基于国产车控芯片的数据缓存技术应用研究
2025-02-08刘子毓陈树星刘振东卜海芋史宜灵













【Cite this paper】LIU Z Y,CHEN S X,LIU Z D, et al. Application Research of Data CACHE Technology Based on Localization Vehicle Microcontroller[J]. Automotive Digest (Chinese), 2023(XX): XX-XX.
【摘要】目前在动力域控制器设计与开发方面,国外车控芯片占据垄断地位。为解决关键技术被卡脖子的现状,采用国产化芯片结合国产化AUTOSAR操作系统进行开发。研究重点在于数据缓存技术的应用与优化,针对国产化芯片开发中遇到的缓存数据一致性的问题,提出了多种数据同步机制与缓存策略优化方案,有效消除了数据不一致的风险。此外通过设计高效的数据缓存策略,显著提升了控制器的指令执行效率并设计实验进行验证。
关键词:AUTOSAR;高速缓存;多核操作系统
中图分类号:U461.99文献标志码:ADOI:10.19822/j.cnki.1671-6329.20240155
Application Research of Data CACHE Technology Based on Localization Vehicle Microcontroller
Liu Ziyu, Chen Shuxing, Liu Zhendong, Bu Haiyum, Shi Yiling
(Commercial Vehicle Development Institute, FAW Jiefang Truck Co., Ltd., Changchun 130011)
【Abstract】Currently, foreign automotive control chips dominate the design and development of powertrain domain controllers. To address this technological bottleneck, there is a growing trend towards adopting domestically produced chips alongside domestically developed AUTOSAR operating systems. The research focuses on the application and optimization of data caching technology. In response to the challenge of cache data consistency encountered in the development of domestically produced chips, various mechanisms for data synchronization and optimization schemes for cache strategy have been proposed, effectively mitigating the risk of data inconsistency. Furthermore, by designing efficient data caching strategies, the instruction execution efficiency of the controller has been significantly improved, and experiments have been designed to verify these improvements.
Key words: AUTOSAR,CACHE, Multicore operating systems
0 引言
随着汽车智能化和电动化的发展,汽车行业车规级芯片的使用需求呈爆炸式增长。当前车规级芯片的市场份额大部分被外国企业占领,如英飞凌、恩智浦、意法半导体以及瑞萨电子。随着国际形势的改变,近年来汽车行业多次出现由于缺乏芯片导致的减产现象,面对紧缺的车规级芯片市场,国内厂商抢抓机遇,全面布局车规级芯片,旨在解决关键核心芯片“卡脖子”问题,打破国外垄断局面[1]。中国车规级芯片行业基础相对薄弱,在许多应用场景中缺乏产品研发及量产经验,同时中国主机厂对国产车规级芯片信息了解不足、信任度不高、使用量低[2],导致国产车规级芯片缺乏量产经验,难以快速迭代出高质量芯片,尚未形成良性生态循环。
为满足日益复杂的汽车电子电气发展趋势,汽车电子控制系统也趋于复杂化,具体体现在对芯片高算力的要求和对平台软件的高稳定性和高实时性要求2个方面,可以通过使用国产化的汽车开放系统架构(Automotive Open System Architechture,AUTOASR)满足[3]。AUTOSAR是由全球范围内各大型汽车主机厂、汽车零部件供应商以及汽车电子相关软件开发公司联合成立的一个标准协议[4],旨在通过实现软件分层开发架构降低应用层开发人员与底层驱动软件开发人员因硬件变化而受到的影响。
为了满足芯片对高计算能力的要求,可以选择搭载多核处理器芯片,实现执行速度提升。但多核芯片无法提升数据访问速度,因此需要采用高速缓存(CACHE)。鉴于其国产化时间较短,技术领域尚不成熟,需进一步的研究与完善。本文围绕柴油发动机控制器电控单元项目,采用苏州国芯CCFC3008PT多核芯片、国产AUTOSAR实时操作系统,探讨CACHE技术的应用问题。
1 问题分析
在项目开发过程中,控制器集成应用软件后,应用软件无法驱动芯片数字量通道。初始考虑驱动软件存在问题,但是控制器在集成应用前测试驱动功能正常,可以按照给定参数控制芯片引脚输出电平状态。进行软件代码检查,并通过调试器逐级检查应用层函数的传递参数、堆栈信息与程序计数器(ProgramCounter,PC)指针,均未发现异常。需将函数的参数由全局变量改变为立即数才能实现正常输出,因而考虑CACHE访问全局变量存在异常。
1.1 操作系统层面
首先分析故障产生原因是否与代码放置位置有关,故障代码由核1执行,核1负责为变量赋值,并将参数传递至底层驱动函数。驱动函数获取参数后,通过核2向芯片外设模块寄存器传递参数。通过调试器观测外设寄存器发现来自核1的参数未成功传入芯片外设寄存器。若将赋值函数移至核2执行,该问题未出现。
1.2 芯片驱动层面
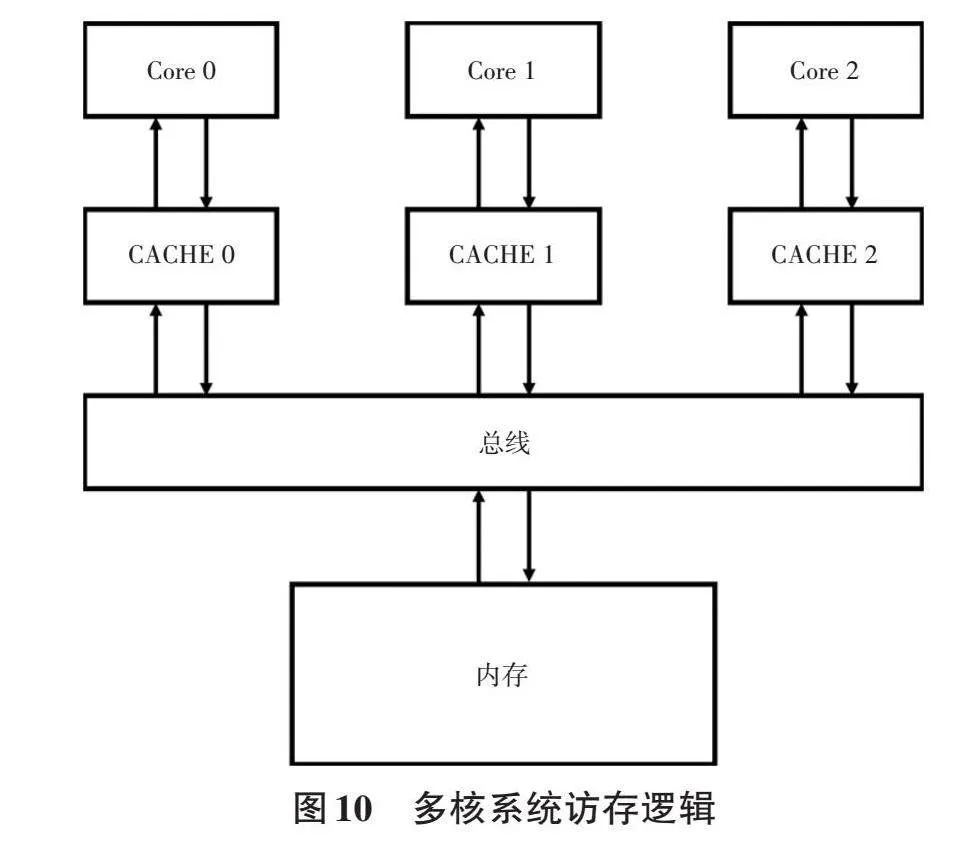
经过上述操作可以确定该问题与代码执行位置具有强相关性。同一行函数在不同执行位置运行结果不同,表明还需进一步排查该问题。通过直接观测内存,发现在运行(Run)状态下,通过核1的函数给变量赋值,变量在内存区域的值未随之更新。而在断点(Break)状态下,变量值改变时,内存中相应的值可随变量更新。仔细观察核1初始化配置代码,发现核1与核2的区别在于核1具有数据区高速缓存(DCACHE),而核2仅配备代码区高速缓存(ICACHE)。在核1运行期间,数据访问范围始终不超出DCACHE命中区域。所有变量赋值与读取均在DCACHE内部进行,不会将变量更新传递到内存区域中。由于每个核均具有独立的CACHE区域,并且只对其专属CACHE具有访问权限[5]。不同核间传递参数必须通过内存进行,导致应用层代码下发的参数无法成功加载到芯片外设寄存器。
2 国产化芯片缓存
2.1 高速缓存存储器
在应用高速缓存存储器前,中央处理单元(Central Processing Unit,CPU)均按照程序员编写的指令读取内存信息。程序员通过高级语言编写程序,再由编译器根据不同芯片指令集将其翻译为芯片能够执行的汇编指令。这些指令与数据通常存放于非易失性存储器中。当系统启动时,这些指令与数据将被加载至内存中。CPU访问内存可以分为2种类型:(1)程序执行过程中需要访问内存以读写数据;(2)CPU必须访问内存以获取下一条需执行的指令。
在CPU与内存的协同作用下,程序得以顺利执行。然而,由于CPU的运行速度远大于内存访问数据或程序的速度,导致实际运行过程中,CPU常处于等待状态,以便数据可以缓慢地由内存传输至CPU。随着内存速度与现代处理器速度之间的差距不断扩大,系统对主储存器的数据存取访问成为系统性能的新瓶颈[6],无法满足对高性能芯片日益增长的需求。为了克服这一缺陷,CPU就不应直接从内存中读取数据或指令。
实际上,CPU访问内存并非完全随机,而是存在时间局限性和空间局限性。在程序占据的内存空间中,只有一部分区域在程序运行过程中经常被CPU所访问,其可能是分散的,也可能是集中的,可以将其集中储存至访问速度较高的存储介质上。该存储介质可以充当CPU和内存之间的中转站称之为CACHE。
引入CACHE后,CPU无需直接对内存进行访问,如图1所示,将经常使用到的数据存放至CACHE中,CPU需要访问内存时,将首先在CACHE中进行查找。如果所需数据或指令以存在于CACHE中里面已经存在相应数据或指令,则无需对内存进行访问,可以有效提升CPU的执行速度。但CACHE不能直接替换内存,因为CACHE的价格更高,为了考虑成本,CACHE的容量不会做的很大。但由于CPU对内存的访问有着时间局限性和空间局限性,即使CACHE比内存小很多具有较高命中率。
2.2 CACHE地址映射方式
由于内存的存储空间远大于CACHE,所以CACHE的同一位置必须可以存储来自不同内存的数据或指令,以实现小容量CACHE对大容量内存区域的有效覆盖。为了避免CPU在通过缓存访问内存时不得不处理内存地址和缓存地址之间的复杂关系,需要建立一个CACHE和内存的映射机制,允许CPU通过预访问内存地址自动确定其存放于CACHE的位置,减少CACHE资源浪费,提高访问速度。
为了建立缓存与主存之间的映射关系,需对CACHE内部存储单元进行分类,如图2所示,将CACHE内部资源分别用于存储数据、存储地址信息以及存储地址偏移量和其他有效信息。CPU的读写以字为单位,而CACHE与内存之间的读写以line为单位。将CACHE与内存之间的最小读写单元定义为1个linesize(不包含地址与其他有效信息),若linesize大小为32字节,即CACHE每次缓存数据或指令信息均以0x20地址与内存对齐[7]。而CACHE每条line被称为SET,CACHE的总容量除以linesize,就等于SETNumber,不同的line通过SETNumber进行标识,其他信息存储在line头部位置。
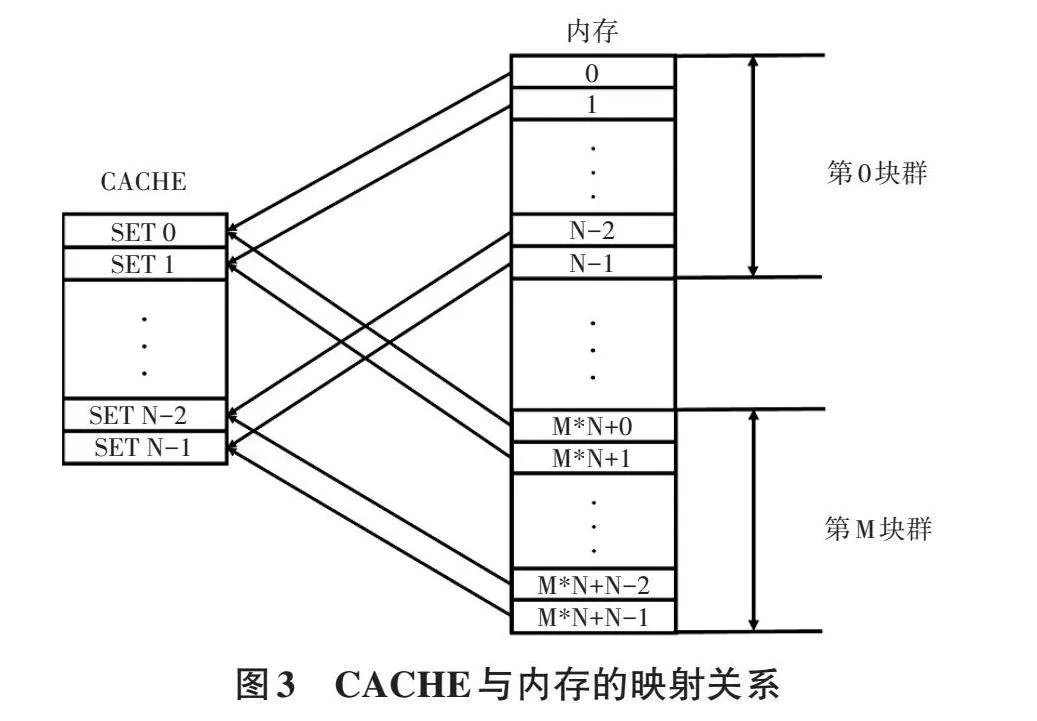
目前,国产化CACHE与内存之间的映射采用直接映射的方法。一个内存块地址始终对应一个固定的CACHE地址,对于同一内存地址的多次访问,其数据均被加载至相同CACHEline内。为了完成此映射,需将内存区域按照CACHE的容量划分为多个区块。
如图3所示,按照CACHE容量将内存区域划分为M个块群。当内存地址为N的倍数的内存区域加载至缓存中,均被分配至SET0中。若需访问第“6N+2”号内存块,假设该块已在CACHE中,则其必定位于SET 2中。这表明CACHE的SETNumber值与内存地址低位存在对应关系。
在CACHE中,存储的数据或指令无需其在主内存中的完整地址标识,因此Tag仅保留了高位地址信息。低位地址信息可以通过CACHE的SETNumber获得。为了重构完整的内存地址,需将CPU预访问的内存地址对Line大小取余后的结果作为偏移量。如图4所示,将SET NUMBER与该偏移量结合,即可复现数据或指令在主内存中的地址信息。
2.3 存在问题与改进措施
若数据需从第0块内存迁移至数据至第N块内存,由于映射方式为直接映射,二者内存将被映射至CACHE的同一line中。此情况可能导致CACHE需持续从内存中加载数据,造成CACHE未命中的情况频繁发生。CPU需等待CACHE清除当前数据并重新加载内存数据,导致CPU的执行效率低于未开启CACHE的情况。为了应对这种情况,将CACHE划分为2部分,称为2个WAY[8]。如图5所示,双WAY的大小和映射机制完全相同。通过这种设计,可以同时命中在直接映射下映射到同一line的内存块,有效提高了CPU的执行速度。
若此时CACHE需要缓存来自第3个内存地址的数据或指令至该line,此时2个WAY对应的存储空间均已占用。为了确定需被替换数据,为CACHE内包含的数据赋予优先级,高优先级数据应尽量包含权值高、访问概率大、数据复杂度小核以及更新时间间隔长的特点[9]。可以采用以下3种办法识别高优先级数据。
(1)先入先出法
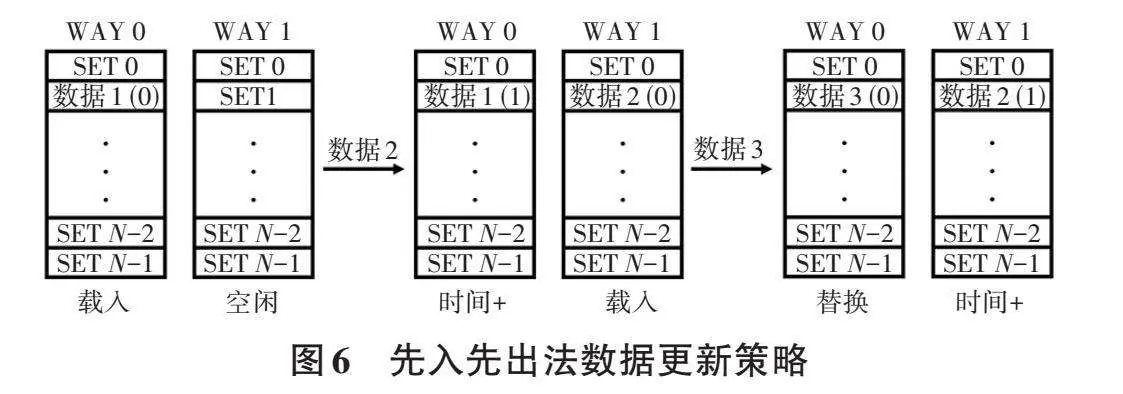
如图6所示,利用CACHE中预留的R位,设置1个计数器,在每次CACHE从内存读取数据或指令时,将计数器加一,若CACHE填满,则选择计数器数值较大的line进行替换。
(2)最不经常使用法
如图7所示,CPU每一次读取CACHE中命中的信息时,将对应的CACHEline计数器加一,当CACHE被填满时,选择计数器较小的line进行替换。
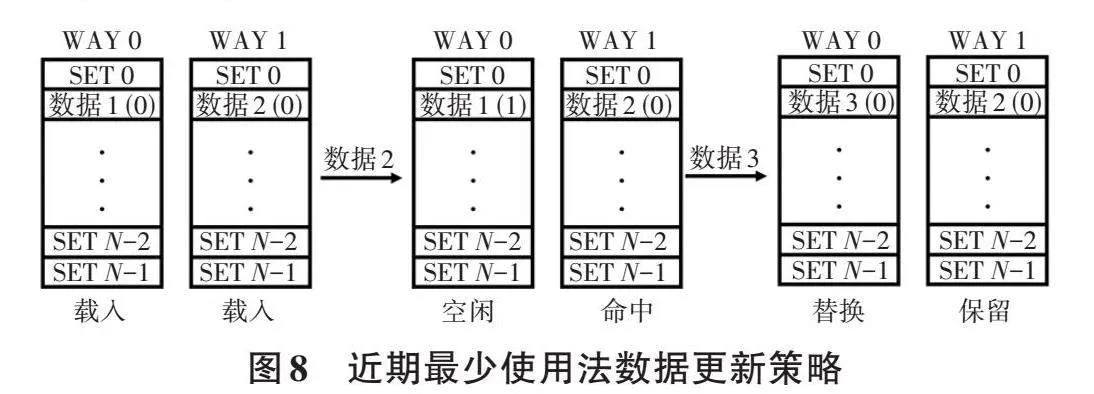
(3)近期最少使用法
如图8所示,在CPU每访问CACHE时,将命中的line计数器清零,其余的所有line的计数器加一,最后选择计数器最大的line进行替换[10]。
通过上述3种替换算法可以最大限度地使CACHE保留最有效的数据或指令,增加CACHE的命中率,进一步避免了由于内存速度缓慢导致CPU等待数据或指令时间过长的问题,提高了国产化芯片性能。
在单核系统中,上述CACHE架构与逻辑可以在全工况条件下提升CPU运行速度。然而,根据上文对于多核系统问题的分析与论证,发现CACHE在多核系统下存在缓存数据一致性的问题。为了保证不同核内CACHE中对应同一内存的CACHEline数据保持一致,关键要确保同一核的写入操作对其他核均可见。基于此,提出以下2个原则:(1)单写多读(Single-WriterMultiple-Read,SWMR。该原则需确保在同一时间内,对于任何内存地址(假设地址为A),仅有一个核对地址为A的内存有读写权限,或者存在多个核具有只读权限。因此,可以避免以下情形发生:当地址A被多个核读取至CACHE内时,若其中某核更改了CACHE中地址A的数据,并将该修改写入内存,而其他核未收到更新通知,导致缓存一致性问题。如图9所示,将时间细分为多个小切片,每个切片均遵循SWMR原则。例如在T1、T4时刻,允许多个核对同一个地址的内存进行读取。然而,在T2、T4时刻,涉及到写入时,仅有一个核被授予读写权限,其他核在该时间切片内不可以读取该内存。(2)数值传播原则。该原则要求在时间片段中,上一个时间片段结束的数据值必须与下一个时间片段开始时的数据值相同。这要求内存更新的数据值需被正确地传播至所有核。例如在T1时刻,核2、核5读取的数据必须相同才能满足一致性要求。在T3时刻,核1应读取T2时刻核3最后写入的数据值。同样地,在T4时刻,核1、核2、核3应当读取T3时刻核3最后写入的数据值才能满足一致性要求。
在设计一致性协议时,应考虑上述2项原则。一致性协议需明确每个参与一致性的内存和缓存组件可能所处的CACHE状态,以及需发送或响应的一致性事务操作。为此,可采用以下3种协议:
(1)监听协议
该协议要求CACHE从内存中读取数据时,均需通过共享总线发出请求。共享总线负责仲裁,决定访问请求的优先级,并将优先级通知所有CACHE。总线仲裁逻辑可以确保在任一时刻共享总线仅处理一个内存访问请求[11]。如图10所示,监听协议通过仲裁逻辑,对同时出现的请求进行优先级排序,并通过总线广播优先级顺序。各CACHE通过监听总线获知排序顺序,从而确定自身请求排序情况。该机制可以满足2个一致性原则的要求。
(2)无效协议
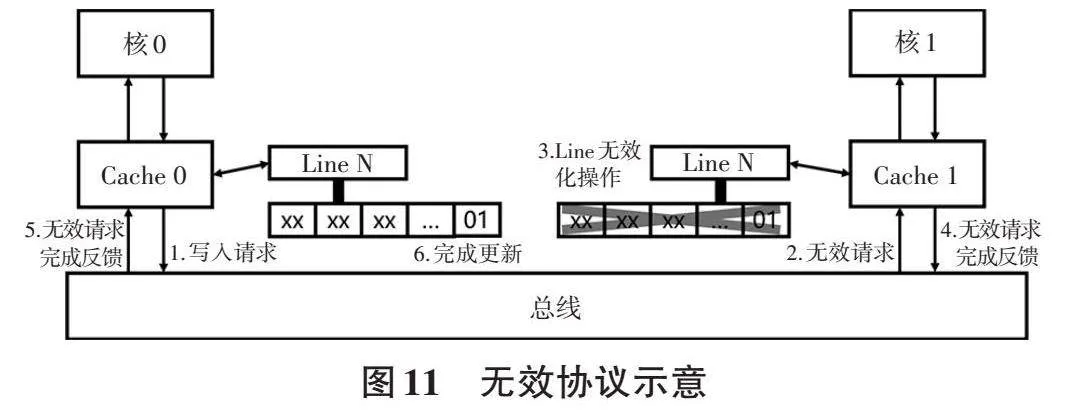
如图11所示,当某核需写入某CACHEline时,CACHE将该CACHEline命中的地址通知其他CACHE。若其他CACHE中存在相同地址的CACHEline,则将根据无效协议将其他所有包含相同信息的CACHEline标记为无效。在确保其他核无法通过CACHE读取过时数据后,该核才能对CACHE进行写入操作,并将对应数据写入内存。其他核需读取该数据时,必须重新将其从内存存入CACHE,以确保数据的一致性。
(3)更新协议
如图12所示,若某核需写入某CACHEline,CACHE首先将新写入的值写入内存,并产生一个更新请求,该请求通过总线广播发送至所有CACHE。CACHE检查自身是否包含待更新的地址信息。若包含待更新地址信息,CACHE将重新从内存中加载数据,确保所有CACHE存储的值均为最新值[12]。
3 数据缓存性能测试软硬件介绍
3.1 硬件部分
本文所搭建的数据缓存开发系统基于CCFC3008PT开发板(图13)开发,并将其作为缓存测试的硬件部分。CCFC3008PT芯片内核采用PowerPC指令集架构[13],具体参数如表1所示。
3.2 软件部分
本文所使用的软件工具如表2所示。
本文搭建的软件系统架构遵循AUTOSAR标准,所有代码均满足车规级要求。使用东软睿驰提供的Configurator进行多核操作系统的配置,使用EBTresos配置端口(Port)与内部输入输出(Input,Output,IO)量相连,通过外部示波器方便观测代码执行时间。使用Hightec编译器将底层驱动代码与上层操作系统软件集成,同时进行代码编译,生成单片机可执行的文件。
3.3 数据传输时间监控方法
由于在测试中将使用多个芯片外设模块,在开展测试前必须完成各模块的初始化操作,并通过AUTOSAR标准的函数接口实现操作系统[14],符合AUTOSAR标准的系统初始化位置如表3所示。
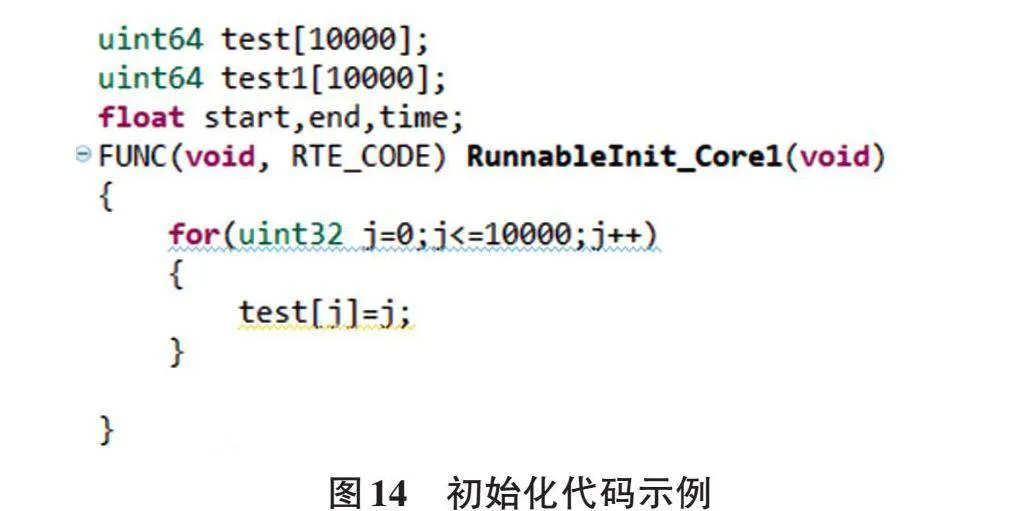
初始化工作完成后,为了检验数据缓存对数据传输性能的影响,进行2个数组间的数据传输工作,通过IO口反转的方式监控数据传输时间。图14为数组定义与初始化代码示例,图15为数据传输与时间监控代码示例。
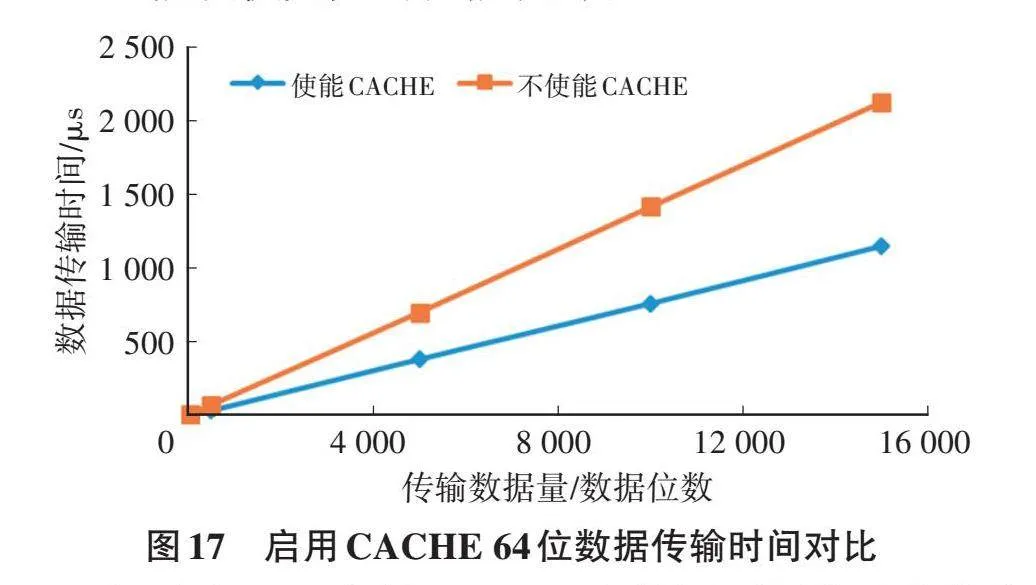
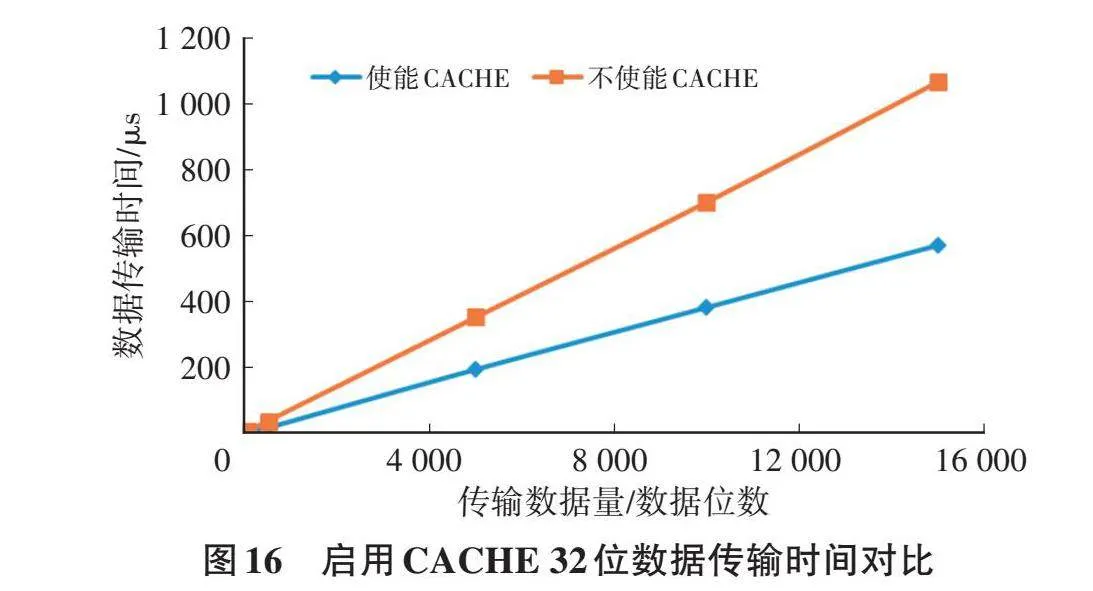
通过示波器观测管脚电平反转的方式,监控代码执行时间[15]。同时通过调试器使用其他核观察数组内数据判断开启数据缓存时是否确保了数据一致性。图16为32位数组相互传输数据用时随数组位数变化的测量结果。图17为64位数组相互传输数据用时随数组位数变化的测量结果。
由图16、图17中曲线可见,当不使用CACHE时,随着数据量的增加,CPU的执行时间呈现出显著的增长趋势。而使用CACHE时,随着数据量的增加,CPU的执行时间增长比率小于1,表明传输大量数据时,CACHE能提供更大的性能提升。
为了进一步分析CACHE的作用,使用调试器分别观察同一变量在内存中的值和CACHE中的值。若变量定义在核1并赋值时,不涉及CACHE一致性问题,此时变量在内存和CACHE中的值保持一致。若将变量赋值于核2执行,而变量定义保留在核1,通过调试器观测核1的内存与CACHE中变量储存的数据分别如图18和如图19所示。
可见在内存与CHACHE中的变量值均为14,经由一致性协议保证,当前数据缓存未出现数据一致性错误。
4 结束语
本文的研究成果解决了国产汽车控制芯片多核系统中维护数据一致性的问题。研究基于AUTOSAR标准和PowerPC架构,通过引入CACHE一致性协议,保障多核环境下的数据一致性,避免因数据不一致导致的系统故障或者传输错误的控制参数。
本文的研究结果与以往研究CACHE重要性的结论一致,支持通过使用缓存机制可以显著提升系统性能的观点。一些早期的研究认为缓存一致性协议可能会引入较大的开销。但本文通过涉及适当的机制与测试,证明这种开销可以通过机制避免,从而提升性能。然而,本文只集中于特定的硬件架构(PowerPC)进行研究,未对其他架构(如ARM或RISC-V)的实用性进行探讨。且研究主要量化了性能提升,未对功耗或热管理的影响进行探讨,这些也是汽车应用的关键因素。
参考文献
[1]武亚恒,张弘,胡凯,等.国产车规级芯片发展现状,问题及建议[J].时代汽车, 2022(6):26-27.
[2] 朱云尧, 吴胜男, 冯莉, 等. 我国汽车产业生态、发展趋势与挑战[J]. 汽车文摘, 2023(10): 32-37.
[3]FÜRST S.AUTOSAR – A Worldwide Standard is on the Road. [J]. 14th International VDI Congress Electronic Systems for Vehicles,2009,62(5):1-16.
[4]STARON M. Automotive Software Architectures[M]. Cham: Springer, 2021.
[5] HASSAN M, KAUSHIK A M , PATEL H.Predictable CACHE Coherence for Multi-Core Real-Time Systems[J].IEEE, 2017: 235-246.
[6]杨朝辉.主存数据库索引机制的研究与改进[D].南京:南京航空航天大学, 2024.
[7]张晓光,陶英轩,黄金山.智能网联趋势下车辆网关路由缓存研究与应用[J].汽车文摘, 2021(5):14-18.
[8]张俊敏,金继欢,侯睿.命名数据网络中的二分缓存方案[J].中南民族大学学报(自然科学版), 2024, 43(2):260-265.
[9] 李诗诗,方寿海.移动数据库缓存同步更新机制[J].煤炭技术, 2010, 29(10):166-168.
[10] 肖文龙,马迪,毛伟,等.基于事实所有权的RPKI缓存更新冲突检测机制[J].计算机系统应用, 2022, 31(2):366-375.
[11]陈家豪,黄乐天,谢暄,等.基于片上网络互连的多核缓存一致性研究综述[J].电子与封装, 2020, 20(11):1-8.
[12] SHUKUR H M, ZEEBAREE S R M, ZEBARI R,et al.CACHE Coherence Protocols in Distrubted Systems[J].Journal of Applied Science and Technology Trends, 2020, 1(3):92-97.
[13]程俊强,刘铎,陈益.基于PowerPC处理器的机载多总线单板计算机设计[J].测控技术, 2020, 39(11):85-90.
[14] 关健斌,吴志红,朱元,等.基于AUTOSAR标准的CAN FD通信实现[J].信息通信, 2020(3):5-7.
[15] ZHANG X , LIU B , GOU Z,et al.DCACHE: A Distributed CACHE Mechanism for HDFS based on RDMA[J].IEEE, 2020(1):283-291.
