA).Chongqing:IEEE,2023:1684-1687.
[9] 袁红春,陶磊.基于改进的Yolov8商业渔船电子监控数据中鱼类的检测与识别 [J].大连海洋大学学报,2023,38(3):533-542.
[10] DING X H,ZHANG X Y,HAN J G,et al. Diverse Branch Block: Building a Convolution as an Inception-like Unit [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville:IEEE,2021:10886-10895.
[11] SZEGEDY C,VANHOUCKE V,IOFFE S,et al. Rethinking the Inception Architecture for Computer Vision [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas:IEEE,2016:2818-2826.
[12] DAI J F,QI H Z,XIONG Y W,et al. Deformable Convolutional Networks [C]//Proceedings of the IEEE International Conference on Computer Vision.Venice:IEEE,2017:764-773.
[13] ZHENG Z H,WANG P,LIU W,et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression [C]//Proceedings of the AAAI Conference on Artificial Intelligence.AAAI:New York, 2020,34(7):12993-13000.
[14] ZHANG Y F,REN W Q,ZHANG Z,et al. Focal and Efficient IOU Loss for Accurate Bounding Box Regression [J].Neurocomputing,2022,506:146-157.
[15] GEVORGYAN Z. SIoU Loss: More Powerful Learning for Bounding Box Regression [J/OL].arXiv:2205.12740 [cs.CV].(2022-05-25).https://arxiv.org/abs/2205.12740.
[16] MA S L,XU Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression [J/OL].arXiv:2307.07662 [cs.CV].(2023-07-14).https://arxiv.org/abs/2307.07662.
[17] TONG Z J,CHEN Y H,XU Z W,et al. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism [J/OL].arXiv:2301.10051 [cs.CV].(2023-04-08).https://arxiv.org/abs/2301.10051.
作者简介:韩伟娟(1986—),女,汉族,河南禹州人,中级工程师,硕士,研究方向:深度学习、图像处理、无线传感网络。
收稿日期:2024-07-16
